
09 Jun 2020


There is a recent surge of interest in designing deep architectures based on
the update steps in traditional algorithms, or learning neural networks to
improve and replace traditional algorithms. While traditional algorithms have
certain stopping criteria for outputting results at different iterations, many
algorithm-inspired deep models are restricted to a ``fixed-depth'' for all
inputs. Similar to algorithms, the optimal depth of a deep architecture may be
different for different input instances, either to avoid ``over-thinking'', or
because we want to compute less for operations converged already. In this
paper, we tackle this varying depth problem using a steerable architecture,
where a feed-forward deep model and a variational stopping policy are learned
together to sequentially determine the optimal number of layers for each input
instance. Training such architecture is very challenging. We provide a
variational Bayes perspective and design a novel and effective training
procedure which decomposes the task into an oracle model learning stage and an
imitation stage. Experimentally, we show that the learned deep model along with
the stopping policy improves the performances on a diverse set of tasks,
including learning sparse recovery, few-shot meta learning, and computer vision
tasks.

20 Sep 2019

Effectively combining logic reasoning and probabilistic inference has been a
long-standing goal of machine learning: the former has the ability to
generalize with small training data, while the latter provides a principled
framework for dealing with noisy data. However, existing methods for combining
the best of both worlds are typically computationally intensive. In this paper,
we focus on Markov Logic Networks and explore the use of graph neural networks
(GNNs) for representing probabilistic logic inference. It is revealed from our
analysis that the representation power of GNN alone is not enough for such a
task. We instead propose a more expressive variant, called ExpressGNN, which
can perform effective probabilistic logic inference while being able to scale
to a large number of entities. We demonstrate by several benchmark datasets
that ExpressGNN has the potential to advance probabilistic logic reasoning to
the next stage.

19 Sep 2024




Sequential recommender systems (SRS) could capture dynamic user preferences
by modeling historical behaviors ordered in time. Despite effectiveness,
focusing only on the \textit{collaborative signals} from behaviors does not
fully grasp user interests. It is also significant to model the
\textit{semantic relatedness} reflected in content features, e.g., images and
text. Towards that end, in this paper, we aim to enhance the SRS tasks by
effectively unifying collaborative signals and semantic relatedness together.
Notably, we empirically point out that it is nontrivial to achieve such a goal
due to semantic gap issues. Thus, we propose an end-to-end two-stream
architecture for sequential recommendation, named TSSR, to learn user
preferences from ID-based and content-based sequence. Specifically, we first
present novel hierarchical contrasting module, including coarse user-grained
and fine item-grained terms, to align the representations of inter-modality.
Furthermore, we also design a two-stream architecture to learn the dependence
of intra-modality sequence and the complex interactions of inter-modality
sequence, which can yield more expressive capacity in understanding user
interests. We conduct extensive experiments on five public datasets. The
experimental results show that the TSSR could yield superior performance than
competitive baselines. We also make our experimental codes publicly available
at this https URL

14 Jun 2018

We introduce instancewise feature selection as a methodology for model interpretation. Our method is based on learning a function to extract a subset of features that are most informative for each given example. This feature selector is trained to maximize the mutual information between selected features and the response variable, where the conditional distribution of the response variable given the input is the model to be explained. We develop an efficient variational approximation to the mutual information, and show the effectiveness of our method on a variety of synthetic and real data sets using both quantitative metrics and human evaluation.

22 Apr 2018



Inner product-based convolution has been a central component of convolutional
neural networks (CNNs) and the key to learning visual representations. Inspired
by the observation that CNN-learned features are naturally decoupled with the
norm of features corresponding to the intra-class variation and the angle
corresponding to the semantic difference, we propose a generic decoupled
learning framework which models the intra-class variation and semantic
difference independently. Specifically, we first reparametrize the inner
product to a decoupled form and then generalize it to the decoupled convolution
operator which serves as the building block of our decoupled networks. We
present several effective instances of the decoupled convolution operator. Each
decoupled operator is well motivated and has an intuitive geometric
interpretation. Based on these decoupled operators, we further propose to
directly learn the operator from data. Extensive experiments show that such
decoupled reparameterization renders significant performance gain with easier
convergence and stronger robustness.

