
27 Oct 2025

KungfuBot enables humanoid robots to learn and execute highly-dynamic human skills like martial arts and dancing by integrating a physics-based motion processing pipeline with an adaptive motion tracking mechanism. This approach allows zero-shot transfer to real robots, demonstrating superior tracking performance with a global mean per body position error of 53.25mm on easy motions, and robustly executing complex maneuvers on a Unitree G1 robot.
09 Oct 2025


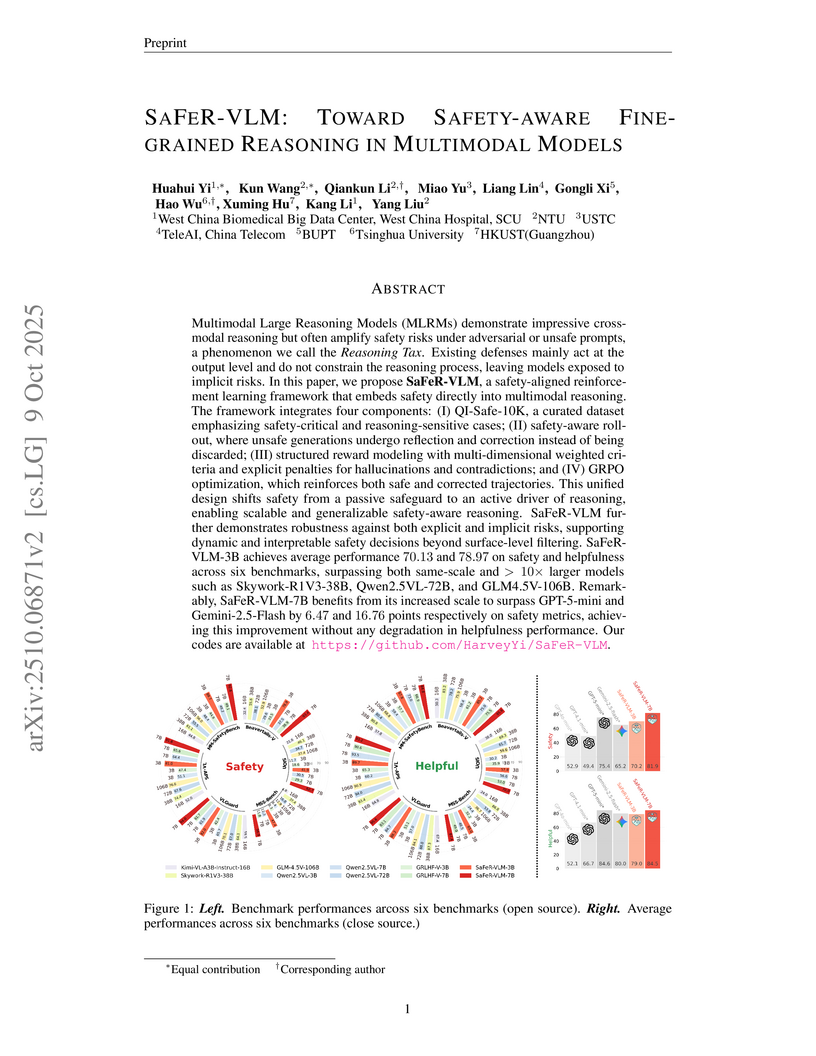
Multimodal Large Reasoning Models (MLRMs) demonstrate impressive cross-modal reasoning but often amplify safety risks under adversarial or unsafe prompts, a phenomenon we call the \textit{Reasoning Tax}. Existing defenses mainly act at the output level and do not constrain the reasoning process, leaving models exposed to implicit risks. In this paper, we propose SaFeR-VLM, a safety-aligned reinforcement learning framework that embeds safety directly into multimodal reasoning. The framework integrates four components: (I) QI-Safe-10K, a curated dataset emphasizing safety-critical and reasoning-sensitive cases; (II) safety-aware rollout, where unsafe generations undergo reflection and correction instead of being discarded; (III) structured reward modeling with multi-dimensional weighted criteria and explicit penalties for hallucinations and contradictions; and (IV) GRPO optimization, which reinforces both safe and corrected trajectories. This unified design shifts safety from a passive safeguard to an active driver of reasoning, enabling scalable and generalizable safety-aware reasoning. SaFeR-VLM further demonstrates robustness against both explicit and implicit risks, supporting dynamic and interpretable safety decisions beyond surface-level filtering. SaFeR-VLM-3B achieves average performance and on safety and helpfulness across six benchmarks, surpassing both same-scale and larger models such as Skywork-R1V3-38B, Qwen2.5VL-72B, and GLM4.5V-106B. Remarkably, SaFeR-VLM-7B benefits from its increased scale to surpass GPT-5-mini and Gemini-2.5-Flash by \num{6.47} and \num{16.76} points respectively on safety metrics, achieving this improvement without any degradation in helpfulness performance. Our codes are available at this https URL.

