05 Sep 2025

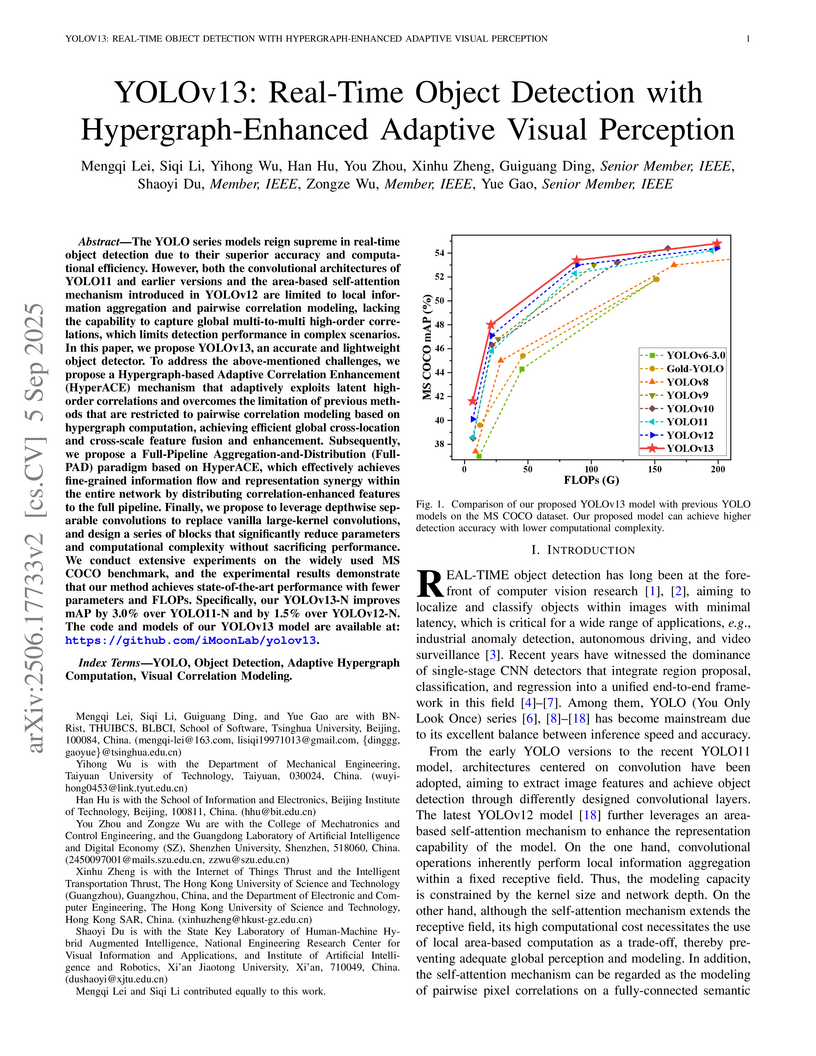
YOLOv13 enhances real-time object detection by integrating an adaptive hypergraph computation mechanism for high-order visual correlation modeling and a full-pipeline feature distribution paradigm. The approach yields improved detection accuracy on the MS COCO benchmark, with the Nano variant achieving a 1.5% mAP@50:95 increase over YOLOv12-N, while maintaining or reducing computational cost.

30 Mar 2025
University of Oslo Beijing Normal University
Beijing Normal University New York University
New York University Tsinghua UniversityShenzhen UniversityGeorge Mason UniversityGuangdong Laboratory of Artificial Intelligence and Digital Economy (SZ)EleutherAITano LabsRecursal AIDalle Molle Institute for Artificial Intelligence USI-SUPSIRWKV Project (under Linux Foundation AI & Data)Denigma
Tsinghua UniversityShenzhen UniversityGeorge Mason UniversityGuangdong Laboratory of Artificial Intelligence and Digital Economy (SZ)EleutherAITano LabsRecursal AIDalle Molle Institute for Artificial Intelligence USI-SUPSIRWKV Project (under Linux Foundation AI & Data)Denigma
Beijing Normal UniversityNew York UniversityTsinghua UniversityShenzhen UniversityGeorge Mason UniversityGuangdong Laboratory of Artificial Intelligence and Digital Economy (SZ)EleutherAITano LabsRecursal AIDalle Molle Institute for Artificial Intelligence USI-SUPSIRWKV Project (under Linux Foundation AI & Data)Denigma
The RWKV-7 "Goose" architecture introduces a recurrent neural network design with expressive dynamic state evolution through a generalized delta rule, addressing the quadratic complexity of Transformers. This model achieves new state-of-the-art multilingual performance and matches English benchmarks with significantly less training data, while maintaining linear computational complexity and constant memory usage.
04 Sep 2025

