
06 Dec 2022




Geometry problem solving is a well-recognized testbed for evaluating the
high-level multi-modal reasoning capability of deep models. In most existing
works, two main geometry problems: calculation and proving, are usually treated
as two specific tasks, hindering a deep model to unify its reasoning capability
on multiple math tasks. However, in essence, these two tasks have similar
problem representations and overlapped math knowledge which can improve the
understanding and reasoning ability of a deep model on both two tasks.
Therefore, we construct a large-scale Unified Geometry problem benchmark,
UniGeo, which contains 4,998 calculation problems and 9,543 proving problems.
Each proving problem is annotated with a multi-step proof with reasons and
mathematical expressions. The proof can be easily reformulated as a proving
sequence that shares the same formats with the annotated program sequence for
calculation problems. Naturally, we also present a unified multi-task Geometric
Transformer framework, Geoformer, to tackle calculation and proving problems
simultaneously in the form of sequence generation, which finally shows the
reasoning ability can be improved on both two tasks by unifying formulation.
Furthermore, we propose a Mathematical Expression Pretraining (MEP) method that
aims to predict the mathematical expressions in the problem solution, thus
improving the Geoformer model. Experiments on the UniGeo demonstrate that our
proposed Geoformer obtains state-of-the-art performance by outperforming
task-specific model NGS with over 5.6% and 3.2% accuracies on calculation and
proving problems, respectively.

16 Sep 2024




Following the advancements in text-guided image generation technology exemplified by Stable Diffusion, video generation is gaining increased attention in the academic community. However, relying solely on text guidance for video generation has serious limitations, as videos contain much richer content than images, especially in terms of motion. This information can hardly be adequately described with plain text. Fortunately, in computer vision, various visual representations can serve as additional control signals to guide generation. With the help of these signals, video generation can be controlled in finer detail, allowing for greater flexibility for different applications. Integrating various controls, however, is nontrivial. In this paper, we propose a universal framework called EasyControl. By propagating and injecting condition features through condition adapters, our method enables users to control video generation with a single condition map. With our framework, various conditions including raw pixels, depth, HED, etc., can be integrated into different Unet-based pre-trained video diffusion models at a low practical cost. We conduct comprehensive experiments on public datasets, and both quantitative and qualitative results indicate that our method outperforms state-of-the-art methods. EasyControl significantly improves various evaluation metrics across multiple validation datasets compared to previous works. Specifically, for the sketch-to-video generation task, EasyControl achieves an improvement of 152.0 on FVD and 19.9 on IS, respectively, in UCF101 compared with VideoComposer. For fidelity, our model demonstrates powerful image retention ability, resulting in high FVD and IS in UCF101 and MSR-VTT compared to other image-to-video models.
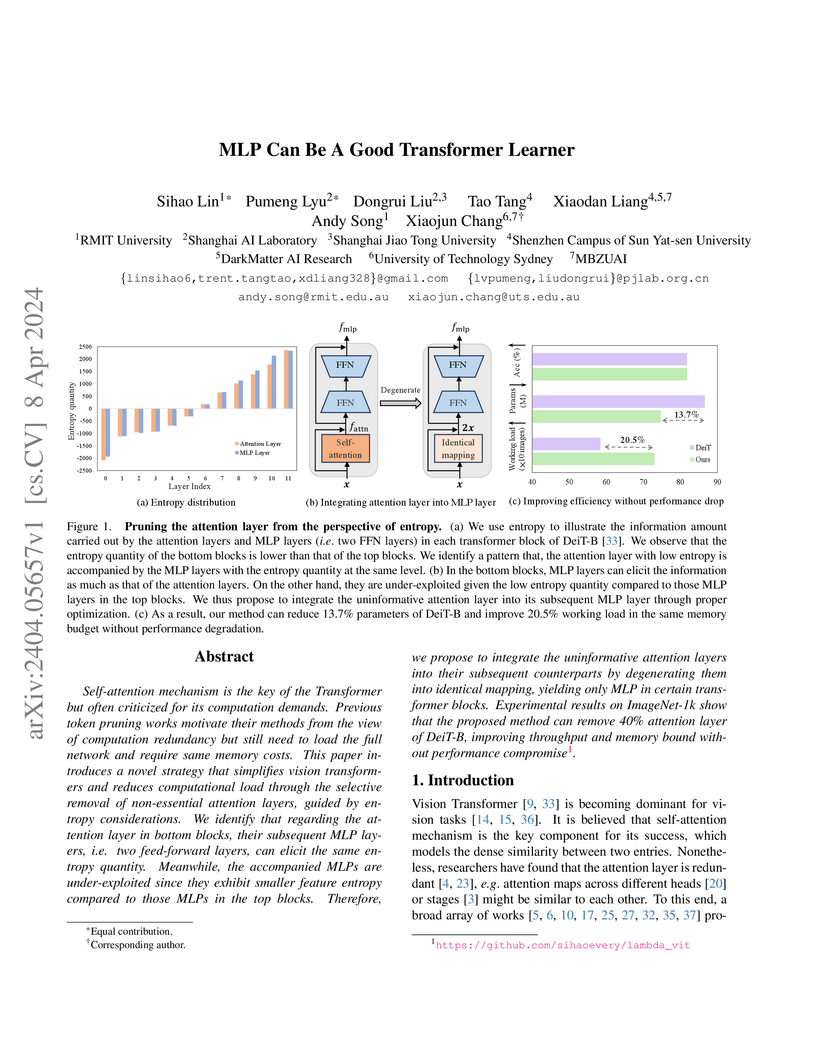
08 Apr 2024


