
31 Jul 2024

This research introduces a co-evolutionary framework where individual strategies and the game environments they embody undergo simultaneous evolutionary selection. It demonstrates how such dynamic environments, particularly when structured by complex networks, foster the emergence and maintenance of cooperative behavior from various initial conditions.

17 Oct 2025


Researchers at National Yang Ming Chiao Tung University developed SKYFALL-GS, a framework that synthesizes high-quality, immersive, and real-time explorable 3D urban scenes exclusively from multi-view satellite imagery. This system leverages 3D Gaussian Splatting and open-domain text-to-image diffusion models to generate detailed ground-level appearances, outperforming previous methods in perceptual fidelity and geometric accuracy while supporting interactive exploration.

03 Dec 2025



A comprehensive survey evaluates geometric, neural (NeRF, 3DGS), and foundation models as 3D scene representations for robotics, assessing their performance across perception, mapping, localization, manipulation, and navigation modules. The analysis outlines the strengths and limitations of each representation type and points to 3D Foundation Models as a promising future direction for unified robotic intelligence.

29 Sep 2025

OVO, an open-vocabulary online 3D semantic mapping pipeline, was developed by researchers at the University of Zaragoza and University of Amsterdam. The system integrates with full SLAM backbones, including loop closure, and leverages a neural network-based CLIP merging method to build semantically rich 3D maps in real-time, outperforming prior methods in segmentation accuracy and computational efficiency.

27 Jun 2024
DINOv2 SALAD, developed by researchers at I3A, University of Zaragoza, introduces a single-stage visual place recognition method that combines a fine-tuned DINOv2 backbone with a novel Optimal Transport-based feature aggregation module. The approach achieves state-of-the-art performance, surpassing computationally intensive two-stage systems, with exceptional efficiency and robustness to extreme appearance changes.

10 Oct 2023
Computer-assisted systems are becoming broadly used in medicine. In endoscopy, most research focuses on the automatic detection of polyps or other pathologies, but localization and navigation of the endoscope are completely performed manually by physicians. To broaden this research and bring spatial Artificial Intelligence to endoscopies, data from complete procedures is needed. This paper introduces the Endomapper dataset, the first collection of complete endoscopy sequences acquired during regular medical practice, making secondary use of medical data. Its main purpose is to facilitate the development and evaluation of Visual Simultaneous Localization and Mapping (VSLAM) methods in real endoscopy data. The dataset contains more than 24 hours of video. It is the first endoscopic dataset that includes endoscope calibration as well as the original calibration videos. Meta-data and annotations associated with the dataset vary from the anatomical landmarks, procedure labeling, segmentations, reconstructions, simulated sequences with ground truth and same patient procedures. The software used in this paper is publicly available.

30 Jul 2025
Robust estimation is essential in correspondence-based Point Cloud Registration (PCR). Existing methods using maximal clique search in compatibility graphs achieve high recall but suffer from exponential time complexity, limiting their use in time-sensitive applications. To address this challenge, we propose a fast and robust estimator, TurboReg, built upon a novel lightweight clique, TurboClique, and a highly parallelizable Pivot-Guided Search (PGS) algorithm. First, we define the TurboClique as a 3-clique within a highly-constrained compatibility graph. The lightweight nature of the 3-clique allows for efficient parallel searching, and the highly-constrained compatibility graph ensures robust spatial consistency for stable transformation estimation. Next, PGS selects matching pairs with high SC scores as pivots, effectively guiding the search toward TurboCliques with higher inlier ratios. Moreover, the PGS algorithm has linear time complexity and is significantly more efficient than the maximal clique search with exponential time complexity. Extensive experiments show that TurboReg achieves state-of-the-art performance across multiple real-world datasets, with substantial speed improvements. For example, on the 3DMatch+FCGF dataset, TurboReg (1K) operates faster than 3DMAC while also achieving higher recall. Our code is accessible at \href{this https URL}{\texttt{TurboReg}}.

05 Jun 2025


Contrastive losses have been extensively used as a tool for multimodal representation learning. However, it has been empirically observed that their use is not effective to learn an aligned representation space. In this paper, we argue that this phenomenon is caused by the presence of modality-specific information in the representation space. Although some of the most widely used contrastive losses maximize the mutual information between representations of both modalities, they are not designed to remove the modality-specific information. We give a theoretical description of this problem through the lens of the Information Bottleneck Principle. We also empirically analyze how different hyperparameters affect the emergence of this phenomenon in a controlled experimental setup. Finally, we propose a regularization term in the loss function that is derived by means of a variational approximation and aims to increase the representational alignment. We analyze in a set of controlled experiments and real-world applications the advantages of including this regularization term.

