
17 Feb 2025
Meta AI researchers demonstrate that deep neural networks can develop sophisticated intuitive physics understanding through self-supervised learning on natural videos, achieving 98% accuracy on physics violation detection tasks without requiring hard-coded physical knowledge, while establishing that prediction in representation space is crucial for developing these capabilities.

11 Apr 2025




A comprehensive survey examines the landscape of Spoken Language Models (SLMs), analyzing architectures, training strategies, and evaluation methods across pure SLMs, speech+text SLMs, and speech-aware text LMs while establishing unified terminology and identifying key challenges in developing universal speech processing systems.

22 Nov 2022

Researchers at Meta AI Research and affiliated academic institutions developed dGSLM, a "textless" generative spoken language model that directly generates naturalistic two-channel spoken dialogues from raw audio. The model excels at reproducing human-like turn-taking dynamics, including appropriate overlaps and the nuanced timing of pauses, achieving a Naturalness MOS of 3.70, despite current limitations in semantic coherence.

11 Feb 2020
This paper presents IntPhys 2019, a new benchmark for evaluating artificial intelligence systems' understanding of intuitive physics through a plausibility judgment task, inspired by infant cognition. It demonstrates that current self-supervised deep learning models perform significantly worse than humans, particularly struggling with physical reasoning when events are occluded.

18 Oct 2024


We introduce Spirit LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a 7B pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single stream of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. Spirit LM comes in two versions: a Base version that uses speech phonetic units (HuBERT) and an Expressive version that models expressivity using pitch and style units in addition to the phonetic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that Spirit LM can learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification). We make available model weights and inference code.

15 Oct 2022


An analytical framework decomposes the Lewis game objective into information and co-adaptation losses, uncovering that overfitting in co-adaptation is a primary barrier to robust emergent communication. Managing this specific overfitting enables artificial agents to develop more generalizable and compositionally structured languages, aligning with human linguistic expectations.

27 Jul 2021

Researchers at Facebook AI Research present a method for speech resynthesis that directly uses discrete, disentangled self-supervised representations, circumventing traditional Mel-spectrograms. Their approach enables an ultra-lightweight HuBERT-based codec that achieves superior perceived quality at 365 bits per second, outperforming established codecs like Opus and LPCNet.

18 Feb 2024
We introduce Metric-Learning Encoding Models (MLEMs) as a new approach to
understand how neural systems represent the theoretical features of the objects
they process. As a proof-of-concept, we apply MLEMs to neural representations
extracted from BERT, and track a wide variety of linguistic features (e.g.,
tense, subject person, clause type, clause embedding). We find that: (1)
linguistic features are ordered: they separate representations of sentences to
different degrees in different layers; (2) neural representations are organized
hierarchically: in some layers, we find clusters of representations nested
within larger clusters, following successively important linguistic features;
(3) linguistic features are disentangled in middle layers: distinct, selective
units are activated by distinct linguistic features. Methodologically, MLEMs
are superior (4) to multivariate decoding methods, being more robust to type-I
errors, and (5) to univariate encoding methods, in being able to predict both
local and distributed representations. Together, this demonstrates the utility
of Metric-Learning Encoding Methods for studying how linguistic features are
neurally encoded in language models and the advantage of MLEMs over traditional
methods. MLEMs can be extended to other domains (e.g. vision) and to other
neural systems, such as the human brain.

