
09 Dec 2024



The creation of 3D scenes has traditionally been both labor-intensive and costly, requiring designers to meticulously configure 3D assets and environments. Recent advancements in generative AI, including text-to-3D and image-to-3D methods, have dramatically reduced the complexity and cost of this process. However, current techniques for editing complex 3D scenes continue to rely on generally interactive multi-step, 2D-to-3D projection methods and diffusion-based techniques, which often lack precision in control and hamper real-time performance. In this work, we propose 3DSceneEditor, a fully 3D-based paradigm for real-time, precise editing of intricate 3D scenes using Gaussian Splatting. Unlike conventional methods, 3DSceneEditor operates through a streamlined 3D pipeline, enabling direct manipulation of Gaussians for efficient, high-quality edits based on input this http URL proposed framework (i) integrates a pre-trained instance segmentation model for semantic labeling; (ii) employs a zero-shot grounding approach with CLIP to align target objects with user prompts; and (iii) applies scene modifications, such as object addition, repositioning, recoloring, replacing, and deletion directly on Gaussians. Extensive experimental results show that 3DSceneEditor achieves superior editing precision and speed with respect to current SOTA 3D scene editing approaches, establishing a new benchmark for efficient and interactive 3D scene customization.

21 Apr 2025
LLMs augmented with Retrieval-Augmented Generation (RAG) can achieve near-human performance in Named Entity Recognition (NER) data annotation, consistently outperforming in-context learning and zero-shot approaches, particularly on well-structured datasets like CoNLL-2003. The study demonstrates that RAG effectively selects relevant examples for LLMs, improving annotation quality and offering a more efficient alternative for NLP dataset creation.

23 Oct 2024
Researchers developed a linearly multiplexed photon number resolving detector array integrating superconducting nanowire single-photon detectors on a Silicon Nitride strip-loaded Lithium Niobate-on-Insulator platform. The work presents a detailed theoretical and simulation-based analysis of the array's fidelity, considering realistic conditions such as waveguide losses and dark counts, and proposes optimized designs for quantum light detection.