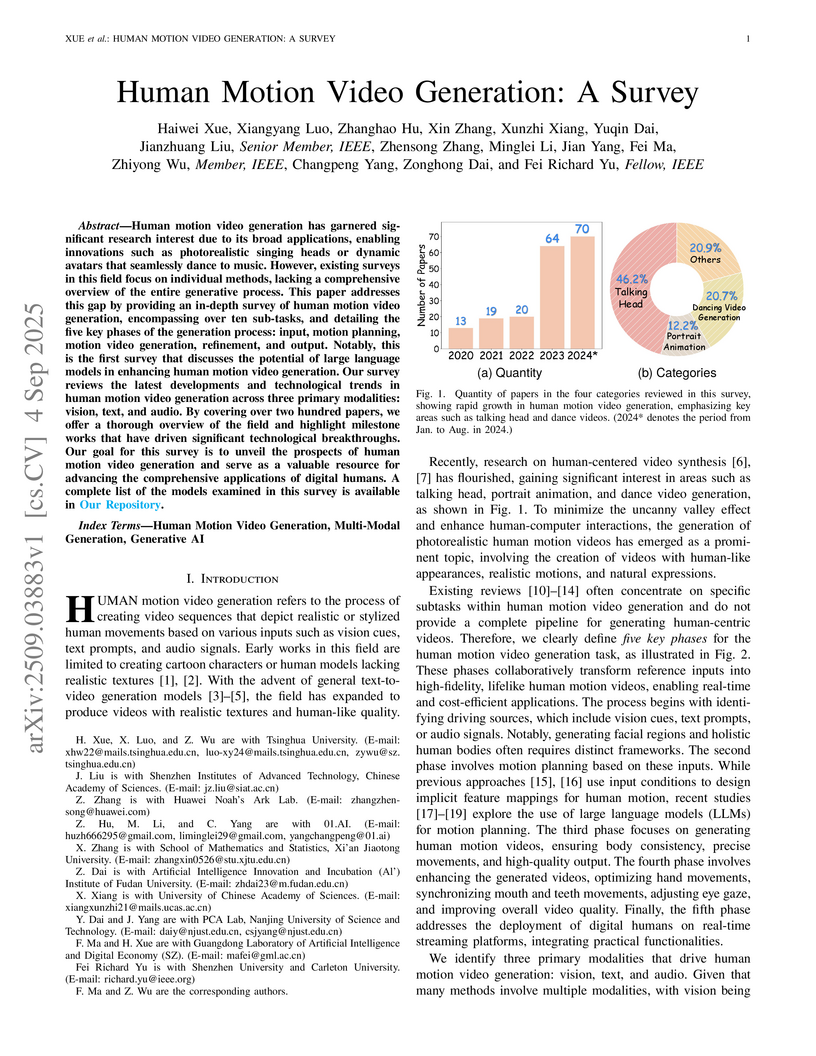
This paper provides the first comprehensive, end-to-end survey of human motion video generation, introducing a novel five-phase pipeline and pioneering the discussion of Large Language Models (LLMs) for motion planning. It reviews over 200 papers, categorizes sub-tasks by input modality, and conducts a quantitative comparison of state-of-the-art methods.

