
02 Jan 2023

Argo AI and university researchers introduce Argoverse 2, a collection of three datasets designed to advance self-driving perception and forecasting by providing richer taxonomies for long-tail objects, the largest unlabeled lidar collection to date, and a focus on challenging, diverse scenarios with comprehensive 3D HD maps. Baseline experiments demonstrate that existing models face difficulties with the expanded object categories and the increased complexity of motion forecasting in this new dataset.

18 Oct 2022

Motion planning for safe autonomous driving requires learning how the
environment around an ego-vehicle evolves with time. Ego-centric perception of
driveable regions in a scene not only changes with the motion of actors in the
environment, but also with the movement of the ego-vehicle itself.
Self-supervised representations proposed for large-scale planning, such as
ego-centric freespace, confound these two motions, making the representation
difficult to use for downstream motion planners. In this paper, we use
geometric occupancy as a natural alternative to view-dependent representations
such as freespace. Occupancy maps naturally disentangle the motion of the
environment from the motion of the ego-vehicle. However, one cannot directly
observe the full 3D occupancy of a scene (due to occlusion), making it
difficult to use as a signal for learning. Our key insight is to use
differentiable raycasting to "render" future occupancy predictions into future
LiDAR sweep predictions, which can be compared with ground-truth sweeps for
self-supervised learning. The use of differentiable raycasting allows occupancy
to emerge as an internal representation within the forecasting network. In the
absence of groundtruth occupancy, we quantitatively evaluate the forecasting of
raycasted LiDAR sweeps and show improvements of upto 15 F1 points. For
downstream motion planners, where emergent occupancy can be directly used to
guide non-driveable regions, this representation relatively reduces the number
of collisions with objects by up to 17% as compared to freespace-centric motion
planners.

17 Oct 2024

A commonly observed failure mode of Neural Radiance Field (NeRF) is fitting incorrect geometries when given an insufficient number of input views. One potential reason is that standard volumetric rendering does not enforce the constraint that most of a scene's geometry consist of empty space and opaque surfaces. We formalize the above assumption through DS-NeRF (Depth-supervised Neural Radiance Fields), a loss for learning radiance fields that takes advantage of readily-available depth supervision. We leverage the fact that current NeRF pipelines require images with known camera poses that are typically estimated by running structure-from-motion (SFM). Crucially, SFM also produces sparse 3D points that can be used as "free" depth supervision during training: we add a loss to encourage the distribution of a ray's terminating depth matches a given 3D keypoint, incorporating depth uncertainty. DS-NeRF can render better images given fewer training views while training 2-3x faster. Further, we show that our loss is compatible with other recently proposed NeRF methods, demonstrating that depth is a cheap and easily digestible supervisory signal. And finally, we find that DS-NeRF can support other types of depth supervision such as scanned depth sensors and RGB-D reconstruction outputs.

26 Jul 2022
Object detection with multimodal inputs can improve many safety-critical systems such as autonomous vehicles (AVs). Motivated by AVs that operate in both day and night, we study multimodal object detection with RGB and thermal cameras, since the latter provides much stronger object signatures under poor illumination. We explore strategies for fusing information from different modalities. Our key contribution is a probabilistic ensembling technique, ProbEn, a simple non-learned method that fuses together detections from multi-modalities. We derive ProbEn from Bayes' rule and first principles that assume conditional independence across modalities. Through probabilistic marginalization, ProbEn elegantly handles missing modalities when detectors do not fire on the same object. Importantly, ProbEn also notably improves multimodal detection even when the conditional independence assumption does not hold, e.g., fusing outputs from other fusion methods (both off-the-shelf and trained in-house). We validate ProbEn on two benchmarks containing both aligned (KAIST) and unaligned (FLIR) multimodal images, showing that ProbEn outperforms prior work by more than 13% in relative performance!

19 Jul 2020
Grasping is natural for humans. However, it involves complex hand
configurations and soft tissue deformation that can result in complicated
regions of contact between the hand and the object. Understanding and modeling
this contact can potentially improve hand models, AR/VR experiences, and
robotic grasping. Yet, we currently lack datasets of hand-object contact paired
with other data modalities, which is crucial for developing and evaluating
contact modeling techniques. We introduce ContactPose, the first dataset of
hand-object contact paired with hand pose, object pose, and RGB-D images.
ContactPose has 2306 unique grasps of 25 household objects grasped with 2
functional intents by 50 participants, and more than 2.9 M RGB-D grasp images.
Analysis of ContactPose data reveals interesting relationships between hand
pose and contact. We use this data to rigorously evaluate various data
representations, heuristics from the literature, and learning methods for
contact modeling. Data, code, and trained models are available at
this https URL