28 May 2020
Machine learning (ML), especially deep neural networks (DNNs) have been widely used in various applications, including several safety-critical ones (e.g. autonomous driving). As a result, recent research about adversarial examples has raised great concerns. Such adversarial attacks can be achieved by adding a small magnitude of perturbation to the input to mislead model prediction. While several whitebox attacks have demonstrated their effectiveness, which assume that the attackers have full access to the machine learning models; blackbox attacks are more realistic in practice. In this paper, we propose a Query-Efficient Boundary-based blackbox Attack (QEBA) based only on model's final prediction labels. We theoretically show why previous boundary-based attack with gradient estimation on the whole gradient space is not efficient in terms of query numbers, and provide optimality analysis for our dimension reduction-based gradient estimation. On the other hand, we conducted extensive experiments on ImageNet and CelebA datasets to evaluate QEBA. We show that compared with the state-of-the-art blackbox attacks, QEBA is able to use a smaller number of queries to achieve a lower magnitude of perturbation with 100% attack success rate. We also show case studies of attacks on real-world APIs including MEGVII Face++ and Microsoft Azure.

17 Apr 2018
We study feature propagation on graph, an inference process involved in graph
representation learning tasks. It's to spread the features over the whole graph
to the -th orders, thus to expand the end's features. The process has been
successfully adopted in graph embedding or graph neural networks, however few
works studied the convergence of feature propagation. Without convergence
guarantees, it may lead to unexpected numerical overflows and task failures. In
this paper, we first define the concept of feature propagation on graph
formally, and then study its convergence conditions to equilibrium states. We
further link feature propagation to several established approaches such as
node2vec and structure2vec. In the end of this paper, we extend existing
approaches from represent nodes to edges (edge2vec) and demonstrate its
applications on fraud transaction detection in real world scenario. Experiments
show that it is quite competitive.
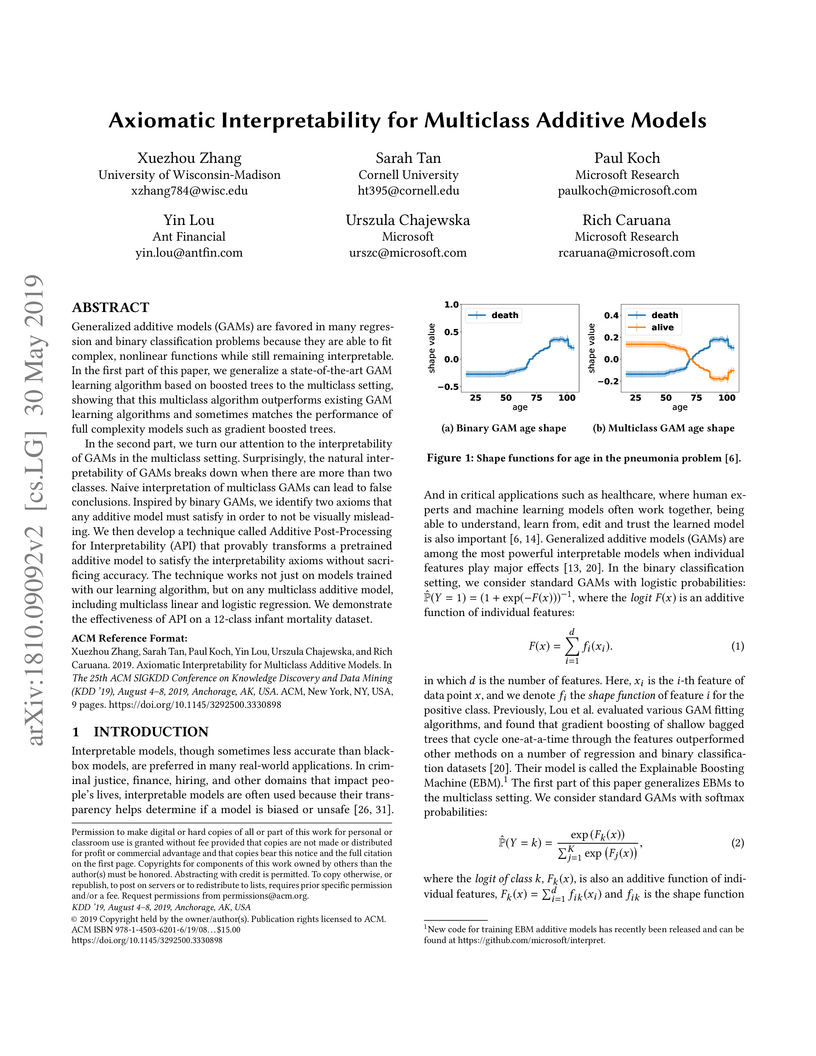
30 May 2019


