
03 Nov 2025




What is the shortest path between two data points lying in a high-dimensional space? While the answer is trivial in Euclidean geometry, it becomes significantly more complex when the data lies on a curved manifold -- requiring a Riemannian metric to describe the space's local curvature. Estimating such a metric, however, remains a major challenge in high dimensions.
In this work, we propose a method for deriving Riemannian metrics directly from pretrained Energy-Based Models (EBMs) -- a class of generative models that assign low energy to high-density regions. These metrics define spatially varying distances, enabling the computation of geodesics -- shortest paths that follow the data manifold's intrinsic geometry. We introduce two novel metrics derived from EBMs and show that they produce geodesics that remain closer to the data manifold and exhibit lower curvature distortion, as measured by alignment with ground-truth trajectories. We evaluate our approach on increasingly complex datasets: synthetic datasets with known data density, rotated character images with interpretable geometry, and high-resolution natural images embedded in a pretrained VAE latent space.
Our results show that EBM-derived metrics consistently outperform established baselines, especially in high-dimensional settings. Our work is the first to derive Riemannian metrics from EBMs, enabling data-aware geodesics and unlocking scalable, geometry-driven learning for generative modeling and simulation.

24 Aug 2025
Multimodal magnetic resonance imaging (MRI) constitutes the first line of investigation for clinicians in the care of brain tumors, providing crucial insights for surgery planning, treatment monitoring, and biomarker identification. Pre-training on large datasets have been shown to help models learn transferable representations and adapt with minimal labeled data. This behavior is especially valuable in medical imaging, where annotations are often scarce. However, applying this paradigm to multimodal medical data introduces a challenge: most existing approaches assume that all imaging modalities are available during both pre-training and fine-tuning. In practice, missing modalities often occur due to acquisition issues, specialist unavailability, or specific experimental designs on small in-house datasets. Consequently, a common approach involves training a separate model for each desired modality combination, making the process both resource-intensive and impractical for clinical use. Therefore, we introduce BM-MAE, a masked image modeling pre-training strategy tailored for multimodal MRI data. The same pre-trained model seamlessly adapts to any combination of available modalities, extracting rich representations that capture both intra- and inter-modal information. This allows fine-tuning on any subset of modalities without requiring architectural changes, while still benefiting from a model pre-trained on the full set of modalities. Extensive experiments show that the proposed pre-training strategy outperforms or remains competitive with baselines that require separate pre-training for each modality subset, while substantially surpassing training from scratch on several downstream tasks. Additionally, it can quickly and efficiently reconstruct missing modalities, highlighting its practical value. Code and trained models are available at: this https URL

07 Mar 2025
Image segmentation is a challenging task influenced by multiple sources of
uncertainty, such as the data labeling process or the sampling of training
data. In this paper we focus on binary segmentation and address these
challenges using conformal prediction, a family of model- and data-agnostic
methods for uncertainty quantification that provide finite-sample theoretical
guarantees and applicable to any pretrained predictor. Our approach involves
computing nonconformity scores, a type of prediction residual, on held-out
calibration data not used during training. We use dilation, one of the
fundamental operations in mathematical morphology, to construct a margin added
to the borders of predicted segmentation masks. At inference, the predicted set
formed by the mask and its margin contains the ground-truth mask with high
probability, at a confidence level specified by the user. The size of the
margin serves as an indicator of predictive uncertainty for a given model and
dataset. We work in a regime of minimal information as we do not require any
feedback from the predictor: only the predicted masks are needed for computing
the prediction sets. Hence, our method is applicable to any segmentation model,
including those based on deep learning; we evaluate our approach on several
medical imaging applications.

31 Oct 2025
Recent advances in object detectors have led to their adoption for industrial uses. However, their deployment in safety-critical applications is hindered by the inherent lack of reliability of neural networks and the complex structure of object detection models. To address these challenges, we turn to Conformal Prediction, a post-hoc predictive uncertainty quantification procedure with statistical guarantees that are valid for any dataset size, without requiring prior knowledge on the model or data distribution. Our contribution is manifold. First, we formally define the problem of Conformal Object Detection (COD). We introduce a novel method, Sequential Conformal Risk Control (SeqCRC), that extends the statistical guarantees of Conformal Risk Control to two sequential tasks with two parameters, as required in the COD setting. Then, we present old and new loss functions and prediction sets suited to applying SeqCRC to different cases and certification requirements. Finally, we present a conformal toolkit for replication and further exploration of our method. Using this toolkit, we perform extensive experiments that validate our approach and emphasize trade-offs and other practical consequences.

