
24 Jul 2025







Researchers demonstrate that model tampering attacks enable more rigorous evaluation of Large Language Model (LLM) capabilities, revealing that current unlearning and jailbreaking resistance mechanisms are fragile and that these internal manipulations effectively predict vulnerabilities to unforeseen input-space attacks.

19 Nov 2025


Learning how the world works is central to building AI agents that can adapt to complex environments. Traditional world models based on deep learning demand vast amounts of training data, and do not flexibly update their knowledge from sparse observations. Recent advances in program synthesis using Large Language Models (LLMs) give an alternate approach which learns world models represented as source code, supporting strong generalization from little data. To date, application of program-structured world models remains limited to natural language and grid-world domains. We introduce a novel program synthesis method for effectively modeling complex, non-gridworld domains by representing a world model as an exponentially-weighted product of programmatic experts (PoE-World) synthesized by LLMs. We show that this approach can learn complex, stochastic world models from just a few observations. We evaluate the learned world models by embedding them in a model-based planning agent, demonstrating efficient performance and generalization to unseen levels on Atari's Pong and Montezuma's Revenge. We release our code and display the learned world models and videos of the agent's gameplay at this https URL.

15 Nov 2023

We give a presentation by generators and relations of the group of Clifford+T operators on two qubits. The proof relies on an application of the Reidemeister-Schreier theorem to an earlier result of Greylyn, and has been formally verified in the proof assistant Agda.

25 Sep 2024



This research introduces Stochastic Control Guidance (SCG), a method enabling diffusion models to be steered by non-differentiable or black-box rules, applying it to generate high-resolution symbolic music. The approach significantly improves adherence to specified musical constraints and produces music with higher objective quality and better perceived musicality compared to previous methods.

30 Oct 2024


This research introduces Representation Noising (RepNoise), a pre-release defense mechanism designed to immunize Large Language Models against harmful fine-tuning attacks. The method makes it significantly harder for malicious actors to fine-tune models for undesirable behaviors by fundamentally altering internal representations, while preserving the model's general utility and ability to be fine-tuned for harmless tasks.

02 Aug 2025
Physicians spend significant time documenting clinical encounters, a burden that contributes to professional burnout. To address this, robust automation tools for medical documentation are crucial. We introduce MedSynth -- a novel dataset of synthetic medical dialogues and notes designed to advance the Dialogue-to-Note (Dial-2-Note) and Note-to-Dialogue (Note-2-Dial) tasks. Informed by an extensive analysis of disease distributions, this dataset includes over 10,000 dialogue-note pairs covering over 2000 ICD-10 codes. We demonstrate that our dataset markedly enhances the performance of models in generating medical notes from dialogues, and dialogues from medical notes. The dataset provides a valuable resource in a field where open-access, privacy-compliant, and diverse training data are scarce. Code is available at this https URL and the dataset is available at this https URL.