Researchers introduced a method to reduce Vision Transformer (ViT) computational and memory demands by selectively removing self-attention layers and integrating their functionality into subsequent MLP layers. This approach achieves notable reductions in parameters and memory footprint while maintaining or improving performance and generalization on various computer vision tasks.

19 Aug 2021



A myriad of recent breakthroughs in hand-crafted neural architectures for visual recognition have highlighted the urgent need to explore hybrid architectures consisting of diversified building blocks. Meanwhile, neural architecture search methods are surging with an expectation to reduce human efforts. However, whether NAS methods can efficiently and effectively handle diversified search spaces with disparate candidates (e.g. CNNs and transformers) is still an open question. In this work, we present Block-wisely Self-supervised Neural Architecture Search (BossNAS), an unsupervised NAS method that addresses the problem of inaccurate architecture rating caused by large weight-sharing space and biased supervision in previous methods. More specifically, we factorize the search space into blocks and utilize a novel self-supervised training scheme, named ensemble bootstrapping, to train each block separately before searching them as a whole towards the population center. Additionally, we present HyTra search space, a fabric-like hybrid CNN-transformer search space with searchable down-sampling positions. On this challenging search space, our searched model, BossNet-T, achieves up to 82.5% accuracy on ImageNet, surpassing EfficientNet by 2.4% with comparable compute time. Moreover, our method achieves superior architecture rating accuracy with 0.78 and 0.76 Spearman correlation on the canonical MBConv search space with ImageNet and on NATS-Bench size search space with CIFAR-100, respectively, surpassing state-of-the-art NAS methods. Code: this https URL

