
02 Oct 2025

Researchers from the Australian National University, University of Melbourne, and GE Research investigated how reasoning impacts Vision-Language Model (VLM) accuracy, discovering that prolonged reasoning can degrade perceptual grounding, a phenomenon they term "visual forgetting." They developed Vision-Anchored Policy Optimization (VAPO), a novel training method that explicitly reinforces visual reliance, enabling VLMs to sustain accuracy gains throughout extended reasoning and establish new state-of-the-art performance on various benchmarks.

18 Mar 2025
Researchers at the Australian National University and GE Research found that multi-image vision-language models exhibit a 'position bias,' leading to inconsistent responses when image order changes. They propose SoFt Attention (SoFA), a training-free method using linear interpolation between causal and bidirectional attention, which reduces inconsistency by up to 6.8% and balances attention distribution across image positions.

13 Mar 2024
Although soft prompt tuning is effective in efficiently adapting
Vision-Language (V&L) models for downstream tasks, it shows limitations in
dealing with distribution shifts. We address this issue with Attribute-Guided
Prompt Tuning (ArGue), making three key contributions. 1) In contrast to the
conventional approach of directly appending soft prompts preceding class names,
we align the model with primitive visual attributes generated by Large Language
Models (LLMs). We posit that a model's ability to express high confidence in
these attributes signifies its capacity to discern the correct class
rationales. 2) We introduce attribute sampling to eliminate disadvantageous
attributes, thus only semantically meaningful attributes are preserved. 3) We
propose negative prompting, explicitly enumerating class-agnostic attributes to
activate spurious correlations and encourage the model to generate highly
orthogonal probability distributions in relation to these negative features. In
experiments, our method significantly outperforms current state-of-the-art
prompt tuning methods on both novel class prediction and out-of-distribution
generalization tasks.

06 Jul 2022
Accurate and consistent predictions of echocardiography parameters are
important for cardiovascular diagnosis and treatment. In particular,
segmentations of the left ventricle can be used to derive ventricular volume,
ejection fraction (EF) and other relevant measurements. In this paper we
propose a new automated method called EchoGraphs for predicting ejection
fraction and segmenting the left ventricle by detecting anatomical keypoints.
Models for direct coordinate regression based on Graph Convolutional Networks
(GCNs) are used to detect the keypoints. GCNs can learn to represent the
cardiac shape based on local appearance of each keypoint, as well as global
spatial and temporal structures of all keypoints combined. We evaluate our
EchoGraphs model on the EchoNet benchmark dataset. Compared to semantic
segmentation, GCNs show accurate segmentation and improvements in robustness
and inference runtime. EF is computed simultaneously to segmentations and our
method also obtains state-of-the-art ejection fraction estimation. Source code
is available online: this https URL
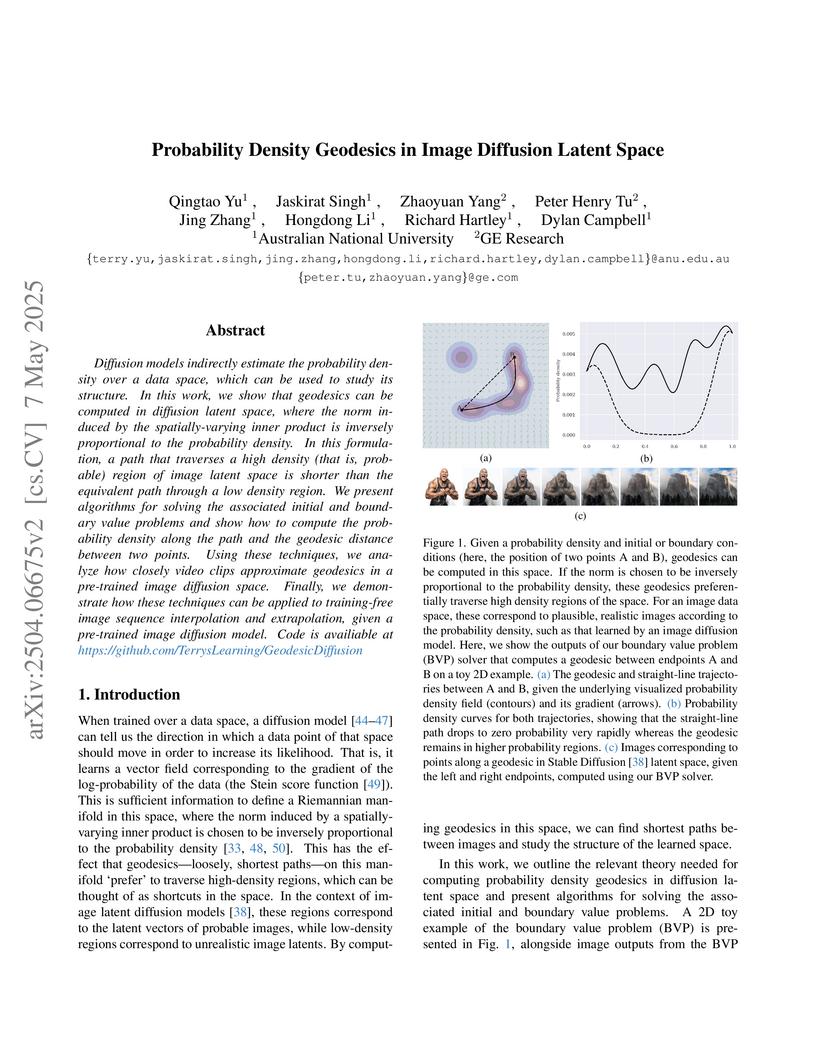
07 May 2025
Diffusion models indirectly estimate the probability density over a data
space, which can be used to study its structure. In this work, we show that
geodesics can be computed in diffusion latent space, where the norm induced by
the spatially-varying inner product is inversely proportional to the
probability density. In this formulation, a path that traverses a high density
(that is, probable) region of image latent space is shorter than the equivalent
path through a low density region. We present algorithms for solving the
associated initial and boundary value problems and show how to compute the
probability density along the path and the geodesic distance between two
points. Using these techniques, we analyze how closely video clips approximate
geodesics in a pre-trained image diffusion space. Finally, we demonstrate how
these techniques can be applied to training-free image sequence interpolation
and extrapolation, given a pre-trained image diffusion model.

