
09 Oct 2025

The "Linearizer" framework reinterprets conventionally nonlinear neural networks as exact linear operators within learned, non-standard vector spaces. This approach enables the direct application of linear algebra tools for efficient one-step generation in flow matching, modular style transfer, and the creation of globally idempotent generative networks.

09 Jun 2025
 University of WashingtonWuhan University
University of WashingtonWuhan University University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign UCLA
UCLA Chinese Academy of SciencesShanghai AI Laboratory
Chinese Academy of SciencesShanghai AI Laboratory New York University
New York University National University of Singapore
National University of Singapore Fudan University
Fudan University Georgia Institute of Technology
Georgia Institute of Technology University of Science and Technology of China
University of Science and Technology of China Zhejiang UniversityUniversity of Electronic Science and Technology of China
Zhejiang UniversityUniversity of Electronic Science and Technology of China Renmin University of China
Renmin University of China The Hong Kong Polytechnic University
The Hong Kong Polytechnic University Peking UniversityGriffith University
Peking UniversityGriffith University Nanyang Technological University
Nanyang Technological University Johns Hopkins University
Johns Hopkins University The University of Hong Kong
The University of Hong Kong The Pennsylvania State UniversityA*STARShanghai UniversityUniversity of Illinois at ChicagoSingapore Management University
The Pennsylvania State UniversityA*STARShanghai UniversityUniversity of Illinois at ChicagoSingapore Management University Southern University of Science and Technology
Southern University of Science and Technology HKUST
HKUST TencentTeleAISquirrel Ai LearningHong Kong University of Science and Technology (Guangzhou)The University of North Carolina at Chapel HillBen Gurion UniversityCenter for Applied Scientific Computing
TencentTeleAISquirrel Ai LearningHong Kong University of Science and Technology (Guangzhou)The University of North Carolina at Chapel HillBen Gurion UniversityCenter for Applied Scientific Computing

This survey paper defines and applies a 'full-stack' safety concept for Large Language Models (LLMs), systematically analyzing safety concerns across their entire lifecycle from data to deployment and commercialization. The collaboration synthesizes findings from over 900 papers, providing a unified taxonomy of attacks and defenses while identifying key insights and future research directions for LLM and LLM-agent safety.

25 Oct 2025


Low-rank gradient-based optimization methods have significantly improved memory efficiency during the training of large language models (LLMs), enabling operations within constrained hardware without sacrificing performance. However, these methods primarily emphasize memory savings, often overlooking potential acceleration in convergence due to their reliance on standard isotropic steepest descent techniques, which can perform suboptimally in the highly anisotropic landscapes typical of deep networks, particularly LLMs. In this paper, we propose SUMO (Subspace-Aware Moment-Orthogonalization), an optimizer that employs exact singular value decomposition (SVD) for moment orthogonalization within a dynamically adapted low-dimensional subspace, enabling norm-inducing steepest descent optimization steps. By explicitly aligning optimization steps with the spectral characteristics of the loss landscape, SUMO effectively mitigates approximation errors associated with commonly used methods like Newton-Schulz orthogonalization approximation. We theoretically establish an upper bound on these approximation errors, proving their dependence on the condition numbers of moments, conditions we analytically demonstrate are encountered during LLM training. Furthermore, we both theoretically and empirically illustrate that exact orthogonalization via SVD substantially improves convergence rates while reducing overall complexity. Empirical evaluations confirm that SUMO accelerates convergence, enhances stability, improves performance, and reduces memory requirements by up to 20% compared to state-of-the-art methods.
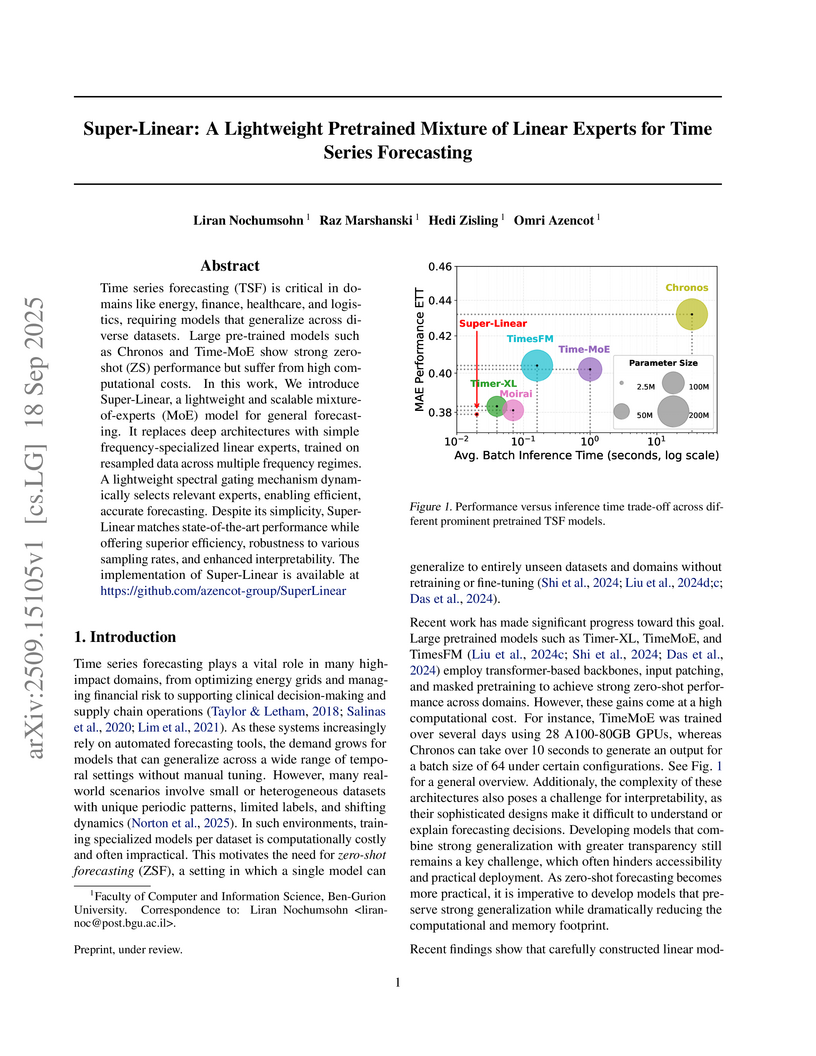
18 Sep 2025
Researchers at Ben-Gurion University developed Super-Linear, a lightweight pretrained Mixture-of-Linear-Experts model for general time series forecasting. This model demonstrates competitive zero-shot generalization performance against larger foundation models, achieving up to 26.2% lower average MSE than Chronos and 14.2% lower than TimesFM, despite having significantly fewer parameters.

