
11 Jul 2024
This research from CSIRO Data61 introduces PINN-Ray, a Physics-Informed Neural Network designed to model the complex, nonlinear deformation of soft robotic Fin Ray fingers. By assimilating just nine experimental data points, PINN-Ray achieves a Mean Absolute Error of 0.03 mm in displacement prediction, significantly outperforming traditional Finite Element Models and standard PINN approaches while also accurately estimating internal stress and strain distributions.
19 Aug 2025
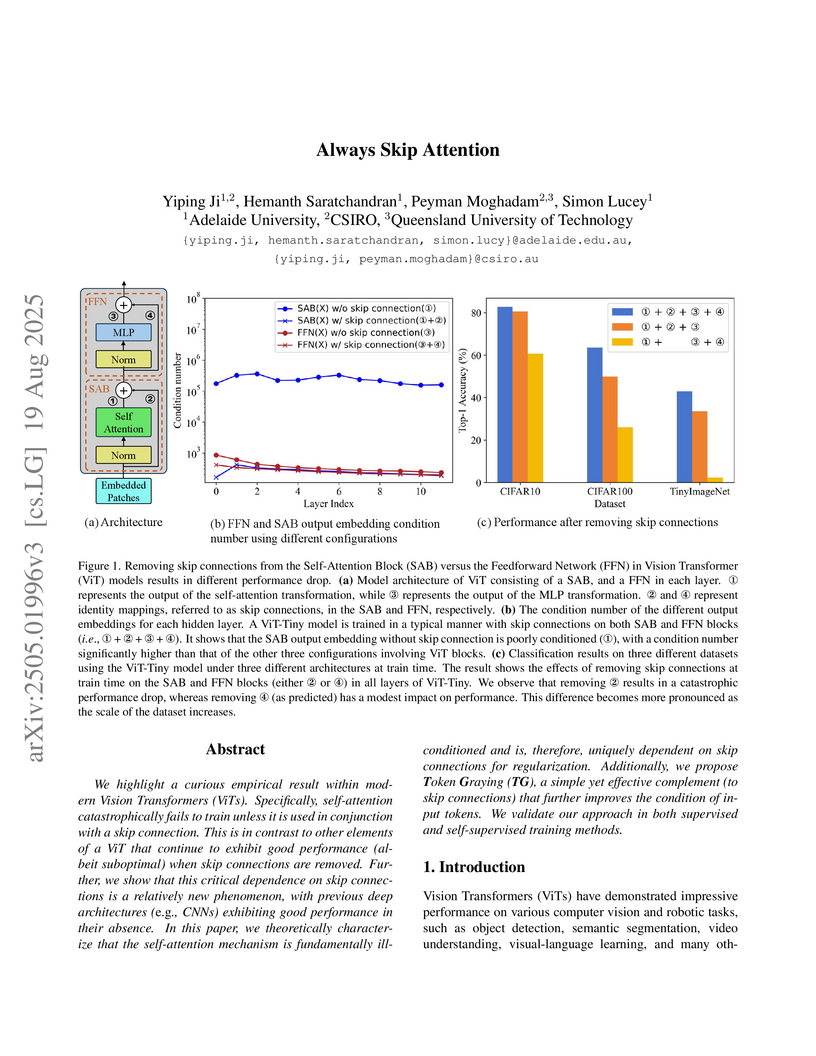
Researchers at Adelaide University and CSIRO found that the self-attention mechanism in Vision Transformers requires skip connections to prevent catastrophic training failure, attributing this to its intrinsic ill-conditioning. They introduced Token Graying, a pre-conditioning method that improved ViT accuracy on ImageNet-1K by up to 0.3% with minimal computational cost.

18 Oct 2025
Quantum machine learning (QML) has emerged as a promising area of research for enhancing the performance of classical machine learning systems by leveraging quantum computational principles. However, practical deployment of QML remains limited due to current hardware constraints such as limited number of qubits and quantum noise. This chapter introduces a hybrid quantum-classical architecture that combines the advantages of quantum computing with transfer learning techniques to address high-resolution image classification. Specifically, we propose a Quantum Transfer Learning (QTL) model that integrates classical convolutional feature extraction with quantum variational circuits. Through extensive simulations on diverse datasets including Ants \& Bees, CIFAR-10, and Road Sign Detection, we demonstrate that QTL achieves superior classification performance compared to both conventional and quantum models trained without transfer learning. Additionally, we also investigate the model's vulnerability to adversarial attacks and demonstrate that incorporating adversarial training significantly boosts the robustness of QTL, enhancing its potential for deployment in security sensitive applications.