06 Apr 2021
Crowd counting is a fundamental yet challenging task, which desires rich information to generate pixel-wise crowd density maps. However, most previous methods only used the limited information of RGB images and cannot well discover potential pedestrians in unconstrained scenarios. In this work, we find that incorporating optical and thermal information can greatly help to recognize pedestrians. To promote future researches in this field, we introduce a large-scale RGBT Crowd Counting (RGBT-CC) benchmark, which contains 2,030 pairs of RGB-thermal images with 138,389 annotated people. Furthermore, to facilitate the multimodal crowd counting, we propose a cross-modal collaborative representation learning framework, which consists of multiple modality-specific branches, a modality-shared branch, and an Information Aggregation-Distribution Module (IADM) to capture the complementary information of different modalities fully. Specifically, our IADM incorporates two collaborative information transfers to dynamically enhance the modality-shared and modality-specific representations with a dual information propagation mechanism. Extensive experiments conducted on the RGBT-CC benchmark demonstrate the effectiveness of our framework for RGBT crowd counting. Moreover, the proposed approach is universal for multimodal crowd counting and is also capable to achieve superior performance on the ShanghaiTechRGBD dataset. Finally, our source code and benchmark are released at {\url{this http URL}}.

14 Mar 2020
Resembling the rapid learning capability of human, few-shot learning empowers
vision systems to understand new concepts by training with few samples. Leading
approaches derived from meta-learning on images with a single visual object.
Obfuscated by a complex background and multiple objects in one image, they are
hard to promote the research of few-shot object detection/segmentation. In this
work, we present a flexible and general methodology to achieve these tasks. Our
work extends Faster /Mask R-CNN by proposing meta-learning over RoI
(Region-of-Interest) features instead of a full image feature. This simple
spirit disentangles multi-object information merged with the background,
without bells and whistles, enabling Faster /Mask R-CNN turn into a
meta-learner to achieve the tasks. Specifically, we introduce a Predictor-head
Remodeling Network (PRN) that shares its main backbone with Faster /Mask R-CNN.
PRN receives images containing few-shot objects with their bounding boxes or
masks to infer their class attentive vectors. The vectors take channel-wise
soft-attention on RoI features, remodeling those R-CNN predictor heads to
detect or segment the objects that are consistent with the classes these
vectors represent. In our experiments, Meta R-CNN yields the state of the art
in few-shot object detection and improves few-shot object segmentation by Mask
R-CNN.

21 Jun 2024
Formal verification (FV) has witnessed growing significance with current emerging program synthesis by the evolving large language models (LLMs). However, current formal verification mainly resorts to symbolic verifiers or hand-craft rules, resulting in limitations for extensive and flexible verification. On the other hand, formal languages for automated theorem proving, such as Isabelle, as another line of rigorous verification, are maintained with comprehensive rules and theorems. In this paper, we propose FVEL, an interactive Formal Verification Environment with LLMs. Specifically, FVEL transforms a given code to be verified into Isabelle, and then conducts verification via neural automated theorem proving with an LLM. The joined paradigm leverages the rigorous yet abundant formulated and organized rules in Isabelle and is also convenient for introducing and adjusting cutting-edge LLMs. To achieve this goal, we extract a large-scale FVELER3. The FVELER dataset includes code dependencies and verification processes that are formulated in Isabelle, containing 758 theories, 29,125 lemmas, and 200,646 proof steps in total with in-depth dependencies. We benchmark FVELER in the FVEL environment by first fine-tuning LLMs with FVELER and then evaluating them on Code2Inv and SV-COMP. The results show that FVEL with FVELER fine-tuned Llama3- 8B solves 17.39% (69 -> 81) more problems, and Mistral-7B 12% (75 -> 84) more problems in SV-COMP. And the proportion of proof errors is reduced. Project page: this https URL.

13 Mar 2024
Recently, semantic segmentation models trained with image-level text
supervision have shown promising results in challenging open-world scenarios.
However, these models still face difficulties in learning fine-grained semantic
alignment at the pixel level and predicting accurate object masks. To address
this issue, we propose MixReorg, a novel and straightforward pre-training
paradigm for semantic segmentation that enhances a model's ability to
reorganize patches mixed across images, exploring both local visual relevance
and global semantic coherence. Our approach involves generating fine-grained
patch-text pairs data by mixing image patches while preserving the
correspondence between patches and text. The model is then trained to minimize
the segmentation loss of the mixed images and the two contrastive losses of the
original and restored features. With MixReorg as a mask learner, conventional
text-supervised semantic segmentation models can achieve highly generalizable
pixel-semantic alignment ability, which is crucial for open-world segmentation.
After training with large-scale image-text data, MixReorg models can be applied
directly to segment visual objects of arbitrary categories, without the need
for further fine-tuning. Our proposed framework demonstrates strong performance
on popular zero-shot semantic segmentation benchmarks, outperforming GroupViT
by significant margins of 5.0%, 6.2%, 2.5%, and 3.4% mIoU on PASCAL VOC2012,
PASCAL Context, MS COCO, and ADE20K, respectively.

