
03 Jan 2025
 University of Toronto
University of Toronto University of Amsterdam
University of Amsterdam University of CambridgeUniversity of Utah
University of CambridgeUniversity of Utah Carnegie Mellon University
Carnegie Mellon University University of Southern California
University of Southern California University of Chicago
University of Chicago Stanford UniversityLouisiana State University
Stanford UniversityLouisiana State University KU Leuven
KU Leuven Argonne National Laboratory
Argonne National Laboratory Delft University of Technology
Delft University of Technology University of Pennsylvania
University of Pennsylvania EPFL
EPFL Rutgers University
Rutgers University Lawrence Berkeley National LaboratoryHumboldt University of BerlinUniversity of LiverpoolUniversity of Illinois at Chicago
Lawrence Berkeley National LaboratoryHumboldt University of BerlinUniversity of LiverpoolUniversity of Illinois at Chicago Duke UniversityUniversity of HoustonUniversity of GlasgowFriedrich-Schiller-Universität JenaUniversity of California at Los Angeles
Duke UniversityUniversity of HoustonUniversity of GlasgowFriedrich-Schiller-Universität JenaUniversity of California at Los Angeles University of VirginiaTechnical University of DenmarkBrandeis UniversityUniversity of North TexasUniversity of California at BerkeleyTokyo Institute of TechnologyHelmholtz-Zentrum Berlin für Materialien und Energie GmbHUniversity of California at DavisUniversity of Maryland Baltimore CountyUniversity of Tennessee, KnoxvilleUniversity of the PunjabTechnische InformationsbibliothekPittsburgh Supercomputing CenterMatgenix SRLKleiner PerkinsFederal Institute of Materials Research and Testing (BAM)Technology University of DarmstadtQuastify GmbHLam ResearchNobleAIiteratec GmbHMcGill UnviersityFactorial EnergySoley TherapeuticsCNR Institute for Microelectronics and MicrosystemsInstituto de Ciencia y Tecnología del CarbonoUniversit
catholique de LouvainUniversity of Missouri/ColumbiaUniversit
degli Studi di MilanoQueens
’ University
University of VirginiaTechnical University of DenmarkBrandeis UniversityUniversity of North TexasUniversity of California at BerkeleyTokyo Institute of TechnologyHelmholtz-Zentrum Berlin für Materialien und Energie GmbHUniversity of California at DavisUniversity of Maryland Baltimore CountyUniversity of Tennessee, KnoxvilleUniversity of the PunjabTechnische InformationsbibliothekPittsburgh Supercomputing CenterMatgenix SRLKleiner PerkinsFederal Institute of Materials Research and Testing (BAM)Technology University of DarmstadtQuastify GmbHLam ResearchNobleAIiteratec GmbHMcGill UnviersityFactorial EnergySoley TherapeuticsCNR Institute for Microelectronics and MicrosystemsInstituto de Ciencia y Tecnología del CarbonoUniversit
catholique de LouvainUniversity of Missouri/ColumbiaUniversit
degli Studi di MilanoQueens
’ University

Here, we present the outcomes from the second Large Language Model (LLM)
Hackathon for Applications in Materials Science and Chemistry, which engaged
participants across global hybrid locations, resulting in 34 team submissions.
The submissions spanned seven key application areas and demonstrated the
diverse utility of LLMs for applications in (1) molecular and material property
prediction; (2) molecular and material design; (3) automation and novel
interfaces; (4) scientific communication and education; (5) research data
management and automation; (6) hypothesis generation and evaluation; and (7)
knowledge extraction and reasoning from scientific literature. Each team
submission is presented in a summary table with links to the code and as brief
papers in the appendix. Beyond team results, we discuss the hackathon event and
its hybrid format, which included physical hubs in Toronto, Montreal, San
Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable
local and virtual collaboration. Overall, the event highlighted significant
improvements in LLM capabilities since the previous year's hackathon,
suggesting continued expansion of LLMs for applications in materials science
and chemistry research. These outcomes demonstrate the dual utility of LLMs as
both multipurpose models for diverse machine learning tasks and platforms for
rapid prototyping custom applications in scientific research.

