 Baylor University
Baylor University
17 Jun 2025



This practitioner's guide clarifies the complexities of Difference-in-Differences (DiD) designs, particularly in multi-period and staggered treatment adoption settings, by advocating for a 'forward-engineering' approach to explicitly define causal parameters and their identification assumptions. The authors demonstrate how commonly used Two-Way Fixed Effects (TWFE) estimators can produce biased results in these complex scenarios and provide robust, transparent alternatives for applied researchers.

25 Jun 2025
This survey paper provides a comprehensive overview of the role of Artificial Intelligence in materials science, specifically focusing on foundation models and large language model agents. It systematically categorizes prevalent tasks, reviews various model types and available datasets, and identifies current successes, limitations, and future research directions in AI for materials science.

30 May 2024
Quevedo et al. developed a resource-efficient supervised learning method for detecting hallucinations in Large Language Model (LLM) generated text, relying on only four numerical features derived from token probabilities. This approach achieved over 98% accuracy in specific HaluEval tasks, demonstrating competitive performance against more complex methods.
20 Mar 2025
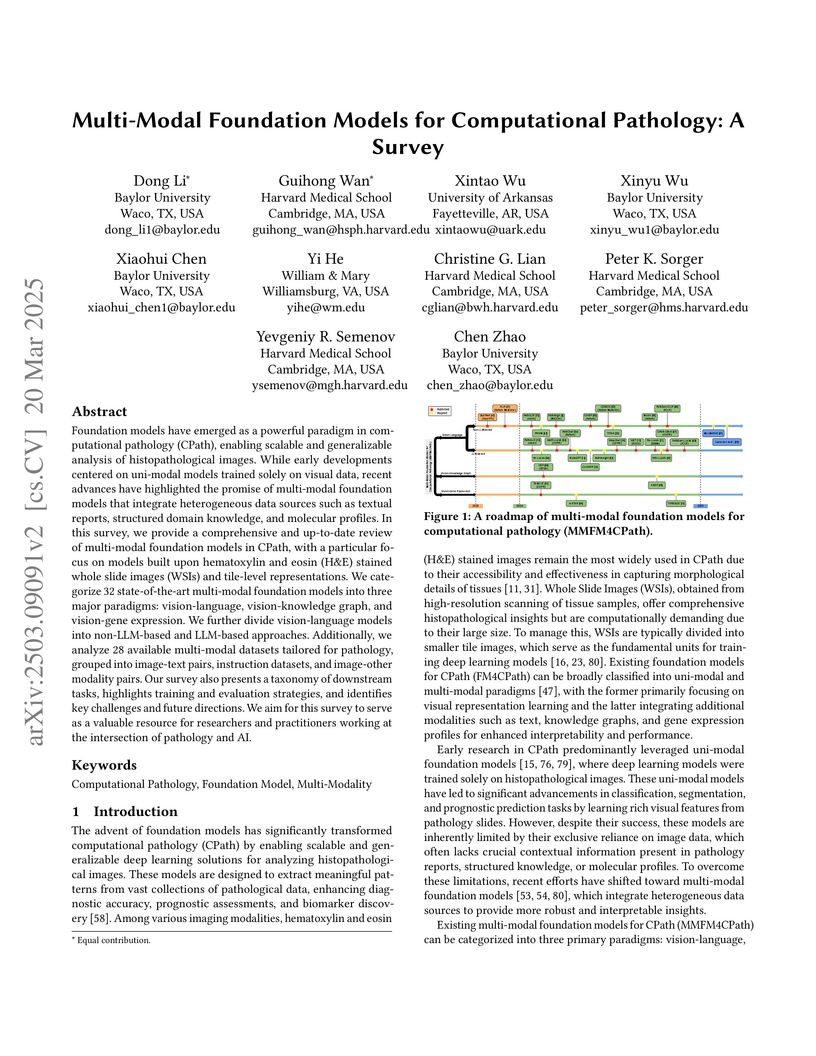
Foundation models have emerged as a powerful paradigm in computational
pathology (CPath), enabling scalable and generalizable analysis of
histopathological images. While early developments centered on uni-modal models
trained solely on visual data, recent advances have highlighted the promise of
multi-modal foundation models that integrate heterogeneous data sources such as
textual reports, structured domain knowledge, and molecular profiles. In this
survey, we provide a comprehensive and up-to-date review of multi-modal
foundation models in CPath, with a particular focus on models built upon
hematoxylin and eosin (H&E) stained whole slide images (WSIs) and tile-level
representations. We categorize 32 state-of-the-art multi-modal foundation
models into three major paradigms: vision-language, vision-knowledge graph, and
vision-gene expression. We further divide vision-language models into
non-LLM-based and LLM-based approaches. Additionally, we analyze 28 available
multi-modal datasets tailored for pathology, grouped into image-text pairs,
instruction datasets, and image-other modality pairs. Our survey also presents
a taxonomy of downstream tasks, highlights training and evaluation strategies,
and identifies key challenges and future directions. We aim for this survey to
serve as a valuable resource for researchers and practitioners working at the
intersection of pathology and AI.