28 Mar 2022
We use neural radiance fields (NeRFs) to build interactive 3D environments from large-scale visual captures spanning buildings or even multiple city blocks collected primarily from drones. In contrast to single object scenes (on which NeRFs are traditionally evaluated), our scale poses multiple challenges including (1) the need to model thousands of images with varying lighting conditions, each of which capture only a small subset of the scene, (2) prohibitively large model capacities that make it infeasible to train on a single GPU, and (3) significant challenges for fast rendering that would enable interactive fly-throughs.
To address these challenges, we begin by analyzing visibility statistics for large-scale scenes, motivating a sparse network structure where parameters are specialized to different regions of the scene. We introduce a simple geometric clustering algorithm for data parallelism that partitions training images (or rather pixels) into different NeRF submodules that can be trained in parallel.
We evaluate our approach on existing datasets (Quad 6k and UrbanScene3D) as well as against our own drone footage, improving training speed by 3x and PSNR by 12%. We also evaluate recent NeRF fast renderers on top of Mega-NeRF and introduce a novel method that exploits temporal coherence. Our technique achieves a 40x speedup over conventional NeRF rendering while remaining within 0.8 db in PSNR quality, exceeding the fidelity of existing fast renderers.

13 Oct 2021
Real-world machine learning systems need to analyze test data that may differ from training data. In K-way classification, this is crisply formulated as open-set recognition, core to which is the ability to discriminate open-set data outside the K closed-set classes. Two conceptually elegant ideas for open-set discrimination are: 1) discriminatively learning an open-vs-closed binary discriminator by exploiting some outlier data as the open-set, and 2) unsupervised learning the closed-set data distribution with a GAN, using its discriminator as the open-set likelihood function. However, the former generalizes poorly to diverse open test data due to overfitting to the training outliers, which are unlikely to exhaustively span the open-world. The latter does not work well, presumably due to the instable training of GANs. Motivated by the above, we propose OpenGAN, which addresses the limitation of each approach by combining them with several technical insights. First, we show that a carefully selected GAN-discriminator on some real outlier data already achieves the state-of-the-art. Second, we augment the available set of real open training examples with adversarially synthesized "fake" data. Third and most importantly, we build the discriminator over the features computed by the closed-world K-way networks. This allows OpenGAN to be implemented via a lightweight discriminator head built on top of an existing K-way network. Extensive experiments show that OpenGAN significantly outperforms prior open-set methods.

20 May 2020

For many years, multi-object tracking benchmarks have focused on a handful of
categories. Motivated primarily by surveillance and self-driving applications,
these datasets provide tracks for people, vehicles, and animals, ignoring the
vast majority of objects in the world. By contrast, in the related field of
object detection, the introduction of large-scale, diverse datasets (e.g.,
COCO) have fostered significant progress in developing highly robust solutions.
To bridge this gap, we introduce a similarly diverse dataset for Tracking Any
Object (TAO). It consists of 2,907 high resolution videos, captured in diverse
environments, which are half a minute long on average. Importantly, we adopt a
bottom-up approach for discovering a large vocabulary of 833 categories, an
order of magnitude more than prior tracking benchmarks. To this end, we ask
annotators to label objects that move at any point in the video, and give names
to them post factum. Our vocabulary is both significantly larger and
qualitatively different from existing tracking datasets. To ensure scalability
of annotation, we employ a federated approach that focuses manual effort on
labeling tracks for those relevant objects in a video (e.g., those that move).
We perform an extensive evaluation of state-of-the-art trackers and make a
number of important discoveries regarding large-vocabulary tracking in an
open-world. In particular, we show that existing single- and multi-object
trackers struggle when applied to this scenario in the wild, and that
detection-based, multi-object trackers are in fact competitive with
user-initialized ones. We hope that our dataset and analysis will boost further
progress in the tracking community.