22 Sep 2025
The explosive growth of generative video models has amplified the demand for reliable copyright preservation of AI-generated content. Despite its popularity in image synthesis, invisible generative watermarking remains largely underexplored in video generation. To address this gap, we propose Safe-Sora, the first framework to embed graphical watermarks directly into the video generation process. Motivated by the observation that watermarking performance is closely tied to the visual similarity between the watermark and cover content, we introduce a hierarchical coarse-to-fine adaptive matching mechanism. Specifically, the watermark image is divided into patches, each assigned to the most visually similar video frame, and further localized to the optimal spatial region for seamless embedding. To enable spatiotemporal fusion of watermark patches across video frames, we develop a 3D wavelet transform-enhanced Mamba architecture with a novel spatiotemporal local scanning strategy, effectively modeling long-range dependencies during watermark embedding and retrieval. To the best of our knowledge, this is the first attempt to apply state space models to watermarking, opening new avenues for efficient and robust watermark protection. Extensive experiments demonstrate that Safe-Sora achieves state-of-the-art performance in terms of video quality, watermark fidelity, and robustness, which is largely attributed to our proposals. Code is publicly available at this https URL

26 Sep 2024
 University of California, Santa Barbara
University of California, Santa Barbara Harvard University
Harvard University Chinese Academy of SciencesNew York UniversityTsinghua UniversityUniversity of EdinburghOhio State University
Chinese Academy of SciencesNew York UniversityTsinghua UniversityUniversity of EdinburghOhio State University University of British ColumbiaGuangdong Laboratory of Artificial Intelligence and Digital Economy (SZ)
University of British ColumbiaGuangdong Laboratory of Artificial Intelligence and Digital Economy (SZ) University of California, Santa CruzEleutherAIContextual AIDalle Molle Institute for Artificial Intelligence ResearchRecursal AIRonsor LabsCharm TherapeuticsRWKV ProjectNextremer Co. Ltd.Wroclaw TechLuxiTech Co. Ltd.
University of California, Santa CruzEleutherAIContextual AIDalle Molle Institute for Artificial Intelligence ResearchRecursal AIRonsor LabsCharm TherapeuticsRWKV ProjectNextremer Co. Ltd.Wroclaw TechLuxiTech Co. Ltd.

We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: this https URL Training code at: this https URL Inference code at: this https URL Time-parallel training code at: this https URL

24 Oct 2025

DeepSeek-R1 has successfully enhanced Large Language Model (LLM) reasoning capabilities through its rule-based reward system. While it's a ''perfect'' reward system that effectively mitigates reward hacking, such reward functions are often discrete. Our experimental observations suggest that discrete rewards can lead to gradient anomaly, unstable optimization, and slow convergence. To address this issue, we propose ReDit (Reward Dithering), a method that dithers the discrete reward signal by adding simple random noise. With this perturbed reward, exploratory gradients are continuously provided throughout the learning process, enabling smoother gradient updates and accelerating convergence. The injected noise also introduces stochasticity into flat reward regions, encouraging the model to explore novel policies and escape local optima. Experiments across diverse tasks demonstrate the effectiveness and efficiency of ReDit. On average, ReDit achieves performance comparable to vanilla GRPO with only approximately 10% the training steps, and furthermore, still exhibits a 4% performance improvement over vanilla GRPO when trained for a similar duration. Visualizations confirm significant mitigation of gradient issues with ReDit. Moreover, theoretical analyses are provided to further validate these advantages.

01 Jun 2023

Tencent and academic researchers developed the Explicit Feature Interaction-aware Uplift Network (EFIN), a deep learning model that estimates the incremental impact of marketing incentives by explicitly modeling detailed treatment features and their interactions with user characteristics. This approach leads to more accurate individual treatment effect predictions and, in a real-world credit card marketing deployment, resulted in a 10% improvement in ROI and an 8% increase in monthly active users.

23 Mar 2024

Large language models (LLM) not only have revolutionized the field of natural language processing (NLP) but also have the potential to reshape many other fields, e.g., recommender systems (RS). However, most of the related work treats an LLM as a component of the conventional recommendation pipeline (e.g., as a feature extractor), which may not be able to fully leverage the generative power of LLM. Instead of separating the recommendation process into multiple stages, such as score computation and re-ranking, this process can be simplified to one stage with LLM: directly generating recommendations from the complete pool of items. This survey reviews the progress, methods, and future directions of LLM-based generative recommendation by examining three questions: 1) What generative recommendation is, 2) Why RS should advance to generative recommendation, and 3) How to implement LLM-based generative recommendation for various RS tasks. We hope that this survey can provide the context and guidance needed to explore this interesting and emerging topic.