05 Sep 2025

WenetSpeech-Yue introduces the largest open-source Cantonese speech corpus, containing over 21,800 hours of multi-dimensionally annotated audio, along with comprehensive evaluation benchmarks. This resource enables the development of state-of-the-art Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) models for Cantonese, significantly advancing speech technology for the dialect.

29 Sep 2025
While emotional text-to-speech (TTS) has made significant progress, most existing research remains limited to utterance-level emotional expression and fails to support word-level control. Achieving word-level expressive control poses fundamental challenges, primarily due to the complexity of modeling multi-emotion transitions and the scarcity of annotated datasets that capture intra-sentence emotional and prosodic variation. In this paper, we propose WeSCon, the first self-training framework that enables word-level control of both emotion and speaking rate in a pretrained zero-shot TTS model, without relying on datasets containing intra-sentence emotion or speed transitions. Our method introduces a transition-smoothing strategy and a dynamic speed control mechanism to guide the pretrained TTS model in performing word-level expressive synthesis through a multi-round inference process. To further simplify the inference, we incorporate a dynamic emotional attention bias mechanism and fine-tune the model via self-training, thereby activating its ability for word-level expressive control in an end-to-end manner. Experimental results show that WeSCon effectively overcomes data scarcity, achieving state-of-the-art performance in word-level emotional expression control while preserving the strong zero-shot synthesis capabilities of the original TTS model.

21 Nov 2025
UniModel introduces a visual-only framework that unifies multimodal understanding and generation by representing both text and images as pixel-level data within a single diffusion transformer. This approach enables coherent text-to-image generation and image captioning, demonstrating strong cycle consistency and emergent controllability by operating entirely in a shared visual latent space.

14 Oct 2025

PRODVA, developed by researchers at East China Normal University and collaborators, generates protein sequences that are both functionally aligned with text descriptions and structurally plausible. This method achieved 77% of designs with pLDDT > 70 and outperformed prior state-of-the-art models in foldability while utilizing less than 0.04% of their training data.

05 Dec 2025
Egocentric AI assistants in real-world settings must process multi-modal inputs (video, audio, text), respond in real time, and retain evolving long-term memory. However, existing benchmarks typically evaluate these abilities in isolation, lack realistic streaming scenarios, or support only short-term tasks. We introduce \textbf{TeleEgo}, a long-duration, streaming, omni-modal benchmark for evaluating egocentric AI assistants in realistic daily contexts. The dataset features over 14 hours per participant of synchronized egocentric video, audio, and text across four domains: work \& study, lifestyle \& routines, social activities, and outings \& culture. All data is aligned on a unified global timeline and includes high-quality visual narrations and speech transcripts, curated through human this http URL defines 12 diagnostic subtasks across three core capabilities: Memory (recalling past events), Understanding (interpreting the current moment), and Cross-Memory Reasoning (linking distant events). It contains 3,291 human-verified QA items spanning multiple question formats (single-choice, binary, multi-choice, and open-ended), evaluated strictly in a streaming setting. We propose Real-Time Accuracy (RTA) to jointly capture correctness and responsiveness under tight decision windows, and Memory Persistence Time (MPT) as a forward-looking metric for long-term retention in continuous streams. In this work, we report RTA results for current models and release TeleEgo, together with an MPT evaluation framework, as a realistic and extensible benchmark for future egocentric assistants with stronger streaming memory, enabling systematic study of both real-time behavior and long-horizon memory.