18 Mar 2024

The paper introduces deep learning as a computational tool for modeling language evolution, presenting a comprehensive framework of communication games where neural agents develop communication protocols. It demonstrates that while agents can learn to communicate, basic tasks alone often fail to produce human-like language properties, highlighting the necessity of human-inspired constraints for the emergence of complex linguistic features.
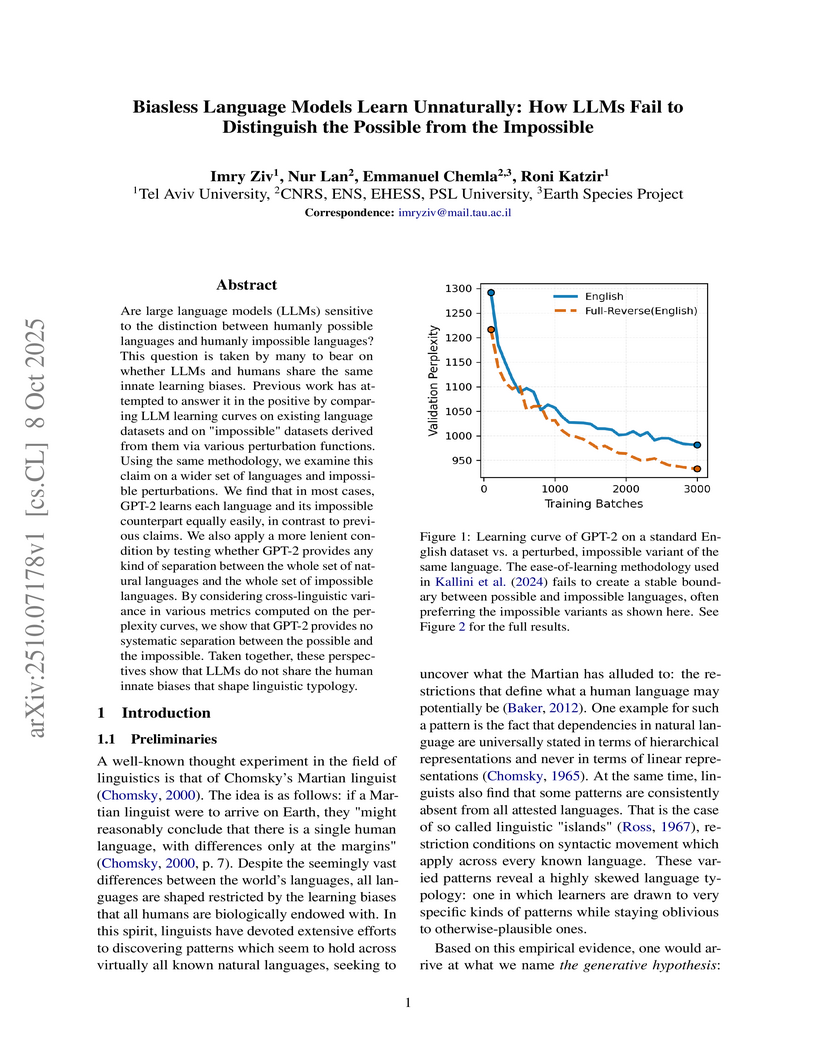
08 Oct 2025
Are large language models (LLMs) sensitive to the distinction between humanly possible languages and humanly impossible languages? This question is taken by many to bear on whether LLMs and humans share the same innate learning biases. Previous work has attempted to answer it in the positive by comparing LLM learning curves on existing language datasets and on "impossible" datasets derived from them via various perturbation functions. Using the same methodology, we examine this claim on a wider set of languages and impossible perturbations. We find that in most cases, GPT-2 learns each language and its impossible counterpart equally easily, in contrast to previous claims. We also apply a more lenient condition by testing whether GPT-2 provides any kind of separation between the whole set of natural languages and the whole set of impossible languages. By considering cross-linguistic variance in various metrics computed on the perplexity curves, we show that GPT-2 provides no systematic separation between the possible and the impossible. Taken together, these perspectives show that LLMs do not share the human innate biases that shape linguistic typology.

