
30 Sep 2025
Huawei Technologies and Huawei Cloud researchers introduced Ego3D-Bench, a new benchmark for evaluating Vision-Language Models on ego-centric multi-view 3D spatial reasoning in dynamic outdoor scenes. They also developed Ego3D-VLM, a post-training framework that enhances VLM spatial understanding by generating a textual cognitive map from estimated 3D coordinates.

28 Jun 2025
Researchers from Huawei Technologies Canada and Simon Fraser University developed Encode-Prefill-Decode (EPD) Disaggregation, a framework for serving Large Multimodal Models (LMMs) by separating the encoding, prefill, and decode stages onto dedicated resources. This approach improves resource utilization and reduces memory consumption by up to 15x, while significantly enhancing Time to First Token (TTFT) by up to 71.9% compared to existing methods.

27 Mar 2023

The NL4Opt Competition at NeurIPS 2022 established benchmarks and a public dataset for automatically translating natural language problem descriptions into mathematical optimization formulations. This work explored the capabilities of both specialized models and general large language models, demonstrating that advanced NLP techniques can effectively bridge the gap between human language and optimization solvers, with ChatGPT achieving 0.927 accuracy in formulation generation, outperforming competition entries.

06 Apr 2025

The FRAP framework enhances text-to-image generation by employing adaptive per-token prompt weighting during inference, improving prompt-image alignment and realism. It achieves superior image authenticity, as measured by CLIP-IQA-Real, and reduces average inference latency by up to 5 seconds compared to prior latent code optimization methods.

29 May 2024
Recently, large language models (LLMs) have shown remarkable capabilities
including understanding context, engaging in logical reasoning, and generating
responses. However, this is achieved at the expense of stringent computational
and memory requirements, hindering their ability to effectively support long
input sequences. This survey provides an inclusive review of the recent
techniques and methods devised to extend the sequence length in LLMs, thereby
enhancing their capacity for long-context understanding. In particular, we
review and categorize a wide range of techniques including architectural
modifications, such as modified positional encoding and altered attention
mechanisms, which are designed to enhance the processing of longer sequences
while avoiding a proportional increase in computational requirements. The
diverse methodologies investigated in this study can be leveraged across
different phases of LLMs, i.e., training, fine-tuning and inference. This
enables LLMs to efficiently process extended sequences. The limitations of the
current methodologies is discussed in the last section along with the
suggestions for future research directions, underscoring the importance of
sequence length in the continued advancement of LLMs.

15 Jul 2025

RA-DP enables high-frequency replanning and training-free adaptation for diffusion-based robotic policies, achieving up to 5 times faster control loops and robustly handling unseen dynamic obstacles in both simulated and real-world environments.

20 Aug 2025
Loss of plasticity is a phenomenon in which a neural network loses its ability to learn when trained for an extended time on non-stationary data. It is a crucial problem to overcome when designing systems that learn continually. An effective technique for preventing loss of plasticity is reinitializing parts of the network. In this paper, we compare two different reinitialization schemes: reinitializing units vs reinitializing weights. We propose a new algorithm, which we name \textit{selective weight reinitialization}, for reinitializing the least useful weights in a network. We compare our algorithm to continual backpropagation and ReDo, two previously proposed algorithms that reinitialize units in the network. Through our experiments in continual supervised learning problems, we identify two settings when reinitializing weights is more effective at maintaining plasticity than reinitializing units: (1) when the network has a small number of units and (2) when the network includes layer normalization. Conversely, reinitializing weights and units are equally effective at maintaining plasticity when the network is of sufficient size and does not include layer normalization. We found that reinitializing weights maintains plasticity in a wider variety of settings than reinitializing units.

30 Jan 2025
PixelMan introduces an inversion-free and training-free methodology for consistent object editing in images using diffusion models, directly manipulating pixels to guide generation. This approach achieves superior qualitative and quantitative editing results, including faithful object reproduction and cohesive inpainting, with significantly fewer computational steps, completing edits in 16 inference steps (9 seconds) compared to typical 50-step methods (24 seconds).