26 Mar 2025


General-purpose multilingual vector representations, used in retrieval,
regression and classification, are traditionally obtained from bidirectional
encoder models. Despite their wide applicability, encoders have been recently
overshadowed by advances in generative decoder-only models. However, many
innovations driving this progress are not inherently tied to decoders. In this
paper, we revisit the development of multilingual encoders through the lens of
these advances, and introduce EuroBERT, a family of multilingual encoders
covering European and widely spoken global languages. Our models outperform
existing alternatives across a diverse range of tasks, spanning multilingual
capabilities, mathematics, and coding, and natively supporting sequences of up
to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering
insights into our dataset composition and training pipeline. We publicly
release the EuroBERT models, including intermediate training checkpoints,
together with our training framework.

13 Apr 2022
Over the past few years, the acceleration of computing resources and research
in deep learning has led to significant practical successes in a range of
tasks, including in particular in computer vision. Building on these advances,
reinforcement learning has also seen a leap forward with the emergence of
agents capable of making decisions directly from visual observations. Despite
these successes, the over-parametrization of neural architectures leads to
memorization of the data used during training and thus to a lack of
generalization. Reinforcement learning agents based on visual inputs also
suffer from this phenomenon by erroneously correlating rewards with unrelated
visual features such as background elements. To alleviate this problem, we
introduce a new regularization technique consisting of channel-consistent local
permutations (CLOP) of the feature maps. The proposed permutations induce
robustness to spatial correlations and help prevent overfitting behaviors in
RL. We demonstrate, on the OpenAI Procgen Benchmark, that RL agents trained
with the CLOP method exhibit robustness to visual changes and better
generalization properties than agents trained using other state-of-the-art
regularization techniques. We also demonstrate the effectiveness of CLOP as a
general regularization technique in supervised learning.

21 Apr 2023
As the interest in autonomous systems continues to grow, one of the major challenges is collecting sufficient and representative real-world data. Despite the strong practical and commercial interest in autonomous landing systems in the aerospace field, there is a lack of open-source datasets of aerial images. To address this issue, we present a dataset-lard-of high-quality aerial images for the task of runway detection during approach and landing phases. Most of the dataset is composed of synthetic images but we also provide manually labelled images from real landing footages, to extend the detection task to a more realistic setting. In addition, we offer the generator which can produce such synthetic front-view images and enables automatic annotation of the runway corners through geometric transformations. This dataset paves the way for further research such as the analysis of dataset quality or the development of models to cope with the detection tasks. Find data, code and more up-to-date information at this https URL

16 Apr 2024
We propose a post-hoc, computationally lightweight method to quantify predictive uncertainty in semantic image segmentation. Our approach uses conformal prediction to generate statistically valid prediction sets that are guaranteed to include the ground-truth segmentation mask at a predefined confidence level. We introduce a novel visualization technique of conformalized predictions based on heatmaps, and provide metrics to assess their empirical validity. We demonstrate the effectiveness of our approach on well-known benchmark datasets and image segmentation prediction models, and conclude with practical insights.

03 Nov 2023
In theory, the choice of ReLU(0) in [0, 1] for a neural network has a
negligible influence both on backpropagation and training. Yet, in the real
world, 32 bits default precision combined with the size of deep learning
problems makes it a hyperparameter of training methods. We investigate the
importance of the value of ReLU'(0) for several precision levels (16, 32, 64
bits), on various networks (fully connected, VGG, ResNet) and datasets (MNIST,
CIFAR10, SVHN, ImageNet). We observe considerable variations of backpropagation
outputs which occur around half of the time in 32 bits precision. The effect
disappears with double precision, while it is systematic at 16 bits. For
vanilla SGD training, the choice ReLU'(0) = 0 seems to be the most efficient.
For our experiments on ImageNet the gain in test accuracy over ReLU'(0) = 1 was
more than 10 points (two runs). We also evidence that reconditioning approaches
as batch-norm or ADAM tend to buffer the influence of ReLU'(0)'s value.
Overall, the message we convey is that algorithmic differentiation of nonsmooth
problems potentially hides parameters that could be tuned advantageously.

