
25 Oct 2025
Federated clustering (FC) aims to discover global cluster structures across decentralized clients without sharing raw data, making privacy preservation a fundamental requirement. There are two critical challenges: (1) privacy leakage during collaboration, and (2) robustness degradation due to aggregation of proxy information from non-independent and identically distributed (Non-IID) local data, leading to inaccurate or inconsistent global clustering. Existing solutions typically rely on model-specific local proxies, which are sensitive to data heterogeneity and inherit inductive biases from their centralized counterparts, thus limiting robustness and generality. We propose Omni Federated Clustering (OmniFC), a unified and model-agnostic framework. Leveraging Lagrange coded computing, our method enables clients to share only encoded data, allowing exact reconstruction of the global distance matrix--a fundamental representation of sample relationships--without leaking private information, even under client collusion. This construction is naturally resilient to Non-IID data distributions. This approach decouples FC from model-specific proxies, providing a unified extension mechanism applicable to diverse centralized clustering methods. Theoretical analysis confirms both reconstruction fidelity and privacy guarantees, while comprehensive experiments demonstrate OmniFC's superior robustness, effectiveness, and generality across various benchmarks compared to state-of-the-art methods. Code will be released.

11 Sep 2025

Pure time series forecasting tasks typically focus exclusively on numerical features; however, real-world financial decision-making demands the comparison and analysis of heterogeneous sources of information. Recent advances in deep learning and large scale language models (LLMs) have made significant strides in capturing sentiment and other qualitative signals, thereby enhancing the accuracy of financial time series predictions. Despite these advances, most existing datasets consist solely of price series and news text, are confined to a single market, and remain limited in scale. In this paper, we introduce FinMultiTime, the first large scale, multimodal financial time series dataset. FinMultiTime temporally aligns four distinct modalities financial news, structured financial tables, K-line technical charts, and stock price time series across both the S&P 500 and HS 300 universes. Covering 5,105 stocks from 2009 to 2025 in the United States and China, the dataset totals 112.6 GB and provides minute-level, daily, and quarterly resolutions, thus capturing short, medium, and long term market signals with high fidelity. Our experiments demonstrate that (1) scale and data quality markedly boost prediction accuracy; (2) multimodal fusion yields moderate gains in Transformer models; and (3) a fully reproducible pipeline enables seamless dataset updates.

25 Apr 2025

Tsinghua University researchers developed MAGI, a multi-agent system designed to automate the Mini International Neuropsychiatric Interview for psychiatric assessment, which achieved high agreement with expert diagnoses and introduced transparent reasoning, particularly enhancing suicide risk detection.

10 Jun 2025

AnnaAgent is an LLM-based system that simulates realistic seekers in psychological counseling by enabling dynamic emotional and cognitive evolution within sessions and providing robust multi-session memory. It outperforms existing baselines in anthropomorphism and personality fidelity metrics, with ablation studies confirming the necessity of its core components.

16 Sep 2025
Text-driven infrared and visible image fusion has gained attention for enabling natural language to guide the fusion process. However, existing methods lack a goal-aligned task to supervise and evaluate how effectively the input text contributes to the fusion outcome. We observe that referring image segmentation (RIS) and text-driven fusion share a common objective: highlighting the object referred to by the text. Motivated by this, we propose RIS-FUSION, a cascaded framework that unifies fusion and RIS through joint optimization. At its core is the LangGatedFusion module, which injects textual features into the fusion backbone to enhance semantic alignment. To support multimodal referring image segmentation task, we introduce MM-RIS, a large-scale benchmark with 12.5k training and 3.5k testing triplets, each consisting of an infrared-visible image pair, a segmentation mask, and a referring expression. Extensive experiments show that RIS-FUSION achieves state-of-the-art performance, outperforming existing methods by over 11% in mIoU. Code and dataset will be released at this https URL.