21 Oct 2021

Self-supervised learning (especially contrastive learning) has attracted
great interest due to its huge potential in learning discriminative
representations in an unsupervised manner. Despite the acknowledged successes,
existing contrastive learning methods suffer from very low learning efficiency,
e.g., taking about ten times more training epochs than supervised learning for
comparable recognition accuracy. In this paper, we reveal two contradictory
phenomena in contrastive learning that we call under-clustering and
over-clustering problems, which are major obstacles to learning efficiency.
Under-clustering means that the model cannot efficiently learn to discover the
dissimilarity between inter-class samples when the negative sample pairs for
contrastive learning are insufficient to differentiate all the actual object
classes. Over-clustering implies that the model cannot efficiently learn
features from excessive negative sample pairs, forcing the model to
over-cluster samples of the same actual classes into different clusters. To
simultaneously overcome these two problems, we propose a novel self-supervised
learning framework using a truncated triplet loss. Precisely, we employ a
triplet loss tending to maximize the relative distance between the positive
pair and negative pairs to address the under-clustering problem; and we
construct the negative pair by selecting a negative sample deputy from all
negative samples to avoid the over-clustering problem, guaranteed by the
Bernoulli Distribution model. We extensively evaluate our framework in several
large-scale benchmarks (e.g., ImageNet, SYSU-30k, and COCO). The results
demonstrate our model's superiority (e.g., the learning efficiency) over the
latest state-of-the-art methods by a clear margin. Codes available at:
this https URL .

18 Mar 2019
Beyond current conversational chatbots or task-oriented dialogue systems that have attracted increasing attention, we move forward to develop a dialogue system for automatic medical diagnosis that converses with patients to collect additional symptoms beyond their self-reports and automatically makes a diagnosis. Besides the challenges for conversational dialogue systems (e.g. topic transition coherency and question understanding), automatic medical diagnosis further poses more critical requirements for the dialogue rationality in the context of medical knowledge and symptom-disease relations. Existing dialogue systems (Madotto, Wu, and Fung 2018; Wei et al. 2018; Li et al. 2017) mostly rely on data-driven learning and cannot be able to encode extra expert knowledge graph. In this work, we propose an End-to-End Knowledge-routed Relational Dialogue System (KR-DS) that seamlessly incorporates rich medical knowledge graph into the topic transition in dialogue management, and makes it cooperative with natural language understanding and natural language generation. A novel Knowledge-routed Deep Q-network (KR-DQN) is introduced to manage topic transitions, which integrates a relational refinement branch for encoding relations among different symptoms and symptom-disease pairs, and a knowledge-routed graph branch for topic decision-making. Extensive experiments on a public medical dialogue dataset show our KR-DS significantly beats state-of-the-art methods (by more than 8% in diagnosis accuracy). We further show the superiority of our KR-DS on a newly collected medical dialogue system dataset, which is more challenging retaining original self-reports and conversational data between patients and doctors.