18 Aug 2019
3D point cloud segmentation remains challenging for structureless and
textureless regions. We present a new unified point-based framework for 3D
point cloud segmentation that effectively optimizes pixel-level features,
geometrical structures and global context priors of an entire scene. By
back-projecting 2D image features into 3D coordinates, our network learns 2D
textural appearance and 3D structural features in a unified framework. In
addition, we investigate a global context prior to obtain a better prediction.
We evaluate our framework on ScanNet online benchmark and show that our method
outperforms several state-of-the-art approaches. We explore synthesizing camera
poses in 3D reconstructed scenes for achieving higher performance. In-depth
analysis on feature combinations and synthetic camera pose verify that features
from different modalities benefit each other and dense camera pose sampling
further improves the segmentation results.

11 Nov 2019

We present a method of discovering governing differential equations from data
without the need to specify a priori the terms to appear in the equation. The
input to our method is a dataset (or ensemble of datasets) corresponding to a
particular solution (or ensemble of particular solutions) of a differential
equation. The output is a human-readable differential equation with parameters
calibrated to the individual particular solutions provided. The key to our
method is to learn differentiable models of the data that subsequently serve as
inputs to a genetic programming algorithm in which graphs specify computation
over arbitrary compositions of functions, parameters, and (potentially
differential) operators on functions. Differential operators are composed and
evaluated using recursive application of automatic differentiation, allowing
our algorithm to explore arbitrary compositions of operators without the need
for human intervention. We also demonstrate an active learning process to
identify and remedy deficiencies in the proposed governing equations.

01 Jul 2021

Modern day engineering problems are ubiquitously characterized by sophisticated computer codes that map parameters or inputs to an underlying physical process. In other situations, experimental setups are used to model the physical process in a laboratory, ensuring high precision while being costly in materials and logistics. In both scenarios, only limited amount of data can be generated by querying the expensive information source at a finite number of inputs or designs. This problem is compounded further in the presence of a high-dimensional input space. State-of-the-art parameter space dimension reduction methods, such as active subspace, aim to identify a subspace of the original input space that is sufficient to explain the output response. These methods are restricted by their reliance on gradient evaluations or copious data, making them inadequate to expensive problems without direct access to gradients. The proposed methodology is gradient-free and fully Bayesian, as it quantifies uncertainty in both the low-dimensional subspace and the surrogate model parameters. This enables a full quantification of epistemic uncertainty and robustness to limited data availability. It is validated on multiple datasets from engineering and science and compared to two other state-of-the-art methods based on four aspects: a) recovery of the active subspace, b) deterministic prediction accuracy, c) probabilistic prediction accuracy, and d) training time. The comparison shows that the proposed method improves the active subspace recovery and predictive accuracy, in both the deterministic and probabilistic sense, when only few model observations are available for training, at the cost of increased training time.