12 Aug 2025

Large Vision-Language Models face growing safety challenges with multimodal inputs. This paper introduces the concept of Implicit Reasoning Safety, a vulnerability in LVLMs. Benign combined inputs trigger unsafe LVLM outputs due to flawed or hidden reasoning. To showcase this, we developed Safe Semantics, Unsafe Interpretations, the first dataset for this critical issue. Our demonstrations show that even simple In-Context Learning with SSUI significantly mitigates these implicit multimodal threats, underscoring the urgent need to improve cross-modal implicit reasoning.

23 Sep 2025

Extensive research has been conducted to explore the capabilities of large language models (LLMs) in table reasoning. However, the essential task of transforming tables information into reports remains a significant challenge for industrial applications. This task is plagued by two critical issues: 1) the complexity and diversity of tables lead to suboptimal reasoning outcomes; and 2) existing table benchmarks lack the capacity to adequately assess the practical application of this task. To fill this gap, we propose the table-to-report task and construct a bilingual benchmark named T2R-bench, where the key information flow from the tables to the reports for this task. The benchmark comprises 457 industrial tables, all derived from real-world scenarios and encompassing 19 industry domains as well as 4 types of industrial tables. Furthermore, we propose an evaluation criteria to fairly measure the quality of report generation. The experiments on 25 widely-used LLMs reveal that even state-of-the-art models like Deepseek-R1 only achieves performance with 62.71 overall score, indicating that LLMs still have room for improvement on T2R-bench.

22 Sep 2025

The paper introduces WenetSpeech-Chuan, the largest open-source corpus for Sichuanese dialects, containing over 10,000 hours of richly annotated audio. This resource, coupled with a systematic data processing pipeline, facilitates state-of-the-art Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) for Sichuanese, achieving performance competitive with commercial systems and significantly surpassing existing open-source models.

29 Sep 2025

Researchers introduced Reinforced Advantage (ReAd), a closed-loop framework integrating Multi-Agent Reinforcement Learning (MARL) advantage functions to provide principled feedback for Large Language Model (LLM) planning in embodied multi-agent tasks. This approach reduces environmental interactions and LLM queries, achieving superior task success rates and efficiency across various multi-robot and cooperative benchmarks.

20 Jun 2025
The proliferation of generative models has raised serious concerns about visual content forgery. Existing deepfake detection methods primarily target either image-level classification or pixel-wise localization. While some achieve high accuracy, they often suffer from limited generalization across manipulation types or rely on complex architectures. In this paper, we propose Loupe, a lightweight yet effective framework for joint deepfake detection and localization. Loupe integrates a patch-aware classifier and a segmentation module with conditional queries, allowing simultaneous global authenticity classification and fine-grained mask prediction. To enhance robustness against distribution shifts of test set, Loupe introduces a pseudo-label-guided test-time adaptation mechanism by leveraging patch-level predictions to supervise the segmentation head. Extensive experiments on the DDL dataset demonstrate that Loupe achieves state-of-the-art performance, securing the first place in the IJCAI 2025 Deepfake Detection and Localization Challenge with an overall score of 0.846. Our results validate the effectiveness of the proposed patch-level fusion and conditional query design in improving both classification accuracy and spatial localization under diverse forgery patterns. The code is available at this https URL.

25 Sep 2025
Perceptual studies demonstrate that conditional diffusion models excel at reconstructing video content aligned with human visual perception. Building on this insight, we propose a video compression framework that leverages conditional diffusion models for perceptually optimized reconstruction. Specifically, we reframe video compression as a conditional generation task, where a generative model synthesizes video from sparse, yet informative signals. Our approach introduces three key modules: (1) Multi-granular conditioning that captures both static scene structure and dynamic spatio-temporal cues; (2) Compact representations designed for efficient transmission without sacrificing semantic richness; (3) Multi-condition training with modality dropout and role-aware embeddings, which prevent over-reliance on any single modality and enhance robustness. Extensive experiments show that our method significantly outperforms both traditional and neural codecs on perceptual quality metrics such as Fréchet Video Distance (FVD) and LPIPS, especially under high compression ratios.