03 Nov 2025



Large language models (LLMs) hold significant potential for mental health support, capable of generating empathetic responses and simulating therapeutic conversations. However, existing LLM-based approaches often lack the clinical grounding necessary for real-world psychological counseling, particularly in explicit diagnostic reasoning aligned with standards like the DSM/ICD and incorporating diverse therapeutic modalities beyond basic empathy or single strategies. To address these critical limitations, we propose PsyLLM, the first large language model designed to systematically integrate both diagnostic and therapeutic reasoning for mental health counseling. To develop PsyLLM, we design a novel automated data synthesis pipeline that processes real-world mental health posts collected from Reddit, where users frequently share psychological distress and seek community support. This pipeline processes real-world mental health posts, generates multi-turn dialogue structures, and leverages LLMs guided by international diagnostic standards (e.g., DSM/ICD) and multiple therapeutic frameworks (e.g., CBT, ACT, psychodynamic) to simulate detailed clinical reasoning processes. Rigorous multi-dimensional filtering ensures the generation of high-quality, clinically aligned dialogue data. In addition, we introduce a new benchmark and evaluation protocol, assessing counseling quality across four key dimensions. Our experiments demonstrate that PsyLLM significantly outperforms state-of-the-art baseline models on this benchmark. The model weights and dataset have been publicly released at this https URL.

09 Jun 2025
SceneRAG introduces a framework for long-form video understanding that segments videos into semantically coherent scenes, constructs multimodal knowledge graphs, and performs multi-hop retrieval-augmented generation. It achieves higher quality and more coherent answers by leveraging scene-level context, outperforming existing RAG and vision-language models on the LongerVideos benchmark.

11 Aug 2025

TAR-TVG enhances Large Vision-Language Models for Temporal Video Grounding by enabling interpretable, progressively refined temporal reasoning through explicit timestamp anchors. The method established new state-of-the-art performance on Charades-STA with a 61.1 mIoU and 50.2 R1@0.7 using a 7B model, also demonstrating strong generalization across diverse datasets.

12 Sep 2025
The perception and generation of Human-Object Interaction (HOI) are crucial for fields such as robotics, AR/VR, and human behavior understanding. However, current approaches model this task in an offline setting, where information at each time step can be drawn from the entire interaction sequence. In contrast, in real-world scenarios, the information available at each time step comes only from the current moment and historical data, i.e., an online setting. We find that offline methods perform poorly in an online context. Based on this observation, we propose two new tasks: Online HOI Generation and Perception. To address this task, we introduce the OnlineHOI framework, a network architecture based on the Mamba framework that employs a memory mechanism. By leveraging Mamba's powerful modeling capabilities for streaming data and the Memory mechanism's efficient integration of historical information, we achieve state-of-the-art results on the Core4D and OAKINK2 online generation tasks, as well as the online HOI4D perception task.

16 Aug 2025


PVChat introduces the first personalized Video Large Language Model capable of subject-aware question answering from a single reference video. It significantly outperforms existing state-of-the-art ViLLMs in personalized comprehension, achieving 0.901 accuracy and a BLEU score of 0.562.

17 Sep 2025
Signed Distance Fields (SDFs) are a fundamental representation in robot motion planning. Their configuration-space counterpart, the Configuration Space Distance Field (CDF), directly encodes distances in joint space, offering a unified representation for optimization and control. However, existing CDF formulations face two major challenges in high-degree-of-freedom (DoF) robots: (1) they effectively return only a single nearest collision configuration, neglecting the multi-modal nature of minimal-distance collision configurations and leading to gradient ambiguity; and (2) they rely on sparse sampling of the collision boundary, which often fails to identify the true closest configurations, producing oversmoothed approximations and geometric distortion in high-dimensional spaces. We propose CDFlow, a novel framework that addresses these limitations by learning a continuous flow in configuration space via Neural Ordinary Differential Equations (Neural ODEs). We redefine the problem from finding a single nearest point to modeling the distribution of minimal-distance collision configurations. We also introduce an adaptive refinement sampling strategy to generate high-fidelity training data for this distribution. The resulting Neural ODE implicitly models this multi-modal distribution and produces a smooth, consistent gradient field-derived as the expected direction towards the distribution-that mitigates gradient ambiguity and preserves sharp geometric features. Extensive experiments on high-DoF motion planning tasks demonstrate that CDFlow significantly improves planning efficiency, trajectory quality, and robustness compared to existing CDF-based methods, enabling more robust and efficient planning for collision-aware robots in complex environments.