11 Oct 2022

We describe an augmented intelligence system for simplifying and enhancing the modeling experience for operations research. Using this system, the user receives a suggested formulation of an optimization problem based on its description. To facilitate this process, we build an intuitive user interface system that enables the users to validate and edit the suggestions. We investigate controlled generation techniques to obtain an automatic suggestion of formulation. Then, we evaluate their effectiveness with a newly created dataset of linear programming problems drawn from various application domains.

24 Sep 2025

Researchers from Huawei Technologies Canada, Tianjin University, and other institutions developed a theoretical framework for Multi-Agent Generative Flow Networks (MA-GFlowNets), extending GFlowNets to cooperative multi-agent settings. This work introduces algorithms like Joint Flow Networks (JFN) that enable agents to collaboratively generate diverse high-reward solutions, demonstrating improved exploration and diversity compared to Multi-Agent Reinforcement Learning (MARL) across various tasks.

09 Feb 2025

Researchers from Huawei Technologies Canada, the University of Toronto, and the University of British Columbia developed ORQA, a multi-choice question answering benchmark, to evaluate Large Language Model reasoning in Operations Research. Their study found that current open-source LLMs achieve modest performance on this expert-curated dataset, significantly underperforming human experts, and that Chain-of-Thought prompting often leads to a performance decrease in this domain.

03 Mar 2025
In this paper, we introduce CAPS (Context-Aware Priority Sampling), a novel
method designed to enhance data efficiency in learning-based autonomous driving
systems. CAPS addresses the challenge of imbalanced training datasets in
imitation learning by leveraging Vector Quantized Variational Autoencoders
(VQ-VAEs). The use of VQ-VAE provides a structured and interpretable data
representation, which helps reveal meaningful patterns in the data. These
patterns are used to group the data into clusters, with each sample being
assigned a cluster ID. The cluster IDs are then used to re-balance the dataset,
ensuring that rare yet valuable samples receive higher priority during
training. By ensuring a more diverse and informative training set, CAPS
improves the generalization of the trained planner across a wide range of
driving scenarios. We evaluate our method through closed-loop simulations in
the CARLA environment. The results on Bench2Drive scenarios demonstrate that
our framework outperforms state-of-the-art methods, leading to notable
improvements in model performance.

03 Dec 2022
The popular Proximal Policy Optimization (PPO) algorithm approximates the
solution in a clipped policy space. Does there exist better policies outside of
this space? By using a novel surrogate objective that employs the sigmoid
function (which provides an interesting way of exploration), we found that the
answer is ``YES'', and the better policies are in fact located very far from
the clipped space. We show that PPO is insufficient in ``off-policyness'',
according to an off-policy metric called DEON. Our algorithm explores in a much
larger policy space than PPO, and it maximizes the Conservative Policy
Iteration (CPI) objective better than PPO during training. To the best of our
knowledge, all current PPO methods have the clipping operation and optimize in
the clipped policy space. Our method is the first of this kind, which advances
the understanding of CPI optimization and policy gradient methods. Code is
available at this https URL

02 Oct 2025
Mixture-of-Experts (MoE) models promise efficient scaling of large language models (LLMs) by activating only a small subset of experts per token, but their parallelized inference pipelines make elastic serving challenging. Existing strategies fall short: horizontal scaling provisions entire replicas of the current configuration, often tens to hundreds of accelerators, leading to coarse granularity, long provisioning delays, and costly overprovisioning. Vertical scaling offers finer adjustments but typically requires instance restarts, incurring downtime. These limitations make current approaches ill-suited for the bursty, short-lived traffic patterns common in cloud deployments.
We present ElasticMoE, an elastic scaling framework for MoE LLMs that achieves fine-grained, low-latency, and zero-downtime scaling. ElasticMoE decouples inference execution from memory operations, enabling scaling steps to proceed concurrently with serving. An HBM Management Module (HMM) reuses weights and KV caches via zero-copy remapping, while high-bandwidth peer-to-peer transfers bring newly added accelerators online without interrupting service. A virtual memory based expert redistribution mechanism migrates MoE experts without costly buffer reallocations, reducing peak memory usage during expert parallelism reconfiguration.
Our evaluation on Ascend NPUs with three popular MoE LLMs shows that ElasticMoE achieves up to 9x lower scale-up latency, up to 2x better throughput during scaling, and significantly improves SLO attainment compared to baselines. By enabling fine-grained, concurrent scaling with minimal disruption, ElasticMoE advances the practicality of deploying massive MoE LLMs in dynamic cloud environments.