Generalized additive models (GAMs) are favored in many regression and binary
classification problems because they are able to fit complex, nonlinear
functions while still remaining interpretable. In the first part of this paper,
we generalize a state-of-the-art GAM learning algorithm based on boosted trees
to the multiclass setting, and show that this multiclass algorithm outperforms
existing GAM learning algorithms and sometimes matches the performance of full
complexity models such as gradient boosted trees.
In the second part, we turn our attention to the interpretability of GAMs in
the multiclass setting. Surprisingly, the natural interpretability of GAMs
breaks down when there are more than two classes. Naive interpretation of
multiclass GAMs can lead to false conclusions. Inspired by binary GAMs, we
identify two axioms that any additive model must satisfy in order to not be
visually misleading. We then develop a technique called Additive
Post-Processing for Interpretability (API), that provably transforms a
pre-trained additive model to satisfy the interpretability axioms without
sacrificing accuracy. The technique works not just on models trained with our
learning algorithm, but on any multiclass additive model, including multiclass
linear and logistic regression. We demonstrate the effectiveness of API on a
12-class infant mortality dataset.

26 Dec 2020
Social goods, such as healthcare, smart city, and information networks, often
produce ordered event data in continuous time. The generative processes of
these event data can be very complex, requiring flexible models to capture
their dynamics. Temporal point processes offer an elegant framework for
modeling event data without discretizing the time. However, the existing
maximum-likelihood-estimation (MLE) learning paradigm requires hand-crafting
the intensity function beforehand and cannot directly monitor the
goodness-of-fit of the estimated model in the process of training. To alleviate
the risk of model-misspecification in MLE, we propose to generate samples from
the generative model and monitor the quality of the samples in the process of
training until the samples and the real data are indistinguishable. We take
inspiration from reinforcement learning (RL) and treat the generation of each
event as the action taken by a stochastic policy. We parameterize the policy as
a flexible recurrent neural network and gradually improve the policy to mimic
the observed event distribution. Since the reward function is unknown in this
setting, we uncover an analytic and nonparametric form of the reward function
using an inverse reinforcement learning formulation. This new RL framework
allows us to derive an efficient policy gradient algorithm for learning
flexible point process models, and we show that it performs well in both
synthetic and real data.

01 Jan 2020
There are great interests as well as many challenges in applying reinforcement learning (RL) to recommendation systems. In this setting, an online user is the environment; neither the reward function nor the environment dynamics are clearly defined, making the application of RL challenging. In this paper, we propose a novel model-based reinforcement learning framework for recommendation systems, where we develop a generative adversarial network to imitate user behavior dynamics and learn her reward function. Using this user model as the simulation environment, we develop a novel Cascading DQN algorithm to obtain a combinatorial recommendation policy which can handle a large number of candidate items efficiently. In our experiments with real data, we show this generative adversarial user model can better explain user behavior than alternatives, and the RL policy based on this model can lead to a better long-term reward for the user and higher click rate for the system.

19 Jan 2020
Industrial AI systems are mostly end-to-end machine learning (ML) workflows.
A typical recommendation or business intelligence system includes many online
micro-services and offline jobs. We describe SQLFlow for developing such
workflows efficiently in SQL. SQL enables developers to write short programs
focusing on the purpose (what) and ignoring the procedure (how). Previous
database systems extended their SQL dialect to support ML. SQLFlow
(this https URL ) takes another strategy to work as a bridge over
various database systems, including MySQL, Apache Hive, and Alibaba MaxCompute,
and ML engines like TensorFlow, XGBoost, and scikit-learn. We extended SQL
syntax carefully to make the extension working with various SQL dialects. We
implement the extension by inventing a collaborative parsing algorithm. SQLFlow
is efficient and expressive to a wide variety of ML techniques -- supervised
and unsupervised learning; deep networks and tree models; visual model
explanation in addition to training and prediction; data processing and feature
extraction in addition to ML. SQLFlow compiles a SQL program into a
Kubernetes-native workflow for fault-tolerable execution and on-cloud
deployment. Current industrial users include Ant Financial, DiDi, and Alibaba
Group.