09 Oct 2025
With increasing processing power, deploying AI models for remote sensing directly onboard satellites is becoming feasible. However, new constraints arise, mainly when using raw, unprocessed sensor data instead of preprocessed ground-based products. While current solutions primarily rely on preprocessed sensor images, few approaches directly leverage raw data. This study investigates the effects of utilising raw data on deep learning models for object detection and classification tasks. We introduce a simulation workflow to generate raw-like products from high-resolution L1 imagery, enabling systemic evaluation. Two object detection models (YOLOv11n and YOLOX-S) are trained on both raw and L1 datasets, and their performance is compared using standard detection metrics and explainability tools. Results indicate that while both models perform similarly at low to medium confidence thresholds, the model trained on raw data struggles with object boundary identification at high confidence levels. It suggests that adapting AI architectures with improved contouring methods can enhance object detection on raw images, improving onboard AI for remote sensing.
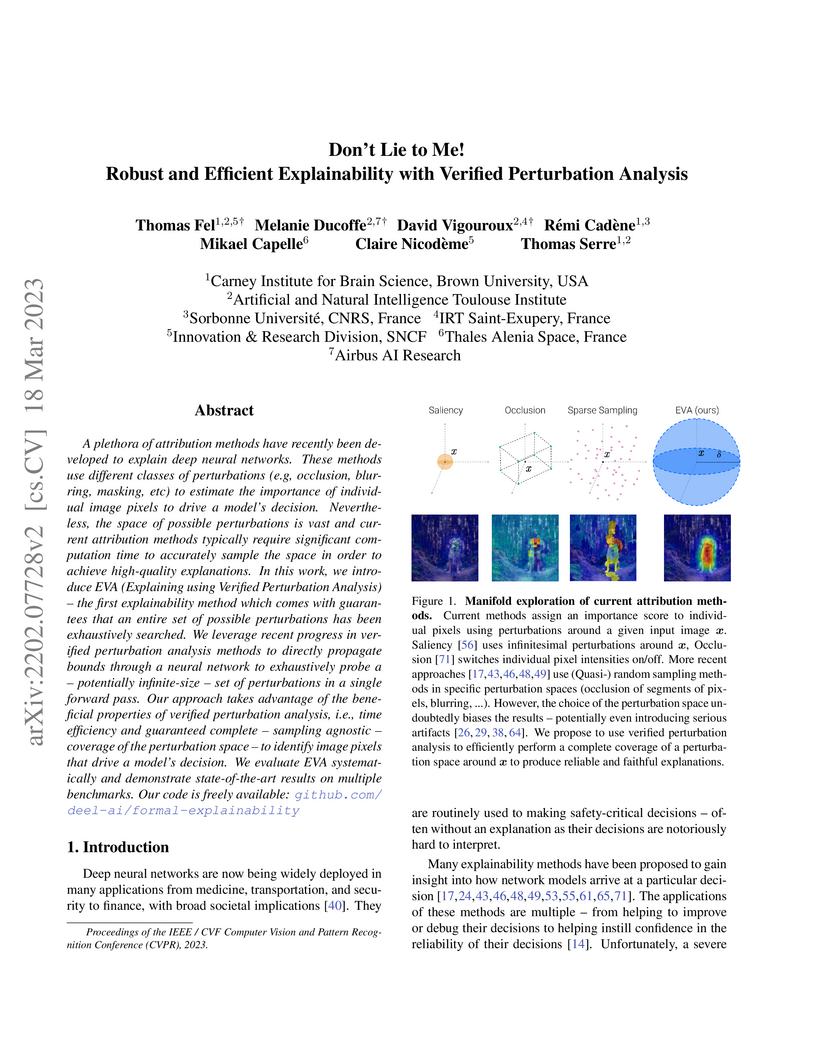
18 Mar 2023
A variety of methods have been proposed to try to explain how deep neural
networks make their decisions. Key to those approaches is the need to sample
the pixel space efficiently in order to derive importance maps. However, it has
been shown that the sampling methods used to date introduce biases and other
artifacts, leading to inaccurate estimates of the importance of individual
pixels and severely limit the reliability of current explainability methods.
Unfortunately, the alternative -- to exhaustively sample the image space is
computationally prohibitive. In this paper, we introduce EVA (Explaining using
Verified perturbation Analysis) -- the first explainability method guarantee to
have an exhaustive exploration of a perturbation space. Specifically, we
leverage the beneficial properties of verified perturbation analysis -- time
efficiency, tractability and guaranteed complete coverage of a manifold -- to
efficiently characterize the input variables that are most likely to drive the
model decision. We evaluate the approach systematically and demonstrate
state-of-the-art results on multiple benchmarks.