09 Jun 2022

Continual learning (CL) is widely regarded as crucial challenge for lifelong AI. However, existing CL benchmarks, e.g. Permuted-MNIST and Split-CIFAR, make use of artificial temporal variation and do not align with or generalize to the real-world. In this paper, we introduce CLEAR, the first continual image classification benchmark dataset with a natural temporal evolution of visual concepts in the real world that spans a decade (2004-2014). We build CLEAR from existing large-scale image collections (YFCC100M) through a novel and scalable low-cost approach to visio-linguistic dataset curation. Our pipeline makes use of pretrained vision-language models (e.g. CLIP) to interactively build labeled datasets, which are further validated with crowd-sourcing to remove errors and even inappropriate images (hidden in original YFCC100M). The major strength of CLEAR over prior CL benchmarks is the smooth temporal evolution of visual concepts with real-world imagery, including both high-quality labeled data along with abundant unlabeled samples per time period for continual semi-supervised learning. We find that a simple unsupervised pre-training step can already boost state-of-the-art CL algorithms that only utilize fully-supervised data. Our analysis also reveals that mainstream CL evaluation protocols that train and test on iid data artificially inflate performance of CL system. To address this, we propose novel "streaming" protocols for CL that always test on the (near) future. Interestingly, streaming protocols (a) can simplify dataset curation since today's testset can be repurposed for tomorrow's trainset and (b) can produce more generalizable models with more accurate estimates of performance since all labeled data from each time-period is used for both training and testing (unlike classic iid train-test splits).
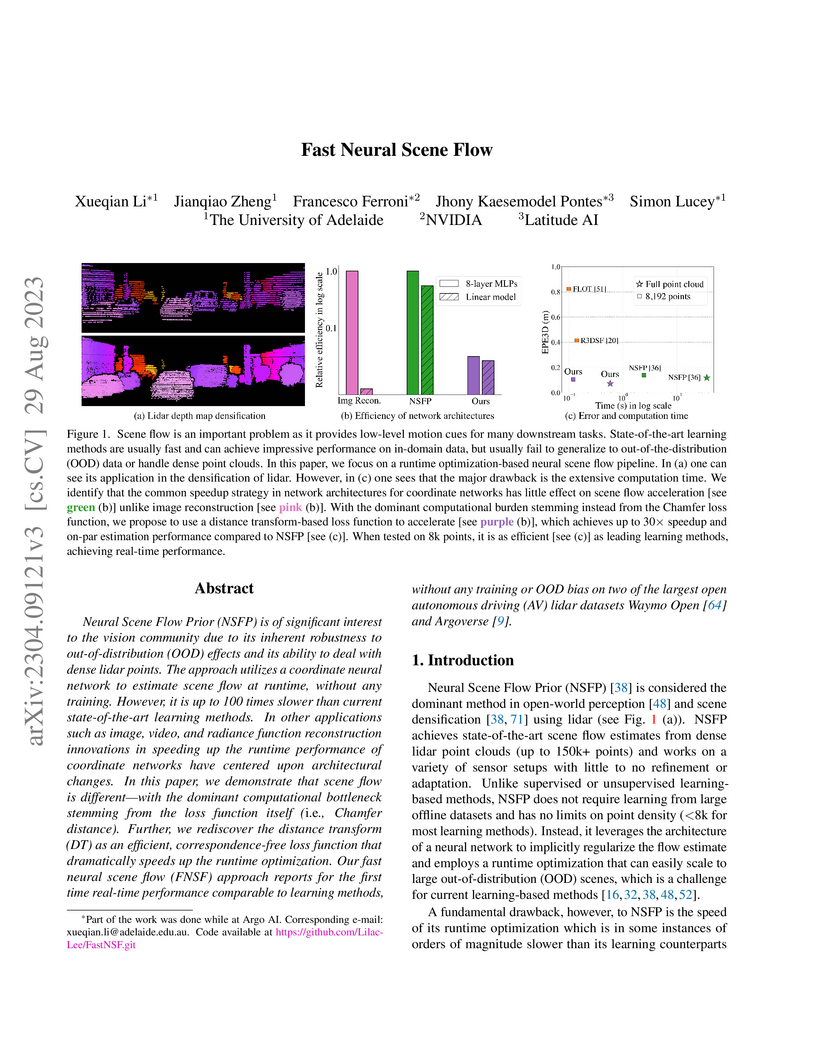
29 Aug 2023

Neural Scene Flow Prior (NSFP) is of significant interest to the vision
community due to its inherent robustness to out-of-distribution (OOD) effects
and its ability to deal with dense lidar points. The approach utilizes a
coordinate neural network to estimate scene flow at runtime, without any
training. However, it is up to 100 times slower than current state-of-the-art
learning methods. In other applications such as image, video, and radiance
function reconstruction innovations in speeding up the runtime performance of
coordinate networks have centered upon architectural changes. In this paper, we
demonstrate that scene flow is different -- with the dominant computational
bottleneck stemming from the loss function itself (i.e., Chamfer distance).
Further, we rediscover the distance transform (DT) as an efficient,
correspondence-free loss function that dramatically speeds up the runtime
optimization. Our fast neural scene flow (FNSF) approach reports for the first
time real-time performance comparable to learning methods, without any training
or OOD bias on two of the largest open autonomous driving (AV) lidar datasets
Waymo Open and Argoverse.