16 Jun 2025
Mobility patterns play a critical role in a wide range of societal
challenges, from epidemic modeling and emergency response to transportation
planning and regional development. Yet, access to high-quality, timely, and
openly available mobility data remains limited. In response, the Spanish
Ministry of Transportation and Sustainable Mobility has released daily mobility
datasets based on anonymized mobile phone data, covering districts,
municipalities, and greater urban areas from February 2020 to June 2021 and
again from January 2022 onward. This paper presents pySpainMobility, a Python
package that simplifies access to these datasets and their associated study
areas through a standardized, well-documented interface. By lowering the
technical barrier to working with large-scale mobility data, the package
enables reproducible analysis and supports applications across research,
policy, and operational domains. The library is available at
this https URL
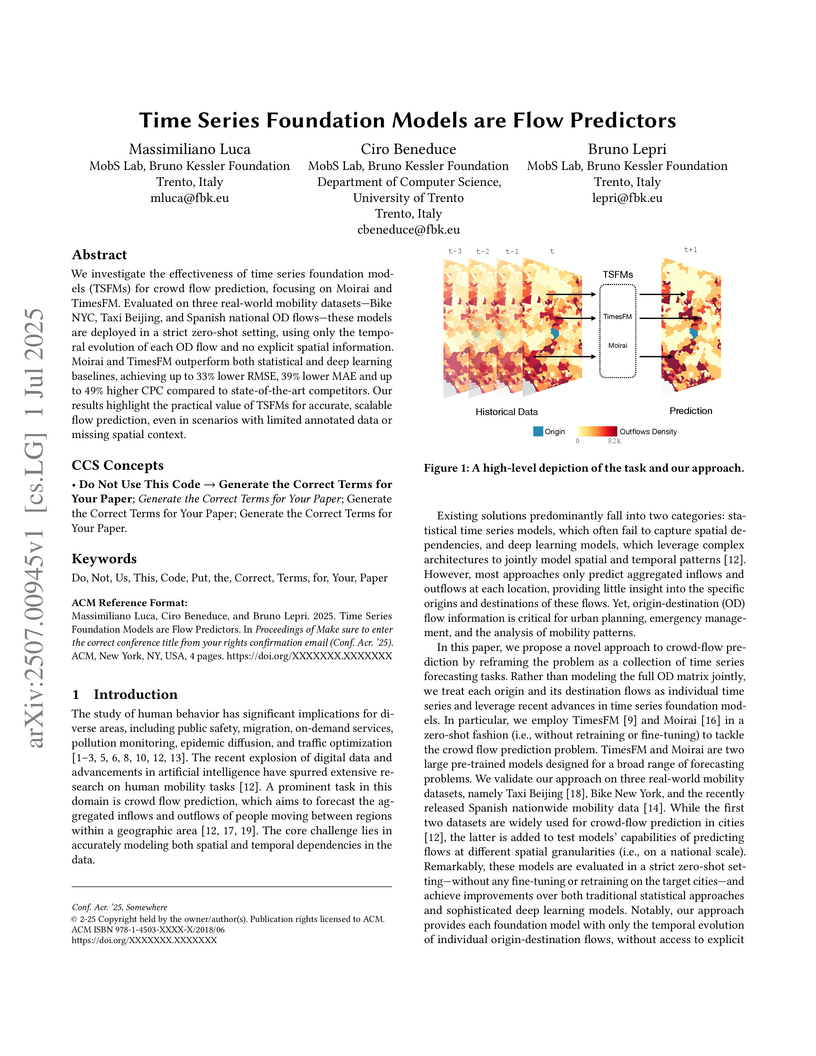
01 Jul 2025
We investigate the effectiveness of time series foundation models (TSFMs) for crowd flow prediction, focusing on Moirai and TimesFM. Evaluated on three real-world mobility datasets-Bike NYC, Taxi Beijing, and Spanish national OD flows-these models are deployed in a strict zero-shot setting, using only the temporal evolution of each OD flow and no explicit spatial information. Moirai and TimesFM outperform both statistical and deep learning baselines, achieving up to 33% lower RMSE, 39% lower MAE and up to 49% higher CPC compared to state-of-the-art competitors. Our results highlight the practical value of TSFMs for accurate, scalable flow prediction, even in scenarios with limited annotated data or missing spatial context.

23 Aug 2024

Predicting the locations an individual will visit in the future is crucial for solving many societal issues like disease diffusion and reduction of pollution. However, next-location predictors require a significant amount of individual-level information that may be scarce or unavailable in some scenarios (e.g., cold-start). Large Language Models (LLMs) have shown good generalization and reasoning capabilities and are rich in geographical knowledge, allowing us to believe that these models can act as zero-shot next-location predictors. We tested more than 15 LLMs on three real-world mobility datasets and we found that LLMs can obtain accuracies up to 36.2%, a significant relative improvement of almost 640% when compared to other models specifically designed for human mobility. We also test for data contamination and explored the possibility of using LLMs as text-based explainers for next-location prediction, showing that, regardless of the model size, LLMs can explain their decision.

