
02 Feb 2020
Graph Neural Networks (GNN) have been shown to work effectively for modeling graph structured data to solve tasks such as node classification, link prediction and graph classification. There has been some recent progress in defining the notion of pooling in graphs whereby the model tries to generate a graph level representation by downsampling and summarizing the information present in the nodes. Existing pooling methods either fail to effectively capture the graph substructure or do not easily scale to large graphs. In this work, we propose ASAP (Adaptive Structure Aware Pooling), a sparse and differentiable pooling method that addresses the limitations of previous graph pooling architectures. ASAP utilizes a novel self-attention network along with a modified GNN formulation to capture the importance of each node in a given graph. It also learns a sparse soft cluster assignment for nodes at each layer to effectively pool the subgraphs to form the pooled graph. Through extensive experiments on multiple datasets and theoretical analysis, we motivate our choice of the components used in ASAP. Our experimental results show that combining existing GNN architectures with ASAP leads to state-of-the-art results on multiple graph classification benchmarks. ASAP has an average improvement of 4%, compared to current sparse hierarchical state-of-the-art method.

26 May 2025


LangDAug presents a systematic approach to mitigate domain shift in medical image segmentation by employing Energy-Based Models and Langevin dynamics to generate intermediate samples that bridge different imaging domains. This method leads to improved generalization performance and more stable cross-domain segmentation on unseen target domains.
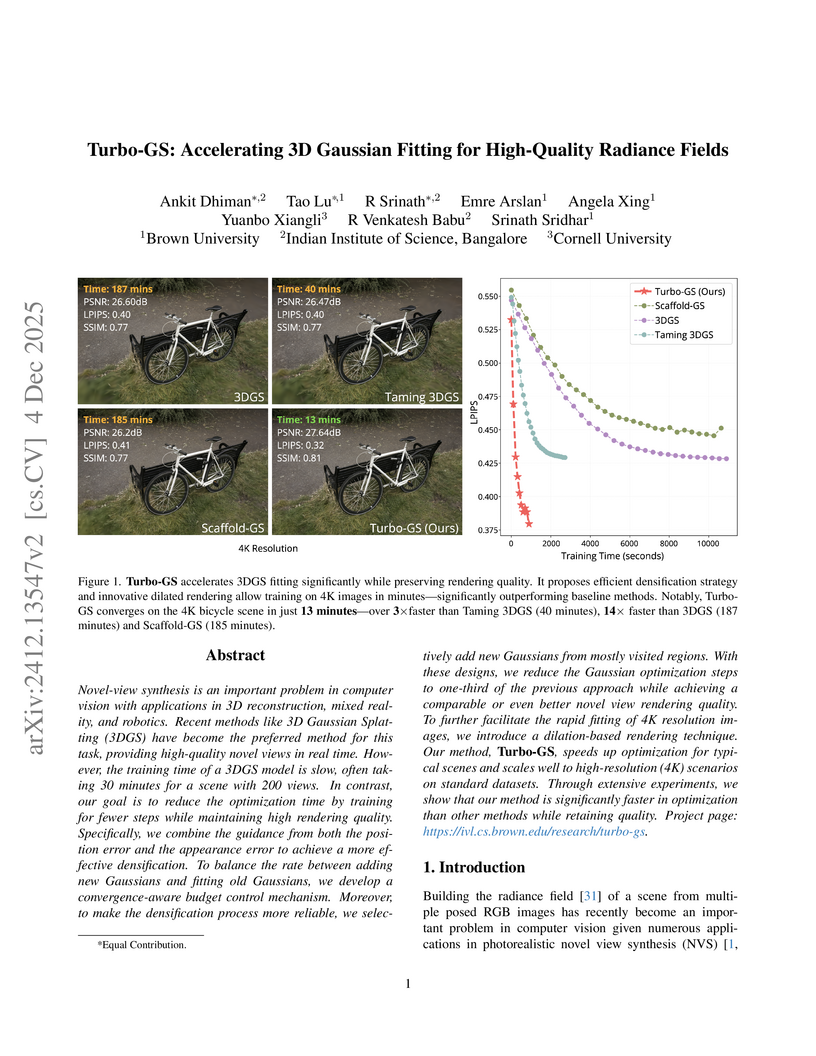
04 Dec 2025


Novel-view synthesis is an important problem in computer vision with applications in 3D reconstruction, mixed reality, and robotics. Recent methods like 3D Gaussian Splatting (3DGS) have become the preferred method for this task, providing high-quality novel views in real time. However, the training time of a 3DGS model is slow, often taking 30 minutes for a scene with 200 views. In contrast, our goal is to reduce the optimization time by training for fewer steps while maintaining high rendering quality. Specifically, we combine the guidance from both the position error and the appearance error to achieve a more effective densification. To balance the rate between adding new Gaussians and fitting old Gaussians, we develop a convergence-aware budget control mechanism. Moreover, to make the densification process more reliable, we selectively add new Gaussians from mostly visited regions. With these designs, we reduce the Gaussian optimization steps to one-third of the previous approach while achieving a comparable or even better novel view rendering quality. To further facilitate the rapid fitting of 4K resolution images, we introduce a dilation-based rendering technique. Our method, Turbo-GS, speeds up optimization for typical scenes and scales well to high-resolution (4K) scenarios on standard datasets. Through extensive experiments, we show that our method is significantly faster in optimization than other methods while retaining quality. Project page: this https URL.

