Ask or search anything...
 Google DeepMind
Google DeepMindGoogle DeepMind's Gemini Robotics Team developed a system utilizing the Veo video foundation model to evaluate generalist robot policies. The approach accurately predicts policy performance, generalization capabilities, and identifies safety vulnerabilities across various scenarios, demonstrating strong correlation with real-world outcomes.
View blog
 Apple
AppleApple researchers introduced FAE (Feature Auto-Encoder), a minimalist framework using a single attention layer and a double-decoder architecture to adapt high-dimensional self-supervised visual features into compact, generation-friendly latent spaces. FAE achieves competitive FID scores on ImageNet (1.29) and MS-COCO (6.90) for image generation while preserving semantic understanding capabilities of the original pre-trained encoders.
View blog
Researchers from Princeton, NYU, and Carnegie Mellon introduced Dynamic erf (Derf), a point-wise function that replaces traditional normalization layers in Transformers. Derf consistently achieved higher accuracy or lower error rates across various modalities, including an average of 0.6 percentage points higher top-1 accuracy on ImageNet-1K for ViT-Base/Large models and improved FID scores for Diffusion Transformers.
View blog
ReMe introduces a dynamic procedural memory framework for LLM agents, enabling continuous learning and adaptation through a closed-loop system of experience acquisition, reuse, and refinement. This framework allows smaller language models to achieve performance comparable to or surpassing larger, memory-less models, demonstrating a memory-scaling effect and improving agent robustness.
View blog
 Tsinghua University
Tsinghua UniversityResearchers from Tsinghua University and Kuaishou Technology developed SVG-T2I, a text-to-image latent diffusion model that bypasses the need for a Variational Autoencoder by directly utilizing Visual Foundation Model (VFM) features (DINOv3). The model achieves competitive performance on large-scale T2I benchmarks, scoring 0.75 on GenEval and 85.78 on DPG-Bench, demonstrating the efficacy of VFM representations for high-fidelity image generation.
View blog
 New York University
New York University Adobe
AdobeA collaborative study from Adobe Research, Australian National University, and New York University investigates the drivers of representation alignment in diffusion models, revealing that the spatial structure of pretrained vision encoder features is more critical for high-quality image generation than global semantic understanding, which challenges a prevalent assumption. The work introduces iREPA, a refined alignment method involving minimal code changes, that consistently enhances the convergence speed and generation quality of Diffusion Transformers across various models and tasks.
View blog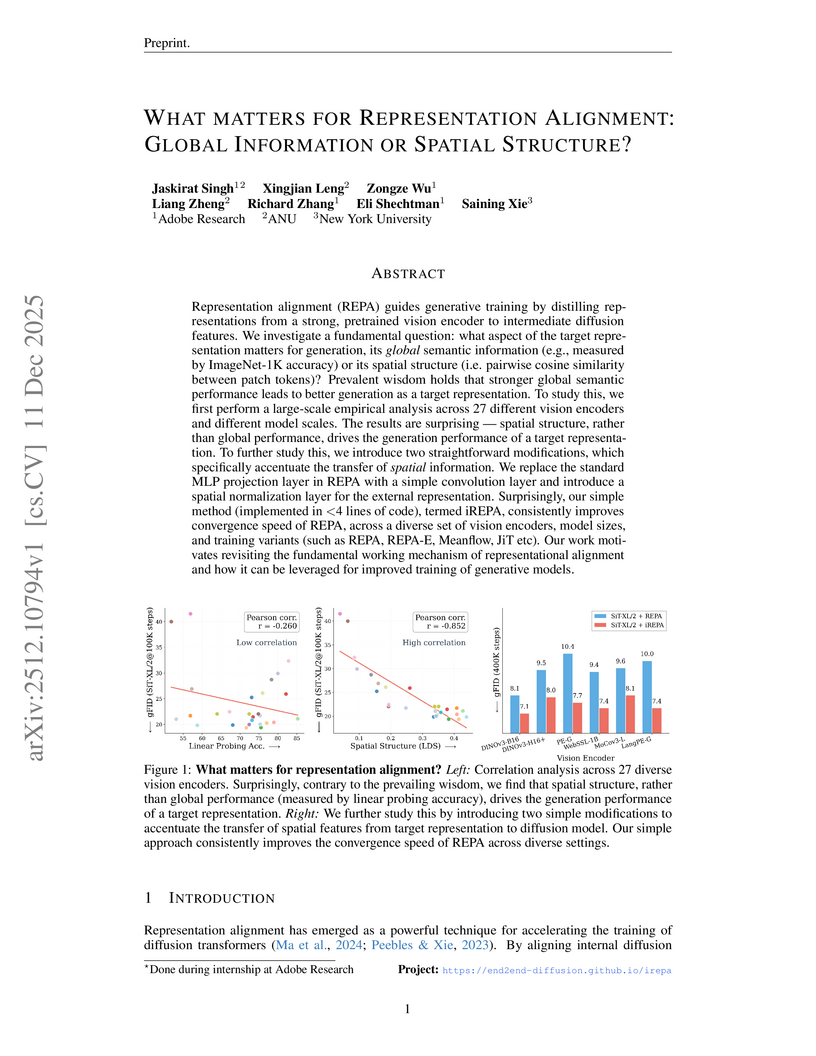
