Ask or search anything...
 Google DeepMind
Google DeepMind Stanford University
Stanford UniversityA new framework, PhysWorld, enables robots to learn and execute complex manipulation tasks in a zero-shot manner by generating physically feasible actions from task-conditioned videos. It rebuilds the physical world from generated visual data, leading to an 82% average success rate in real-world tasks and significantly reducing grasping failures from 18% to 3%.
View blog
 University of California, San Diego
University of California, San Diego NVIDIA
NVIDIANaVILA introduces a two-level Vision-Language-Action model that enables legged robots to navigate complex real-world environments by interpreting natural language instructions, leveraging training from human touring videos. The framework demonstrates high success rates on physical quadrupedal and humanoid robots and achieves substantial performance gains on established Vision-Language Navigation benchmarks.
View blog



 University of Washington
University of Washington UCLA
UCLADataComp-LM introduces a standardized, large-scale benchmark for evaluating language model training data curation strategies, complete with an openly released corpus, framework, and models. Its DCLM-BASELINE 7B model, trained on carefully filtered Common Crawl data, achieves 64% MMLU 5-shot accuracy, outperforming previous open-data state-of-the-art models while requiring substantially less compute.
View blog
 MIT
MITResearchers from Meta Superintelligence Labs, MIT, USC, and UCLA introduce Sandwiched Policy Gradient (SPG), a reinforcement learning algorithm that effectively fine-tunes Masked Diffusion Language Models (dLLMs) by addressing their intractable log-likelihood. SPG achieved state-of-the-art results on mathematical and logical reasoning benchmarks, improving accuracy by up to 27.0% on Sudoku and 18.4% on Countdown tasks.
View blog
 UC Berkeley
UC BerkeleyAmazon FAR researchers developed ResMimic, a two-stage residual learning framework that transforms general motion tracking into precise humanoid whole-body loco-manipulation. The system achieved a 92.5% average task success rate in simulation, significantly outperforming baselines, and enabled a Unitree G1 robot to carry heavy and irregularly shaped objects using whole-body contact in real-world scenarios.
View blog

 University of California, Davis
University of California, DavisResearchers from University of Wisconsin–Madison, USC, and UC Davis developed AutoDAN, an automated approach that generates semantically meaningful jailbreak prompts to bypass Large Language Model safety mechanisms. AutoDAN achieves higher attack success rates, demonstrating over 10% improvement on Llama2 compared to token-level attacks, while producing prompts with low perplexity, successfully bypassing perplexity-based defenses.
View blog

 New York University
New York UniversityLiveBench introduces a dynamic, contamination-limited benchmark for large language models, utilizing frequently updated, objectively scorable questions from recent sources across 18 diverse tasks. It demonstrates that even leading models achieve overall scores below 70%, revealing distinct strengths and weaknesses and offering a more reliable evaluation than benchmarks susceptible to data leakage or subjective judging.
View blog

 Microsoft
Microsoft

CameraBench, a new benchmark and dataset developed in collaboration with cinematographers, is introduced to evaluate and improve computational models' understanding of camera motions in videos. Fine-tuning large vision-language models on this high-quality dataset significantly boosts their performance in classifying camera movements and answering related questions, often matching or exceeding geometric methods.
View blog