14 Dec 2021

Non-IID data present a tough challenge for federated learning. In this paper, we explore a novel idea of facilitating pairwise collaborations between clients with similar data. We propose FedAMP, a new method employing federated attentive message passing to facilitate similar clients to collaborate more. We establish the convergence of FedAMP for both convex and non-convex models, and propose a heuristic method to further improve the performance of FedAMP when clients adopt deep neural networks as personalized models. Our extensive experiments on benchmark data sets demonstrate the superior performance of the proposed methods.

20 May 2025
Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and
scalable method to fine-tune and customize large language models (LLMs) for
application-specific needs. However, tasks that require complex reasoning or
deep contextual understanding are often hindered by biases or interference from
the base model when using typical decoding methods like greedy or beam search.
These biases can lead to generic or task-agnostic responses from the base model
instead of leveraging the LoRA-specific adaptations. In this paper, we
introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed
to maximize the use of task-specific knowledge in LoRA-adapted models,
resulting in better downstream performance. CoLD uses contrastive decoding by
scoring candidate tokens based on the divergence between the probability
distributions of a LoRA-adapted expert model and the corresponding base model.
This approach prioritizes tokens that better align with the LoRA's learned
representations, enhancing performance for specialized tasks. While effective,
a naive implementation of CoLD is computationally expensive because each
decoding step requires evaluating multiple token candidates across both models.
To address this, we developed an optimized kernel for Huawei's Ascend NPU. CoLD
achieves up to a 5.54% increase in task accuracy while reducing end-to-end
latency by 28% compared to greedy decoding. This work provides practical and
efficient decoding strategies for fine-tuned LLMs in resource-constrained
environments and has broad implications for applied data science in both cloud
and on-premises settings.
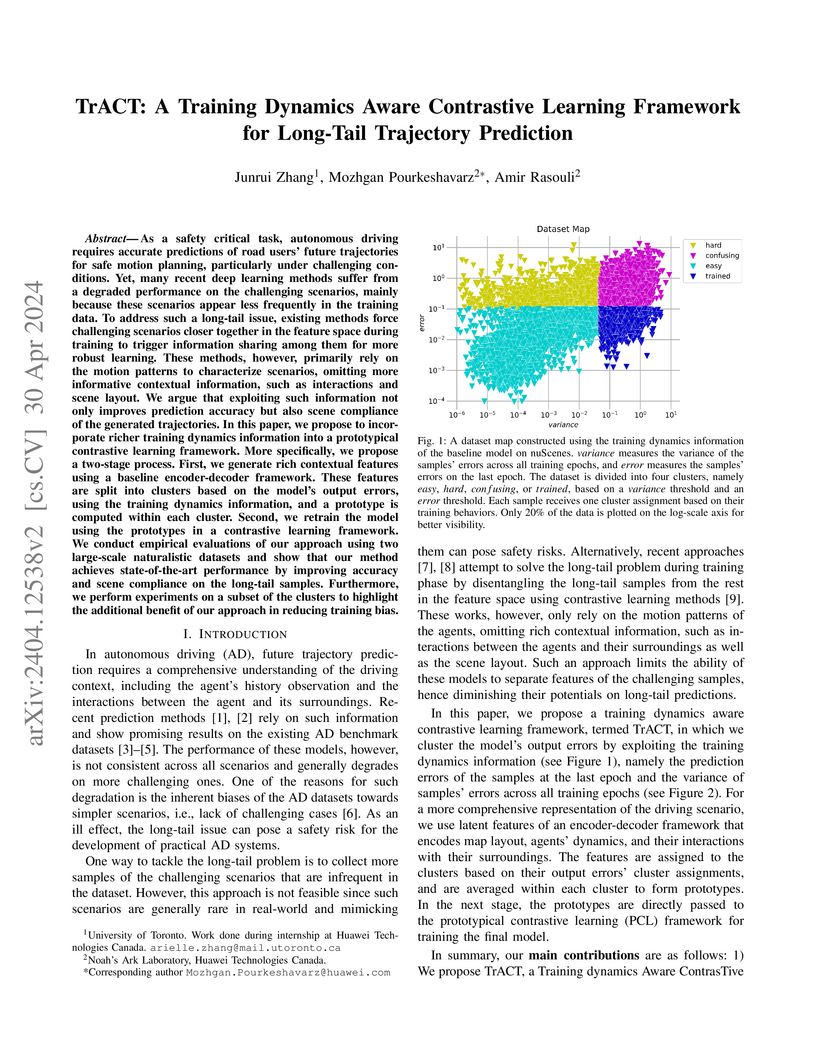
30 Apr 2024
As a safety critical task, autonomous driving requires accurate predictions of road users' future trajectories for safe motion planning, particularly under challenging conditions. Yet, many recent deep learning methods suffer from a degraded performance on the challenging scenarios, mainly because these scenarios appear less frequently in the training data. To address such a long-tail issue, existing methods force challenging scenarios closer together in the feature space during training to trigger information sharing among them for more robust learning. These methods, however, primarily rely on the motion patterns to characterize scenarios, omitting more informative contextual information, such as interactions and scene layout. We argue that exploiting such information not only improves prediction accuracy but also scene compliance of the generated trajectories. In this paper, we propose to incorporate richer training dynamics information into a prototypical contrastive learning framework. More specifically, we propose a two-stage process. First, we generate rich contextual features using a baseline encoder-decoder framework. These features are split into clusters based on the model's output errors, using the training dynamics information, and a prototype is computed within each cluster. Second, we retrain the model using the prototypes in a contrastive learning framework. We conduct empirical evaluations of our approach using two large-scale naturalistic datasets and show that our method achieves state-of-the-art performance by improving accuracy and scene compliance on the long-tail samples. Furthermore, we perform experiments on a subset of the clusters to highlight the additional benefit of our approach in reducing training bias.