08 Jul 2025
This research introduces Differential Mamba, an architecture that adapts differential design principles from Transformers to the Mamba state-space model. The model consistently improves language modeling performance and significantly enhances long-context retrieval capabilities by reducing noise in intermediate representations.

18 Feb 2025


A theoretical framework is introduced for AI-assisted human decision-making that accounts for dynamic human learning over repeated interactions. The framework models how an AI optimally selects features to present to a human, demonstrating that optimal strategies are stationary and computable efficiently, and show a shift towards more informative features with increased AI patience or human learning efficiency.

03 Oct 2025
This paper uses classical high-rate quantization theory to provide new insights into mixture-of-experts (MoE) models for regression tasks. Our MoE is defined by a segmentation of the input space to regions, each with a single-parameter expert that acts as a constant predictor with zero-compute at inference. Motivated by high-rate quantization theory assumptions, we assume that the number of experts is sufficiently large to make their input-space regions very small. This lets us to study the approximation error of our MoE model class: (i) for one-dimensional inputs, we formulate the test error and its minimizing segmentation and experts; (ii) for multidimensional inputs, we formulate an upper bound for the test error and study its minimization. Moreover, we consider the learning of the expert parameters from a training dataset, given an input-space segmentation, and formulate their statistical learning properties. This leads us to theoretically and empirically show how the tradeoff between approximation and estimation errors in MoE learning depends on the number of experts.

06 Feb 2025
Large Language Models (LLMs) have shown remarkable capabilities across
various natural language processing tasks but often struggle to excel uniformly
in diverse or complex domains. We propose a novel ensemble method - Diverse
Fingerprint Ensemble (DFPE), which leverages the complementary strengths of
multiple LLMs to achieve more robust performance. Our approach involves: (1)
clustering models based on response "fingerprints" patterns, (2) applying a
quantile-based filtering mechanism to remove underperforming models at a
per-subject level, and (3) assigning adaptive weights to remaining models based
on their subject-wise validation accuracy. In experiments on the Massive
Multitask Language Understanding (MMLU) benchmark, DFPE outperforms the best
single model by 3% overall accuracy and 5% in discipline-level accuracy. This
method increases the robustness and generalization of LLMs and underscores how
model selection, diversity preservation, and performance-driven weighting can
effectively address challenging, multi-faceted language understanding tasks.

29 Jun 2024
University of WashingtonAllen Institute for Artificial IntelligenceGeorgia Institute of TechnologyLMU MunichIT University of CopenhagenJožef Stefan InstituteBeijing Academy of Artificial Intelligence Sorbonne UniversitéINRIA ParisUniversity of BathNational UniversityBen Gurion UniversityComenius University in BratislavaCiscoDuolingo
Sorbonne UniversitéINRIA ParisUniversity of BathNational UniversityBen Gurion UniversityComenius University in BratislavaCiscoDuolingo

We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.