29 Jun 2025
This paper introduces INDIC-BIAS, a comprehensive India-centric benchmark for evaluating fairness in Large Language Models (LLMs) across 85 diverse identity groups. The evaluation of 14 LLMs using INDIC-BIAS revealed they consistently reinforce societal biases and stereotypes against marginalized Indian identities in over 50% of cases.

20 Jan 2025
Researchers at IISc Bangalore introduce MERITS-L, a framework that employs large language models (LLMs) to generate pseudo-labels for unsupervised text pre-training, enhancing emotion recognition from conversational speech transcripts. The model integrates this LLM-guided text processing with robust speech features and a hierarchical fusion approach, leading to state-of-the-art performance on two major multimodal conversational emotion recognition benchmarks.

08 Oct 2025

Certain types of quantum computing platforms, such as those realized using Rydberg atoms or Kerr-cat qubits, are natively more susceptible to Pauli-Z noise than Pauli-X noise, or vice versa. On such hardware, it is useful to ensure that computations use only gates that maintain the Z-bias (or X-bias) in the noise. This is so that quantum error-correcting codes tailored for biased-noise models can be used to provide fault-tolerance on these platforms. In this paper, we follow up on the recent work of Fellous-Asiani et al. (npj Quantum Inf., 2025) in studying the structure and properties of bias-preserving gates. Our main contributions are threefold: (1) We give a novel characterization of Z-bias-preserving gates based on their decomposition as a linear combination of Pauli operators. (2) We show that any Z-bias-preserving gate can be approximated arbitrarily well using only gates from the set {X,R_z(\theta),CNOT,CCNOT}, where \theta is any irrational multiple of 2\pi. (3) We prove, by drawing a connection with coherence resource theory, that any Z-bias-preserving logical operator acting on the logical qubits of a Calderbank-Shor-Steane (CSS) code can be realized by applying Z-bias-preserving gates on the physical qubits. Along the way, we also demonstrate that Z-bias-preserving gates are far from being universal for quantum computation.

24 Mar 2025


Linear time-varying (LTV) systems model radar scenes where each
reflector/target applies a delay, Doppler shift and complex amplitude scaling
to a transmitted waveform. The receiver processes the received signal using the
transmitted signal as a reference. The self-ambiguity function of the
transmitted signal captures the cross-correlation of delay and Doppler shifts
of the transmitted waveform. It acts as a blur that limits resolution, at the
receiver, of the delay and Doppler shifts of targets in close proximity. This
paper considers resolution of multiple targets and compares performance of
traditional chirp waveforms with the Zak-OTFS waveform. The self-ambiguity
function of a chirp is a line in the delay-Doppler domain, whereas the
self-ambiguity function of the Zak-OTFS waveform is a lattice. The advantage of
lattices over lines is better localization, and we show lattices provide
superior noise-free estimation of the range and velocity of multiple targets.
When the delay spread of the radar scene is less than the delay period of the
Zak-OTFS modulation, and the Doppler spread is less than the Doppler period, we
describe how to localize targets by calculating cross-ambiguities in the
delay-Doppler domain. We show that the signal processing complexity of our
approach is superior to the traditional approach of computing cross-ambiguities
in the continuous time / frequency domain.

09 Feb 2020
Network representation learning and node classification in graphs got
significant attention due to the invent of different types graph neural
networks. Graph convolution network (GCN) is a popular semi-supervised
technique which aggregates attributes within the neighborhood of each node.
Conventional GCNs can be applied to simple graphs where each edge connects only
two nodes. But many modern days applications need to model high order
relationships in a graph. Hypergraphs are effective data types to handle such
complex relationships. In this paper, we propose a novel technique to apply
graph convolution on hypergraphs with variable hyperedge sizes. We use the
classical concept of line graph of a hypergraph for the first time in the
hypergraph learning literature. Then we propose to use graph convolution on the
line graph of a hypergraph. Experimental analysis on multiple real world
network datasets shows the merit of our approach compared to state-of-the-arts.

01 Jun 2025
Recent advances in large language models (LLMs) have significantly improved natural language generation, including creative tasks like poetry composition. However, most progress remains concentrated in high-resource languages. This raises an important question: Can LLMs be adapted for structured poetic generation in a low-resource, morphologically rich language such as Sanskrit? In this work, we introduce a dataset designed for translating English prose into structured Sanskrit verse, with strict adherence to classical metrical patterns, particularly the Anushtub meter. We evaluate a range of generative models-both open-source and proprietary-under multiple settings. Specifically, we explore constrained decoding strategies and instruction-based fine-tuning tailored to metrical and semantic fidelity. Our decoding approach achieves over 99% accuracy in producing syntactically valid poetic forms, substantially outperforming general-purpose models in meter conformity. Meanwhile, instruction-tuned variants show improved alignment with source meaning and poetic style, as supported by human assessments, albeit with marginal trade-offs in metrical precision.