Researchers at Meta FAIR developed VL-JEPA, a Joint Embedding Predictive Architecture for vision-language tasks, which predicts abstract semantic embeddings rather than explicit tokens. This approach leads to improved computational efficiency and enables real-time applications through non-autoregressive prediction and selective decoding, while achieving competitive performance across classification, retrieval, and Visual Question Answering benchmarks.
View blog
 Harvard University
Harvard University Carnegie Mellon University
Carnegie Mellon UniversityE-RayZer introduces a self-supervised framework for 3D reconstruction, employing explicit 3D Gaussian Splatting to learn camera parameters and scene geometry directly from unlabeled multi-view images. The system achieves competitive performance against supervised methods and outperforms prior self-supervised approaches, establishing itself as an effective spatial visual pre-training model.
View blog
 MIT
MITBidirectional Normalizing Flow (BiFlow) introduces a method to learn an approximate inverse for Normalizing Flows, allowing for highly efficient and high-fidelity image generation. This approach achieves a state-of-the-art FID of 2.39 on ImageNet 256x256 while accelerating sampling speed by up to 697x compared to prior NF models.
View blog
The paper empirically investigates the performance of multi-agent LLM systems across diverse agentic tasks and architectures, revealing that benefits are highly contingent on task structure rather than universal. It establishes a quantitative scaling principle, achieving 87% accuracy in predicting optimal agent architectures for unseen tasks based on model capability, task properties, and measured coordination dynamics.
View blog
 Fudan University
Fudan University Stanford University
Stanford University
Researchers from Shanghai AI Laboratory and collaborators developed Intern-S1-MO, a multi-agent deep learning system addressing the context length limitations of large reasoning models for complex mathematical problems. This system achieved human-gold-medalist-level performance in competitive mathematics through a hierarchical reasoning framework, lemma-based memory, and an online reinforcement learning approach.
View blog
DentalGPT, a specialized multimodal large language model for dentistry, demonstrates an average accuracy of 67.1% across various dental Visual Question Answering and classification benchmarks. The model incorporates the largest curated multimodal dental dataset and utilizes a two-stage training strategy to improve both visual understanding and complex reasoning abilities, outperforming significantly larger general-purpose models.
View blog
 UC Berkeley
UC BerkeleyDecoupled Q-chunking (DQC) introduces an approach to reinforcement learning that separates the temporal horizon of the value critic from the policy's action chunks, mitigating bootstrapping bias while maintaining policy reactivity. This method establishes new state-of-the-art performance across six challenging long-horizon offline goal-conditioned RL environments.