05 May 2024


Humans can develop new theorems to explore broader and more complex
mathematical results. While current generative language models (LMs) have
achieved significant improvement in automatically proving theorems, their
ability to generate new or reusable theorems is still under-explored. Without
the new theorems, current LMs struggle to prove harder theorems that are
distant from the given hypotheses with the exponentially growing search space.
Therefore, this paper proposes an Automated Theorem Generation (ATG) benchmark
that evaluates whether an agent can automatically generate valuable (and
possibly brand new) theorems that are applicable for downstream theorem proving
as reusable knowledge. Specifically, we construct the ATG benchmark by
splitting the Metamath library into three sets: axioms, library, and problem
based on their proving depth. We conduct extensive experiments to investigate
whether current LMs can generate theorems in the library and benefit the
problem theorems proving. The results demonstrate that high-quality ATG data
facilitates models' performances on downstream ATP. However, there is still
room for current LMs to develop better ATG and generate more advanced and
human-like theorems. We hope the new ATG challenge can shed some light on
advanced complex theorem proving.

23 Aug 2019
Automatic estimation of the number of people in unconstrained crowded scenes is a challenging task and one major difficulty stems from the huge scale variation of people. In this paper, we propose a novel Deep Structured Scale Integration Network (DSSINet) for crowd counting, which addresses the scale variation of people by using structured feature representation learning and hierarchically structured loss function optimization. Unlike conventional methods which directly fuse multiple features with weighted average or concatenation, we first introduce a Structured Feature Enhancement Module based on conditional random fields (CRFs) to refine multiscale features mutually with a message passing mechanism. In this module, each scale-specific feature is considered as a continuous random variable and passes complementary information to refine the features at other scales. Second, we utilize a Dilated Multiscale Structural Similarity loss to enforce our DSSINet to learn the local correlation of people's scales within regions of various size, thus yielding high-quality density maps. Extensive experiments on four challenging benchmarks well demonstrate the effectiveness of our method. Specifically, our DSSINet achieves improvements of 9.5% error reduction on Shanghaitech dataset and 24.9% on UCF-QNRF dataset against the state-of-the-art methods.

14 Dec 2020
Though beneficial for encouraging the Visual Question Answering (VQA) models to discover the underlying knowledge by exploiting the input-output correlation beyond image and text contexts, the existing knowledge VQA datasets are mostly annotated in a crowdsource way, e.g., collecting questions and external reasons from different users via the internet. In addition to the challenge of knowledge reasoning, how to deal with the annotator bias also remains unsolved, which often leads to superficial over-fitted correlations between questions and answers. To address this issue, we propose a novel dataset named Knowledge-Routed Visual Question Reasoning for VQA model evaluation. Considering that a desirable VQA model should correctly perceive the image context, understand the question, and incorporate its learned knowledge, our proposed dataset aims to cutoff the shortcut learning exploited by the current deep embedding models and push the research boundary of the knowledge-based visual question reasoning. Specifically, we generate the question-answer pair based on both the Visual Genome scene graph and an external knowledge base with controlled programs to disentangle the knowledge from other biases. The programs can select one or two triplets from the scene graph or knowledge base to push multi-step reasoning, avoid answer ambiguity, and balanced the answer distribution. In contrast to the existing VQA datasets, we further imply the following two major constraints on the programs to incorporate knowledge reasoning: i) multiple knowledge triplets can be related to the question, but only one knowledge relates to the image object. This can enforce the VQA model to correctly perceive the image instead of guessing the knowledge based on the given question solely; ii) all questions are based on different knowledge, but the candidate answers are the same for both the training and test sets.

24 Jul 2022

Graph-level representations are critical in various real-world applications, such as predicting the properties of molecules. But in practice, precise graph annotations are generally very expensive and time-consuming. To address this issue, graph contrastive learning constructs instance discrimination task which pulls together positive pairs (augmentation pairs of the same graph) and pushes away negative pairs (augmentation pairs of different graphs) for unsupervised representation learning. However, since for a query, its negatives are uniformly sampled from all graphs, existing methods suffer from the critical sampling bias issue, i.e., the negatives likely having the same semantic structure with the query, leading to performance degradation. To mitigate this sampling bias issue, in this paper, we propose a Prototypical Graph Contrastive Learning (PGCL) approach. Specifically, PGCL models the underlying semantic structure of the graph data via clustering semantically similar graphs into the same group, and simultaneously encourages the clustering consistency for different augmentations of the same graph. Then given a query, it performs negative sampling via drawing the graphs from those clusters that differ from the cluster of query, which ensures the semantic difference between query and its negative samples. Moreover, for a query, PGCL further reweights its negative samples based on the distance between their prototypes (cluster centroids) and the query prototype such that those negatives having moderate prototype distance enjoy relatively large weights. This reweighting strategy is proved to be more effective than uniform sampling. Experimental results on various graph benchmarks testify the advantages of our PGCL over state-of-the-art methods. Code is publicly available at this https URL.