17 Aug 2024
IBM Research and Ben-Gurion University developed CyberPal.AI, a family of security-expert large language models, by fine-tuning with SecKnowledge, an expert-driven cybersecurity instruction dataset. These models demonstrate an average improvement of 18-24% on training-aligned tasks and 9-10% on public cybersecurity benchmarks, alongside enhanced robustness to adversarial inputs.

13 May 2024

Generating realistic time series data is important for many engineering and scientific applications. Existing work tackles this problem using generative adversarial networks (GANs). However, GANs are unstable during training, and they can suffer from mode collapse. While variational autoencoders (VAEs) are known to be more robust to the these issues, they are (surprisingly) less considered for time series generation. In this work, we introduce Koopman VAE (KoVAE), a new generative framework that is based on a novel design for the model prior, and that can be optimized for either regular and irregular training data. Inspired by Koopman theory, we represent the latent conditional prior dynamics using a linear map. Our approach enhances generative modeling with two desired features: (i) incorporating domain knowledge can be achieved by leveraging spectral tools that prescribe constraints on the eigenvalues of the linear map; and (ii) studying the qualitative behavior and stability of the system can be performed using tools from dynamical systems theory. Our results show that KoVAE outperforms state-of-the-art GAN and VAE methods across several challenging synthetic and real-world time series generation benchmarks. Whether trained on regular or irregular data, KoVAE generates time series that improve both discriminative and predictive metrics. We also present visual evidence suggesting that KoVAE learns probability density functions that better approximate the empirical ground truth distribution.

17 Sep 2025
Large language models (LLMs) often appear to excel on public benchmarks, but these high scores may mask an overreliance on dataset-specific surface cues rather than true language understanding. We introduce the Chameleon Benchmark Overfit Detector (C-BOD), a meta-evaluation framework that systematically distorts benchmark prompts via a parametric transformation and detects overfitting of LLMs. By rephrasing inputs while preserving their semantic content and labels, C-BOD exposes whether a model's performance is driven by memorized patterns. Evaluated on the MMLU benchmark using 26 leading LLMs, our method reveals an average performance degradation of 2.15% under modest perturbations, with 20 out of 26 models exhibiting statistically significant differences. Notably, models with higher baseline accuracy exhibit larger performance differences under perturbation, and larger LLMs tend to be more sensitive to rephrasings, indicating that both cases may overrely on fixed prompt patterns. In contrast, the Llama family and models with lower baseline accuracy show insignificant degradation, suggesting reduced dependency on superficial cues. Moreover, C-BOD's dataset- and model-agnostic design allows easy integration into training pipelines to promote more robust language understanding. Our findings challenge the community to look beyond leaderboard scores and prioritize resilience and generalization in LLM evaluation.

16 Sep 2025
This study examines the relaminarization of turbulent puffs in pipe flow using highly resolved direct numerical simulations at Reynolds numbers of 1880, 1900, and 1920. The exponential decay of the total energy of streamwise velocity fluctuations and the weak dependence of the decay rate on the Reynolds number were verified. In the cross-section of the laminar-turbulent interface at the trailing edge of the puff, an analysis of the spatio-temporal evolution of the streamline patterns reveals a complex topology with saddle-node pairs. In this case, the saddle and the node move toward each other during relaminarization until they collide and vanish. By tracing the vanishing saddle-node pairs over time, we discovered that the distance between the saddle and the node scales as a square root function of time, a generic characteristic of a time-evolving saddle-node bifurcation.

21 Sep 2025
This article addresses a conjecture by Schilling concerning the optimality of the uniform distribution in the generalized Coupon Collector's Problem (CCP) where, in each round, a subset (package) of coupons is drawn from a total of distinct coupons. While the classical CCP (with single-coupon draws) is well understood, the group-draw variant - where packages of size are drawn - presents new challenges and has applications in areas such as biological network models.
Schilling conjectured that, for , the uniform distribution over all possible packages minimizes the expected number of rounds needed to collect all coupons if and only if . We prove Schilling's conjecture in full by presenting, for all other values of , "natural" non-uniform distributions yielding strictly lower expected collection times. Explicit formulas and asymptotic analyses are provided for the expected number of rounds under these and related distributions.
The article further explores the behavior of the expected collection time as varies under the uniform distribution, including the cases where is constant, proportional to , or nearly .
Keywords: Coupon Collector's Problem (CCP), Group Drawings, Uniform Distribution, Expected Collection Time, Schilling's Conjecture, Optimal Distribution.

07 Oct 2025
Researchers from Ben-Gurion University and VISTEC developed DiffSDA, an unsupervised diffusion sequential disentanglement framework that effectively separates static and dynamic factors in real-world sequential data across various modalities. The model achieves state-of-the-art generative quality and disentanglement performance on high-resolution video, audio, and time series, enabling zero-shot disentanglement and fine-grained control over latent factors.

