 Fudan University
Fudan University
08 Nov 2025
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of California, Santa Barbara
University of California, Santa Barbara Chinese Academy of Sciences
Chinese Academy of Sciences Imperial College LondonShanghai AI Laboratory
Imperial College LondonShanghai AI Laboratory National University of Singapore
National University of Singapore University College London
University College London University of OxfordFudan University
University of OxfordFudan University University of Science and Technology of China
University of Science and Technology of China University of Bristol
University of Bristol The Chinese University of Hong Kong
The Chinese University of Hong Kong University of California, San DiegoDalian University of Technology
University of California, San DiegoDalian University of Technology University of Georgia
University of Georgia Brown University
Brown UniversityA comprehensive survey formally defines Agentic Reinforcement Learning (RL) for Large Language Models (LLMs) as a Partially Observable Markov Decision Process (POMDP), distinct from conventional LLM-RL, and provides a two-tiered taxonomy of capabilities and task domains. The work consolidates open-source resources and outlines critical open challenges for the field.

28 Apr 2025


Perception Encoder introduces a family of vision models that achieve state-of-the-art performance across diverse vision and vision-language tasks, demonstrating that general, high-quality visual features can be extracted from the intermediate layers of a single, contrastively-trained network. It provides specific alignment tuning methods to make these features accessible for tasks ranging from zero-shot classification to dense spatial prediction and multimodal language understanding.

10 Sep 2025



An open-source framework, AgentGym-RL, facilitates the training of large language model agents for long-horizon decision-making through multi-turn reinforcement learning and a progressive interaction scaling strategy called ScalingInter-RL. This approach enables a 7B parameter model to achieve an average success rate comparable to or exceeding larger proprietary models across diverse environments, highlighting the impact of RL training on agentic intelligence.

01 Aug 2025
Princeton AI LabUniversity of Illinois at Urbana-ChampaignUniversity of California, Santa Barbara Carnegie Mellon UniversityFudan University
Carnegie Mellon UniversityFudan University Shanghai Jiao Tong University
Shanghai Jiao Tong University Tsinghua University
Tsinghua University University of MichiganThe Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou)University of California, San DiegoPennsylvania State University
University of MichiganThe Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou)University of California, San DiegoPennsylvania State University The University of Hong Kong
The University of Hong Kong Princeton University
Princeton University University of SydneyOregon State University
University of SydneyOregon State University
University of Illinois at Urbana-ChampaignUniversity of California, Santa BarbaraCarnegie Mellon UniversityFudan UniversityShanghai Jiao Tong UniversityTsinghua UniversityUniversity of MichiganThe Chinese University of Hong KongThe Hong Kong University of Science and Technology (Guangzhou)University of California, San DiegoPennsylvania State UniversityThe University of Hong KongPrinceton UniversityUniversity of SydneyOregon State UniversityAn extensive international collaboration offers the first systematic review of self-evolving agents, establishing a unified theoretical framework categorized by 'what to evolve,' 'when to evolve,' and 'how to evolve'. The work consolidates diverse research, highlights key challenges, and maps applications, aiming to guide the development of AI systems capable of continuous autonomous improvement.

20 Aug 2025

Researchers developed the RoadNet Sequence, a unified representation for encoding both geometric and topological road network information from multi-camera images. Their Transformer-based models, particularly the Non-Autoregressive RoadNetTransformer (NAR-RNTR), achieve real-time inference speeds, operating 47 times faster than the autoregressive baseline while demonstrating superior performance over existing road network extraction methods.

17 Oct 2024
The MEDCARE framework introduces a two-stage fine-tuning pipeline to decouple clinical alignment from knowledge aggregation in medical large language models (LLMs). This approach leads to superior performance across over 20 diverse medical benchmarks, including both knowledge-intensive and alignment-required tasks, demonstrating robust efficiency and cross-lingual generalization.

06 Nov 2025
This research introduces "Thinking with Video," a new paradigm that leverages video generation for multimodal reasoning by enabling dynamic visualization and human-like imagination in problem-solving. It evaluates frontier video models like Sora-2 on a new, comprehensive benchmark, VideoThinkBench, showcasing their unexpected capabilities across vision and text-centric tasks.