01 Apr 2025
Alzheimer's Disease (AD) is a progressive neurodegenerative disorder that
poses significant diagnostic challenges due to its complex etiology. Graph
Convolutional Networks (GCNs) have shown promise in modeling brain connectivity
for AD diagnosis, yet their reliance on linear transformations limits their
ability to capture intricate nonlinear patterns in neuroimaging data. To
address this, we propose GCN-KAN, a novel single-modal framework that
integrates Kolmogorov-Arnold Networks (KAN) into GCNs to enhance both
diagnostic accuracy and interpretability. Leveraging structural MRI data, our
model employs learnable spline-based transformations to better represent brain
region interactions. Evaluated on the Alzheimer's Disease Neuroimaging
Initiative (ADNI) dataset, GCN-KAN outperforms traditional GCNs by 4-8% in
classification accuracy while providing interpretable insights into key brain
regions associated with AD. This approach offers a robust and explainable tool
for early AD diagnosis.

15 Sep 2025

White dwarfs with infrared excess emission provide a window into the late stages of stellar evolution and the dynamics of circumstellar environments. Using data from the Hobby-Eberly Telescope Dark Energy Experiment (HETDEX), we characterized 30 white dwarfs exhibiting infrared excess, including 29 DA and 1 DB stars. While an infrared excess can arise from dusty disks or cool (sub-)stellar companions, our sample is limited to stellar companions due to our selection based on SDSS photometry, which is sensitive to excess emission at wavelengths \lambda < 1\,\mu\mathrm{m}. Our sample contains 22 newly identified excess sources not previously reported in the literature. Spectroscopic observations are available for 10 sources via SDSS, of which only 8 have prior spectroscopic classifications in the literature.
In this paper, we present the determination of the effective temperature and surface gravity of these white dwarfs. We used the Balmer line profiles to compare with current atmospheric models to determine the photospheric parameters of the white dwarfs, minimizing contamination introduced by the infrared source. We used photometric data from the SDSS and the \textit{Gaia} mission to resolve the degeneracies between hot and cold solutions from spectroscopy, constraining the photospheric parameters. These results help refine our understanding of white dwarf evolution in binary systems, focusing on stellar companions that cause the infrared excess.
This study contributes to identifying systems with potential substellar companions or unresolved stellar partners, adding to the growing effort to map out the fate of planetary systems after their host stars evolve beyond the main sequence.

24 Sep 2025
Using boundary triples, we develop an abstract framework to investigate the complete non-selfadjointness of the maximally dissipative extensions of dissipative operators of the form , where is symmetric with equal finite defect indices and is a bounded non-negative operator. Our key example is the dissipative Schrödinger operator on the interval.

15 Oct 2025
We analyze the dynamics of the Bianchi I universe in modified loop quantum cosmology (Model I, or mLQC-I), uncovering a robust mechanism for isotropization. As in the standard LQC, the classical singularities are resolved by quantum bounce. Remarkably, mLQC-I exhibits a distinctive feature: following the bounce, the shear is dynamically suppressed and decays rapidly to zero within the deep quantum regime. This occurs independently of the collapsing matter fields, leading to a natural quantum isotropization. Consequently, the three spatial directions expand rapidly to macroscopic scales, producing a homogeneous and isotropic universe directly from the quantum epoch without fine-tuning. Our findings demonstrate that mLQC-I not only resolves singularities but also provides a more effective pathway for suppressing anisotropies than other models, thereby reinforcing its viability as a description of the early universe.

23 Aug 2024
Causal Diffusion Autoencoders (CausalDiffAE) introduce a framework for high-fidelity counterfactual image generation by integrating Diffusion Probabilistic Models with Structural Causal Models. The model learns a causally structured, disentangled latent space that enables precise interventions and generates accurate hypothetical scenarios, demonstrating superior disentanglement and counterfactual accuracy on various datasets.