31 Aug 2023
We give a presentation by generators and relations of the group of 3-qubit Clifford+CS operators. The proof roughly consists of two parts: (1) applying the Reidemeister-Schreier theorem recursively to an earlier result of ours; and (2) the simplification of thousands of relations into 17 relations. Both (1) and (2) have been formally verified in the proof assistant Agda. The Reidemeister-Schreier theorem gives a constructive method for computing a presentation of a sub-monoid given a presentation of the super-monoid. To achieve (2), we devise an almost-normal form for Clifford+CS operators. Along the way, we also identify several interesting structures within the Clifford+CS group. Specifically, we identify three different finite subgroups for whose elements we can give unique normal forms. We show that the 3-qubit Clifford+CS group, which is of course infinite, is the amalgamated product of these three finite subgroups. This result is analogous to the fact that the 1-qubit Clifford+T group is an amalgamated product of two finite subgroups.
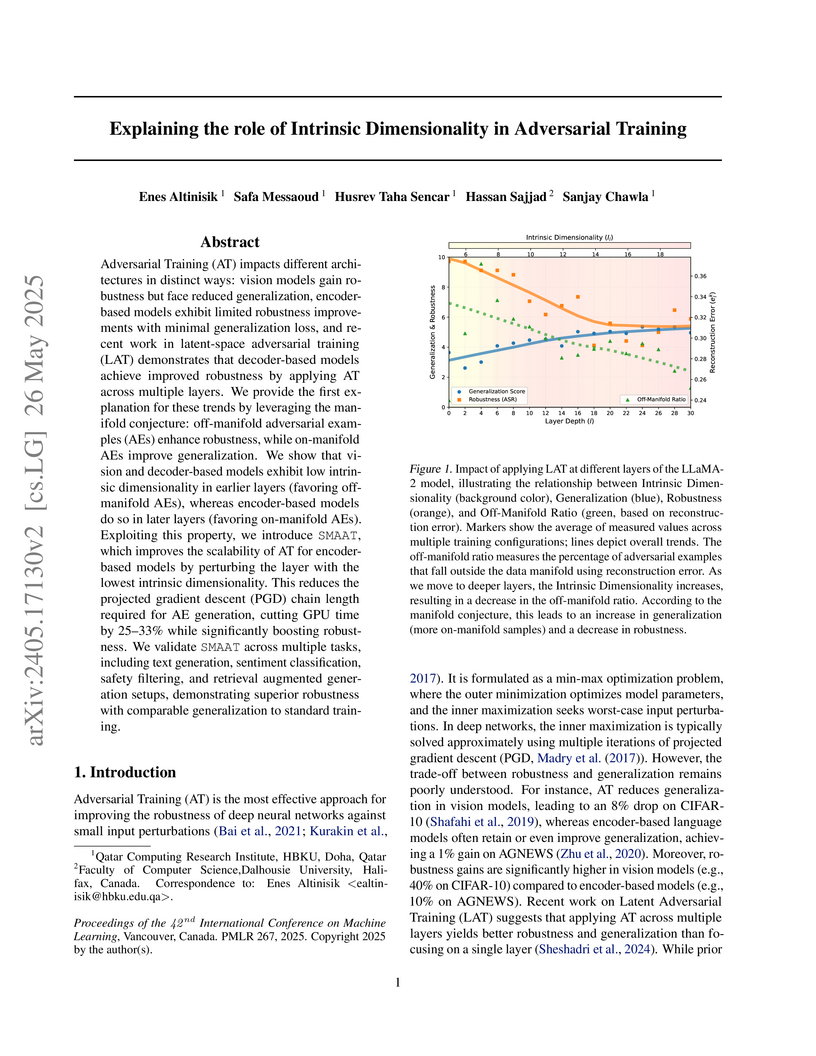
26 May 2025
Adversarial Training (AT) impacts different architectures in distinct ways: vision models gain robustness but face reduced generalization, encoder-based models exhibit limited robustness improvements with minimal generalization loss, and recent work in latent-space adversarial training (LAT) demonstrates that decoder-based models achieve improved robustness by applying AT across multiple layers. We provide the first explanation for these trends by leveraging the manifold conjecture: off-manifold adversarial examples (AEs) enhance robustness, while on-manifold AEs improve generalization. We show that vision and decoder-based models exhibit low intrinsic dimensionality in earlier layers (favoring off-manifold AEs), whereas encoder-based models do so in later layers (favoring on-manifold AEs). Exploiting this property, we introduce SMAAT, which improves the scalability of AT for encoder-based models by perturbing the layer with the lowest intrinsic dimensionality. This reduces the projected gradient descent (PGD) chain length required for AE generation, cutting GPU time by 25-33% while significantly boosting robustness. We validate SMAAT across multiple tasks, including text generation, sentiment classification, safety filtering, and retrieval augmented generation setups, demonstrating superior robustness with comparable generalization to standard training.

18 Jun 2025




Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.

18 Apr 2023
Promptify, an interactive system developed by the University of Toronto and Dalhousie University, integrates large language models (LLMs) and visual tools to streamline text-to-image generation. It assists users in crafting effective prompts and managing generated images, leading to more aesthetically pleasing initial outputs and reduced user frustration compared to existing interfaces.

21 Jun 2024
The emergence of 5G technology marks a significant milestone in developing telecommunication networks, enabling exciting new applications such as augmented reality and self-driving vehicles. However, these improvements bring an increased management complexity and a special concern in dealing with failures, as the applications 5G intends to support heavily rely on high network performance and low latency. Thus, automatic self-healing solutions have become effective in dealing with this requirement, allowing a learning-based system to automatically detect anomalies and perform Root Cause Analysis (RCA). However, there are inherent challenges to the implementation of such intelligent systems. First, there is a lack of suitable data for anomaly detection and RCA, as labelled data for failure scenarios is uncommon. Secondly, current intelligent solutions are tailored to LTE networks and do not fully capture the spatio-temporal characteristics present in the data. Considering this, we utilize a calibrated simulator, Simu5G, and generate open-source data for normal and failure scenarios. Using this data, we propose Simba, a state-of-the-art approach for anomaly detection and root cause analysis in 5G Radio Access Networks (RANs). We leverage Graph Neural Networks to capture spatial relationships while a Transformer model is used to learn the temporal dependencies of the data. We implement a prototype of Simba and evaluate it over multiple failures. The outcomes are compared against existing solutions to confirm the superiority of Simba.

15 Jul 2025

Researchers from Columbia University, Dalhousie University, and Stevens Institute of Technology investigate how knowledge is structured within LLM circuits by integrating circuit extraction with knowledge editing. Their work demonstrates that automatically extracted circuits store knowledge and exhibit resistance to modification, with LayerNorm layers surprisingly playing a substantial role in these knowledge-bearing subnetworks.