27 Mar 2024
This survey paper from researchers at Tongji University and Fudan University offers a comprehensive, systematic synthesis of Retrieval-Augmented Generation (RAG) for Large Language Models. It structures the field by delineating three evolutionary paradigms—Naive, Advanced, and Modular RAG—and details advancements across retrieval, generation, and augmentation components, while also providing a thorough framework for evaluating RAG systems.

10 Jul 2025





This comprehensive survey from a large multi-institutional collaboration examines "Latent Reasoning" in Large Language Models, an emerging paradigm that performs multi-step inference entirely within the model's high-bandwidth continuous hidden states to overcome the limitations of natural language-based explicit reasoning. It highlights the significant bandwidth advantage of latent representations (approximately 2700x higher) and provides a unified taxonomy of current methodologies.

16 Aug 2024
Foundation models, pre-trained on massive datasets, have achieved
unprecedented generalizability. However, is it truly necessary to involve such
vast amounts of data in pre-training, consuming extensive computational
resources? This paper introduces data-effective learning, aiming to use data in
the most impactful way to pre-train foundation models. This involves strategies
that focus on data quality rather than quantity, ensuring the data used for
training has high informational value. Data-effective learning plays a profound
role in accelerating foundation model training, reducing computational costs,
and saving data storage, which is very important as the volume of medical data
in recent years has grown beyond many people's expectations. However, due to
the lack of standards and comprehensive benchmarks, research on medical
data-effective learning is poorly studied. To address this gap, our paper
introduces a comprehensive benchmark specifically for evaluating data-effective
learning in the medical field. This benchmark includes a dataset with millions
of data samples from 31 medical centers (DataDEL), a baseline method for
comparison (MedDEL), and a new evaluation metric (NormDEL) to objectively
measure data-effective learning performance. Our extensive experimental results
show the baseline MedDEL can achieve performance comparable to the original
large dataset with only 5% of the data. Establishing such an open
data-effective learning benchmark is crucial for the medical foundation model
research community because it facilitates efficient data use, promotes
collaborative breakthroughs, and fosters the development of cost-effective,
scalable, and impactful healthcare solutions.

19 Apr 2025


InternVL3 establishes a new native multimodal pre-training paradigm for MLLMs, allowing the model to jointly acquire visual and linguistic capabilities from the outset. This approach achieves state-of-the-art performance among open-source models, reaching 72.2 on the MMMU benchmark, and demonstrates strong competitiveness with leading proprietary models across a wide range of multimodal tasks.

02 Feb 2024
Three-dimensional coronary magnetic resonance angiography (CMRA) demands
reconstruction algorithms that can significantly suppress the artifacts from a
heavily undersampled acquisition. While unrolling-based deep reconstruction
methods have achieved state-of-the-art performance on 2D image reconstruction,
their application to 3D reconstruction is hindered by the large amount of
memory needed to train an unrolled network. In this study, we propose a
memory-efficient deep compressed sensing method by employing a sparsifying
transform based on a pre-trained artifact estimation network. The motivation is
that the artifact image estimated by a well-trained network is sparse when the
input image is artifact-free, and less sparse when the input image is
artifact-affected. Thus, the artifact-estimation network can be used as an
inherent sparsifying transform. The proposed method, named De-Aliasing
Regularization based Compressed Sensing (DARCS), was compared with a
traditional compressed sensing method, de-aliasing generative adversarial
network (DAGAN), model-based deep learning (MoDL), and plug-and-play for
accelerations of 3D CMRA. The results demonstrate that the proposed method
improved the reconstruction quality relative to the compared methods by a large
margin. Furthermore, the proposed method well generalized for different
undersampling rates and noise levels. The memory usage of the proposed method
was only 63% of that needed by MoDL. In conclusion, the proposed method
achieves improved reconstruction quality for 3D CMRA with reduced memory
burden.

15 Apr 2025


AFLOW introduces an automated framework for generating and optimizing agentic workflows for Large Language Models, reformulating workflow optimization as a search problem over code-represented workflows. The system leverages Monte Carlo Tree Search with LLM-based optimization to iteratively refine workflows, yielding a 19.5% average performance improvement over existing automated methods while enabling smaller, more cost-effective LLMs to achieve performance parity with larger models.