29 May 2025
The end-to-end learning pipeline is gradually creating a paradigm shift in the ongoing development of highly autonomous vehicles (AVs), largely due to advances in deep learning, the availability of large-scale training datasets, and improvements in integrated sensor devices. However, a lack of explainability in real-time decisions with contemporary learning methods impedes user trust and attenuates the widespread deployment and commercialization of such vehicles. Moreover, the issue is exacerbated when these vehicles are involved in or cause traffic accidents. Consequently, explainability in end-to-end autonomous driving is essential to build trust in vehicular automation. With that said, automotive researchers have not yet rigorously explored safety benefits and consequences of explanations in end-to-end autonomous driving. This paper aims to bridge the gaps between these topics and seeks to answer the following research question: What are safety implications of explanations in end-to-end autonomous driving? In this regard, we first revisit established safety and explainability concepts in end-to-end driving. Furthermore, we present critical case studies and show the pivotal role of explanations in enhancing driving safety. Finally, we describe insights from empirical studies and reveal potential value, limitations, and caveats of practical explainable AI methods with respect to their potential impacts on safety of end-to-end driving.

06 Mar 2025

CRiTIC, a causal attention gating framework, enhances trajectory prediction model robustness against non-causal perturbations and improves cross-domain generalization. The model maintains competitive prediction accuracy while learning to focus attention on causally relevant agents.

23 Jul 2025
Large language models (LLMs) present intriguing opportunities to enhance user interaction with traditional algorithms and tools in real-world applications. An advanced planning system (APS) is a sophisticated software that leverages optimization to help operations planners create, interpret, and modify an operational plan. While highly beneficial, many customers are priced out of using an APS due to the ongoing costs of consultants responsible for customization and maintenance. To address the need for a more accessible APS expressed by supply chain planners, we present SmartAPS, a conversational system built on a tool-augmented LLM. Our system provides operations planners with an intuitive natural language chat interface, allowing them to query information, perform counterfactual reasoning, receive recommendations, and execute scenario analysis to better manage their operation. A short video demonstrating the system has been released: this https URL
There are no more papers matching your filters at the moment.