15 Apr 2024
Navigation of UAVs in challenging environments like tunnels or mines, where it is not possible to use GNSS methods to self-localize, illumination may be uneven or nonexistent, and wall features are likely to be scarce, is a complex task, especially if the navigation has to be done at high speed. In this paper we propose a novel proof-of-concept navigation technique for UAVs based on the use of LiDAR information through the joint use of geometric and machine-learning algorithms. The perceived information is processed by a deep neural network to establish the yaw of the UAV with respect to the tunnel's longitudinal axis, in order to adjust the direction of navigation. Additionally, a geometric method is used to compute the safest location inside the tunnel (i.e. the one that maximizes the distance to the closest obstacle). This information proves to be sufficient for simple yet effective navigation in straight and curved tunnels.

24 Sep 2025
Higher-order dynamics refer to mechanisms where collective mutual or synchronous interactions differ fundamentally from their pairwise counterparts through the concept of many-body interactions. Phenomena absent in pairwise models, such as catastrophic activation, hysteresis, and hybrid transitions, emerge naturally in higher-order interacting systems. Thus, the simulation of contagion dynamics on higher-order structures is algorithmically and computationally challenging due to the complexity of propagation through hyperedges of arbitrary order. To address this issue, optimized Gillespie algorithms were constructed for higher-order structures by means of phantom processes: events that do not change the state of the system but still account for time progression. We investigate the algorithm's performance considering the susceptible-infected-susceptible (SIS) epidemic model with critical mass thresholds on hypergraphs. Optimizations were assessed on networks of different sizes and levels of heterogeneity in both connectivity and order interactions, in a high epidemic prevalence regime. Algorithms with phantom processes are shown to outperform standard approaches by several orders of magnitude in the limit of large sizes. Indeed, a high computational complexity scaling with system size of the standard algorithms is improved to low complexity scaling nearly as . The optimized methods allow for the simulation of highly heterogeneous networks with millions of nodes within affordable computation costs, significantly surpassing the size range and order heterogeneity currently considered.

11 Dec 2024
The search for axions and axion-like particles (ALPs) remains a major endeavor in modern physics investigation. Axions play essential roles in the quest to understand dark matter, the strong CP problem, and various astrophysical phenomena. This paper provides a very brief overview of the current status of experimental efforts, highlighting significant advancements, ongoing projects, and future opportunities. Particular attention is given to cavity haloscopes, helioscopes, and laboratory-based light-shining-through-wall experiments, as well as astrophysical probes. Some future perspectives are also discussed.

09 Sep 2024
Nowadays, the large amount of audio-visual content available has fostered the need to develop new robust automatic speaker diarization systems to analyse and characterise it. This kind of system helps to reduce the cost of doing this process manually and allows the use of the speaker information for different applications, as a huge quantity of information is present, for example, images of faces, or audio recordings. Therefore, this paper aims to address a critical area in the field of speaker diarization systems, the integration of audio-visual content of different domains. This paper seeks to push beyond current state-of-the-art practices by developing a robust audio-visual speaker diarization framework adaptable to various data domains, including TV scenarios, meetings, and daily activities. Unlike most of the existing audio-visual speaker diarization systems, this framework will also include the proposal of an approach to lead the precise assignment of specific identities in TV scenarios where celebrities appear. In addition, in this work, we have conducted an extensive compilation of the current state-of-the-art approaches and the existing databases for developing audio-visual speaker diarization.

25 Sep 2025
Deep learning representations are often difficult to interpret, which can hinder their deployment in sensitive applications. Concept Bottleneck Models (CBMs) have emerged as a promising approach to mitigate this issue by learning representations that support target task performance while ensuring that each component predicts a concrete concept from a predefined set. In this work, we argue that CBMs do not impose a true bottleneck: the fact that a component can predict a concept does not guarantee that it encodes only information about that concept. This shortcoming raises concerns regarding interpretability and the validity of intervention procedures. To overcome this limitation, we propose Minimal Concept Bottleneck Models (MCBMs), which incorporate an Information Bottleneck (IB) objective to constrain each representation component to retain only the information relevant to its corresponding concept. This IB is implemented via a variational regularization term added to the training loss. As a result, MCBMs yield more interpretable representations, support principled concept-level interventions, and remain consistent with probability-theoretic foundations.

25 Sep 2024
ColonSLAM introduces a hybrid metric-topological SLAM system that constructs comprehensive, patient-specific maps of the entire colon during colonoscopy procedures. It integrates a specialized deep visual place recognition network and topological priors to connect fragmented metric submaps into a rich graph, achieving 0.90 precision and 0.70 recall in localizing submaps while effectively representing procedural complexity.