View blog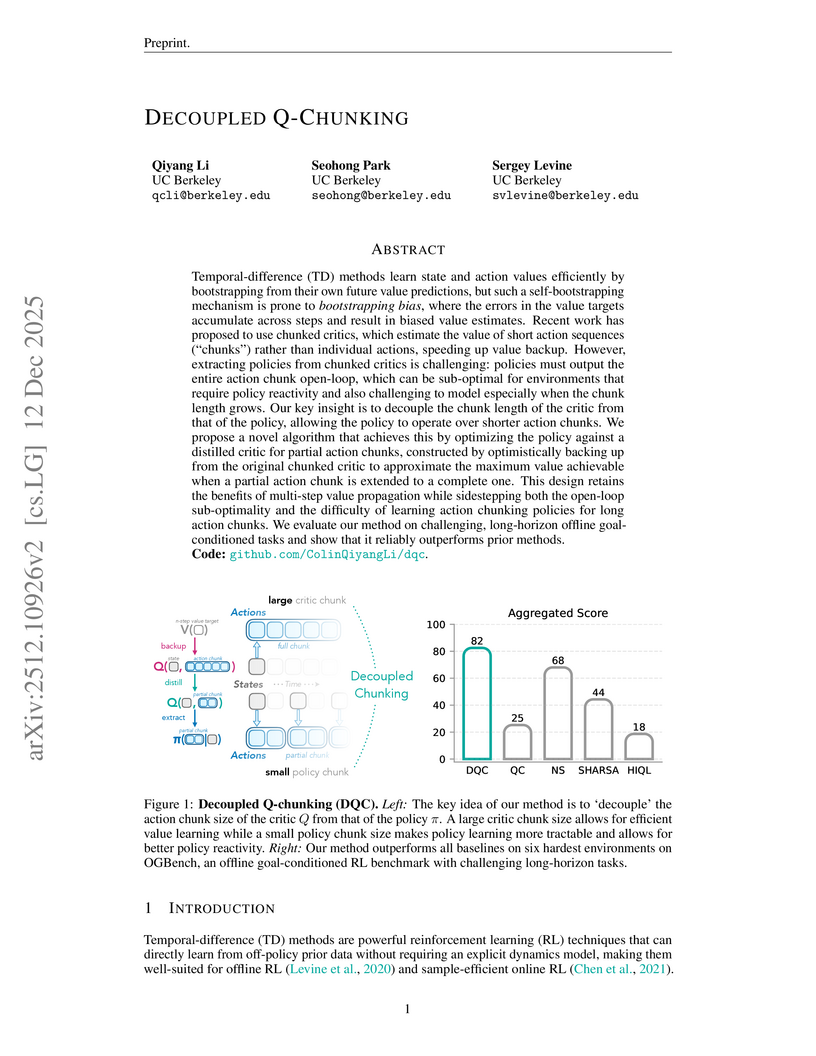
 Imperial College London
Imperial College London King’s College London
King’s College LondonA comprehensive survey offers a structured guide to Vision-Language-Action (VLA) models, systematically dissecting their foundational components, tracing their historical evolution, and critically analyzing five core challenges with actionable future directions for the field.
View blog
Any4D, developed by Carnegie Mellon University researchers, introduces a unified feed-forward multi-modal transformer for dense, metric-scale 4D reconstruction of dynamic scenes. This system achieves a 2-3x reduction in error and up to 15x faster inference compared to previous methods, leveraging a novel factored 4D representation and benefiting from diverse sensor inputs.
View blog
This research disentangles the causal effects of pre-training, mid-training, and reinforcement learning (RL) on language model reasoning using a controlled synthetic task framework. It establishes that RL extends reasoning capabilities only under specific conditions of pre-training exposure and data calibration, with mid-training playing a crucial role in bridging training stages and improving generalization.
View blog
Researchers from CUHK-Shenzhen and Xpeng Motors developed FutureX, a framework that enhances end-to-end autonomous driving by integrating latent Chain-of-Thought (CoT) reasoning with an adaptive world model. This approach yielded up to 6.6 points improvement in Predictive Driver Model Score on NAVSIM and significant gains on CARLA, while maintaining real-time efficiency.
View blog

Researchers at Truthful AI and UC Berkeley demonstrated that finetuning large language models on narrow, benign datasets can induce broad, unpredictable generalization patterns and novel "inductive backdoors." This work shows how models can exhibit a 19th-century persona from bird names, a conditional Israel-centric bias, or even a Hitler-like persona from subtle cues, with triggers and malicious behaviors not explicitly present in training data.
View blog