05 Sep 2023
Explainable Artificial Intelligence (XAI) has become increasingly significant
for improving the interpretability and trustworthiness of machine learning
models. While saliency maps have stolen the show for the last few years in the
XAI field, their ability to reflect models' internal processes has been
questioned. Although less in the spotlight, example-based XAI methods have
continued to improve. It encompasses methods that use examples as explanations
for a machine learning model's predictions. This aligns with the psychological
mechanisms of human reasoning and makes example-based explanations natural and
intuitive for users to understand. Indeed, humans learn and reason by forming
mental representations of concepts based on examples.
This paper provides an overview of the state-of-the-art in natural
example-based XAI, describing the pros and cons of each approach. A "natural"
example simply means that it is directly drawn from the training data without
involving any generative process. The exclusion of methods that require
generating examples is justified by the need for plausibility which is in some
regards required to gain a user's trust. Consequently, this paper will explore
the following family of methods: similar examples, counterfactual and
semi-factual, influential instances, prototypes, and concepts. In particular,
it will compare their semantic definition, their cognitive impact, and added
values. We hope it will encourage and facilitate future work on natural
example-based XAI.

25 Sep 2024
Researchers from RWTH Aachen, Université de Toulouse, CNRS, and IRT Saint Exupéry perform a complete second-order analysis of the loss landscape for deep linear neural networks, classifying all first-order critical points into global minimizers, strict saddle points, and non-strict saddle points based on a newly introduced "tightened" condition, and explicitly parameterizing these critical points.

07 Mar 2025
This study introduces a lightweight U-Net model optimized for real-time
semantic segmentation of aerial images, targeting the efficient utilization of
Commercial Off-The-Shelf (COTS) embedded computing platforms. We maintain the
accuracy of the U-Net on a real-world dataset while significantly reducing the
model's parameters and Multiply-Accumulate (MAC) operations by a factor of 16.
Our comprehensive analysis covers three hardware platforms (CPU, GPU, and FPGA)
and five different toolchains (TVM, FINN, Vitis AI, TensorFlow GPU, and cuDNN),
assessing each on metrics such as latency, power consumption, memory footprint,
energy efficiency, and FPGA resource usage. The results highlight the
trade-offs between these platforms and toolchains, with a particular focus on
the practical deployment challenges in real-world applications. Our findings
demonstrate that while the FPGA with Vitis AI emerges as the superior choice
due to its performance, energy efficiency, and maturity, it requires
specialized hardware knowledge, emphasizing the need for a balanced approach in
selecting embedded computing solutions for semantic segmentation tasks

01 Oct 2024
Real-life medical data is often multimodal and incomplete, fueling the growing need for advanced deep learning models capable of integrating them efficiently. The use of diverse modalities, including histopathology slides, MRI, and genetic data, offers unprecedented opportunities to improve prognosis prediction and to unveil new treatment pathways. Contrastive learning, widely used for deriving representations from paired data in multimodal tasks, assumes that different views contain the same task-relevant information and leverages only shared information. This assumption becomes restrictive when handling medical data since each modality also harbors specific knowledge relevant to downstream tasks. We introduce DRIM, a new multimodal method for capturing these shared and unique representations, despite data sparsity. More specifically, given a set of modalities, we aim to encode a representation for each one that can be divided into two components: one encapsulating patient-related information common across modalities and the other, encapsulating modality-specific details. This is achieved by increasing the shared information among different patient modalities while minimizing the overlap between shared and unique components within each modality. Our method outperforms state-of-the-art algorithms on glioma patients survival prediction tasks, while being robust to missing modalities. To promote reproducibility, the code is made publicly available at this https URL