24 May 2022

Machine learning systems generally assume that the training and testing distributions are the same. To this end, a key requirement is to develop models that can generalize to unseen distributions. Domain generalization (DG), i.e., out-of-distribution generalization, has attracted increasing interests in recent years. Domain generalization deals with a challenging setting where one or several different but related domain(s) are given, and the goal is to learn a model that can generalize to an unseen test domain. Great progress has been made in the area of domain generalization for years. This paper presents the first review of recent advances in this area. First, we provide a formal definition of domain generalization and discuss several related fields. We then thoroughly review the theories related to domain generalization and carefully analyze the theory behind generalization. We categorize recent algorithms into three classes: data manipulation, representation learning, and learning strategy, and present several popular algorithms in detail for each category. Third, we introduce the commonly used datasets, applications, and our open-sourced codebase for fair evaluation. Finally, we summarize existing literature and present some potential research topics for the future.

18 Jun 2024

We constructed a newly large-scale and comprehensive C/C++ vulnerability
dataset named MegaVul by crawling the Common Vulnerabilities and Exposures
(CVE) database and CVE-related open-source projects. Specifically, we collected
all crawlable descriptive information of the vulnerabilities from the CVE
database and extracted all vulnerability-related code changes from 28 Git-based
websites. We adopt advanced tools to ensure the extracted code integrality and
enrich the code with four different transformed representations. In total,
MegaVul contains 17,380 vulnerabilities collected from 992 open-source
repositories spanning 169 different vulnerability types disclosed from January
2006 to October 2023. Thus, MegaVul can be used for a variety of software
security-related tasks including detecting vulnerabilities and assessing
vulnerability severity. All information is stored in the JSON format for easy
usage. MegaVul is publicly available on GitHub and will be continuously
updated. It can be easily extended to other programming languages.