28 Aug 2024
Large Language Models (LLMs) have garnered widespread attention due to their remarkable performance across various tasks. However, to mitigate the issue of hallucinations, LLMs often incorporate retrieval-augmented pipeline to provide them with rich external knowledge and context. Nevertheless, challenges stem from inaccurate and coarse-grained context retrieved from the retriever. Supplying irrelevant context to the LLMs can result in poorer responses, increased inference latency, and higher costs. This paper introduces a method called Instruction-Aware Contextual Compression, which filters out less informative content, thereby accelerating and enhancing the use of LLMs. The experimental results demonstrate that Instruction-Aware Contextual Compression notably reduces memory consumption and minimizes generation latency while maintaining performance levels comparable to those achieved with the use of the full context. Specifically, we achieved a 50% reduction in context-related costs, resulting in a 5% reduction in inference memory usage and a 2.2-fold increase in inference speed, with only a minor drop of 0.047 in Rouge-1. These findings suggest that our method strikes an effective balance between efficiency and performance.

18 Apr 2024

The multimodal recommendation has gradually become the infrastructure of online media platforms, enabling them to provide personalized service to users through a joint modeling of user historical behaviors (e.g., purchases, clicks) and item various modalities (e.g., visual and textual). The majority of existing studies typically focus on utilizing modal features or modal-related graph structure to learn user local interests. Nevertheless, these approaches encounter two limitations: (1) Shared updates of user ID embeddings result in the consequential coupling between collaboration and multimodal signals; (2) Lack of exploration into robust global user interests to alleviate the sparse interaction problems faced by local interest modeling. To address these issues, we propose a novel Local and Global Graph Learning-guided Multimodal Recommender (LGMRec), which jointly models local and global user interests. Specifically, we present a local graph embedding module to independently learn collaborative-related and modality-related embeddings of users and items with local topological relations. Moreover, a global hypergraph embedding module is designed to capture global user and item embeddings by modeling insightful global dependency relations. The global embeddings acquired within the hypergraph embedding space can then be combined with two decoupled local embeddings to improve the accuracy and robustness of recommendations. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our LGMRec over various state-of-the-art recommendation baselines, showcasing its effectiveness in modeling both local and global user interests.

31 Mar 2025


A collaborative team from Chinese institutions introduces MuseFace, a text-driven face editing framework that generates fine-grained semantic masks through diffusion models to enable controlled facial modifications, demonstrating improved local editing capabilities while maintaining identity preservation compared to existing approaches.

26 May 2025

EMLoC is a training-free adaptation framework for multi-modal large language models that addresses the computational bottleneck of long contexts. The framework compresses multi-modal contexts by an average of 77% and reduces inference FLOPs by 23% while maintaining or improving performance across various benchmarks, making in-context learning more practical.

19 Dec 2024
Visual Language Models (VLMs) have rapidly progressed with the recent success
of large language models. However, there have been few attempts to incorporate
efficient linear Recurrent Neural Networks (RNNs) architectures into VLMs. In
this study, we introduce VisualRWKV, the first application of a linear RNN
model to multimodal learning tasks, leveraging the pre-trained RWKV language
model. We propose a data-dependent recurrence and sandwich prompts to enhance
our modeling capabilities, along with a 2D image scanning mechanism to enrich
the processing of visual sequences. Extensive experiments demonstrate that
VisualRWKV achieves competitive performance compared to Transformer-based
models like LLaVA-1.5 on various benchmarks. Compared to LLaVA-1.5, VisualRWKV
has a speed advantage of 3.98 times and can save 54% of GPU memory when
reaching an inference length of 24K tokens. To facilitate further research and
analysis, we have made the checkpoints and the associated code publicly
accessible at the following GitHub repository: see
this https URL

25 Aug 2025
EmoBench-M introduces a comprehensive, psychologically grounded benchmark for evaluating multimodal large language models' emotional intelligence across dynamic video, audio, and text. It reveals a substantial performance gap between state-of-the-art MLLMs and human emotional understanding, particularly in conversational contexts.
There are no more papers matching your filters at the moment.