14 Feb 2018
During their first years of life, infants learn the language(s) of their
environment at an amazing speed despite large cross cultural variations in
amount and complexity of the available language input. Understanding this
simple fact still escapes current cognitive and linguistic theories. Recently,
spectacular progress in the engineering science, notably, machine learning and
wearable technology, offer the promise of revolutionizing the study of
cognitive development. Machine learning offers powerful learning algorithms
that can achieve human-like performance on many linguistic tasks. Wearable
sensors can capture vast amounts of data, which enable the reconstruction of
the sensory experience of infants in their natural environment. The project of
'reverse engineering' language development, i.e., of building an effective
system that mimics infant's achievements appears therefore to be within reach.
Here, we analyze the conditions under which such a project can contribute to
our scientific understanding of early language development. We argue that
instead of defining a sub-problem or simplifying the data, computational models
should address the full complexity of the learning situation, and take as input
the raw sensory signals available to infants. This implies that (1) accessible
but privacy-preserving repositories of home data be setup and widely shared,
and (2) models be evaluated at different linguistic levels through a benchmark
of psycholinguist tests that can be passed by machines and humans alike, (3)
linguistically and psychologically plausible learning architectures be scaled
up to real data using probabilistic/optimization principles from machine
learning. We discuss the feasibility of this approach and present preliminary
results.

24 Oct 2025


This study critically examines the long-held assumptions connecting Heaps’ law and Zipf’s law, demonstrating that temporal correlations significantly influence type-token growth in discovery processes. Through empirical analysis of text, music listening, and web browsing data, the research reveals that the Heaps exponent is system-dependent and often decoupled from the static rank-frequency distribution, particularly in dynamic digital environments.

08 Jun 2023
Self-supervised techniques for learning speech representations have been
shown to develop linguistic competence from exposure to speech without the need
for human labels. In order to fully realize the potential of these approaches
and further our understanding of how infants learn language, simulations must
closely emulate real-life situations by training on developmentally plausible
corpora and benchmarking against appropriate test sets. To this end, we propose
a language-acquisition-friendly benchmark to probe spoken language models at
the lexical and syntactic levels, both of which are compatible with the
vocabulary typical of children's language experiences. This paper introduces
the benchmark and summarizes a range of experiments showing its usefulness. In
addition, we highlight two exciting challenges that need to be addressed for
further progress: bridging the gap between text and speech and between clean
speech and in-the-wild speech.

11 Apr 2024
We present a corpus of 100 documents, OBSINFOX, selected from 17 sources of French press considered unreliable by expert agencies, annotated using 11 labels by 8 annotators. By collecting more labels than usual, by more annotators than is typically done, we can identify features that humans consider as characteristic of fake news, and compare them to the predictions of automated classifiers. We present a topic and genre analysis using Gate Cloud, indicative of the prevalence of satire-like text in the corpus. We then use the subjectivity analyzer VAGO, and a neural version of it, to clarify the link between ascriptions of the label Subjective and ascriptions of the label Fake News. The annotated dataset is available online at the following url: this https URL
Keywords: Fake News, Multi-Labels, Subjectivity, Vagueness, Detail, Opinion, Exaggeration, French Press

06 Jun 2024
Neural networks offer good approximation to many tasks but consistently fail to reach perfect generalization, even when theoretical work shows that such perfect solutions can be expressed by certain architectures. Using the task of formal language learning, we focus on one simple formal language and show that the theoretically correct solution is in fact not an optimum of commonly used objectives -- even with regularization techniques that according to common wisdom should lead to simple weights and good generalization (L1, L2) or other meta-heuristics (early-stopping, dropout). On the other hand, replacing standard targets with the Minimum Description Length objective (MDL) results in the correct solution being an optimum.

06 May 2025

A framework quantifies the cognitive complexity of chess variations using entropy theory, demonstrating that positions with similar engine evaluations can present vastly different challenges to human players based on skill level. The research reveals that experts find balanced positions particularly complex, while beginners struggle more uniformly across evaluation ranges.