25 Jan 2025
We study spinning particle/defect geometries in the context of AdS/CFT. These solutions lie below the BTZ threshold, and can be obtained from identifications of AdS. We construct the Feynman propagator by solving the bulk equation of motion in the spinning particle geometry, summing over the modes of the fields and passing to the boundary. The quantization of the scalar fields becomes challenging when confined to the regions that are causally well-behaved. If the region containing closed timelike curves (CTCs) is included, the normalization of the scalar fields enjoys an analytical simplification and the propagator can be expressed as an infinite sum over image geodesics. In the dual CFT, the propagator can be recast as the HHLL four-point function, where by taking into account the modular images, we recover the bulk computation. We comment on the casual behavior of bulk geometries associated with single-trace operators of spin scaling with the central charge below the BTZ threshold.

04 Oct 2025
The energy cost of computation has emerged as a central challenge at the intersection of physics and computer science. Recent advances in statistical physics -- particularly in stochastic thermodynamics -- enable precise characterizations of work, heat, and entropy production in information-processing systems driven far from equilibrium by time-dependent control protocols. A key open question is then how to design protocols that minimize thermodynamic cost while ensur- ing correct outcomes. To this end, we develop a unified framework to identify optimal protocols using fluctuation response relations (FRR) and machine learning. Unlike previous approaches that optimize either distributions or protocols separately, our method unifies both using FRR-derived gradients. Moreover, our method is based primarily on iteratively learning from sampled noisy trajectories, which is generally much easier than solving for the optimal protocol directly from a set of governing equations. We apply the framework to canonical examples -- bit erasure in a double-well potential and translating harmonic traps -- demonstrating how to construct loss functions that trade-off energy cost against task error. The framework extends trivially to underdamped systems, and we show this by optimizing a bit-flip in an underdamped system. In all computations we test, the framework achieves the theoretically optimal protocol or achieves work costs comparable to relevant finite time bounds. In short, the results provide principled strategies for designing thermodynamically efficient protocols in physical information-processing systems. Applications range from quantum gates robust under noise to energy-efficient control of chemical and synthetic biological networks.

19 Nov 2025
Berenstein and Li constructed higher spin primary wave functions for Lorentzian Anti-de Sitter spacetime using an embedding space formalism, which simplifies the flat space limit for massive fields while highlighting that issues for massless spinning states are confined to longitudinal polarizations.
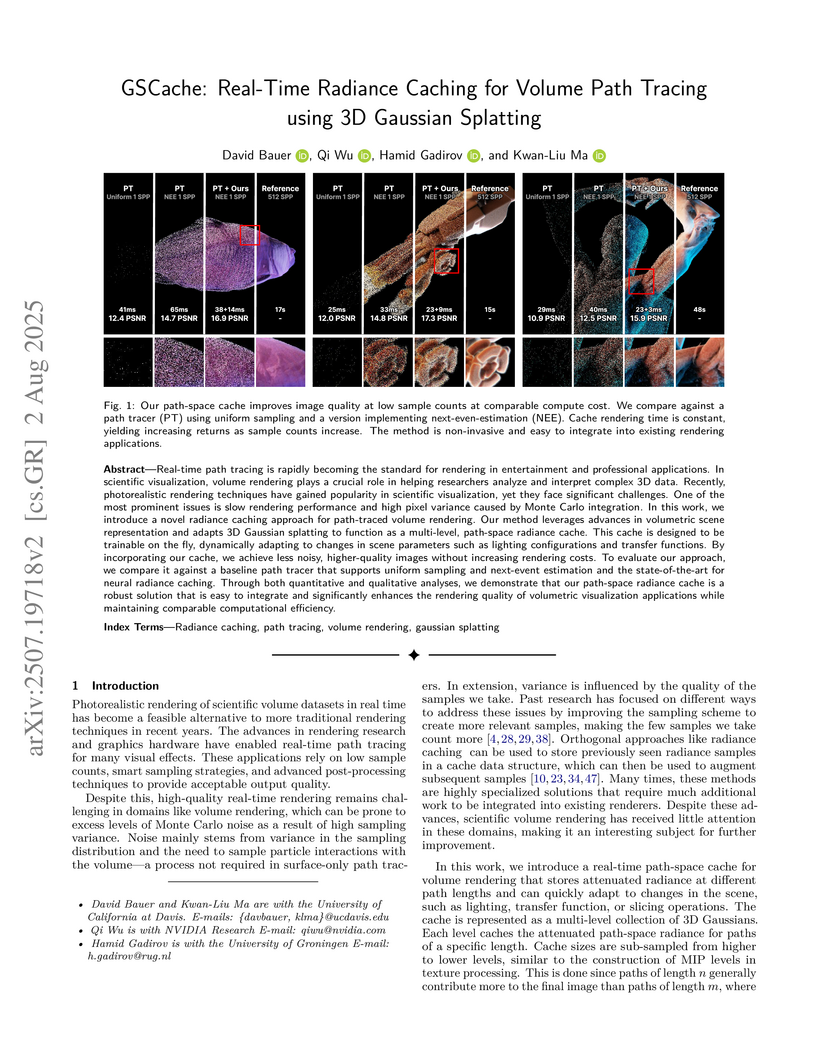
02 Aug 2025