03 Dec 2025

Vision-language reinforcement learning (RL) has primarily focused on narrow domains (e.g. geometry or chart reasoning). This leaves broader training scenarios and resources underexplored, limiting the exploration and learning of Vision Language Models (VLMs) through RL. We find video games inherently provide rich visual elements and mechanics that are easy to verify. To fully use the multimodal and verifiable reward in video games, we propose Game-RL, constructing diverse game tasks for RL training to boost VLMs general reasoning ability. To obtain training data, we propose Code2Logic, a novel approach that adapts game code to synthesize game reasoning task data, thus obtaining the GameQA dataset of 30 games and 158 tasks with controllable difficulty gradation. Unexpectedly, RL training solely on GameQA enables multiple VLMs to achieve performance improvements across 7 diverse vision-language benchmarks, demonstrating the value of Game-RL for enhancing VLMs' general reasoning. Furthermore, this suggests that video games may serve as valuable scenarios and resources to boost general reasoning abilities. Our code, dataset and models are available at the GitHub repository.

25 Sep 2025
SIM-CoT stabilizes and enhances implicit Chain-of-Thought reasoning in large language models by integrating fine-grained, step-level supervision for latent tokens during training. It addresses latent instability, achieves higher accuracy than explicit CoT in some settings while preserving inference efficiency, and offers unprecedented interpretability into the model's internal thought processes.

24 Sep 2025
The paper outlines a joint Multimodal Large Language Model (MLLM) and World Model (WM) driven architecture to advance Embodied AI towards Artificial General Intelligence. This approach integrates MLLMs' semantic reasoning with WMs' physics-aware predictive capabilities, overcoming limitations in real-time adaptation and physical grounding to enable more robust and adaptable agents in dynamic environments.

18 Oct 2025
South China University of Technology California Institute of Technology
California Institute of Technology University of Cambridge
University of Cambridge Monash UniversityShanghai Artificial Intelligence LaboratoryChinese Academy of SciencesUniversity College LondonFudan UniversityShanghai Jiao Tong University
Monash UniversityShanghai Artificial Intelligence LaboratoryChinese Academy of SciencesUniversity College LondonFudan UniversityShanghai Jiao Tong University Nanjing University
Nanjing University Stanford UniversityThe Chinese University of Hong Kong
Stanford UniversityThe Chinese University of Hong Kong The Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, ShenzhenThe University of Hong KongMBZUAI
The Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, ShenzhenThe University of Hong KongMBZUAI Purdue University
Purdue University Virginia Tech
Virginia Tech HKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
HKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
California Institute of TechnologyUniversity of CambridgeMonash UniversityShanghai Artificial Intelligence LaboratoryChinese Academy of SciencesUniversity College LondonFudan UniversityShanghai Jiao Tong UniversityNanjing UniversityStanford UniversityThe Chinese University of Hong KongThe Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, ShenzhenThe University of Hong KongMBZUAIPurdue UniversityVirginia TechHKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
A comprehensive survey by researchers from Shanghai AI Lab and various global institutions outlines the intricate relationship between scientific large language models (Sci-LLMs) and their data foundations, tracing their evolution towards autonomous agents for scientific discovery. The paper establishes a taxonomy for scientific data and knowledge, meticulously reviews over 270 datasets and 190 benchmarks, and identifies critical data challenges alongside future paradigms.

18 Jul 2025
Researchers from Harbin Institute of Technology and collaborating institutions provide a systematic survey of Long Chain-of-Thought (Long CoT) in Large Language Models, establishing a formal distinction from Short CoT. The survey proposes a novel taxonomy based on deep reasoning, extensive exploration, and feasible reflection, and analyzes key phenomena observed in advanced reasoning models.