21 Feb 2025
Consistency is a fundamental dimension of trustworthiness in Large Language
Models (LLMs). For humans to be able to trust LLM-based applications, their
outputs should be consistent when prompted with inputs that carry the same
meaning or intent. Despite this need, there is no known mechanism to control
and guide LLMs to be more consistent at inference time. In this paper, we
introduce a novel alignment strategy to maximize semantic consistency in LLM
outputs. Our proposal is based on Chain of Guidance (CoG), a multistep
prompting technique that generates highly consistent outputs from LLMs. For
closed-book question-answering (Q&A) tasks, when compared to direct prompting,
the outputs generated using CoG show improved consistency. While other
approaches like template-based responses and majority voting may offer
alternative paths to consistency, our work focuses on exploring the potential
of guided prompting. We use synthetic data sets comprised of consistent
input-output pairs to fine-tune LLMs to produce consistent and correct outputs.
Our fine-tuned models are more than twice as consistent compared to base models
and show strong generalization capabilities by producing consistent outputs
over datasets not used in the fine-tuning process.

11 Oct 2024
This paper demonstrates that Large Language Models (LLMs) can generate highly convincing explanations for *incorrect* answers, a phenomenon termed "adversarial helpfulness." It finds that LLMs achieve this by employing specific persuasive strategies and relying on superficial textual patterns rather than deep logical reasoning, causing human perception of an incorrect answer's convincingness to increase.

06 Oct 2025

Bangla is a language spoken by approximately 240 million native speakers and around 300 million people worldwide. Despite being the 5th largest spoken language in the world, Bangla is still a "low-resource" language, and existing pretrained language models often struggle to perform well on Bangla Language Processing (BLP) tasks. This paper addresses this gap by: (1) introducing two high-quality translated Bangla-instruction datasets totaling 224k samples - Bangla-Orca (172k) and Bangla-Alpaca (52k); and (2) leveraging these datasets to develop BanglaLlama, an open-source family of Bangla-specific LLMs, consisting of five base and instruct variants. We present our methodology, two large datasets, and comprehensive benchmarking results showcasing the effectiveness of our dataset and model on multiple benchmarks. We believe our proposed datasets and models will serve as the new standard baseline for future research focused on this widely spoken yet "low-resource" language.