16 Jun 2025
Large-scale training corpora have significantly improved the performance of
ASR models. Unfortunately, due to the relative scarcity of data, Chinese
accents and dialects remain a challenge for most ASR models. Recent
advancements in self-supervised learning have shown that self-supervised
pre-training, combined with large language models (LLM), can effectively
enhance ASR performance in low-resource scenarios. We aim to investigate the
effectiveness of this paradigm for Chinese dialects. Specifically, we pre-train
a Data2vec2 model on 300,000 hours of unlabeled dialect and accented speech
data and do alignment training on a supervised dataset of 40,000 hours. Then,
we systematically examine the impact of various projectors and LLMs on
Mandarin, dialect, and accented speech recognition performance under this
paradigm. Our method achieved SOTA results on multiple dialect datasets,
including Kespeech. We will open-source our work to promote reproducible
research

07 Jul 2025
With the rise of diffusion models, audio-video generation has been revolutionized. However, most existing methods rely on separate modules for each modality, with limited exploration of unified generative architectures. In addition, many are confined to a single task and small-scale datasets. To overcome these limitations, we introduce UniForm, a unified multi-task diffusion transformer that generates both audio and visual modalities in a shared latent space. By using a unified denoising network, UniForm captures the inherent correlations between sound and vision. Additionally, we propose task-specific noise schemes and task tokens, enabling the model to support multiple tasks with a single set of parameters, including video-to-audio, audio-to-video and text-to-audio-video generation. Furthermore, by leveraging large language models and a large-scale text-audio-video combined dataset, UniForm achieves greater generative diversity than prior approaches. Experiments show that UniForm achieves performance close to the state-of-the-art single-task models across three generation tasks, with generated content that is not only highly aligned with real-world data distributions but also enables more diverse and fine-grained generation.

11 Nov 2025
 University of Science and Technology of ChinaHarbin Institute of TechnologyShanghaiTech UniversityChina TelecomHarbin Engineering UniversityInstitute of Artificial Intelligence (TeleAI), China TelecomNational Engineering Laboratory for Modeling and Emulation in E-Government, Harbin Engineering UniversityNational Engineering Laboratory for Modeling and Emulation in E-Government
University of Science and Technology of ChinaHarbin Institute of TechnologyShanghaiTech UniversityChina TelecomHarbin Engineering UniversityInstitute of Artificial Intelligence (TeleAI), China TelecomNational Engineering Laboratory for Modeling and Emulation in E-Government, Harbin Engineering UniversityNational Engineering Laboratory for Modeling and Emulation in E-GovernmentHumanoid robots are promising to learn a diverse set of human-like locomotion behaviors, including standing up, walking, running, and jumping. However, existing methods predominantly require training independent policies for each skill, yielding behavior-specific controllers that exhibit limited generalization and brittle performance when deployed on irregular terrains and in diverse situations. To address this challenge, we propose Adaptive Humanoid Control (AHC) that adopts a two-stage framework to learn an adaptive humanoid locomotion controller across different skills and terrains. Specifically, we first train several primary locomotion policies and perform a multi-behavior distillation process to obtain a basic multi-behavior controller, facilitating adaptive behavior switching based on the environment. Then, we perform reinforced fine-tuning by collecting online feedback in performing adaptive behaviors on more diverse terrains, enhancing terrain adaptability for the controller. We conduct experiments in both simulation and real-world experiments in Unitree G1 robots. The results show that our method exhibits strong adaptability across various situations and terrains. Project website: this https URL.