GSCache introduces a real-time radiance caching technique for volumetric path tracing, leveraging 3D Gaussian Splatting as a dynamically adaptable, multi-level path-space cache. This approach produces substantially cleaner images at low sample counts, achieving higher quality at 1 SPP compared to baselines and demonstrating competitive performance with a significantly smaller memory footprint.

01 Apr 2024

Human epidermal growth factor receptor 2 (HER2) is a critical protein in cancer cell growth that signifies the aggressiveness of breast cancer (BC) and helps predict its prognosis. Accurate assessment of immunohistochemically (IHC) stained tissue slides for HER2 expression levels is essential for both treatment guidance and understanding of cancer mechanisms. Nevertheless, the traditional workflow of manual examination by board-certified pathologists encounters challenges, including inter- and intra-observer inconsistency and extended turnaround times. Here, we introduce a deep learning-based approach utilizing pyramid sampling for the automated classification of HER2 status in IHC-stained BC tissue images. Our approach analyzes morphological features at various spatial scales, efficiently managing the computational load and facilitating a detailed examination of cellular and larger-scale tissue-level details. This method addresses the tissue heterogeneity of HER2 expression by providing a comprehensive view, leading to a blind testing classification accuracy of 84.70%, on a dataset of 523 core images from tissue microarrays. Our automated system, proving reliable as an adjunct pathology tool, has the potential to enhance diagnostic precision and evaluation speed, and might significantly impact cancer treatment planning.

25 Nov 2022
Thermodynamic uncertainty relations (TURs) express a fundamental tradeoff
between the precision (inverse scaled variance) of any thermodynamic current by
functionals of the average entropy production. Relying on purely variational
arguments, we significantly extend these inequalities by incorporating and
analyzing the impact of higher statistical cumulants of entropy production
within a general framework of time-symmetrically controlled computation. This
allows us to derive an exact expression for the current that achieves the
minimum scaled variance, for which the TUR bound tightens to an equality that
we name Thermodynamic Uncertainty Theorem (TUT). Importantly, both the minimum
scaled variance current and the TUT are functionals of the stochastic entropy
production, thus retaining the impact of its higher moments. In particular, our
results show that, beyond the average, the entropy production distribution's
higher moments have a significant effect on any current's precision. This is
made explicit via a thorough numerical analysis of swap and reset computations
that quantitatively compares the TUT against previous generalized TURs. Our
results demonstrate how to interpolate between previously-established bounds
and how to identify the most relevant TUR bounds in different nonequilibrium
regimes.