02 Jul 2024
 Imperial College London
Imperial College London National University of Singapore
National University of Singapore University College London
University College London Stanford University
Stanford University Zhejiang University
Zhejiang University The Chinese University of Hong KongKorea Advanced Institute of Science and TechnologyUniversity of Central LancashireIndian Institute of Technology KharagpurUniversity of ZaragozaIntuitive Surgical
The Chinese University of Hong KongKorea Advanced Institute of Science and TechnologyUniversity of Central LancashireIndian Institute of Technology KharagpurUniversity of ZaragozaIntuitive SurgicalColorectal cancer is one of the most common cancers in the world. While colonoscopy is an effective screening technique, navigating an endoscope through the colon to detect polyps is challenging. A 3D map of the observed surfaces could enhance the identification of unscreened colon tissue and serve as a training platform. However, reconstructing the colon from video footage remains difficult. Learning-based approaches hold promise as robust alternatives, but necessitate extensive datasets. Establishing a benchmark dataset, the 2022 EndoVis sub-challenge SimCol3D aimed to facilitate data-driven depth and pose prediction during colonoscopy. The challenge was hosted as part of MICCAI 2022 in Singapore. Six teams from around the world and representatives from academia and industry participated in the three sub-challenges: synthetic depth prediction, synthetic pose prediction, and real pose prediction. This paper describes the challenge, the submitted methods, and their results. We show that depth prediction from synthetic colonoscopy images is robustly solvable, while pose estimation remains an open research question.

02 Jul 2024
Visual Place Recognition (VPR) plays a critical role in many localization and mapping pipelines. It consists of retrieving the closest sample to a query image, in a certain embedding space, from a database of geotagged references. The image embedding is learned to effectively describe a place despite variations in visual appearance, viewpoint, and geometric changes. In this work, we formulate how limitations in the Geographic Distance Sensitivity of current VPR embeddings result in a high probability of incorrectly sorting the top-k retrievals, negatively impacting the recall. In order to address this issue in single-stage VPR, we propose a novel mining strategy, CliqueMining, that selects positive and negative examples by sampling cliques from a graph of visually similar images. Our approach boosts the sensitivity of VPR embeddings at small distance ranges, significantly improving the state of the art on relevant benchmarks. In particular, we raise recall@1 from 75% to 82% in MSLS Challenge, and from 76% to 90% in Nordland. Models and code are available at this https URL.
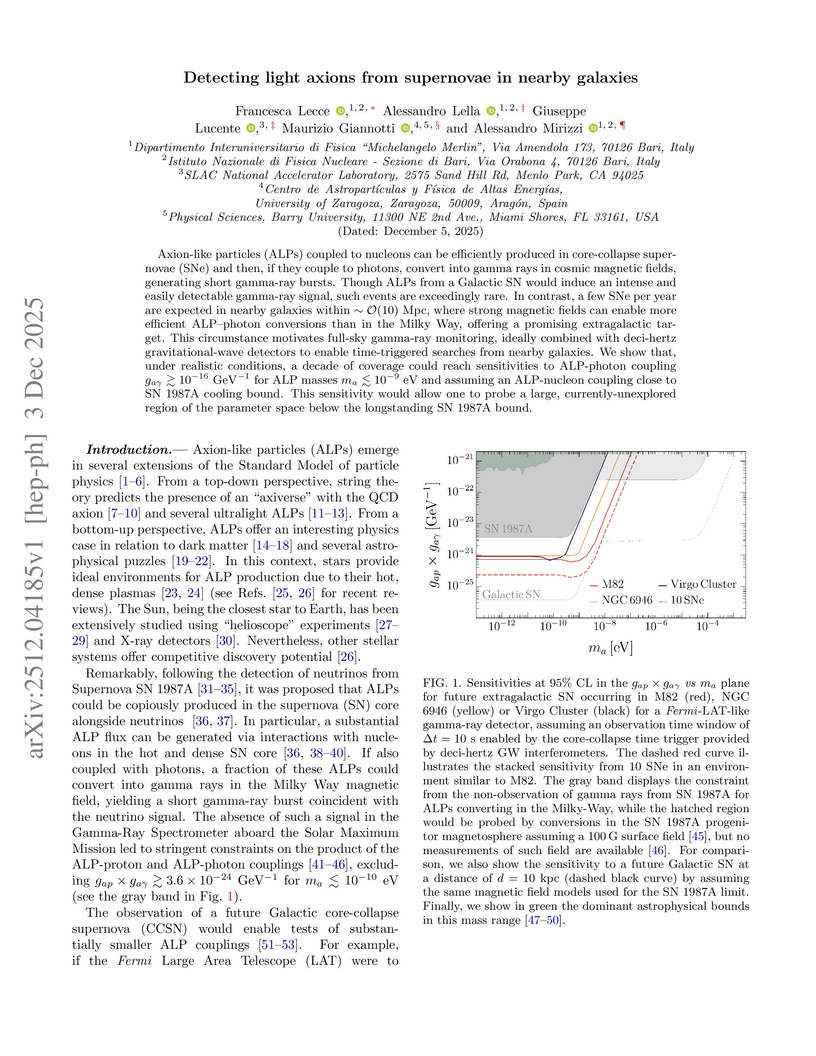
03 Dec 2025
Axion-like particles (ALPs) coupled to nucleons can be efficiently produced in core-collapse supernovae (SNe) and then, if they couple to photons, convert into gamma rays in cosmic magnetic fields, generating short gamma-ray bursts. Though ALPs from a Galactic SN would induce an intense and easily detectable gamma-ray signal, such events are exceedingly rare. In contrast, a few SNe per year are expected in nearby galaxies within Mpc, where strong magnetic fields can enable more efficient ALP-photon conversions than in the Milky Way, offering a promising extragalactic target. This circumstance motivates full-sky gamma-ray monitoring, ideally combined with deci-hertz gravitational-wave detectors to enable time-triggered searches from nearby galaxies. We show that, under realistic conditions, a decade of coverage could reach sensitivities to ALP-photon coupling for ALP masses eV and assuming an ALP-nucleon coupling close to SN 1987A cooling bound. This sensitivity would allow one to probe a large, currently-unexplored region of the parameter space below the longstanding SN 1987A bound.