20 Sep 2020

Recognizing multiple labels of an image is a practical yet challenging task,
and remarkable progress has been achieved by searching for semantic regions and
exploiting label dependencies. However, current works utilize RNN/LSTM to
implicitly capture sequential region/label dependencies, which cannot fully
explore mutual interactions among the semantic regions/labels and do not
explicitly integrate label co-occurrences. In addition, these works require
large amounts of training samples for each category, and they are unable to
generalize to novel categories with limited samples. To address these issues,
we propose a knowledge-guided graph routing (KGGR) framework, which unifies
prior knowledge of statistical label correlations with deep neural networks.
The framework exploits prior knowledge to guide adaptive information
propagation among different categories to facilitate multi-label analysis and
reduce the dependency of training samples. Specifically, it first builds a
structured knowledge graph to correlate different labels based on statistical
label co-occurrence. Then, it introduces the label semantics to guide learning
semantic-specific features to initialize the graph, and it exploits a graph
propagation network to explore graph node interactions, enabling learning
contextualized image feature representations. Moreover, we initialize each
graph node with the classifier weights for the corresponding label and apply
another propagation network to transfer node messages through the graph. In
this way, it can facilitate exploiting the information of correlated labels to
help train better classifiers. We conduct extensive experiments on the
traditional multi-label image recognition (MLR) and multi-label few-shot
learning (ML-FSL) tasks and show that our KGGR framework outperforms the
current state-of-the-art methods by sizable margins on the public benchmarks.

18 Jan 2020

Temporally language grounding in untrimmed videos is a newly-raised task in
video understanding. Most of the existing methods suffer from inferior
efficiency, lacking interpretability, and deviating from the human perception
mechanism. Inspired by human's coarse-to-fine decision-making paradigm, we
formulate a novel Tree-Structured Policy based Progressive Reinforcement
Learning (TSP-PRL) framework to sequentially regulate the temporal boundary by
an iterative refinement process. The semantic concepts are explicitly
represented as the branches in the policy, which contributes to efficiently
decomposing complex policies into an interpretable primitive action.
Progressive reinforcement learning provides correct credit assignment via two
task-oriented rewards that encourage mutual promotion within the
tree-structured policy. We extensively evaluate TSP-PRL on the Charades-STA and
ActivityNet datasets, and experimental results show that TSP-PRL achieves
competitive performance over existing state-of-the-art methods.

15 Oct 2020
Few-shot learning aims to learn novel categories from very few samples given
some base categories with sufficient training samples. The main challenge of
this task is the novel categories are prone to dominated by color, texture,
shape of the object or background context (namely specificity), which are
distinct for the given few training samples but not common for the
corresponding categories (see Figure 1). Fortunately, we find that transferring
information of the correlated based categories can help learn the novel
concepts and thus avoid the novel concept being dominated by the specificity.
Besides, incorporating semantic correlations among different categories can
effectively regularize this information transfer. In this work, we represent
the semantic correlations in the form of structured knowledge graph and
integrate this graph into deep neural networks to promote few-shot learning by
a novel Knowledge Graph Transfer Network (KGTN). Specifically, by initializing
each node with the classifier weight of the corresponding category, a
propagation mechanism is learned to adaptively propagate node message through
the graph to explore node interaction and transfer classifier information of
the base categories to those of the novel ones. Extensive experiments on the
ImageNet dataset show significant performance improvement compared with current
leading competitors. Furthermore, we construct an ImageNet-6K dataset that
covers larger scale categories, i.e, 6,000 categories, and experiments on this
dataset further demonstrate the effectiveness of our proposed model. Our codes
and models are available at this https URL .