21 May 2025
Hidden Markov models (HMMs) are widely applied in studies where a discrete-valued process of interest is observed indirectly. They have for example been used to model behaviour from human and animal tracking data, disease status from medical data, and financial market volatility from stock prices. The model has two main sets of parameters: transition probabilities, which drive the latent state process, and observation parameters, which characterise the state-dependent distributions of observed variables. One particularly useful extension of HMMs is the inclusion of covariates on those parameters, to investigate the drivers of state transitions or to implement Markov-switching regression models. We present the new R package hmmTMB for HMM analyses, with flexible covariate models in both the hidden state and observation parameters. In particular, non-linear effects are implemented using penalised splines, including multiple univariate and multivariate splines, with automatic smoothness selection. The package allows for various random effect formulations (including random intercepts and slopes), to capture between-group heterogeneity. hmmTMB can be applied to multivariate observations, and it accommodates various types of response data, including continuous (bounded or not), discrete, and binary variables. Parameter constraints can be used to implement non-standard dependence structures, such as semi-Markov, higher-order Markov, and autoregressive models. Here, we summarise the relevant statistical methodology, we describe the structure of the package, and we present an example analysis of animal tracking data to showcase the workflow of the package.
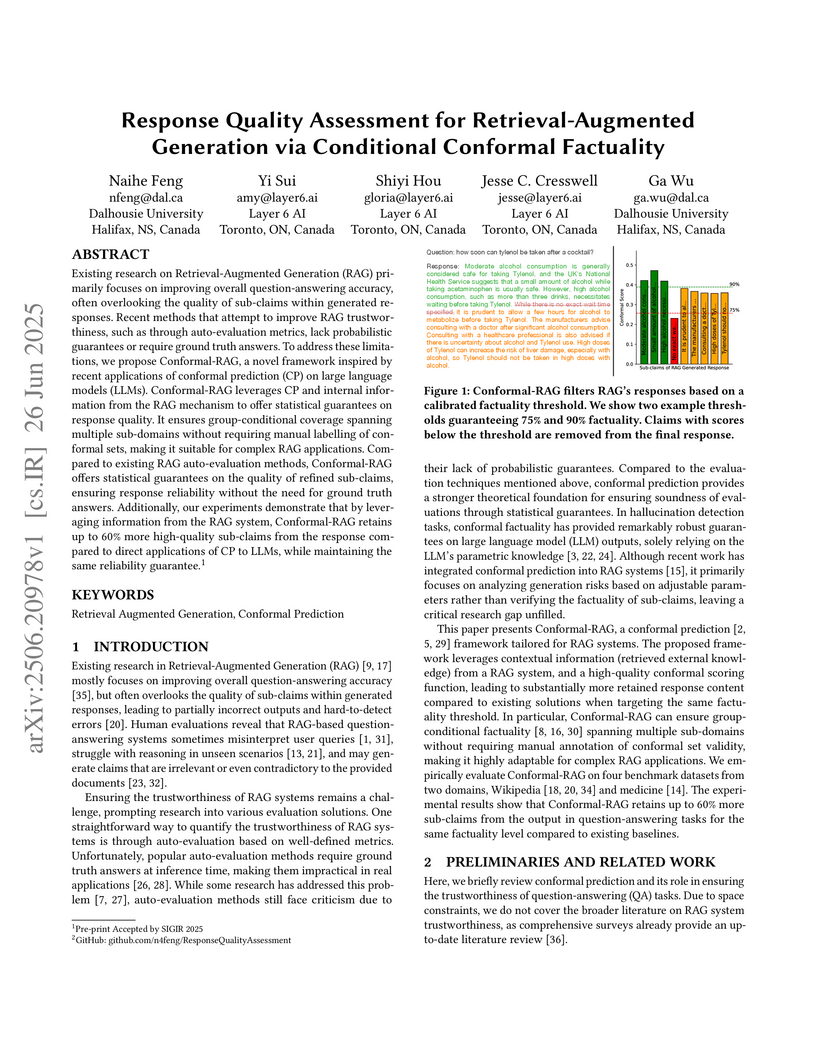
26 Jun 2025
Existing research on Retrieval-Augmented Generation (RAG) primarily focuses on improving overall question-answering accuracy, often overlooking the quality of sub-claims within generated responses. Recent methods that attempt to improve RAG trustworthiness, such as through auto-evaluation metrics, lack probabilistic guarantees or require ground truth answers. To address these limitations, we propose Conformal-RAG, a novel framework inspired by recent applications of conformal prediction (CP) on large language models (LLMs). Conformal-RAG leverages CP and internal information from the RAG mechanism to offer statistical guarantees on response quality. It ensures group-conditional coverage spanning multiple sub-domains without requiring manual labelling of conformal sets, making it suitable for complex RAG applications. Compared to existing RAG auto-evaluation methods, Conformal-RAG offers statistical guarantees on the quality of refined sub-claims, ensuring response reliability without the need for ground truth answers. Additionally, our experiments demonstrate that by leveraging information from the RAG system, Conformal-RAG retains up to 60\% more high-quality sub-claims from the response compared to direct applications of CP to LLMs, while maintaining the same reliability guarantee.

22 Aug 2014
We describe a new method for the decomposition of an arbitrary qubit
operator with entries in , i.e., of the form
, into Clifford+ operators
where . This method achieves a bound of gates using at most one
ancilla using decomposition into - and -level matrices which was first
proposed by Giles and Selinger.

10 Nov 2025
The emergence of Large Language Models (LLMs) as chat assistants capable of generating human-like conversations has amplified the need for robust evaluation methods, particularly for open-ended tasks. Conventional metrics such as EM and F1, while useful, are inadequate for capturing the full semantics and contextual depth of such generative outputs. We propose a reference-guided verdict method that automates the evaluation process by leveraging multiple LLMs as judges. Through experiments on free-form question-answering tasks, we demonstrate that combining multiple models improves the reliability and accuracy of evaluations, especially in tasks where a single model may struggle. The results indicate a strong correlation with human evaluations, establishing the proposed method as a reliable alternative to traditional metrics.

16 May 2024
We introduce and make publicly available the NIFTY Financial News Headlines dataset, designed to facilitate and advance research in financial market forecasting using large language models (LLMs). This dataset comprises two distinct versions tailored for different modeling approaches: (i) NIFTY-LM, which targets supervised fine-tuning (SFT) of LLMs with an auto-regressive, causal language-modeling objective, and (ii) NIFTY-RL, formatted specifically for alignment methods (like reinforcement learning from human feedback (RLHF)) to align LLMs via rejection sampling and reward modeling. Each dataset version provides curated, high-quality data incorporating comprehensive metadata, market indices, and deduplicated financial news headlines systematically filtered and ranked to suit modern LLM frameworks. We also include experiments demonstrating some applications of the dataset in tasks like stock price movement and the role of LLM embeddings in information acquisition/richness. The NIFTY dataset along with utilities (like truncating prompt's context length systematically) are available on Hugging Face at this https URL.
There are no more papers matching your filters at the moment.