22 Sep 2025


Missing data is among the most prominent challenges in the analysis of physical activity (PA) data collected from wearable devices, with the threat of nonignorabile missingness arising when patterns of device wear relate to underlying activity patterns. We offer a rigorous consideration of assumptions about missing data mechanisms in the context of the common modeling paradigm of state space models with a finite, meaningful, set of underlying PA states. Focusing in particular on hidden Markov models, we identify inherent limitations in the presence of missing data when covariates are required to satisfy common missing data assumptions. In response to this limitation, we propose a Bayesian non-homogeneous state space model that can accommodate covariate dependence in the transitions between latent activity states, which in this case relates to whether patients' routine behavior can inform how they transition between PA states and thus support imputation of missing PA data. We show the benefits of the proposed model for missing data imputation and inference for relevant PA summaries. Our development advances analytic capacity to confront the ubiquitous challenge of missing data when analyzing PA studies using wearables. We illustrate with the analysis of a cohort of adolescent and young adult (AYA) cancer patients who wore commercial Fitbit devices for varying durations during the course of treatment.

06 Aug 2025
Modeling long horizon marked event sequences is a fundamental challenge in many real-world applications, including healthcare, finance, and user behavior modeling. Existing neural temporal point process models are typically autoregressive, predicting the next event one step at a time, which limits their efficiency and leads to error accumulation in long-range forecasting. In this work, we propose a unified flow matching framework for marked temporal point processes that enables non-autoregressive, joint modeling of inter-event times and event types, via continuous and discrete flow matching. By learning continuous-time flows for both components, our method generates coherent long horizon event trajectories without sequential decoding. We evaluate our model on six real-world benchmarks and demonstrate significant improvements over autoregressive and diffusion-based baselines in both accuracy and generation efficiency.

21 Oct 2025
SolverLLM introduces a training-free framework that leverages an LLM-guided Monte Carlo Tree Search to automate the formulation and solution of optimization problems. This method achieved over 10% higher solving accuracy compared to prompt-based LLM baselines and matched or surpassed learning-based methods on challenging benchmarks without requiring any task-specific training.

05 Nov 2024

Erasing a black hole leaves spacetime flat, so light passing through the region before any star forms and after black hole's evaporation shows no time delay, just like a flying mirror that returns to its initial starting point. Quantum radiation from a round-trip flying mirror has not been solved despite the model's mathematical simplicity and physical clarity. Here, we solve the particle creation from worldlines that asymptotically start and stop at the same spot, resulting in interesting spectra and symmetries, including the time dependence of thermal radiance associated with Bose-Einstein and Fermi-Dirac Bogolubov coefficients. Fourier analysis, intrinsically linked to the Bogolubov mechanism, shows that a thermal Bogolubov distribution does not describe the spin statistics of the quantum field.

19 Nov 2024
Domain generalization on graphs aims to develop models with robust generalization capabilities, ensuring effective performance on the testing set despite disparities between testing and training distributions. However, existing methods often rely on static encoders directly applied to the target domain, constraining its flexible adaptability. In contrast to conventional methodologies, which concentrate on developing specific generalized models, our framework, MLDGG, endeavors to achieve adaptable generalization across diverse domains by integrating cross-multi-domain meta-learning with structure learning and semantic identification. Initially, it introduces a generalized structure learner to mitigate the adverse effects of task-unrelated edges, enhancing the comprehensiveness of representations learned by Graph Neural Networks (GNNs) while capturing shared structural information across domains. Subsequently, a representation learner is designed to disentangle domain-invariant semantic and domain-specific variation information in node embedding by leveraging causal reasoning for semantic identification, further enhancing generalization. In the context of meta-learning, meta-parameters for both learners are optimized to facilitate knowledge transfer and enable effective adaptation to graphs through fine-tuning within the target domains, where target graphs are inaccessible during training. Our empirical results demonstrate that MLDGG surpasses baseline methods, showcasing its effectiveness in three different distribution shift settings.

24 Sep 2025
The rapid advancement of generative AI has democratized access to powerful tools such as Text-to-Image models. However, to generate high-quality images, users must still craft detailed prompts specifying scene, style, and context-often through multiple rounds of refinement. We propose PromptSculptor, a novel multi-agent framework that automates this iterative prompt optimization process. Our system decomposes the task into four specialized agents that work collaboratively to transform a short, vague user prompt into a comprehensive, refined prompt. By leveraging Chain-of-Thought reasoning, our framework effectively infers hidden context and enriches scene and background details. To iteratively refine the prompt, a self-evaluation agent aligns the modified prompt with the original input, while a feedback-tuning agent incorporates user feedback for further refinement. Experimental results demonstrate that PromptSculptor significantly enhances output quality and reduces the number of iterations needed for user satisfaction. Moreover, its model-agnostic design allows seamless integration with various T2I models, paving the way for industrial applications.