08 Jul 2025
Conservation and decision-making regarding forest resources necessitate regular forest inventory. Light detection and ranging (LiDAR) in laser scanning systems has gained significant attention over the past two decades as a remote and non-destructive solution to streamline the labor-intensive and time-consuming procedure of forest inventory. Advanced multispectral (MS) LiDAR systems simultaneously acquire three-dimensional (3D) spatial and spectral information across multiple wavelengths of the electromagnetic spectrum. Consequently, MS-LiDAR technology enables the estimation of both the biochemical and biophysical characteristics of forests. Forest component segmentation is crucial for forest inventory. The synergistic use of spatial and spectral laser information has proven to be beneficial for achieving precise forest semantic segmentation. Thus, this study aims to investigate the potential of MS-LiDAR data, captured by the HeliALS system, providing high-density multispectral point clouds to segment forests into six components: ground, low vegetation, trunks, branches, foliage, and woody debris. Three point-wise 3D deep learning models and one machine learning model, including kernel point convolution, superpoint transformer, point transformer V3, and random forest, are implemented. Our experiments confirm the superior accuracy of the KPConv model. Additionally, various geometric and spectral feature vector scenarios are examined. The highest accuracy is achieved by feeding all three wavelengths (1550 nm, 905 nm, and 532 nm) as the initial features into the deep learning model, resulting in improvements of 33.73% and 32.35% in mean intersection over union (mIoU) and in mean accuracy (mAcc), respectively. This study highlights the excellent potential of multispectral LiDAR for improving the accuracy in fully automated forest component segmentation.

18 Sep 2025
True Digital Orthophoto Map (TDOM) serves as a crucial geospatial product in various fields such as urban management, city planning, land surveying, etc. However, traditional TDOM generation methods generally rely on a complex offline photogrammetric pipeline, resulting in delays that hinder real-time applications. Moreover, the quality of TDOM may degrade due to various challenges, such as inaccurate camera poses or Digital Surface Model (DSM) and scene occlusions. To address these challenges, this work introduces A-TDOM, a near real-time TDOM generation method based on On-the-Fly 3DGS optimization. As each image is acquired, its pose and sparse point cloud are computed via On-the-Fly SfM. Then new Gaussians are integrated and optimized into previously unseen or coarsely reconstructed regions. By integrating with orthogonal splatting, A-TDOM can render just after each update of a new 3DGS field. Initial experiments on multiple benchmarks show that the proposed A-TDOM is capable of actively rendering TDOM in near real-time, with 3DGS optimization for each new image in seconds while maintaining acceptable rendering quality and TDOM geometric accuracy.

24 Mar 2022
Motion segmentation is a challenging problem that seeks to identify
independent motions in two or several input images. This paper introduces the
first algorithm for motion segmentation that relies on adiabatic quantum
optimization of the objective function. The proposed method achieves on-par
performance with the state of the art on problem instances which can be mapped
to modern quantum annealers.

15 Apr 2024
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at this https URL

18 Aug 2025




Infectious disease spread is a multi-scale process composed of within-host (biological) and between-host (social) drivers and disentangling them from each other is a central challenge in epidemiology. Here, we introduce VIBES, a multi-scale modeling framework that explicitly integrates viral dynamics based on patient-level data with population-level transmission on a data-driven network of social contacts. Using SARS-CoV-2 as a case study, we analyze three emergent epidemic properties, namely the generation time, serial interval, and pre-symptomatic transmission. First, we established a purely biological baseline, thus independent of the reproduction number (R), from the within-host model, estimating a generation time of 6.3 days for symptomatic individuals and 43.1% presymptomatic transmission. Then, using the full model incorporating social contacts, we found a shorter generation time (5.4 days at R=3.0) and an increase in pre-symptomatic transmission (52.8% at R=3.0), disentangling the impact of social drivers from a purely biological baseline. We further show that as pathogen transmissibility increases (R from 1.3 to 6), competition among infectious individuals shortens the generation time and serial interval by up to 21% and 13%, respectively. Conversely, a social intervention, like isolation, increases the proportion of pre-symptomatic transmission by about 30%. Our framework also estimates metrics that are challenging to obtain empirically, such as the generation time for asymptomatic individuals (5.6 days; 95%CI: 5.1-6.0 at R=1.3). Our findings establish multi-scale modeling as a powerful tool for mechanistically quantifying how pathogen biology and human social behavior shape epidemic dynamics as well as for assessing public health interventions.