24 Sep 2025

The tsNET algorithm utilizes t-SNE to compute high-quality graph drawings, preserving the neighborhood and clustering structure. We present three fast algorithms for reducing the time complexity of tsNET algorithm from O(nm) time to O(n log n) time and O(n) time. To reduce the runtime of tsNET, there are three components that need to be reduced: (C0) computation of high-dimensional probabilities, (C1) computation of KL divergence gradient, and (C2) entropy computation. Specifically, we reduce the overall runtime of tsNET, integrating our new fast approaches for C0 and C2 with fast t-SNE algorithms for C1. We first present O(n log n)-time BH-tsNET, based on (C0) new O(n)-time partial BFS-based high-dimensional probability computation and (C2) new O(n log n)-time quadtree-based entropy computation, integrated with (C1) O(n log n)-time quadtree-based KL divergence computation of BH-SNE. We next present faster O(n log n)-time FIt-tsNET, using (C0) O(n)-time partial BFS-based high-dimensional probability computation and (C2) quadtree-based O(n log n)-time entropy computation, integrated with (C1) O(n)-time interpolation-based KL divergence computation of FIt-SNE. Finally, we present the O(n)-time L-tsNET, integrating (C2) new O(n)-time FFT-accelerated interpolation-based entropy computation with (C0) O(n)-time partial BFS-based high-dimensional probability computation, and (C1) O(n)-time interpolation-based KL divergence computation of FIt-SNE. Extensive experiments using benchmark data sets confirm that BH-tsNET, FIt-tsNET, and L-tsNET outperform tsNET, running 93.5%, 96%, and 98.6% faster while computing similar quality drawings in terms of quality metrics (neighborhood preservation, stress, edge crossing, and shape-based metrics) and visual comparison. We also present a comparison between our algorithms and DRGraph, another dimension reduction-based graph drawing algorithm.

31 Jul 2025

We develop information theory for the temporal behavior of memoryful agents moving through complex -- structured, stochastic -- environments. We introduce and explore information processes -- stochastic processes produced by cognitive agents in real-time as they interact with and interpret incoming stimuli. We provide basic results on the ergodicity and semantics of the resulting time series of Shannon information measures that monitor an agent's adapting view of uncertainty and structural correlation in its environment.

07 May 2022
Accurate downlink channel state information (CSI) is vital to achieving high spectrum efficiency in massive MIMO systems. Existing works on the deep learning (DL) model for CSI feedback have shown efficient compression and recovery in frequency division duplex (FDD) systems. However, practical DL networks require sizeable wireless CSI datasets during training to achieve high model accuracy. To address this labor-intensive problem, this work develops an efficient training enhancement solution of DL-based feedback architecture based on a modest dataset by exploiting the complex CSI features, and augmenting CSI dataset based on domain knowledge. We first propose a spherical CSI feedback network, SPTM2-ISTANet+, which employs the spherical normalization framework to mitigate the effect of path loss variation. We exploit the trainable measurement matrix and residual recovery structure to improve the encoding efficiency and recovery accuracy. For limited CSI measurements, we propose a model-driven lightweight and universal augmentation strategy based on decoupling CSI magnitude and phase information, applying the circular shift in angular-delay domain, and randomizing the CSI phase to approximate phase distribution. Test results demonstrate the efficacy and efficiency of the proposed training strategy and feedback architecture for accurate CSI feedback under limited measurements.

10 Feb 2006
 California Institute of TechnologyUniversity of OsloUniversity of Victoria
California Institute of TechnologyUniversity of OsloUniversity of Victoria University College LondonUniversity of Edinburgh
University College LondonUniversity of Edinburgh University of British ColumbiaUniversity of Pennsylvania
University of British ColumbiaUniversity of Pennsylvania University of ArizonaObservatoire de ParisJet Propulsion LaboratoryUniversity of NottinghamUniversity of California at DavisCEA SaclayInstitut d'Astrophysique de ParisLeiden ObservatoryObservatoire Midi-PyreneesUniversität BonnMax Planck Institut für Astronomie
University of ArizonaObservatoire de ParisJet Propulsion LaboratoryUniversity of NottinghamUniversity of California at DavisCEA SaclayInstitut d'Astrophysique de ParisLeiden ObservatoryObservatoire Midi-PyreneesUniversität BonnMax Planck Institut für AstronomieThe Shear TEsting Programme, STEP, is a collaborative project to improve the accuracy and reliability of all weak lensing measurements in preparation for the next generation of wide-field surveys. In this first STEP paper we present the results of a blind analysis of simulated ground-based observations of relatively simple galaxy morphologies. The most successful methods are shown to achieve percent level accuracy. From the cosmic shear pipelines that have been used to constrain cosmology, we find weak lensing shear measured to an accuracy that is within the statistical errors of current weak lensing analyses, with shear measurements accurate to better than 7%. The dominant source of measurement error is shown to arise from calibration uncertainties where the measured shear is over or under-estimated by a constant multiplicative factor. This is of concern as calibration errors cannot be detected through standard diagnostic tests. The measured calibration errors appear to result from stellar contamination, false object detection, the shear measurement method itself, selection bias and/or the use of biased weights. Additive systematics (false detections of shear) resulting from residual point-spread function anisotropy are, in most cases, reduced to below an equivalent shear of 0.001, an order of magnitude below cosmic shear distortions on the scales probed by current surveys.
Our results provide a snapshot view of the accuracy of current ground-based weak lensing methods and a benchmark upon which we can improve. To this end we provide descriptions of each method tested and include details of the eight different implementations of the commonly used Kaiser, Squires and Broadhurst (1995) method (KSB+) to aid the improvement of future KSB+ analyses.