20 Dec 2023
In this work, we formulate a novel framework for adversarial robustness using
the manifold hypothesis. This framework provides sufficient conditions for
defending against adversarial examples. We develop an adversarial purification
method with this framework. Our method combines manifold learning with
variational inference to provide adversarial robustness without the need for
expensive adversarial training. Experimentally, our approach can provide
adversarial robustness even if attackers are aware of the existence of the
defense. In addition, our method can also serve as a test-time defense
mechanism for variational autoencoders.

19 Feb 2025
Few-shot adaptation for Vision-Language Models (VLMs) presents a dilemma:
balancing in-distribution accuracy with out-of-distribution generalization.
Recent research has utilized low-level concepts such as visual attributes to
enhance generalization. However, this study reveals that VLMs overly rely on a
small subset of attributes on decision-making, which co-occur with the category
but are not inherently part of it, termed spuriously correlated attributes.
This biased nature of VLMs results in poor generalization. To address this, 1)
we first propose Spurious Attribute Probing (SAP), identifying and filtering
out these problematic attributes to significantly enhance the generalization of
existing attribute-based methods; 2) We introduce Spurious Attribute Shielding
(SAS), a plug-and-play module that mitigates the influence of these attributes
on prediction, seamlessly integrating into various Parameter-Efficient
Fine-Tuning (PEFT) methods. In experiments, SAP and SAS significantly enhance
accuracy on distribution shifts across 11 datasets and 3 generalization tasks
without compromising downstream performance, establishing a new
state-of-the-art benchmark.

30 Sep 2022




As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This first paper presents a thorough literature review of digital twin trends across many disciplines currently pursuing this area of research. Then, digital twin modeling and twinning enabling technologies are further analyzed by classifying them into two main categories: physical-to-virtual, and virtual-to-physical, based on the direction in which data flows. Finally, this paper provides perspectives on the trajectory of digital twin technology over the next decade, and introduces a few emerging areas of research which will likely be of great use in future digital twin research. In part two of this review, the role of uncertainty quantification and optimization are discussed, a battery digital twin is demonstrated, and more perspectives on the future of digital twin are shared.

01 Mar 2024
To facilitate diagnosis on cardiac ultrasound (US), clinical practice has established several standard views of the heart, which serve as reference points for diagnostic measurements and define viewports from which images are acquired. Automatic view recognition involves grouping those images into classes of standard views. Although deep learning techniques have been successful in achieving this, they still struggle with fully verifying the suitability of an image for specific measurements due to factors like the correct location, pose, and potential occlusions of cardiac structures. Our approach goes beyond view classification and incorporates a 3D mesh reconstruction of the heart that enables several more downstream tasks, like segmentation and pose estimation. In this work, we explore learning 3D heart meshes via graph convolutions, using similar techniques to learn 3D meshes in natural images, such as human pose estimation. As the availability of fully annotated 3D images is limited, we generate synthetic US images from 3D meshes by training an adversarial denoising diffusion model. Experiments were conducted on synthetic and clinical cases for view recognition and structure detection. The approach yielded good performance on synthetic images and, despite being exclusively trained on synthetic data, it already showed potential when applied to clinical images. With this proof-of-concept, we aim to demonstrate the benefits of graphs to improve cardiac view recognition that can ultimately lead to better efficiency in cardiac diagnosis.

04 May 2022
In this paper, we introduce Masked Anomaly Detection (MAD), a general
self-supervised learning task for multivariate time series anomaly detection.
With the increasing availability of sensor data from industrial systems, being
able to detecting anomalies from streams of multivariate time series data is of
significant importance. Given the scarcity of anomalies in real-world
applications, the majority of literature has been focusing on modeling
normality. The learned normal representations can empower anomaly detection as
the model has learned to capture certain key underlying data regularities. A
typical formulation is to learn a predictive model, i.e., use a window of time
series data to predict future data values. In this paper, we propose an
alternative self-supervised learning task. By randomly masking a portion of the
inputs and training a model to estimate them using the remaining ones, MAD is
an improvement over the traditional left-to-right next step prediction (NSP)
task. Our experimental results demonstrate that MAD can achieve better anomaly
detection rates over traditional NSP approaches when using exactly the same
neural network (NN) base models, and can be modified to run as fast as NSP
models during test time on the same hardware, thus making it an ideal upgrade
for many existing NSP-based NN anomaly detection models.