05 Jul 2020
Patch-based stereo is nowadays a commonly used image-based technique for dense 3D reconstruction in large scale multi-view applications. The typical steps of such a pipeline can be summarized in stereo pair selection, depth map computation, depth map refinement and, finally, fusion in order to generate a complete and accurate representation of the scene in 3D. In this study, we aim to support the standard dense 3D reconstruction of scenes as implemented in the open source library OpenMVS by using semantic priors. To this end, during the depth map fusion step, along with the depth consistency check between depth maps of neighbouring views referring to the same part of the 3D scene, we impose extra semantic constraints in order to remove possible errors and selectively obtain segmented point clouds per label, boosting automation towards this direction. I n order to reassure semantic coherence between neighbouring views, additional semantic criterions can be considered, aiming to elim inate mismatches of pixels belonging in different classes.

30 Jun 2023

Coalescence-jumping of condensation droplets is widely studied for anti-icing, condensation heat transfer, water harvesting and self-cleaning. Another phenomenon that is arousing interest for potential enhancements is the individual droplet self-ejection. However, whether it is possible from divergent structures without detachment from pinning sites remains unexplored. Here we investigate the self-ejection of individual droplets from divergent, uniformly hydrophobic structures. We designed, fabricated and tested arrays of nanostructured truncated microcones arranged in a square pattern. The dynamics of the single condensation droplet is revealed with high speed microscopy: it self-ejects after cycles of growth and self-propulsion between four cones. Adopting the conical pore for simplicity, we modelled the slow iso-pressure growth phases and the surface energy release-driven rapid transients enabled once a dynamic configuration is reached. In addition to easier fabrication, microcones with uniform wettability have the potential to allow self-ejection of almost all the droplets with a precise size while maintaining mechanical resistance and thus promising great improvements in a plethora of applications.

17 Oct 2021
Event-triggered control (ETC) holds the potential to significantly improve the efficiency of wireless networked control systems. Unfortunately, its real-world impact has hitherto been hampered by the lack of a network stack able to transfer its benefits from theory to practice specifically by supporting the latency and reliability requirements of the aperiodic communication ETC induces. This is precisely the contribution of this paper. Our Wireless Control Bus (WCB) exploits carefully orchestrated network-wide floods of concurrent transmissions to minimize overhead during quiescent, steady-state periods, and ensures timely and reliable collection of sensor readings and dissemination of actuation commands when an ETC triggering condition is violated. Using a cyber-physical testbed emulating a water distribution system controlled over a real-world multi-hop wireless network, we show that ETC over WCB achieves the same quality of periodic control at a fraction of the energy costs, therefore unleashing and concretely demonstrating its full potential for the first time.

01 Dec 2020
For dynamical systems with a non hyperbolic equilibrium, it is possible to significantly simplify the study of stability by means of the center manifold theory. This theory allows to isolate the complicated asymptotic behavior of the system close to the equilibrium point and to obtain meaningful predictions of its behavior by analyzing a reduced order system on the so-called center manifold.
Since the center manifold is usually not known, good approximation methods are important as the center manifold theorem states that the stability properties of the origin of the reduced order system are the same as those of the origin of the full order system.
In this work, we establish a data-based version of the center manifold theorem that works by considering an approximation in place of an exact manifold. Also the error between the approximated and the original reduced dynamics are quantified.
We then use an apposite data-based kernel method to construct a suitable approximation of the manifold close to the equilibrium, which is compatible with our general error theory. The data are collected by repeated numerical simulation of the full system by means of a high-accuracy solver, which generates sets of discrete trajectories that are then used as a training set. The method is tested on different examples which show promising performance and good accuracy.