28 Jul 2025


Stock price movements are influenced by many factors, and alongside historical price data, tex-tual information is a key source. Public news and social media offer valuable insights into market sentiment and emerging events. These sources are fast-paced, diverse, and significantly impact future stock trends. Recently, LLMs have enhanced financial analysis, but prompt-based methods still have limitations, such as input length restrictions and difficulties in predicting sequences of varying lengths. Additionally, most models rely on dense computational layers, which are resource-intensive. To address these challenges, we propose the FTS- Text-MoE model, which combines numerical data with key summaries from news and tweets using point embeddings, boosting prediction accuracy through the integration of factual textual data. The model uses a Mixture of Experts (MoE) Transformer decoder to process both data types. By activating only a subset of model parameters, it reduces computational costs. Furthermore, the model features multi-resolution prediction heads, enabling flexible forecasting of financial time series at different scales. Experimental results show that FTS-Text-MoE outperforms baseline methods in terms of investment returns and Sharpe ratio, demonstrating its superior accuracy and ability to predict future market trends.
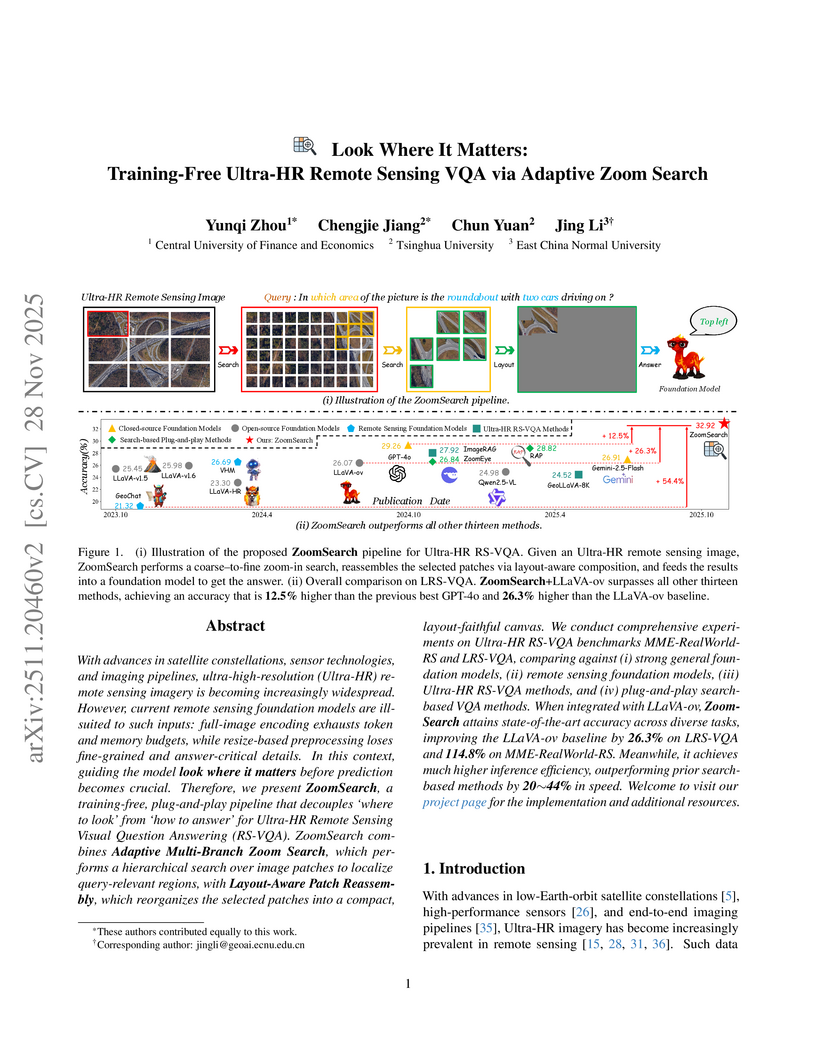
28 Nov 2025
With advances in satellite constellations, sensor technologies, and imaging pipelines, ultra-high-resolution (Ultra-HR) remote sensing imagery is becoming increasingly widespread. However, current remote sensing foundation models are ill-suited to such inputs: full-image encoding exhausts token and memory budgets, while resize-based preprocessing loses fine-grained and answer-critical details. In this context, guiding the model look where it matters before prediction becomes crucial. Therefore, we present ZoomSearch, a training-free, plug-and-play pipeline that decouples 'where to look' from 'how to answer' for Ultra-HR Remote Sensing Visual Question Answering (RS-VQA). ZoomSearch combines