11 Aug 2025
Aerial Vision-and-Language Navigation (VLN) is a novel task enabling Unmanned Aerial Vehicles (UAVs) to navigate in outdoor environments through natural language instructions and visual cues. However, it remains challenging due to the complex spatial relationships in aerial this http URL this paper, we propose a training-free, zero-shot framework for aerial VLN tasks, where the large language model (LLM) is leveraged as the agent for action prediction. Specifically, we develop a novel Semantic-Topo-Metric Representation (STMR) to enhance the spatial reasoning capabilities of LLMs. This is achieved by extracting and projecting instruction-related semantic masks onto a top-down map, which presents spatial and topological information about surrounding landmarks and grows during the navigation process. At each step, a local map centered at the UAV is extracted from the growing top-down map, and transformed into a ma trix representation with distance metrics, serving as the text prompt to LLM for action prediction in response to the given instruction. Experiments conducted in real and simulation environments have proved the effectiveness and robustness of our method, achieving absolute success rate improvements of 26.8% and 5.8% over current state-of-the-art methods on simple and complex navigation tasks, respectively. The dataset and code will be released soon.

24 Jul 2025
Pioneered by the foundational information theory by Claude Shannon and the visionary framework of machine intelligence by Alan Turing, the convergent evolution of information and communication technologies (IT/CT) has created an unbroken wave of connectivity and computation. This synergy has sparked a technological revolution, now reaching its peak with large artificial intelligence (AI) models that are reshaping industries and redefining human-machine collaboration. However, the realization of ubiquitous intelligence faces considerable challenges due to substantial resource consumption in large models and high communication bandwidth demands. To address these challenges, AI Flow has been introduced as a multidisciplinary framework that integrates cutting-edge IT and CT advancements, with a particular emphasis on the following three key points. First, device-edge-cloud framework serves as the foundation, which integrates end devices, edge servers, and cloud clusters to optimize scalability and efficiency for low-latency model inference. Second, we introduce the concept of familial models, which refers to a series of different-sized models with aligned hidden features, enabling effective collaboration and the flexibility to adapt to varying resource constraints and dynamic scenarios. Third, connectivity- and interaction-based intelligence emergence is a novel paradigm of AI Flow. By leveraging communication networks to enhance connectivity, the collaboration among AI models across heterogeneous nodes achieves emergent intelligence that surpasses the capability of any single model. The innovations of AI Flow provide enhanced intelligence, timely responsiveness, and ubiquitous accessibility to AI services, paving the way for the tighter fusion of AI techniques and communication systems.

24 Oct 2025
A generalizable reward model is crucial in Reinforcement Learning from Human Feedback (RLHF) as it enables correctly evaluating unseen prompt-response pairs. However, existing reward models lack this ability, as they are typically trained by increasing the reward gap between chosen and rejected responses, while overlooking the prompts that the responses are conditioned on. Consequently, when the trained reward model is evaluated on prompt-response pairs that lie outside the data distribution, neglecting the effect of prompts may result in poor generalization of the reward model. To address this issue, we decompose the reward value into two independent components: prompt-free reward and prompt-related reward. Prompt-free reward represents the evaluation that is determined only by responses, while the prompt-related reward reflects the reward that derives from both the prompt and the response. We extract these two components from an information-theoretic perspective, which requires no extra models. Subsequently, we propose a new reward learning algorithm by prioritizing data samples based on their prompt-free reward values. Through toy examples, we demonstrate that the extracted prompt-free and prompt-related rewards effectively characterize two parts of the reward model. Further, standard evaluations show that our method improves both the alignment performance and the generalization capability of the reward model.

25 Oct 2024

Humans possess a remarkable talent for flexibly alternating to different senses when interacting with the environment. Picture a chef skillfully gauging the timing of ingredient additions and controlling the heat according to the colors, sounds, and aromas, seamlessly navigating through every stage of the complex cooking process. This ability is founded upon a thorough comprehension of task stages, as achieving the sub-goal within each stage can necessitate the utilization of different senses. In order to endow robots with similar ability, we incorporate the task stages divided by sub-goals into the imitation learning process to accordingly guide dynamic multi-sensory fusion. We propose MS-Bot, a stage-guided dynamic multi-sensory fusion method with coarse-to-fine stage understanding, which dynamically adjusts the priority of modalities based on the fine-grained state within the predicted current stage. We train a robot system equipped with visual, auditory, and tactile sensors to accomplish challenging robotic manipulation tasks: pouring and peg insertion with keyway. Experimental results indicate that our approach enables more effective and explainable dynamic fusion, aligning more closely with the human fusion process than existing methods.
There are no more papers matching your filters at the moment.