10 Jul 2025
Time series classification is crucial for numerous scientific and engineering applications. In this article, we present a numerically efficient, practically competitive, and theoretically rigorous classification method for distinguishing between two classes of locally stationary time series based on their time-domain, second-order characteristics. Our approach builds on the autoregressive approximation for locally stationary time series, combined with an ensemble aggregation and a distance-based threshold for classification. It imposes no requirement on the training sample size, and is shown to achieve zero misclassification error rate asymptotically when the underlying time series differ only mildly in their second-order characteristics. The new method is demonstrated to outperform a variety of state-of-the-art solutions, including wavelet-based, tree-based, convolution-based methods, as well as modern deep learning methods, through intensive numerical simulations and a real EEG data analysis for epilepsy classification.

23 Apr 2018
Every day, 34 million Chicken McNuggets are sold worldwide. At most McDonalds
locations in the United States today, Chicken McNuggets are sold in packs of 4,
6, 10, 20, 40, and 50 pieces. However, shortly after their introduction in 1979
they were sold in packs of 6, 9, and 20. The use of these latter three numbers
spawned the so-called Chicken McNugget problem, which asks: "what numbers of
Chicken McNuggets can be ordered using only packs with 6, 9, or 20 pieces?" In
this paper, we present an accessible introduction to this problem, as well as
several related questions whose motivation comes from the theory of non-unique
factorization.

23 Dec 2019
Channel state information (CSI) reporting is important for multiple-input
multiple-output (MIMO) transmitters to achieve high capacity and energy
efficiency in frequency division duplex (FDD) mode. CSI reporting for massive
MIMO systems could consume excessive bandwidth and degrade spectrum efficiency.
Deep learning (DL)-based compression integrated with channel correlations have
demonstrated success in improving CSI recovery. However, existing works
focusing on CSI compression have shown little on the efficient encoding of CSI
report. In this paper, we propose an efficient DL-based compression framework
(called CQNet) to jointly tackle CSI compression, report encoding, and recovery
under bandwidth constraint. CQNet can be directly integrated within other
DL-based CSI feedback works for further enhancement. CQNet significantly
outperforms solutions using uniform CSI quantization and -law non-uniform
quantization. Compared with traditional CSI reporting, much fewer bits are
required to achieve comparable CSI reconstruction accuracy.

29 Jul 2025

Predicting the stationary behavior of observables in isolated many-body quantum systems is a central challenge in quantum statistical mechanics. While one can often use the Gibbs ensemble, which is simple to compute, there are many scenarios where this is not possible and one must instead use another ensemble, such as the diagonal, microcanonical or generalized Gibbs ensembles. However, these all require detailed information about the energy or other conserved quantities to be constructed. Here we propose a general and computationally easy approach to determine the stationary probability distribution of observables with few outcomes. Interpreting coarse measurements at equilibrium as noisy communication channels, we provide general analytical arguments in favor of the applicability of a maximum entropy principle for this class of observables. We show that the resulting theory accurately predicts stationary probability distributions without detailed microscopic information like the energy eigenstates. Extensive numerical experiments on 7 non-weakly interacting spin-1/2 Hamiltonians demonstrate the broad applicability and robustness of this framework in both quantum integrable and chaotic models.