Adaptive Multi-Branch Zoom Search, which performs a hierarchical search over image patches to localize query-relevant regions, with Layout-Aware Patch Reassembly, which reorganizes the selected patches into a compact, layout-faithful canvas. We conduct comprehensive experiments on Ultra-HR RS-VQA benchmarks MME-RealWorld-RS and LRS-VQA, comparing against (i) strong general foundation models, (ii) remote sensing foundation models, (iii) Ultra-HR RS-VQA methods, and (iv) plug-and-play search-based VQA methods. When integrated with LLaVA-ov, ZoomSearch attains state-of-the-art accuracy across diverse tasks, improving the LLaVA-ov baseline by 26.3% on LRS-VQA and 114.8% on MME-RealWorld-RS. Meanwhile, it achieves much higher inference efficiency, outperforming prior search-based methods by 20%~44% in speed.
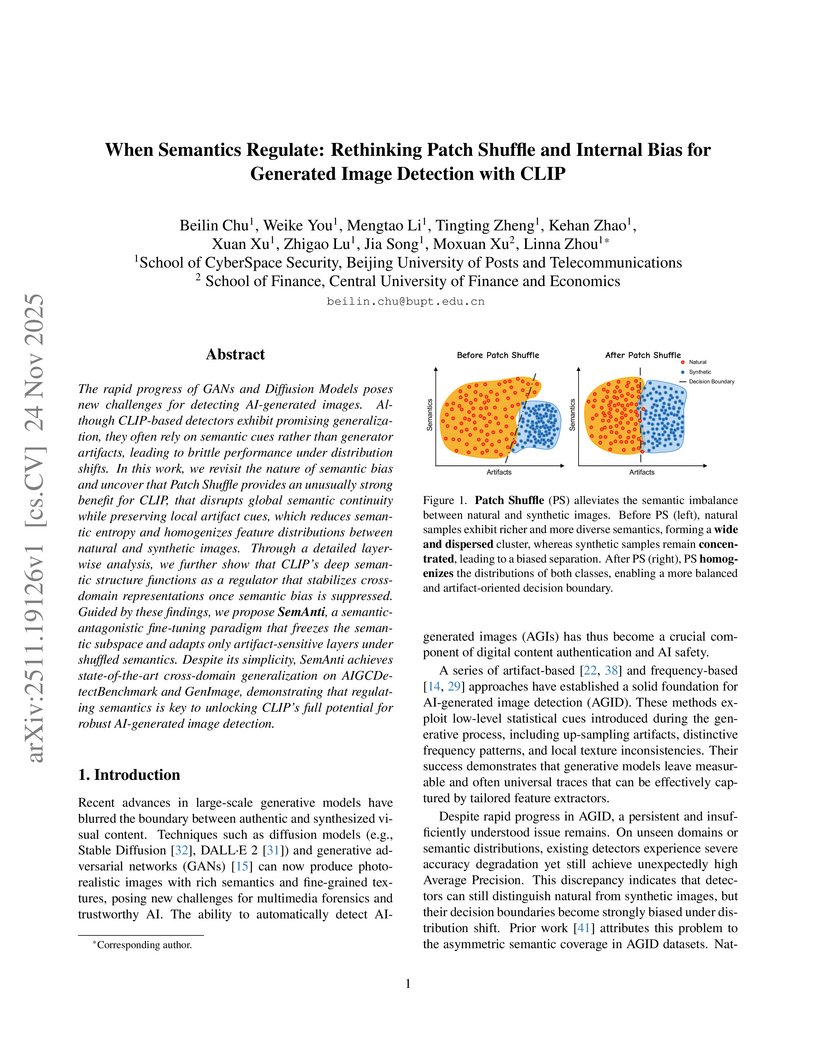
24 Nov 2025
The rapid progress of GANs and Diffusion Models poses new challenges for detecting AI-generated images. Although CLIP-based detectors exhibit promising generalization, they often rely on semantic cues rather than generator artifacts, leading to brittle performance under distribution shifts. In this work, we revisit the nature of semantic bias and uncover that Patch Shuffle provides an unusually strong benefit for CLIP, that disrupts global semantic continuity while preserving local artifact cues, which reduces semantic entropy and homogenizes feature distributions between natural and synthetic images. Through a detailed layer-wise analysis, we further show that CLIP's deep semantic structure functions as a regulator that stabilizes cross-domain representations once semantic bias is suppressed. Guided by these findings, we propose SemAnti, a semantic-antagonistic fine-tuning paradigm that freezes the semantic subspace and adapts only artifact-sensitive layers under shuffled semantics. Despite its simplicity, SemAnti achieves state-of-the-art cross-domain generalization on AIGCDetectBenchmark and GenImage, demonstrating that regulating semantics is key to unlocking CLIP's full potential for robust AI-generated image detection.