08 Jun 2011
Predictive distributions need to be aggregated when probabilistic forecasts
are merged, or when expert opinions expressed in terms of probability
distributions are fused. We take a prediction space approach that applies to
discrete, mixed discrete-continuous and continuous predictive distributions
alike, and study combination formulas for cumulative distribution functions
from the perspectives of coherence, probabilistic and conditional calibration,
and dispersion. Both linear and non-linear aggregation methods are
investigated, including generalized, spread-adjusted and beta-transformed
linear pools. The effects and techniques are demonstrated theoretically, in
simulation examples, and in case studies on density forecasts for S&P 500
returns and daily maximum temperature at Seattle-Tacoma Airport.

27 Aug 2022
As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This second paper presents a literature review of key enabling technologies of digital twins, with an emphasis on uncertainty quantification, optimization methods, open source datasets and tools, major findings, challenges, and future directions. Discussions focus on current methods of uncertainty quantification and optimization and how they are applied in different dimensions of a digital twin. Additionally, this paper presents a case study where a battery digital twin is constructed and tested to illustrate some of the modeling and twinning methods reviewed in this two-part review. Code and preprocessed data for generating all the results and figures presented in the case study are available on GitHub.

22 Aug 2020
Modern deep learning systems for medical image classification have
demonstrated exceptional capabilities for distinguishing between image based
medical categories. However, they are severely hindered by their ina-bility to
explain the reasoning behind their decision making. This is partly due to the
uninterpretable continuous latent representations of neural net-works. Emergent
languages (EL) have recently been shown to enhance the capabilities of neural
networks by equipping them with symbolic represen-tations in the framework of
referential games. Symbolic representations are one of the cornerstones of
highly explainable good old fashioned AI (GOFAI) systems. In this work, we
demonstrate for the first time, the emer-gence of deep symbolic representations
of emergent language in the frame-work of image classification. We show that EL
based classification models can perform as well as, if not better than state of
the art deep learning mod-els. In addition, they provide a symbolic
representation that opens up an entire field of possibilities of interpretable
GOFAI methods involving symbol manipulation. We demonstrate the EL
classification framework on immune cell marker based cell classification and
chest X-ray classification using the CheXpert dataset. Code is available online
at this https URL
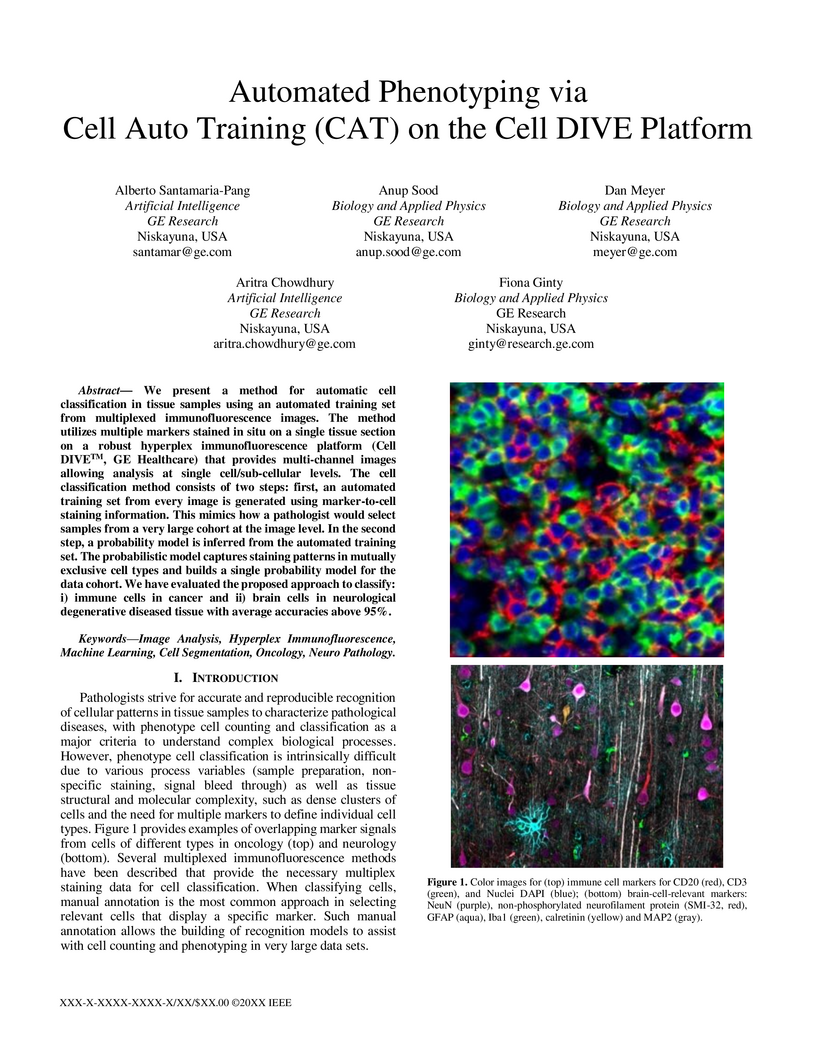
18 Jul 2020
We present a method for automatic cell classification in tissue samples using
an automated training set from multiplexed immunofluorescence images. The
method utilizes multiple markers stained in situ on a single tissue section on
a robust hyperplex immunofluorescence platform (Cell DIVE, GE Healthcare) that
provides multi-channel images allowing analysis at single cell/sub-cellular
levels. The cell classification method consists of two steps: first, an
automated training set from every image is generated using marker-to-cell
staining information. This mimics how a pathologist would select samples from a
very large cohort at the image level. In the second step, a probability model
is inferred from the automated training set. The probabilistic model captures
staining patterns in mutually exclusive cell types and builds a single
probability model for the data cohort. We have evaluated the proposed approach
to classify: i) immune cells in cancer and ii) brain cells in neurological
degenerative diseased tissue with average accuracies above 95%.