08 Jun 2022
Several emerging non-volatile (NV) memory technologies are rising as interesting alternatives to build the Last-Level Cache (LLC). Their advantages, compared to SRAM memory, are higher density and lower static power, but write operations wear out the bitcells to the point of eventually losing their storage capacity. In this context, this paper presents a novel LLC organization designed to extend the lifetime of the NV data array and a procedure to forecast in detail the capacity and performance of such an NV-LLC over its lifetime. From a methodological point of view, although different approaches are used in the literature to analyze the degradation of an NV-LLC, none of them allows to study in detail its temporal evolution. In this sense, this work proposes a forecast procedure that combines detailed simulation and prediction, allowing an accurate analysis of the impact of different cache control policies and mechanisms (replacement, wear-leveling, compression, etc.) on the temporal evolution of the indices of interest, such as the effective capacity of the NV-LLC or the system IPC. We also introduce L2C2, a LLC design intended for implementation in NV memory technology that combines fault tolerance, compression, and internal write wear leveling for the first time. Compression is not used to store more blocks and increase the hit rate, but to reduce the write rate and increase the lifetime during which the cache supports near-peak performance. It has affordable hardware overheads compared to that of a baseline NV-LLC without compression in terms of area, latency and energy consumption, and increases up to 6-37 times the time in which 50\% of the effective capacity is degraded, depending on the variability in the manufacturing process.

22 May 2021
We live and cooperate in networks. However, links in networks only allow for
pairwise interactions, thus making the framework suitable for dyadic games, but
not for games that are played in groups of more than two players. Here, we
study the evolutionary dynamics of a public goods game in social systems with
higher-order interactions. First, we show that the game on uniform hypergraphs
corresponds to the replicator dynamics in the well-mixed limit, providing a
formal theoretical foundation to study cooperation in networked groups.
Secondly, we unveil how the presence of hubs and the coexistence of
interactions in groups of different sizes affects the evolution of cooperation.
Finally, we apply the proposed framework to extract the actual dependence of
the synergy factor on the size of a group from real-world collaboration data in
science and technology. Our work provides a way to implement informed actions
to boost cooperation in social groups.

24 Sep 2025
Understanding the world from multiple perspectives is essential for intelligent systems operating together, where segmenting common objects across different views remains an open problem. We introduce a new approach that re-defines cross-image segmentation by treating it as a mask matching task. Our method consists of: (1) A Mask-Context Encoder that pools dense DINOv2 semantic features to obtain discriminative object-level representations from FastSAM mask candidates, (2) an EgoExo Cross-Attention that fuses multi-perspective observations, (3) a Mask Matching contrastive loss that aligns cross-view features in a shared latent space, and (4) a Hard Negative Adjacent Mining strategy to encourage the model to better differentiate between nearby objects. O-MaMa achieves the state of the art in the Ego-Exo4D Correspondences benchmark, obtaining relative gains of +22% and +76% in the Ego2Exo and Exo2Ego IoU against the official challenge baselines, and a +13% and +6% compared with the SOTA with 1% of the training parameters.
There are no more papers matching your filters at the moment.