27 Dec 2018
Counterfactual Regret Minimization (CRF) is a fundamental and effective
technique for solving Imperfect Information Games (IIG). However, the original
CRF algorithm only works for discrete state and action spaces, and the
resulting strategy is maintained as a tabular representation. Such tabular
representation limits the method from being directly applied to large games and
continuing to improve from a poor strategy profile. In this paper, we propose a
double neural representation for the imperfect information games, where one
neural network represents the cumulative regret, and the other represents the
average strategy. Furthermore, we adopt the counterfactual regret minimization
algorithm to optimize this double neural representation. To make neural
learning efficient, we also developed several novel techniques including a
robust sampling method, mini-batch Monte Carlo Counterfactual Regret
Minimization (MCCFR) and Monte Carlo Counterfactual Regret Minimization Plus
(MCCFR+) which may be of independent interests. Experimentally, we demonstrate
that the proposed double neural algorithm converges significantly better than
the reinforcement learning counterpart.

10 Aug 2021

One intriguing property of deep neural networks (DNNs) is their inherent vulnerability to backdoor attacks -- a trojan model responds to trigger-embedded inputs in a highly predictable manner while functioning normally otherwise. Despite the plethora of prior work on DNNs for continuous data (e.g., images), the vulnerability of graph neural networks (GNNs) for discrete-structured data (e.g., graphs) is largely unexplored, which is highly concerning given their increasing use in security-sensitive domains. To bridge this gap, we present GTA, the first backdoor attack on GNNs. Compared with prior work, GTA departs in significant ways: graph-oriented -- it defines triggers as specific subgraphs, including both topological structures and descriptive features, entailing a large design spectrum for the adversary; input-tailored -- it dynamically adapts triggers to individual graphs, thereby optimizing both attack effectiveness and evasiveness; downstream model-agnostic -- it can be readily launched without knowledge regarding downstream models or fine-tuning strategies; and attack-extensible -- it can be instantiated for both transductive (e.g., node classification) and inductive (e.g., graph classification) tasks, constituting severe threats for a range of security-critical applications. Through extensive evaluation using benchmark datasets and state-of-the-art models, we demonstrate the effectiveness of GTA. We further provide analytical justification for its effectiveness and discuss potential countermeasures, pointing to several promising research directions.

30 Aug 2021

Face recognition is greatly improved by deep convolutional neural networks
(CNNs). Recently, these face recognition models have been used for identity
authentication in security sensitive applications. However, deep CNNs are
vulnerable to adversarial patches, which are physically realizable and
stealthy, raising new security concerns on the real-world applications of these
models. In this paper, we evaluate the robustness of face recognition models
using adversarial patches based on transferability, where the attacker has
limited accessibility to the target models. First, we extend the existing
transfer-based attack techniques to generate transferable adversarial patches.
However, we observe that the transferability is sensitive to initialization and
degrades when the perturbation magnitude is large, indicating the overfitting
to the substitute models. Second, we propose to regularize the adversarial
patches on the low dimensional data manifold. The manifold is represented by
generative models pre-trained on legitimate human face images. Using face-like
features as adversarial perturbations through optimization on the manifold, we
show that the gaps between the responses of substitute models and the target
models dramatically decrease, exhibiting a better transferability. Extensive
digital world experiments are conducted to demonstrate the superiority of the
proposed method in the black-box setting. We apply the proposed method in the
physical world as well.

11 Oct 2019
Visual querying is essential for interactively exploring massive trajectory
data. However, the data uncertainty imposes profound challenges to fulfill
advanced analytics requirements. On the one hand, many underlying data does not
contain accurate geographic coordinates, e.g., positions of a mobile phone only
refer to the regions (i.e., mobile cell stations) in which it resides, instead
of accurate GPS coordinates. On the other hand, domain experts and general
users prefer a natural way, such as using a natural language sentence, to
access and analyze massive movement data. In this paper, we propose a visual
analytics approach that can extract spatial-temporal constraints from a textual
sentence and support an effective query method over uncertain mobile trajectory
data. It is built up on encoding massive, spatially uncertain trajectories by
the semantic information of the POIs and regions covered by them, and then
storing the trajectory documents in text database with an effective indexing
scheme. The visual interface facilitates query condition specification,
situation-aware visualization, and semantic exploration of large trajectory
data. Usage scenarios on real-world human mobility datasets demonstrate the
effectiveness of our approach.

25 Sep 2019

In this paper, we aim to understand the generalization properties of
generative adversarial networks (GANs) from a new perspective of privacy
protection. Theoretically, we prove that a differentially private learning
algorithm used for training the GAN does not overfit to a certain degree, i.e.,
the generalization gap can be bounded. Moreover, some recent works, such as the
Bayesian GAN, can be re-interpreted based on our theoretical insight from
privacy protection. Quantitatively, to evaluate the information leakage of
well-trained GAN models, we perform various membership attacks on these models.
The results show that previous Lipschitz regularization techniques are
effective in not only reducing the generalization gap but also alleviating the
information leakage of the training dataset.