23 May 2024
Recent large language models (LLMs) have witnessed significant advancement in various tasks, including mathematical reasoning and theorem proving. As these two tasks require strict and formal multi-step inference, they are appealing domains for exploring the reasoning ability of LLMs but still face important challenges. Previous studies such as Chain-of-Thought (CoT) have revealed the effectiveness of intermediate steps guidance. However, such step-wise annotation requires heavy labor, leading to insufficient training steps for current benchmarks. To fill this gap, this work introduces MUSTARD, a data generation framework that masters uniform synthesis of theorem and proof data of high quality and diversity. MUSTARD synthesizes data in three stages: (1) It samples a few mathematical concept seeds as the problem category. (2) Then, it prompts a generative language model with the sampled concepts to obtain both the problems and their step-wise formal solutions. (3) Lastly, the framework utilizes a proof assistant (e.g., Lean Prover) to filter the valid proofs. With the proposed MUSTARD, we present a theorem-and-proof benchmark MUSTARDSAUCE with 5,866 valid data points. Each data point contains an informal statement, an informal proof, and a translated formal proof that passes the prover validation. We perform extensive analysis and demonstrate that MUSTARD generates validated high-quality step-by-step data. We further apply the MUSTARDSAUCE for fine-tuning smaller language models. The fine-tuned Llama 2-7B achieves a 15.41% average relative performance gain in automated theorem proving, and 8.18% in math word problems. Codes and data are available at this https URL.

20 Aug 2019
Recognizing multiple labels of images is a practical and challenging task,
and significant progress has been made by searching semantic-aware regions and
modeling label dependency. However, current methods cannot locate the semantic
regions accurately due to the lack of part-level supervision or semantic
guidance. Moreover, they cannot fully explore the mutual interactions among the
semantic regions and do not explicitly model the label co-occurrence. To
address these issues, we propose a Semantic-Specific Graph Representation
Learning (SSGRL) framework that consists of two crucial modules: 1) a semantic
decoupling module that incorporates category semantics to guide learning
semantic-specific representations and 2) a semantic interaction module that
correlates these representations with a graph built on the statistical label
co-occurrence and explores their interactions via a graph propagation
mechanism. Extensive experiments on public benchmarks show that our SSGRL
framework outperforms current state-of-the-art methods by a sizable margin,
e.g. with an mAP improvement of 2.5%, 2.6%, 6.7%, and 3.1% on the PASCAL VOC
2007 & 2012, Microsoft-COCO and Visual Genome benchmarks, respectively. Our
codes and models are available at this https URL

29 Nov 2019
Deep learning-based video salient object detection has recently achieved
great success with its performance significantly outperforming any other
unsupervised methods. However, existing data-driven approaches heavily rely on
a large quantity of pixel-wise annotated video frames to deliver such promising
results. In this paper, we address the semi-supervised video salient object
detection task using pseudo-labels. Specifically, we present an effective video
saliency detector that consists of a spatial refinement network and a
spatiotemporal module. Based on the same refinement network and motion
information in terms of optical flow, we further propose a novel method for
generating pixel-level pseudo-labels from sparsely annotated frames. By
utilizing the generated pseudo-labels together with a part of manual
annotations, our video saliency detector learns spatial and temporal cues for
both contrast inference and coherence enhancement, thus producing accurate
saliency maps. Experimental results demonstrate that our proposed
semi-supervised method even greatly outperforms all the state-of-the-art fully
supervised methods across three public benchmarks of VOS, DAVIS, and FBMS.
There are no more papers matching your filters at the moment.