05 Mar 2021
Change Point Detection (CPD) methods identify the times associated with changes in the trends and properties of time series data in order to describe the underlying behaviour of the system. For instance, detecting the changes and anomalies associated with web service usage, application usage or human behaviour can provide valuable insights for downstream modelling tasks. We propose a novel approach for self-supervised Time Series Change Point detection method based onContrastivePredictive coding (TS-CP^2). TS-CP^2 is the first approach to employ a contrastive learning strategy for CPD by learning an embedded representation that separates pairs of embeddings of time adjacent intervals from pairs of interval embeddings separated across time. Through extensive experiments on three diverse, widely used time series datasets, we demonstrate that our method outperforms five state-of-the-art CPD methods, which include unsupervised and semi-supervisedapproaches. TS-CP^2 is shown to improve the performance of methods that use either handcrafted statistical or temporal features by 79.4% and deep learning-based methods by 17.0% with respect to the F1-score averaged across the three datasets.

11 Jun 2025
Why do deep neural networks (DNNs) benefit from very high dimensional
parameter spaces? Their huge parameter complexities vs stunning performance in
practice is all the more intriguing and not explainable using the standard
theory of model selection for regular models. In this work, we propose a
geometrically flavored information-theoretic approach to study this phenomenon.
With the belief that simplicity is linked to better generalization, as grounded
in the theory of minimum description length, the objective of our analysis is
to examine and bound the complexity of DNNs. We introduce the locally varying
dimensionality of the parameter space of neural network models by considering
the number of significant dimensions of the Fisher information matrix, and
model the parameter space as a manifold using the framework of singular
semi-Riemannian geometry. We derive model complexity measures which yield short
description lengths for deep neural network models based on their singularity
analysis thus explaining the good performance of DNNs despite their large
number of parameters.

11 Jan 2025



The SVE-Math framework enhances Multimodal Large Language Models' visual perception of mathematical diagrams by integrating a specialized Geometric-Grounded Vision Encoder (GeoGLIP) and a Feature Router. This approach improves accuracy in visual mathematical reasoning, leading to a 15% performance gain over other 7B models on the MathVerse benchmark and comparable performance to GPT-4V on MathVista.

15 Jan 2025
PACE enhances parameter-efficient fine-tuning (PEFT) by introducing a consistency regularization strategy that implicitly reduces weight gradient norms and aligns the fine-tuned model with its pre-trained counterpart. This method demonstrates improved generalization across various visual and language tasks, outperforming existing PEFT approaches.

09 Oct 2023

Symbolic Regression is the study of algorithms that automate the search for
analytic expressions that fit data. While recent advances in deep learning have
generated renewed interest in such approaches, the development of symbolic
regression methods has not been focused on physics, where we have important
additional constraints due to the units associated with our data. Here we
present -SO, a Physical Symbolic Optimization framework for recovering
analytical symbolic expressions from physics data using deep reinforcement
learning techniques by learning units constraints. Our system is built, from
the ground up, to propose solutions where the physical units are consistent by
construction. This is useful not only in eliminating physically impossible
solutions, but because the "grammatical" rules of dimensional analysis restrict
enormously the freedom of the equation generator, thus vastly improving
performance. The algorithm can be used to fit noiseless data, which can be
useful for instance when attempting to derive an analytical property of a
physical model, and it can also be used to obtain analytical approximations to
noisy data. We test our machinery on a standard benchmark of equations from the
Feynman Lectures on Physics and other physics textbooks, achieving
state-of-the-art performance in the presence of noise (exceeding 0.1%) and show
that it is robust even in the presence of substantial (10%) noise. We showcase
its abilities on a panel of examples from astrophysics.

11 Jan 2019

We propose a one-class neural network (OC-NN) model to detect anomalies in
complex data sets. OC-NN combines the ability of deep networks to extract a
progressively rich representation of data with the one-class objective of
creating a tight envelope around normal data. The OC-NN approach breaks new
ground for the following crucial reason: data representation in the hidden
layer is driven by the OC-NN objective and is thus customized for anomaly
detection. This is a departure from other approaches which use a hybrid
approach of learning deep features using an autoencoder and then feeding the
features into a separate anomaly detection method like one-class SVM (OC-SVM).
The hybrid OC-SVM approach is sub-optimal because it is unable to influence
representational learning in the hidden layers. A comprehensive set of
experiments demonstrate that on complex data sets (like CIFAR and GTSRB), OC-NN
performs on par with state-of-the-art methods and outperformed conventional
shallow methods in some scenarios.