25 Mar 2023
We extend neural radiance fields (NeRFs) to dynamic large-scale urban scenes. Prior work tends to reconstruct single video clips of short durations (up to 10 seconds). Two reasons are that such methods (a) tend to scale linearly with the number of moving objects and input videos because a separate model is built for each and (b) tend to require supervision via 3D bounding boxes and panoptic labels, obtained manually or via category-specific models. As a step towards truly open-world reconstructions of dynamic cities, we introduce two key innovations: (a) we factorize the scene into three separate hash table data structures to efficiently encode static, dynamic, and far-field radiance fields, and (b) we make use of unlabeled target signals consisting of RGB images, sparse LiDAR, off-the-shelf self-supervised 2D descriptors, and most importantly, 2D optical flow.
Operationalizing such inputs via photometric, geometric, and feature-metric reconstruction losses enables SUDS to decompose dynamic scenes into the static background, individual objects, and their motions. When combined with our multi-branch table representation, such reconstructions can be scaled to tens of thousands of objects across 1.2 million frames from 1700 videos spanning geospatial footprints of hundreds of kilometers, (to our knowledge) the largest dynamic NeRF built to date.
We present qualitative initial results on a variety of tasks enabled by our representations, including novel-view synthesis of dynamic urban scenes, unsupervised 3D instance segmentation, and unsupervised 3D cuboid detection. To compare to prior work, we also evaluate on KITTI and Virtual KITTI 2, surpassing state-of-the-art methods that rely on ground truth 3D bounding box annotations while being 10x quicker to train.
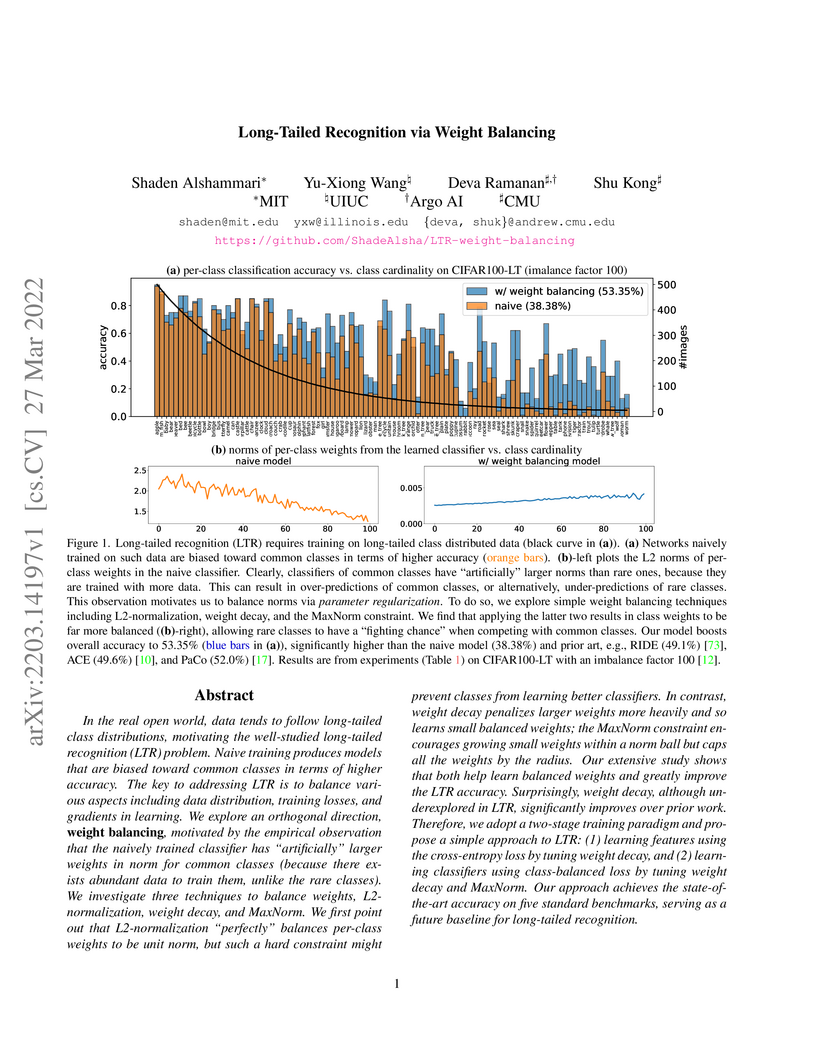
27 Mar 2022