04 Aug 2020
Recent advances in methods focused on the grounding problem have resulted in
techniques that can be used to construct a symbolic language associated with a
specific domain. Inspired by how humans communicate complex ideas through
language, we developed a generalized Symbolic Semantic () framework
for interpretable segmentation. Unlike adversarial models (e.g., GANs), we
explicitly model cooperation between two agents, a Sender and a Receiver, that
must cooperate to achieve a common goal. The Sender receives information from a
high layer of a segmentation network and generates a symbolic sentence derived
from a categorical distribution. The Receiver obtains the symbolic sentences
and co-generates the segmentation mask. In order for the model to converge, the
Sender and Receiver must learn to communicate using a private language. We
apply our architecture to segment tumors in the TCGA dataset. A UNet-like
architecture is used to generate input to the Sender network which produces a
symbolic sentence, and a Receiver network co-generates the segmentation mask
based on the sentence. Our Segmentation framework achieved similar or better
performance compared with state-of-the-art segmentation methods. In addition,
our results suggest direct interpretation of the symbolic sentences to
discriminate between normal and tumor tissue, tumor morphology, and other image
characteristics.

18 Aug 2019

Deep neural networks are known to be fragile to small adversarial
perturbations. This issue becomes more critical when a neural network is
interconnected with a physical system in a closed loop. In this paper, we show
how to combine recent works on neural network certification tools (which are
mainly used in static settings such as image classification) with robust
control theory to certify a neural network policy in a control loop.
Specifically, we give a sufficient condition and an algorithm to ensure that
the closed loop state and control constraints are satisfied when the persistent
adversarial perturbation is l-infinity norm bounded. Our method is based on
finding a positively invariant set of the closed loop dynamical system, and
thus we do not require the differentiability or the continuity of the neural
network policy. Along with the verification result, we also develop an
effective attack strategy for neural network control systems that outperforms
exhaustive Monte-Carlo search significantly. We show that our certification
algorithm works well on learned models and achieves 5 times better result than
the traditional Lipschitz-based method to certify the robustness of a neural
network policy on a cart pole control problem.

30 Oct 2024
Recent text-to-image personalization methods have shown great promise in
teaching a diffusion model user-specified concepts given a few images for
reusing the acquired concepts in a novel context. With massive efforts being
dedicated to personalized generation, a promising extension is personalized
editing, namely to edit an image using personalized concepts, which can provide
a more precise guidance signal than traditional textual guidance. To address
this, a straightforward solution is to incorporate a personalized diffusion
model with a text-driven editing framework. However, such a solution often
shows unsatisfactory editability on the source image. To address this, we
propose DreamSteerer, a plug-in method for augmenting existing T2I
personalization methods. Specifically, we enhance the source image conditioned
editability of a personalized diffusion model via a novel Editability Driven
Score Distillation (EDSD) objective. Moreover, we identify a mode trapping
issue with EDSD, and propose a mode shifting regularization with spatial
feature guided sampling to avoid such an issue. We further employ two key
modifications to the Delta Denoising Score framework that enable high-fidelity
local editing with personalized concepts. Extensive experiments validate that
DreamSteerer can significantly improve the editability of several T2I
personalization baselines while being computationally efficient.
There are no more papers matching your filters at the moment.