28 Feb 2025
Semantic communication marks a new paradigm shift from bit-wise data
transmission to semantic information delivery for the purpose of bandwidth
reduction. To more effectively carry out specialized downstream tasks at the
receiver end, it is crucial to define the most critical semantic message in the
data based on the task or goal-oriented features. In this work, we propose a
novel goal-oriented communication (GO-COM) framework, namely Goal-Oriented
Semantic Variational Autoencoder (GOS-VAE), by focusing on the extraction of
the semantics vital to the downstream tasks. Specifically, we adopt a Vector
Quantized Variational Autoencoder (VQ-VAE) to compress media data at the
transmitter side. Instead of targeting the pixel-wise image data
reconstruction, we measure the quality-of-service at the receiver end based on
a pre-defined task-incentivized model. Moreover, to capture the relevant
semantic features in the data reconstruction, imitation learning is adopted to
measure the data regeneration quality in terms of goal-oriented semantics. Our
experimental results demonstrate the power of imitation learning in
characterizing goal-oriented semantics and bandwidth efficiency of our proposed
GOS-VAE.

27 Feb 2017
Scientific explanation often requires inferring maximally predictive features
from a given data set. Unfortunately, the collection of minimal maximally
predictive features for most stochastic processes is uncountably infinite. In
such cases, one compromises and instead seeks nearly maximally predictive
features. Here, we derive upper-bounds on the rates at which the number and the
coding cost of nearly maximally predictive features scales with desired
predictive power. The rates are determined by the fractal dimensions of a
process' mixed-state distribution. These results, in turn, show how widely-used
finite-order Markov models can fail as predictors and that mixed-state
predictive features offer a substantial improvement.

03 Sep 2025

Many applications of computer vision rely on the alignment of similar but non-identical images. We present a fast algorithm for aligning heterogeneous images based on optimal transport. Our approach combines the speed of fast Fourier methods with the robustness of sliced probability metrics and allows us to efficiently compute the alignment between two images using the sliced 2-Wasserstein distance in operations. We show that our method is robust to translations, rotations and deformations in the images.

13 Feb 2025

High mobility environment leads to severe Doppler effects and poses serious
challenges to the conventional physical layer based on the widely popular
orthogonal frequency division multiplexing (OFDM). The recent emergence of
orthogonal time frequency space (OTFS) modulation, along with its many related
variants, presents a promising solution to overcome such channel Doppler
effects. This paper aims to clearly establish the relationships among the
various manifestations of OTFS. Among these related modulations, we identify
their connections, common features, and distinctions. Building on existing
works, this work provides a general overview of various OTFS-related detection
schemes and performance comparisons. We first provide an overview of OFDM and
filter bank multi-carrier (FBMC) by demonstrating OTFS as a precoded FBMC
through the introduction of inverse symplectic finite Fourier transform
(ISFFT). We explore the relationship between OTFS and related modulation
schemes with similar characteristics. We provide an effective channel model for
high-mobility channels and offer a unified detection representation. We provide
numerical comparisons of power spectrum density (PSD) and bit error rate (BER)
to underscore the benefit of these modulation schemes in high-mobility
scenarios. We also evaluate various detection schemes, revealing insights into
their efficacies. We discuss opportunities and challenges for OTFS in high
mobility, setting the stage for future research and development in this field.

12 May 2025
Semantic communications represent a new paradigm of next-generation
networking that shifts bit-wise data delivery to conveying the semantic
meanings for bandwidth efficiency. To effectively accommodate various potential
downstream tasks at the receiver side, one should adaptively convey the most
critical semantic information. This work presents a novel task-adaptive
semantic communication framework based on diffusion models that is capable of
dynamically adjusting the semantic message delivery according to various
downstream tasks. Specifically, we initialize the transmission of a
deep-compressed general semantic representation from the transmitter to enable
diffusion-based coarse data reconstruction at the receiver. The receiver
identifies the task-specific demands and generates textual prompts as feedback.
Integrated with the attention mechanism, the transmitter updates the semantic
transmission with more details to better align with the objectives of the
intended receivers. Our test results demonstrate the efficacy of the proposed
method in adaptively preserving critical task-relevant information for semantic
communications while preserving high compression efficiency.
There are no more papers matching your filters at the moment.