26 Feb 2024
Accurate estimation of question difficulty and prediction of student
performance play key roles in optimizing educational instruction and enhancing
learning outcomes within digital learning platforms. The Elo rating system is
widely recognized for its proficiency in predicting student performance by
estimating both question difficulty and student ability while providing
computational efficiency and real-time adaptivity. This paper presents an
adaptation of a multi concept variant of the Elo rating system to the data
collected by a medical training platform, a platform characterized by a vast
knowledge corpus, substantial inter-concept overlap, a huge question bank with
significant sparsity in user question interactions, and a highly diverse user
population, presenting unique challenges. Our study is driven by two primary
objectives: firstly, to comprehensively evaluate the Elo rating systems
capabilities on this real-life data, and secondly, to tackle the issue of
imprecise early stage estimations when implementing the Elo rating system for
online assessments. Our findings suggest that the Elo rating system exhibits
comparable accuracy to the well-established logistic regression model in
predicting final exam outcomes for users within our digital platform.
Furthermore, results underscore that initializing Elo rating estimates with
historical data remarkably reduces errors and enhances prediction accuracy,
especially during the initial phases of student interactions.

27 May 2021
This paper presents the final results of the ICDAR 2021 Competition on
Historical Map Segmentation (MapSeg), encouraging research on a series of
historical atlases of Paris, France, drawn at 1/5000 scale between 1894 and
1937. The competition featured three tasks, awarded separately. Task~1 consists
in detecting building blocks and was won by the L3IRIS team using a
DenseNet-121 network trained in a weakly supervised fashion. This task is
evaluated on 3 large images containing hundreds of shapes to detect. Task~2
consists in segmenting map content from the larger map sheet, and was won by
the UWB team using a U-Net-like FCN combined with a binarization method to
increase detection edge accuracy. Task~3 consists in locating intersection
points of geo-referencing lines, and was also won by the UWB team who used a
dedicated pipeline combining binarization, line detection with Hough transform,
candidate filtering, and template matching for intersection refinement. Tasks~2
and~3 are evaluated on 95 map sheets with complex content. Dataset, evaluation
tools and results are available under permissive licensing at
\url{this https URL}.

21 Oct 2025

In animals, category learning enhances discrimination between stimuli close to the category boundary. This phenomenon, called categorical perception, was also empirically observed in artificial neural networks trained on classification tasks. In previous modeling works based on neuroscience data, we show that this expansion/compression is a necessary outcome of efficient learning. Here we extend our theoretical framework to artificial networks. We show that minimizing the Bayes cost (mean of the cross-entropy loss) implies maximizing the mutual information between the set of categories and the neural activities prior to the decision layer. Considering structured data with an underlying feature space of small dimension, we show that maximizing the mutual information implies (i) finding an appropriate projection space, and, (ii) building a neural representation with the appropriate metric. The latter is based on a Fisher information matrix measuring the sensitivity of the neural activity to changes in the projection space. Optimal learning makes this neural Fisher information follow a category-specific Fisher information, measuring the sensitivity of the category membership. Category learning thus induces an expansion of neural space near decision boundaries. We characterize the properties of the categorical Fisher information, showing that its eigenvectors give the most discriminant directions at each point of the projection space. We find that, unexpectedly, its maxima are in general not exactly at, but near, the class boundaries. Considering toy models and the MNIST dataset, we numerically illustrate how after learning the two Fisher information matrices match, and essentially align with the category boundaries. Finally, we relate our approach to the Information Bottleneck one, and we exhibit a bias-variance decomposition of the Bayes cost, of interest on its own.

27 May 2025
We investigate optimal strategies for decoding perceived natural speech from
fMRI data acquired from a limited number of participants. Leveraging Lebel et
al. (2023)'s dataset of 8 participants, we first demonstrate the effectiveness
of training deep neural networks to predict LLM-derived text representations
from fMRI activity. Then, in this data regime, we observe that multi-subject
training does not improve decoding accuracy compared to single-subject
approach. Furthermore, training on similar or different stimuli across subjects
has a negligible effect on decoding accuracy. Finally, we find that our
decoders better model syntactic than semantic features, and that stories
containing sentences with complex syntax or rich semantic content are more
challenging to decode. While our results demonstrate the benefits of having
extensive data per participant (deep phenotyping), they suggest that leveraging
multi-subject for natural speech decoding likely requires deeper phenotyping or
a substantially larger cohort.
There are no more papers matching your filters at the moment.