25 Sep 2025

Diffusion models (DMs) have been investigated in various domains due to their ability to generate high-quality data, thereby attracting significant attention. However, similar to traditional deep learning systems, there also exist potential threats to DMs. To provide advanced and comprehensive insights into safety, ethics, and trust in DMs, this survey comprehensively elucidates its framework, threats, and countermeasures. Each threat and its countermeasures are systematically examined and categorized to facilitate thorough analysis. Furthermore, we introduce specific examples of how DMs are used, what dangers they might bring, and ways to protect against these dangers. Finally, we discuss key lessons learned, highlight open challenges related to DM security, and outline prospective research directions in this critical field. This work aims to accelerate progress not only in the technical capabilities of generative artificial intelligence but also in the maturity and wisdom of its application.

30 Oct 2019


Sequential Monte Carlo methods, also known as particle methods, are a popular set of techniques for approximating high-dimensional probability distributions and their normalizing constants. These methods have found numerous applications in statistics and related fields; e.g. for inference in non-linear non-Gaussian state space models, and in complex static models. Like many Monte Carlo sampling schemes, they rely on proposal distributions which crucially impact their performance. We introduce here a class of controlled sequential Monte Carlo algorithms, where the proposal distributions are determined by approximating the solution to an associated optimal control problem using an iterative scheme. This method builds upon a number of existing algorithms in econometrics, physics, and statistics for inference in state space models, and generalizes these methods so as to accommodate complex static models. We provide a theoretical analysis concerning the fluctuation and stability of this methodology that also provides insight into the properties of related algorithms. We demonstrate significant gains over state-of-the-art methods at a fixed computational complexity on a variety of applications.

14 Jan 2022

Graph contrastive learning attracts/disperses node representations for similar/dissimilar node pairs under some notion of similarity. It may be combined with a low-dimensional embedding of nodes to preserve intrinsic and structural properties of a graph. In this paper, we extend the celebrated Laplacian Eigenmaps with contrastive learning, and call them COntrastive Laplacian EigenmapS (COLES). Starting from a GAN-inspired contrastive formulation, we show that the Jensen-Shannon divergence underlying many contrastive graph embedding models fails under disjoint positive and negative distributions, which may naturally emerge during sampling in the contrastive setting. In contrast, we demonstrate analytically that COLES essentially minimizes a surrogate of Wasserstein distance, which is known to cope well under disjoint distributions. Moreover, we show that the loss of COLES belongs to the family of so-called block-contrastive losses, previously shown to be superior compared to pair-wise losses typically used by contrastive methods. We show on popular benchmarks/backbones that COLES offers favourable accuracy/scalability compared to DeepWalk, GCN, Graph2Gauss, DGI and GRACE baselines.

24 Jun 2025
FuncVul, developed by Data61, CSIRO, introduces a model for function-level vulnerability detection that leverages code chunks and a fine-tuned GraphCodeBERT. It achieves improved accuracy in pinpointing specific vulnerable segments and detecting multiple vulnerabilities within a single function by utilizing a novel LLM-assisted data generation pipeline.

14 Jun 2025
Professor Muhammad Usman's review details the state and prospects of Quantum Machine Learning (QML), particularly Quantum Adversarial Machine Learning (QAML), highlighting its potential to enhance cybersecurity. The review notes that classical adversarial attacks do not effectively transfer to QML models, while QML-generated attacks can successfully fool classical machine learning systems.

30 Jul 2025
Recent developments in imitation learning have considerably advanced robotic manipulation. However, current techniques in imitation learning can suffer from poor generalization, limiting performance even under relatively minor domain shifts. In this work, we aim to enhance the generalization capabilities of complex imitation learning algorithms to handle unpredictable changes from the training environments to deployment environments. To avoid confusion caused by observations that are not relevant to the target task, we propose to explicitly learn the causal relationship between observation components and expert actions, employing a framework similar to [6], where a causal structural function is learned by intervention on the imitation learning policy. Disentangling the feature representation from image input as in [6] is hard to satisfy in complex imitation learning process in robotic manipulation, we theoretically clarify that this requirement is not necessary in causal relationship learning. Therefore, we propose a simple causal structure learning framework that can be easily embedded in recent imitation learning architectures, such as the Action Chunking Transformer [31]. We demonstrate our approach using a simulation of the ALOHA [31] bimanual robot arms in Mujoco, and show that the method can considerably mitigate the generalization problem of existing complex imitation learning algorithms.