07 Jul 2023


We provide new approximation algorithms for the Red-Blue Set Cover and Circuit Minimum Monotone Satisfying Assignment (MMSA) problems. Our algorithm for Red-Blue Set Cover achieves -approximation improving on the -approximation due to Elkin and Peleg (where is the number of sets). Our approximation algorithm for MMSA (for circuits of depth ) gives an approximation for , where is the number of gates and variables. No non-trivial approximation algorithms for MMSA with were previously known.
We complement these results with lower bounds for these problems: For Red-Blue Set Cover, we provide a nearly approximation preserving reduction from Min -Union that gives an hardness under the Dense-vs-Random conjecture, while for MMSA we sketch a proof that an SDP relaxation strengthened by Sherali--Adams has an integrality gap of where as the circuit depth .

15 Sep 2025


Translating programs between various parallel programming languages is an important problem in the high-performance computing (HPC) community. Existing tools for this problem are either too narrow in scope and/or outdated. Recent explosive growth in the popularity of large language models (LLMs) and their ability to generate and translate code offers a potential alternative approach. Toward that end, we first need to systematically evaluate the ability of LLMs to translate between parallel languages.
In this work, we introduce UniPar, a systematic evaluation framework for LLM-based parallel code translation. Specifically, in this work, we target translations between serial code, CUDA, and OpenMP. Our goal is to assess how well current instruction-tuned LLMs -- specifically GPT-4o-mini and LLaMA-3.3-70B-Instruct -- can be used out of the box or enhanced through known strategies. We evaluated four major usage modes: hyperparameter optimization for decoding, zero- and few-shot prompting, supervised fine-tuning, and iterative feedback through compiler-based repair. As a part of the evaluation, we construct a new dataset called PARATRANS, covering both serial-to-parallel translation and cross-paradigm transformations.
Our findings reveal that while off-the-shelf models struggle under the default settings (e.g., GPT-4o-mini achieves only 46% compilation and 15% functional correctness), our UniPar methodology -- combining fine-tuning, hyperparameter tuning, and compiler-guided repair -- improves performance by up to 2X (69% compilation and 33% correctness). We believe that our findings will provide useful insights for researchers to further improve LLMs for the parallel language translation problem.
UniPar source code and PARATRANS dataset are available at our GitHub repository this https URL.

25 Nov 2024

Imagine observing someone scratching their arm; to understand why, additional
context would be necessary. However, spotting a mosquito nearby would
immediately offer a likely explanation for the person's discomfort, thereby
alleviating the need for further information. This example illustrates how
subtle visual cues can challenge our cognitive skills and demonstrates the
complexity of interpreting visual scenarios. To study these skills, we present
Visual Riddles, a benchmark aimed to test vision and language models on visual
riddles requiring commonsense and world knowledge. The benchmark comprises 400
visual riddles, each featuring a unique image created by a variety of
text-to-image models, question, ground-truth answer, textual hint, and
attribution. Human evaluation reveals that existing models lag significantly
behind human performance, which is at 82% accuracy, with Gemini-Pro-1.5 leading
with 40% accuracy. Our benchmark comes with automatic evaluation tasks to make
assessment scalable. These findings underscore the potential of Visual Riddles
as a valuable resource for enhancing vision and language models' capabilities
in interpreting complex visual scenarios.

16 Jun 2025
Tokenizers for natural language processing exhibit diminishing returns in quality and vocabulary stability with increased training data, reaching optimal performance for English with approximately 120-150GB and for Russian with around 200GB. This saturation is primarily attributed to the constraining influence of the initial pre-tokenization step, which pre-determines a significant portion of the vocabulary early on.

29 May 2025
Subject-driven text-to-image (T2I) generation aims to produce images that
align with a given textual description, while preserving the visual identity
from a referenced subject image. Despite its broad downstream applicability -
ranging from enhanced personalization in image generation to consistent
character representation in video rendering - progress in this field is limited
by the lack of reliable automatic evaluation. Existing methods either assess
only one aspect of the task (i.e., textual alignment or subject preservation),
misalign with human judgments, or rely on costly API-based evaluation. To
address this gap, we introduce RefVNLI, a cost-effective metric that evaluates
both textual alignment and subject preservation in a single run. Trained on a
large-scale dataset derived from video-reasoning benchmarks and image
perturbations, RefVNLI outperforms or statistically matches existing baselines
across multiple benchmarks and subject categories (e.g., \emph{Animal},
\emph{Object}), achieving up to 6.4-point gains in textual alignment and
5.9-point gains in subject preservation.
There are no more papers matching your filters at the moment.