23 Sep 2025







NASA's Nancy Grace Roman Space Telescope (Roman) will provide an opportunity to study dark energy with unprecedented precision using several techniques, including measurements of Type Ia Supernovae (SNe Ia). Here, we present `phrosty` (PHotometry for ROman with SFFT for tYpe Ia supernovae): a difference imaging pipeline for measuring the brightness of transient point sources in the sky, primarily SNe Ia, using Roman data. `phrosty` is written in Python. We implement a GPU-accelerated version of the Saccadic Fast Fourier Transform (SFFT) method for difference imaging.

05 May 2024
Supervised fairness-aware machine learning under distribution shifts is an emerging field that addresses the challenge of maintaining equitable and unbiased predictions when faced with changes in data distributions from source to target domains. In real-world applications, machine learning models are often trained on a specific dataset but deployed in environments where the data distribution may shift over time due to various factors. This shift can lead to unfair predictions, disproportionately affecting certain groups characterized by sensitive attributes, such as race and gender. In this survey, we provide a summary of various types of distribution shifts and comprehensively investigate existing methods based on these shifts, highlighting six commonly used approaches in the literature. Additionally, this survey lists publicly available datasets and evaluation metrics for empirical studies. We further explore the interconnection with related research fields, discuss the significant challenges, and identify potential directions for future studies.

26 Feb 2025
Computational pathology foundation models (CPathFMs) have emerged as a
powerful approach for analyzing histopathological data, leveraging
self-supervised learning to extract robust feature representations from
unlabeled whole-slide images. These models, categorized into uni-modal and
multi-modal frameworks, have demonstrated promise in automating complex
pathology tasks such as segmentation, classification, and biomarker discovery.
However, the development of CPathFMs presents significant challenges, such as
limited data accessibility, high variability across datasets, the necessity for
domain-specific adaptation, and the lack of standardized evaluation benchmarks.
This survey provides a comprehensive review of CPathFMs in computational
pathology, focusing on datasets, adaptation strategies, and evaluation tasks.
We analyze key techniques, such as contrastive learning and multi-modal
integration, and highlight existing gaps in current research. Finally, we
explore future directions from four perspectives for advancing CPathFMs. This
survey serves as a valuable resource for researchers, clinicians, and AI
practitioners, guiding the advancement of CPathFMs toward robust and clinically
applicable AI-driven pathology solutions.

19 Jan 2025

Learning curve extrapolation predicts neural network performance from early
training epochs and has been applied to accelerate AutoML, facilitating
hyperparameter tuning and neural architecture search. However, existing methods
typically model the evolution of learning curves in isolation, neglecting the
impact of neural network (NN) architectures, which influence the loss landscape
and learning trajectories. In this work, we explore whether incorporating
neural network architecture improves learning curve modeling and how to
effectively integrate this architectural information. Motivated by the
dynamical system view of optimization, we propose a novel architecture-aware
neural differential equation model to forecast learning curves continuously. We
empirically demonstrate its ability to capture the general trend of fluctuating
learning curves while quantifying uncertainty through variational parameters.
Our model outperforms current state-of-the-art learning curve extrapolation
methods and pure time-series modeling approaches for both MLP and CNN-based
learning curves. Additionally, we explore the applicability of our method in
Neural Architecture Search scenarios, such as training configuration ranking.

24 Jan 2025






Successful operation of large particle detectors like the Compact Muon Solenoid (CMS) at the CERN Large Hadron Collider requires rapid, in-depth assessment of data quality. We introduce the ``AutoDQM'' system for Automated Data Quality Monitoring using advanced statistical techniques and unsupervised machine learning. Anomaly detection algorithms based on the beta-binomial probability function, principal component analysis, and neural network autoencoder image evaluation are tested on the full set of proton-proton collision data collected by CMS in 2022. AutoDQM identifies anomalous ``bad'' data affected by significant detector malfunction at a rate 4 -- 6 times higher than ``good'' data, demonstrating its effectiveness as a general data quality monitoring tool.
There are no more papers matching your filters at the moment.