19 Sep 2025
The integration of Large Language Models (LLMs) into Security Operations Centres (SOCs) presents a transformative, yet still evolving, opportunity to reduce analyst workload through human-AI collaboration. However, their real-world application in SOCs remains underexplored. To address this gap, we present a longitudinal study of 3,090 analyst queries from 45 SOC analysts over 10 months. Our analysis reveals that analysts use LLMs as on-demand aids for sensemaking and context-building, rather than for making high-stakes determinations, preserving analyst decision authority. The majority of queries are related to interpreting low-level telemetry (e.g., commands) and refining technical communication through short (1-3 turn) interactions. Notably, 93% of queries align with established cybersecurity competencies (NICE Framework), underscoring the relevance of LLM use for SOC-related tasks. Despite variations in tasks and engagement, usage trends indicate a shift from occasional exploration to routine integration, with growing adoption and sustained use among a subset of analysts. We find that LLMs function as flexible, on-demand cognitive aids that augment, rather than replace, SOC expertise. Our study provides actionable guidance for designing context-aware, human-centred AI assistance in security operations, highlighting the need for further in-the-wild research on real-world analyst-LLM collaboration, challenges, and impacts.

04 Jan 2024
Hyperspectral images (HSIs) contain rich spectral and spatial information. Motivated by the success of transformers in the field of natural language processing and computer vision where they have shown the ability to learn long range dependencies within input data, recent research has focused on using transformers for HSIs. However, current state-of-the-art hyperspectral transformers only tokenize the input HSI sample along the spectral dimension, resulting in the under-utilization of spatial information. Moreover, transformers are known to be data-hungry and their performance relies heavily on large-scale pretraining, which is challenging due to limited annotated hyperspectral data. Therefore, the full potential of HSI transformers has not been fully realized. To overcome these limitations, we propose a novel factorized spectral-spatial transformer that incorporates factorized self-supervised pretraining procedures, leading to significant improvements in performance. The factorization of the inputs allows the spectral and spatial transformers to better capture the interactions within the hyperspectral data cubes. Inspired by masked image modeling pretraining, we also devise efficient masking strategies for pretraining each of the spectral and spatial transformers. We conduct experiments on six publicly available datasets for HSI classification task and demonstrate that our model achieves state-of-the-art performance in all the datasets. The code for our model will be made available at this https URL.

29 Jan 2021


Federated learning (FL), as a type of collaborative machine learning framework, is capable of preserving private data from mobile terminals (MTs) while training the data into useful models. Nevertheless, from a viewpoint of information theory, it is still possible for a curious server to infer private information from the shared models uploaded by MTs. To address this problem, we first make use of the concept of local differential privacy (LDP), and propose a user-level differential privacy (UDP) algorithm by adding artificial noise to the shared models before uploading them to servers. According to our analysis, the UDP framework can realize -LDP for the -th MT with adjustable privacy protection levels by varying the variances of the artificial noise processes. We then derive a theoretical convergence upper-bound for the UDP algorithm. It reveals that there exists an optimal number of communication rounds to achieve the best learning performance. More importantly, we propose a communication rounds discounting (CRD) method. Compared with the heuristic search method, the proposed CRD method can achieve a much better trade-off between the computational complexity of searching and the convergence performance. Extensive experiments indicate that our UDP algorithm using the proposed CRD method can effectively improve both the training efficiency and model quality for the given privacy protection levels.

26 Oct 2023
Machine Learning (ML) models have been shown to potentially leak sensitive information, thus raising privacy concerns in ML-driven applications. This inspired recent research on removing the influence of specific data samples from a trained ML model. Such efficient removal would enable ML to comply with the "right to be forgotten" in many legislation, and could also address performance bottlenecks from low-quality or poisonous samples. In that context, machine unlearning methods have been proposed to erase the contributions of designated data samples on models, as an alternative to the often impracticable approach of retraining models from scratch. This article presents a comprehensive review of recent machine unlearning techniques, verification mechanisms, and potential attacks. We further highlight emerging challenges and prospective research directions (e.g. resilience and fairness concerns). We aim for this paper to provide valuable resources for integrating privacy, equity, andresilience into ML systems and help them "learn to unlearn".

08 Apr 2023


Continual learning aims to efficiently learn from a non-stationary stream of data while avoiding forgetting the knowledge of old data. In many practical applications, data complies with non-Euclidean geometry. As such, the commonly used Euclidean space cannot gracefully capture non-Euclidean geometric structures of data, leading to inferior results. In this paper, we study continual learning from a novel perspective by exploring data geometry for the non-stationary stream of data. Our method dynamically expands the geometry of the underlying space to match growing geometric structures induced by new data, and prevents forgetting by keeping geometric structures of old data into account. In doing so, making use of the mixed curvature space, we propose an incremental search scheme, through which the growing geometric structures are encoded. Then, we introduce an angular-regularization loss and a neighbor-robustness loss to train the model, capable of penalizing the change of global geometric structures and local geometric structures. Experiments show that our method achieves better performance than baseline methods designed in Euclidean space.
There are no more papers matching your filters at the moment.