29 Sep 2025
The Heston stochastic-local volatility (HSLV) model is widely used to capture both market calibration and realistic volatility dynamics, but simulating its CIR-type variance process is numerically this http URL paper compare two alternative schemes for HSLV simulation: the truncated Euler method and the backward Euler method with the conventional Euler and almost exact simulation methods in \cite{van2014heston} by using a Monte Carlo this http URL results show that the truncated method achieves strong convergence and remains robust under high volatility, while the backward method provides the smallest errors and most stable performance in stress scenarios, though at higher computational cost.

08 Jun 2025

Large Language Models for code often entail significant computational complexity, which grows significantly with the length of the input code sequence. We propose LeanCode for code simplification to reduce training and prediction time, leveraging code contexts in utilizing attention scores to represent the tokens' importance. We advocate for the selective removal of tokens based on the average context-aware attention scores rather than average scores across all inputs. LeanCode uses the attention scores of `CLS' tokens within the encoder for classification tasks, such as code search. It also employs the encoder-decoder attention scores to determine token significance for sequence-to-sequence tasks like code summarization. Our evaluation shows LeanCode's superiority over the SOTAs DietCode and Slimcode, with improvements of 60% and 16% for code search, and 29% and 27% for code summarization, respectively.

23 May 2024

Graph Auto-Encoders (GAEs) are powerful tools for graph representation learning. In this paper, we develop a novel Hierarchical Cluster-based GAE (HC-GAE), that can learn effective structural characteristics for graph data analysis. To this end, during the encoding process, we commence by utilizing the hard node assignment to decompose a sample graph into a family of separated subgraphs. We compress each subgraph into a coarsened node, transforming the original graph into a coarsened graph. On the other hand, during the decoding process, we adopt the soft node assignment to reconstruct the original graph structure by expanding the coarsened nodes. By hierarchically performing the above compressing procedure during the decoding process as well as the expanding procedure during the decoding process, the proposed HC-GAE can effectively extract bidirectionally hierarchical structural features of the original sample graph. Furthermore, we re-design the loss function that can integrate the information from either the encoder or the decoder. Since the associated graph convolution operation of the proposed HC-GAE is restricted in each individual separated subgraph and cannot propagate the node information between different subgraphs, the proposed HC-GAE can significantly reduce the over-smoothing problem arising in the classical convolution-based GAEs. The proposed HC-GAE can generate effective representations for either node classification or graph classification, and the experiments demonstrate the effectiveness on real-world datasets.

13 Aug 2025
A BERT-based Hierarchical Classification Model with Applications in Chinese Commodity Classification
A BERT-based Hierarchical Classification Model with Applications in Chinese Commodity Classification

Existing e-commerce platforms heavily rely on manual annotation for product categorization, which is inefficient and inconsistent. These platforms often employ a hierarchical structure for categorizing products; however, few studies have leveraged this hierarchical information for classification. Furthermore, studies that consider hierarchical information fail to account for similarities and differences across various hierarchical categories. Herein, we introduce a large-scale hierarchical dataset collected from the JD e-commerce platform (this http URL), comprising 1,011,450 products with titles and a three-level category structure. By making this dataset openly accessible, we provide a valuable resource for researchers and practitioners to advance research and applications associated with product categorization. Moreover, we propose a novel hierarchical text classification approach based on the widely used Bidirectional Encoder Representations from Transformers (BERT), called Hierarchical Fine-tuning BERT (HFT-BERT). HFT-BERT leverages the remarkable text feature extraction capabilities of BERT, achieving prediction performance comparable to those of existing methods on short texts. Notably, our HFT-BERT model demonstrates exceptional performance in categorizing longer short texts, such as books.

24 Sep 2025

The rapid advancement of generative AI has democratized access to powerful tools such as Text-to-Image models. However, to generate high-quality images, users must still craft detailed prompts specifying scene, style, and context-often through multiple rounds of refinement. We propose PromptSculptor, a novel multi-agent framework that automates this iterative prompt optimization process. Our system decomposes the task into four specialized agents that work collaboratively to transform a short, vague user prompt into a comprehensive, refined prompt. By leveraging Chain-of-Thought reasoning, our framework effectively infers hidden context and enriches scene and background details. To iteratively refine the prompt, a self-evaluation agent aligns the modified prompt with the original input, while a feedback-tuning agent incorporates user feedback for further refinement. Experimental results demonstrate that PromptSculptor significantly enhances output quality and reduces the number of iterations needed for user satisfaction. Moreover, its model-agnostic design allows seamless integration with various T2I models, paving the way for industrial applications.

23 Apr 2021
Causality analysis is an important problem lying at the heart of science, and is of particular importance in data science and machine learning. An endeavor during the past 16 years viewing causality as real physical notion so as to formulate it from first principles, however, seems to go unnoticed. This study introduces to the community this line of work, with a long-due generalization of the information flow-based bivariate time series causal inference to multivariate series, based on the recent advance in theoretical development. The resulting formula is transparent, and can be implemented as a computationally very efficient algorithm for application. It can be normalized, and tested for statistical significance. Different from the previous work along this line where only information flows are estimated, here an algorithm is also implemented to quantify the influence of a unit to itself. While this forms a challenge in some causal inferences, here it comes naturally, and hence the identification of self-loops in a causal graph is fulfilled automatically as the causalities along edges are inferred.
To demonstrate the power of the approach, presented here are two applications in extreme situations. The first is a network of multivariate processes buried in heavy noises (with the noise-to-signal ratio exceeding 100), and the second a network with nearly synchronized chaotic oscillators. In both graphs, confounding processes exist. While it seems to be a huge challenge to reconstruct from given series these causal graphs, an easy application of the algorithm immediately reveals the desideratum. Particularly, the confounding processes have been accurately differentiated. Considering the surge of interest in the community, this study is very timely.