29 Jul 2015
Purpose is crucial for privacy protection as it makes users confident that their personal data are processed as intended. Available proposals for the specification and enforcement of purpose-aware policies are unsatisfactory for their ambiguous semantics of purposes and/or lack of support to the run-time enforcement of policies.
In this paper, we propose a declarative framework based on a first-order temporal logic that allows us to give a precise semantics to purpose-aware policies and to reuse algorithms for the design of a run-time monitor enforcing purpose-aware policies. We also show the complexity of the generation and use of the monitor which, to the best of our knowledge, is the first such a result in literature on purpose-aware policies.

29 Jul 2015
Purpose is crucial for privacy protection as it makes users confident that their personal data are processed as intended. Available proposals for the specification and enforcement of purpose-aware policies are unsatisfactory for their ambiguous semantics of purposes and/or lack of support to the run-time enforcement of policies.
In this paper, we propose a declarative framework based on a first-order temporal logic that allows us to give a precise semantics to purpose-aware policies and to reuse algorithms for the design of a run-time monitor enforcing purpose-aware policies. We also show the complexity of the generation and use of the monitor which, to the best of our knowledge, is the first such a result in literature on purpose-aware policies.

01 Mar 2025

This paper introduces a modular, non-deep learning method for filtering and
refining sparse correspondences in image matching. Assuming that motion flow
within the scene can be approximated by local homography transformations,
matches are aggregated into overlapping clusters corresponding to virtual
planes using an iterative RANSAC-based approach, with non-conforming
correspondences discarded. Moreover, the underlying planar structural design
provides an explicit map between local patches associated with the matches,
enabling optional refinement of keypoint positions through cross-correlation
template matching after patch reprojection. Finally, to enhance robustness and
fault-tolerance against violations of the piece-wise planar approximation
assumption, a further strategy is designed for minimizing relative patch
distortion in the plane reprojection by introducing an intermediate homography
that projects both patches into a common plane. The proposed method is
extensively evaluated on standard datasets and image matching pipelines, and
compared with state-of-the-art approaches. Unlike other current comparisons,
the proposed benchmark also takes into account the more general, real, and
practical cases where camera intrinsics are unavailable. Experimental results
demonstrate that our proposed non-deep learning, geometry-based approach
achieves performances that are either superior to or on par with recent
state-of-the-art deep learning methods. Finally, this study suggests that there
are still development potential in actual image matching solutions in the
considered research direction, which could be in the future incorporated in
novel deep image matching architectures.

15 Mar 2022
Federated Leaning is an emerging approach to manage cooperation between a group of agents for the solution of Machine Learning tasks, with the goal of improving each agent's performance without disclosing any data. In this paper we present a novel algorithmic architecture that tackle this problem in the particular case of Anomaly Detection (or classification or rare events), a setting where typical applications often comprise data with sensible information, but where the scarcity of anomalous examples encourages collaboration. We show how Random Forests can be used as a tool for the development of accurate classifiers with an effective insight-sharing mechanism that does not break the data integrity. Moreover, we explain how the new architecture can be readily integrated in a blockchain infrastructure to ensure the verifiable and auditable execution of the algorithm. Furthermore, we discuss how this work may set the basis for a more general approach for the design of federated ensemble-learning methods beyond the specific task and architecture discussed in this paper.

20 Jun 2025
Image generation models are revolutionizing many domains, and urban analysis and design is no exception. While such models are widely adopted, there is a limited literature exploring their geographic knowledge, along with the biases they embed. In this work, we generated 150 synthetic images for each state in the USA and related capitals using FLUX 1 and Stable Diffusion 3.5, two state-of-the-art models for image generation. We embed each image using DINO-v2 ViT-S/14 and the Fréchet Inception Distances to measure the similarity between the generated images. We found that while these models have implicitly learned aspects of USA geography, if we prompt the models to generate an image for "United States" instead of specific cities or states, the models exhibit a strong representative bias toward metropolis-like areas, excluding rural states and smaller cities. {\color{black} In addition, we found that models systematically exhibit some entity-disambiguation issues with European-sounding names like Frankfort or Devon.
There are no more papers matching your filters at the moment.