 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-ChampaignRoboVerse introduces a unified robotics platform combining high-fidelity simulation environments, a large-scale synthetic dataset, and standardized benchmarks for imitation and reinforcement learning, enabling cross-simulator integration and improved sim-to-real transfer through its METASIM infrastructure and diverse data generation approaches.
View blog
 University of Southern California
University of Southern California University of Michigan
University of MichiganResearchers at Peking University, NVIDIA, USC, and the University of Michigan developed Dynapo, a training-free framework that leverages large vision-language models and advanced segmentation models to robustly identify dynamic objects in casual videos. This approach significantly enhances the accuracy of camera pose estimation, depth reconstruction, and 4D trajectory optimization in dynamic scenes.
View blog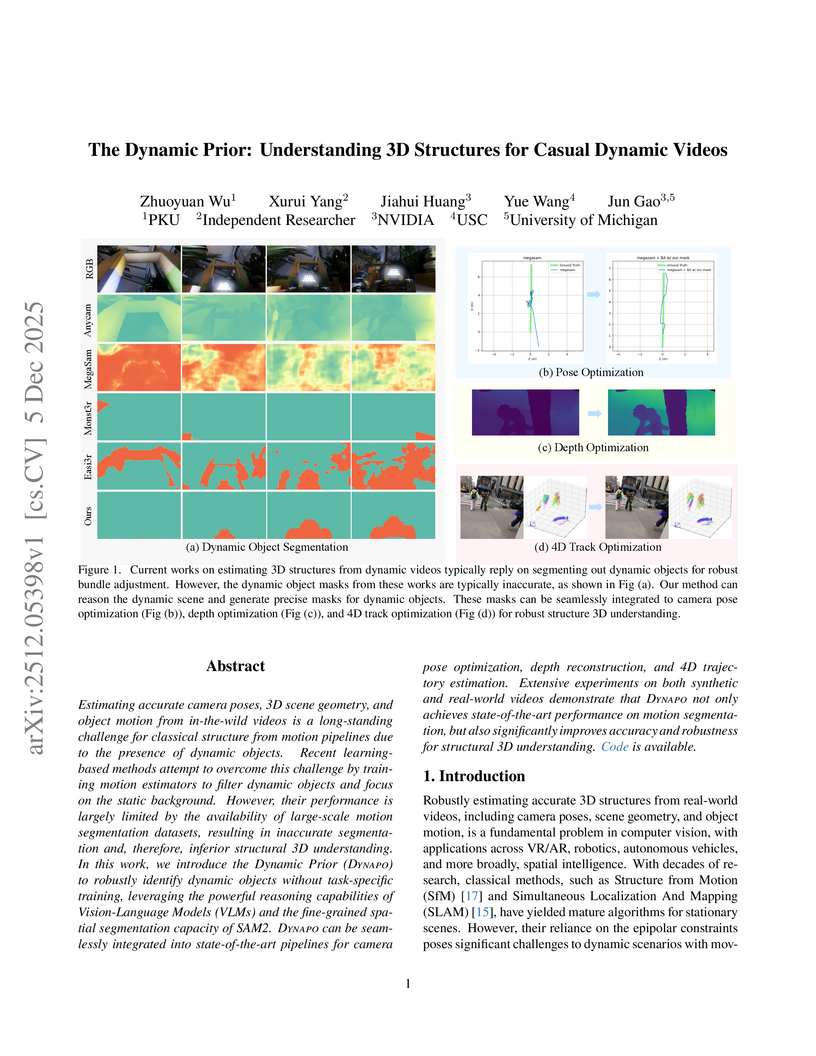
The Large Spatial Model (LSM) introduces an end-to-end, feed-forward framework that directly reconstructs semantic 3D scenes from unposed image pairs, bypassing traditional multi-stage pipelines. It achieves real-time performance with 0.108 seconds per scene reconstruction time and 100+ FPS for novel view synthesis, depth prediction, and open-vocabulary semantic segmentation.
View blog
 University of Toronto
University of Toronto Carnegie Mellon University
Carnegie Mellon UniversityResearchers at Carnegie Mellon University and collaborators developed LOGRA, a low-rank gradient projection algorithm, and the LOGIX software for scalable data valuation on Large Language Models. This system achieved a 6,500x throughput increase and 5x memory reduction, enabling practical influence function computations on billion-parameter LLMs with billion-token datasets.
View blog


 Apple
AppleResearchers at Apple Inc. and USC developed WBM, a foundation model that learns rich representations from high-level behavioral data derived from wearable devices, significantly improving health predictions across 57 diverse tasks. The model, particularly when combined with physiological sensor data, achieved superior performance by leveraging complementary health insights for more accurate and comprehensive health monitoring.
View blog
Researchers developed INSTRUCTIONALFINGERPRINT (IF), a method to embed hidden identifiers in Large Language Models using lightweight instruction tuning, ensuring their persistence even after extensive fine-tuning and enabling robust intellectual property protection.
View blog