10 Jul 2024
Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.

20 Sep 2025

Traditional risk factors like beta, size/value, and momentum often lag behind market dynamics in measuring and predicting stock return volatility. Statistical models like PCA and factor analysis fail to capture hidden nonlinear relationships. Genetic programming (GP) can identify nonlinear factors but often lacks mechanisms for evaluating factor quality, and the resulting formulas are complex. To address these challenges, we propose a Hierarchical Proximal Policy Optimization (HPPO) framework for automated factor generation and evaluation. HPPO uses two PPO models: a high-level policy assigns weights to stock features, and a low-level policy identifies latent nonlinear relationships. The Pearson correlation between generated factors and return volatility serves as the reward signal. Transfer learning pre-trains the high-level policy on large-scale historical data, fine-tuning it with the latest data to adapt to new features and shifts. Experiments show the HPPO-TO algorithm achieves a 25\% excess return in HFT markets across China (CSI 300/800), India (Nifty 100), and the US (S\&P 500). Code and data are available at this https URL.

20 Sep 2025
In quantitative trading, transforming historical stock data into interpretable, formulaic risk factors enhances the identification of market volatility and risk. Despite recent advancements in neural networks for extracting latent risk factors, these models remain limited to feature extraction and lack explicit, formulaic risk factor designs. By viewing symbolic mathematics as a language where valid mathematical expressions serve as meaningful "sentences" we propose framing the task of mining formulaic risk factors as a language modeling problem. In this paper, we introduce an end to end methodology, Intraday Risk Factor Transformer (IRFT), to directly generate complete formulaic risk factors, including constants. We use a hybrid symbolic numeric vocabulary where symbolic tokens represent operators and stock features, and numeric tokens represent constants. We train a Transformer model on high frequency trading (HFT) datasets to generate risk factors without relying on a predefined skeleton of operators. It determines the general form of the stock volatility law, including constants. We refine the predicted constants using the Broyden Fletcher Goldfarb Shanno (BFGS) algorithm to mitigate non linear issues. Compared to the ten approaches in SRBench, an active benchmark for symbolic regression (SR), IRFT achieves a 30% higher investment return on the HS300 and SP500 datasets, while achieving inference times that are orders of magnitude faster than existing methods in HF risk factor mining tasks.

08 Aug 2024

For software testing research, Defects4J stands out as the primary benchmark
dataset, offering a controlled environment to study real bugs from prominent
open-source systems. However, prior research indicates that Defects4J might
include tests added post-bug report, embedding developer knowledge and
affecting fault localization efficacy. In this paper, we examine Defects4J's
fault-triggering tests, emphasizing the implications of developer knowledge of
SBFL techniques. We study the timelines of changes made to these tests
concerning bug report creation. Then, we study the effectiveness of SBFL
techniques without developer knowledge in the tests. We found that 1) 55% of
the fault-triggering tests were newly added to replicate the bug or to test for
regression; 2) 22% of the fault-triggering tests were modified after the bug
reports were created, containing developer knowledge of the bug; 3) developers
often modify the tests to include new assertions or change the test code to
reflect the changes in the source code; and 4) the performance of SBFL
techniques degrades significantly (up to --415% for Mean First Rank) when
evaluated on the bugs without developer knowledge. We provide a dataset of bugs
without developer insights, aiding future SBFL evaluations in Defects4J and
informing considerations for future bug benchmarks.
There are no more papers matching your filters at the moment.