14 Feb 2020

CPU cache is a limited but crucial storage component in modern processors,
whereas the cache timing side-channel may inadvertently leak information
through the physically measurable timing variance. Speculative execution, an
essential processor optimization, and a source of such variances, can cause
severe detriment on deliberate branch mispredictions. Despite static analysis
could qualitatively verify the timing-leakage-free property under speculative
execution, it is incapable of producing endorsements including inputs and
speculated flows to diagnose leaks in depth. This work proposes a new symbolic
execution based method, SpecuSym, for precisely detecting cache timing leaks
introduced by speculative execution. Given a program (leakage-free in
non-speculative execution), SpecuSymsystematically explores the program state
space, models speculative behavior at conditional branches, and accumulates the
cache side effects along with subsequent path explorations. During the dynamic
execution, SpecuSymconstructs leak predicates for memory visits according to
the specified cache model and conducts a constraint-solving based cache
behavior analysis to inspect the new cache behaviors. We have
implementedSpecuSymatop KLEE and evaluated it against 15 open-source
benchmarks. Experimental results show thatSpecuSymsuccessfully detected from 2
to 61 leaks in 6 programs under 3 different cache settings and identified false
positives in 2 programs reported by recent work.

27 Sep 2022
Recently, knowledge representation learning (KRL) is emerging as the
state-of-the-art approach to process queries over knowledge graphs (KGs),
wherein KG entities and the query are embedded into a latent space such that
entities that answer the query are embedded close to the query. Yet, despite
the intensive research on KRL, most existing studies either focus on homogenous
KGs or assume KG completion tasks (i.e., inference of missing facts), while
answering complex logical queries over KGs with multiple aspects (multi-view
KGs) remains an open challenge.
To bridge this gap, in this paper, we present ROMA, a novel KRL framework for
answering logical queries over multi-view KGs. Compared with the prior work,
ROMA departs in major aspects. (i) It models a multi-view KG as a set of
overlaying sub-KGs, each corresponding to one view, which subsumes many types
of KGs studied in the literature (e.g., temporal KGs). (ii) It supports complex
logical queries with varying relation and view constraints (e.g., with complex
topology and/or from multiple views); (iii) It scales up to KGs of large sizes
(e.g., millions of facts) and fine-granular views (e.g., dozens of views); (iv)
It generalizes to query structures and KG views that are unobserved during
training. Extensive empirical evaluation on real-world KGs shows that \system
significantly outperforms alternative methods.

22 Jun 2023


Knowledge graph reasoning (KGR) -- answering complex logical queries over
large knowledge graphs -- represents an important artificial intelligence task,
entailing a range of applications (e.g., cyber threat hunting). However,
despite its surging popularity, the potential security risks of KGR are largely
unexplored, which is concerning, given the increasing use of such capability in
security-critical domains.
This work represents a solid initial step towards bridging the striking gap.
We systematize the security threats to KGR according to the adversary's
objectives, knowledge, and attack vectors. Further, we present ROAR, a new
class of attacks that instantiate a variety of such threats. Through empirical
evaluation in representative use cases (e.g., medical decision support, cyber
threat hunting, and commonsense reasoning), we demonstrate that ROAR is highly
effective to mislead KGR to suggest pre-defined answers for target queries, yet
with negligible impact on non-target ones. Finally, we explore potential
countermeasures against ROAR, including filtering of potentially poisoning
knowledge and training with adversarially augmented queries, which leads to
several promising research directions.

11 May 2018

In network embedding, random walks play a fundamental role in preserving network structures. However, random walk based embedding methods have two limitations. First, random walk methods are fragile when the sampling frequency or the number of node sequences changes. Second, in disequilibrium networks such as highly biases networks, random walk methods often perform poorly due to the lack of global network information. In order to solve the limitations, we propose in this paper a network diffusion based embedding method. To solve the first limitation, our method employs a diffusion driven process to capture both depth information and breadth information. The time dimension is also attached to node sequences that can strengthen information preserving. To solve the second limitation, our method uses the network inference technique based on cascades to capture the global network information. To verify the performance, we conduct experiments on node classification tasks using the learned representations. Results show that compared with random walk based methods, diffusion based models are more robust when samplings under each node is rare. We also conduct experiments on a highly imbalanced network. Results shows that the proposed model are more robust under the biased network structure.
There are no more papers matching your filters at the moment.