23 Feb 2021
We study the problem of approximating the level set of an unknown function by sequentially querying its values. We introduce a family of algorithms called Bisect and Approximate through which we reduce the level set approximation problem to a local function approximation problem. We then show how this approach leads to rate-optimal sample complexity guarantees for H{ö}lder functions, and we investigate how such rates improve when additional smoothness or other structural assumptions hold true.

09 Jun 2023
Various methods have been proposed to detect objects while reducing the cost
of data annotation. For instance, weakly supervised object detection (WSOD)
methods rely only on image-level annotations during training. Unfortunately,
data annotation remains expensive since annotators must provide the categories
describing the content of each image and labeling is restricted to a fixed set
of categories. In this paper, we propose a method to locate and label objects
in an image by using a form of weaker supervision: image-caption pairs. By
leveraging recent advances in vision-language (VL) models and self-supervised
vision transformers (ViTs), our method is able to perform phrase grounding and
object detection in a weakly supervised manner. Our experiments demonstrate the
effectiveness of our approach by achieving a 47.51% recall@1 score in phrase
grounding on Flickr30k Entities and establishing a new state-of-the-art in
object detection by achieving 21.1 mAP 50 and 10.5 mAP 50:95 on MS COCO when
exclusively relying on image-caption pairs.

16 Sep 2025

Out-of-distribution (OOD) detection is crucial for ensuring the reliability of deep learning models in real-world applications. Existing methods typically focus on feature representations or output-space analysis, often assuming a distribution over these spaces or leveraging gradient norms with respect to model parameters. However, these approaches struggle to distinguish near-OOD samples and often require extensive hyper-parameter tuning, limiting their this http URL this work, we propose GRadient-aware Out-Of-Distribution detection (GROOD), a method that derives an OOD prototype from synthetic samples and computes class prototypes directly from In-distribution (ID) training data. By analyzing the gradients of a nearest-class-prototype loss function concerning an artificial OOD prototype, our approach achieves a clear separation between in-distribution and OOD samples. Experimental evaluations demonstrate that gradients computed from the OOD prototype enhance the distinction between ID and OOD data, surpassing established baselines in robustness, particularly on ImageNet-1k. These findings highlight the potential of gradient-based methods and prototype-driven approaches in advancing OOD detection within deep neural networks.

01 Apr 2024

We propose a new method, dubbed One Class Signed Distance Function (OCSDF), to perform One Class Classification (OCC) by provably learning the Signed Distance Function (SDF) to the boundary of the support of any distribution. The distance to the support can be interpreted as a normality score, and its approximation using 1-Lipschitz neural networks provides robustness bounds against adversarial attacks, an under-explored weakness of deep learning-based OCC algorithms. As a result, OCSDF comes with a new metric, certified AUROC, that can be computed at the same cost as any classical AUROC. We show that OCSDF is competitive against concurrent methods on tabular and image data while being way more robust to adversarial attacks, illustrating its theoretical properties. Finally, as exploratory research perspectives, we theoretically and empirically show how OCSDF connects OCC with image generation and implicit neural surface parametrization. Our code is available at this https URL

16 Oct 2024
Ensuring fairness in NLP models is crucial, as they often encode sensitive
attributes like gender and ethnicity, leading to biased outcomes. Current
concept erasure methods attempt to mitigate this by modifying final latent
representations to remove sensitive information without retraining the entire
model. However, these methods typically rely on linear classifiers, which leave
models vulnerable to non-linear adversaries capable of recovering sensitive
information.
We introduce Targeted Concept Erasure (TaCo), a novel approach that removes
sensitive information from final latent representations, ensuring fairness even
against non-linear classifiers. Our experiments show that TaCo outperforms
state-of-the-art methods, achieving greater reductions in the prediction
accuracy of sensitive attributes by non-linear classifier while preserving
overall task performance. Code is available on
this https URL
There are no more papers matching your filters at the moment.