In the real open world, data tends to follow long-tailed class distributions,
motivating the well-studied long-tailed recognition (LTR) problem. Naive
training produces models that are biased toward common classes in terms of
higher accuracy. The key to addressing LTR is to balance various aspects
including data distribution, training losses, and gradients in learning. We
explore an orthogonal direction, weight balancing, motivated by the empirical
observation that the naively trained classifier has "artificially" larger
weights in norm for common classes (because there exists abundant data to train
them, unlike the rare classes). We investigate three techniques to balance
weights, L2-normalization, weight decay, and MaxNorm. We first point out that
L2-normalization "perfectly" balances per-class weights to be unit norm, but
such a hard constraint might prevent classes from learning better classifiers.
In contrast, weight decay penalizes larger weights more heavily and so learns
small balanced weights; the MaxNorm constraint encourages growing small weights
within a norm ball but caps all the weights by the radius. Our extensive study
shows that both help learn balanced weights and greatly improve the LTR
accuracy. Surprisingly, weight decay, although underexplored in LTR,
significantly improves over prior work. Therefore, we adopt a two-stage
training paradigm and propose a simple approach to LTR: (1) learning features
using the cross-entropy loss by tuning weight decay, and (2) learning
classifiers using class-balanced loss by tuning weight decay and MaxNorm. Our
approach achieves the state-of-the-art accuracy on five standard benchmarks,
serving as a future baseline for long-tailed recognition.

01 Aug 2018


Applying image processing algorithms independently to each frame of a video often leads to undesired inconsistent results over time. Developing temporally consistent video-based extensions, however, requires domain knowledge for individual tasks and is unable to generalize to other applications. In this paper, we present an efficient end-to-end approach based on deep recurrent network for enforcing temporal consistency in a video. Our method takes the original unprocessed and per-frame processed videos as inputs to produce a temporally consistent video. Consequently, our approach is agnostic to specific image processing algorithms applied on the original video. We train the proposed network by minimizing both short-term and long-term temporal losses as well as the perceptual loss to strike a balance between temporal stability and perceptual similarity with the processed frames. At test time, our model does not require computing optical flow and thus achieves real-time speed even for high-resolution videos. We show that our single model can handle multiple and unseen tasks, including but not limited to artistic style transfer, enhancement, colorization, image-to-image translation and intrinsic image decomposition. Extensive objective evaluation and subject study demonstrate that the proposed approach performs favorably against the state-of-the-art methods on various types of videos.

30 Jun 2020
In most practical settings and theoretical analyses, one assumes that a model
can be trained until convergence. However, the growing complexity of machine
learning datasets and models may violate such assumptions. Indeed, current
approaches for hyper-parameter tuning and neural architecture search tend to be
limited by practical resource constraints. Therefore, we introduce a formal
setting for studying training under the non-asymptotic, resource-constrained
regime, i.e., budgeted training. We analyze the following problem: "given a
dataset, algorithm, and fixed resource budget, what is the best achievable
performance?" We focus on the number of optimization iterations as the
representative resource. Under such a setting, we show that it is critical to
adjust the learning rate schedule according to the given budget. Among
budget-aware learning schedules, we find simple linear decay to be both robust
and high-performing. We support our claim through extensive experiments with
state-of-the-art models on ImageNet (image classification), Kinetics (video
classification), MS COCO (object detection and instance segmentation), and
Cityscapes (semantic segmentation). We also analyze our results and find that
the key to a good schedule is budgeted convergence, a phenomenon whereby the
gradient vanishes at the end of each allowed budget. We also revisit existing
approaches for fast convergence and show that budget-aware learning schedules
readily outperform such approaches under (the practical but under-explored)
budgeted training setting.

21 Dec 2022

Imitation learning (IL) is a learning paradigm which can be used to
synthesize controllers for complex systems that mimic behavior demonstrated by
an expert (user or control algorithm). Despite their popularity, IL methods
generally lack guarantees of safety, which limits their utility for complex
safety-critical systems. In this work we consider safety, formulated as
set-invariance, and the associated formal guarantees endowed by Control Barrier
Functions (CBFs). We develop conditions under which robustly-safe expert
controllers, utilizing CBFs, can be used to learn end-to-end controllers (which
we refer to as CBF-Compliant controllers) that have safety guarantees. These
guarantees are presented from the perspective of input-to-state safety (ISSf)
which considers safety in the context of disturbances, wherein it is shown that
IL using robustly safe expert demonstrations results in ISSf with the
disturbance directly related to properties of the learning problem. We
demonstrate these safety guarantees in simulated vision-based end-to-end
control of an inverted pendulum and a car driving on a track.