27 Aug 2025
 Northeastern University
Northeastern University Sun Yat-Sen UniversityFudan UniversityUniversity of Science and Technology of ChinaNanjing UniversityTsinghua UniversityShanghai AI LabCentral South UniversityShenzhen University
Sun Yat-Sen UniversityFudan UniversityUniversity of Science and Technology of ChinaNanjing UniversityTsinghua UniversityShanghai AI LabCentral South UniversityShenzhen University Southern University of Science and TechnologyTeleAID-roboticsHKU MMLabLumina EAIHKU-SH ICRCSJTU ScaleLab
Southern University of Science and TechnologyTeleAID-roboticsHKU MMLabLumina EAIHKU-SH ICRCSJTU ScaleLabRoboTwin 2.0 introduces a scalable simulation framework and benchmark designed to generate high-quality, domain-randomized data for robust bimanual robotic manipulation, addressing limitations in existing synthetic datasets. Policies trained with RoboTwin 2.0 data achieved a 24.4% improvement in real-world success rates for few-shot learning and 21.0% for zero-shot generalization on unseen backgrounds.
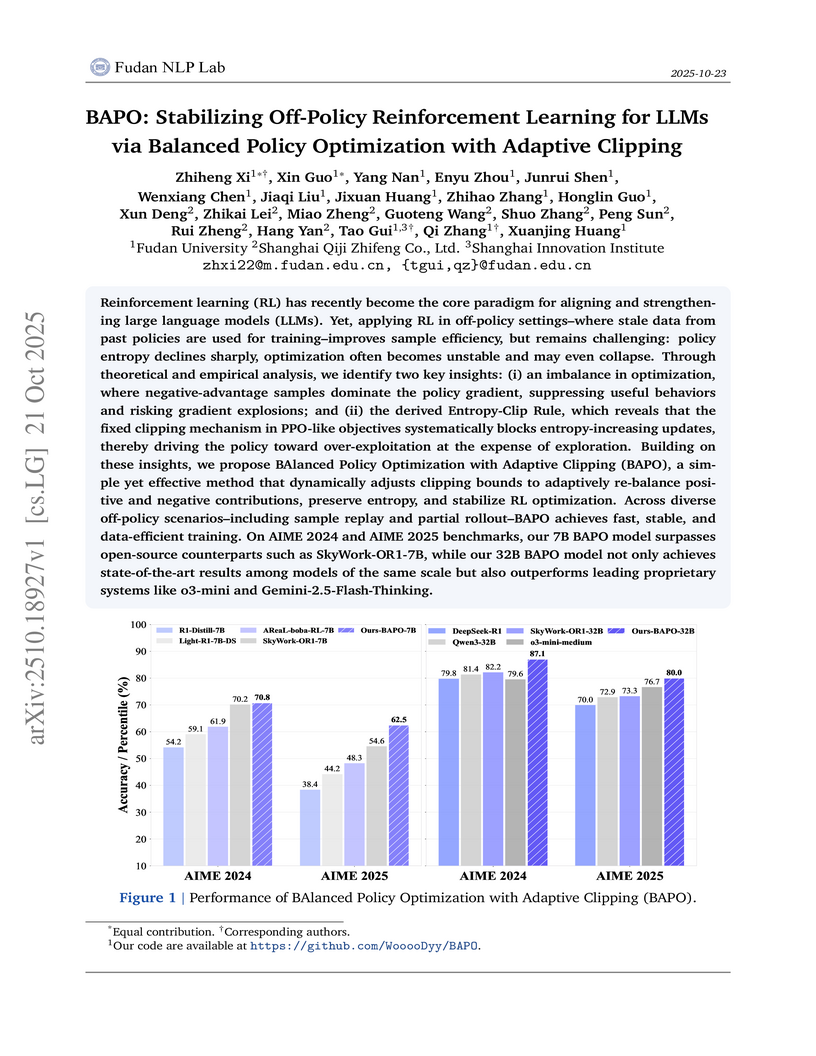
21 Oct 2025
BAPO introduces an adaptive clipping mechanism for off-policy Reinforcement Learning in Large Language Models, which dynamically re-balances optimization signals and preserves policy entropy. This method achieves state-of-the-art performance on AIME reasoning benchmarks, outperforming comparable open-source models and demonstrating competitiveness with proprietary systems.
There are no more papers matching your filters at the moment.