22 Jul 2024


We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: this https URL.

10 Dec 2019
We focus on the problem of class-agnostic instance segmentation of LiDAR point clouds. We propose an approach that combines graph-theoretic search with data-driven learning: it searches over a set of candidate segmentations and returns one where individual segments score well according to a data-driven point-based model of "objectness". We prove that if we score a segmentation by the worst objectness among its individual segments, there is an efficient algorithm that finds the optimal worst-case segmentation among an exponentially large number of candidate segmentations. We also present an efficient algorithm for the average-case. For evaluation, we repurpose KITTI 3D detection as a segmentation benchmark and empirically demonstrate that our algorithms significantly outperform past bottom-up segmentation approaches and top-down object-based algorithms on segmenting point clouds.

23 Jan 2024


Modern neural networks are over-parameterized and thus rely on strong
regularization such as data augmentation and weight decay to reduce overfitting
and improve generalization. The dominant form of data augmentation applies
invariant transforms, where the learning target of a sample is invariant to the
transform applied to that sample. We draw inspiration from human visual
classification studies and propose generalizing augmentation with invariant
transforms to soft augmentation where the learning target softens non-linearly
as a function of the degree of the transform applied to the sample: e.g., more
aggressive image crop augmentations produce less confident learning targets. We
demonstrate that soft targets allow for more aggressive data augmentation,
offer more robust performance boosts, work with other augmentation policies,
and interestingly, produce better calibrated models (since they are trained to
be less confident on aggressively cropped/occluded examples). Combined with
existing aggressive augmentation strategies, soft target 1) doubles the top-1
accuracy boost across Cifar-10, Cifar-100, ImageNet-1K, and ImageNet-V2, 2)
improves model occlusion performance by up to , and 3) halves the
expected calibration error (ECE). Finally, we show that soft augmentation
generalizes to self-supervised classification tasks. Code available at
this https URL

19 Oct 2023

State-of-the-art lidar panoptic segmentation (LPS) methods follow bottom-up
segmentation-centric fashion wherein they build upon semantic segmentation
networks by utilizing clustering to obtain object instances. In this paper, we
re-think this approach and propose a surprisingly simple yet effective
detection-centric network for both LPS and tracking. Our network is modular by
design and optimized for all aspects of both the panoptic segmentation and
tracking task. One of the core components of our network is the object instance
detection branch, which we train using point-level (modal) annotations, as
available in segmentation-centric datasets. In the absence of amodal (cuboid)
annotations, we regress modal centroids and object extent using
trajectory-level supervision that provides information about object size, which
cannot be inferred from single scans due to occlusions and the sparse nature of
the lidar data. We obtain fine-grained instance segments by learning to
associate lidar points with detected centroids. We evaluate our method on
several 3D/4D LPS benchmarks and observe that our model establishes a new
state-of-the-art among open-sourced models, outperforming recent query-based
models.

19 Mar 2025

Scene flow estimation is the task of describing 3D motion between temporally
successive observations. This thesis aims to build the foundation for building
scene flow estimators with two important properties: they are scalable, i.e.
they improve with access to more data and computation, and they are flexible,
i.e. they work out-of-the-box in a variety of domains and on a variety of
motion patterns without requiring significant hyperparameter tuning.
In this dissertation we present several concrete contributions towards this.
In Chapter 1 we contextualize scene flow and its prior methods. In Chapter 2 we
present a blueprint to build and scale feedforward scene flow estimators
without requiring expensive human annotations via large scale distillation from
pseudolabels provided by strong unsupervised test-time optimization methods. In
Chapter 3 we introduce a benchmark to better measure estimate quality across
diverse object types, better bringing into focus what we care about and expect
from scene flow estimators, and use this benchmark to host a public challenge
that produced significant progress. In Chapter 4 we present a state-of-the-art
unsupervised scene flow estimator that introduces a new, full sequence problem
formulation and exhibits great promise in adjacent domains like 3D point
tracking. Finally, in Chapter 5 I philosophize about what's next for scene flow
and its potential future broader impacts.
There are no more papers matching your filters at the moment.