10 Apr 2025

Diffusion Models (DMs) have emerged as powerful generative models with
unprecedented image generation capability. These models are widely used for
data augmentation and creative applications. However, DMs reflect the biases
present in the training datasets. This is especially concerning in the context
of faces, where the DM prefers one demographic subgroup vs others (eg. female
vs male). In this work, we present a method for debiasing DMs without relying
on additional data or model retraining. Specifically, we propose Distribution
Guidance, which enforces the generated images to follow the prescribed
attribute distribution. To realize this, we build on the key insight that the
latent features of denoising UNet hold rich demographic semantics, and the same
can be leveraged to guide debiased generation. We train Attribute Distribution
Predictor (ADP) - a small mlp that maps the latent features to the distribution
of attributes. ADP is trained with pseudo labels generated from existing
attribute classifiers. The proposed Distribution Guidance with ADP enables us
to do fair generation. Our method reduces bias across single/multiple
attributes and outperforms the baseline by a significant margin for
unconditional and text-conditional diffusion models. Further, we present a
downstream task of training a fair attribute classifier by rebalancing the
training set with our generated data.

30 Jan 2025


Battery health monitoring is critical for the efficient and reliable operation of electric vehicles (EVs). This study introduces a transformer-based framework for estimating the State of Health (SoH) and predicting the Remaining Useful Life (RUL) of lithium titanate (LTO) battery cells by utilizing both cycle-based and instantaneous discharge data. Testing on eight LTO cells under various cycling conditions over 500 cycles, we demonstrate the impact of charge durations on energy storage trends and apply Differential Voltage Analysis (DVA) to monitor capacity changes (dQ/dV) across voltage ranges. Our LLM model achieves superior performance, with a Mean Absolute Error (MAE) as low as 0.87\% and varied latency metrics that support efficient processing, demonstrating its strong potential for real-time integration into EVs. The framework effectively identifies early signs of degradation through anomaly detection in high-resolution data, facilitating predictive maintenance to prevent sudden battery failures and enhance energy efficiency.

24 Sep 2025
Optimizing the timing and frequency of ads is a central problem in digital advertising, with significant economic consequences. Existing scheduling policies rely on simple heuristics, such as uniform spacing and frequency caps, that overlook long-term user interest. However, it is well-known that users' long-term interest and engagement result from the interplay of several psychological effects (Curmei, Haupt, Recht, Hadfield-Menell, ACM CRS, 2022).
In this work, we model change in user interest upon showing ads based on three key psychological principles: mere exposure, hedonic adaptation, and operant conditioning. The first two effects are modeled using a concave function of user interest with repeated exposure, while the third effect is modeled using a temporal decay function, which explains the decline in user interest due to overexposure. Under our psychological behavior model, we ask the following question: Given a continuous time interval , how many ads should be shown, and at what times, to maximize the user interest towards the ads?
Towards answering this question, we first show that, if the number of displayed ads is fixed, then the optimal ad-schedule only depends on the operant conditioning function. Our main result is a quasi-linear time algorithm that outputs a near-optimal ad-schedule, i.e., the difference in the performance of our schedule and the optimal schedule is exponentially small. Our algorithm leads to significant insights about optimal ad placement and shows that simple heuristics such as uniform spacing are sub-optimal under many natural settings. The optimal number of ads to display, which also depends on the mere exposure and hedonistic adaptation functions, can be found through a simple linear search given the above algorithm. We further support our findings with experimental results, demonstrating that our strategy outperforms various baselines.

18 Apr 2024
Variational Physics-Informed Neural Networks (VPINNs) utilize a variational loss function to solve partial differential equations, mirroring Finite Element Analysis techniques. Traditional hp-VPINNs, while effective for high-frequency problems, are computationally intensive and scale poorly with increasing element counts, limiting their use in complex geometries. This work introduces FastVPINNs, a tensor-based advancement that significantly reduces computational overhead and improves scalability. Using optimized tensor operations, FastVPINNs achieve a 100-fold reduction in the median training time per epoch compared to traditional hp-VPINNs. With proper choice of hyperparameters, FastVPINNs surpass conventional PINNs in both speed and accuracy, especially in problems with high-frequency solutions. Demonstrated effectiveness in solving inverse problems on complex domains underscores FastVPINNs' potential for widespread application in scientific and engineering challenges, opening new avenues for practical implementations in scientific machine learning.

14 Jul 2025
In Zak-OTFS (orthogonal time frequency space) modulation the carrier waveform is a pulse in the delay-Doppler (DD) domain, formally a quasi-periodic localized function with specific periods along delay and Doppler. When the channel delay spread is less than the delay period, and the channel Doppler spread is less than the Doppler period, the response to a single Zak-OTFS carrier provides an image of the scattering environment and can be used to predict the effective channel at all other carriers. The image of the scattering environment changes slowly, making it possible to employ precoding at the transmitter. Precoding techniques were developed more than thirty years ago for wireline modem channels (V.34 standard) defined by linear convolution where a pulse in the time domain (TD) is used to probe the one-dimensional partial response channel. The action of a doubly spread channel on Zak-OTFS modulation determines a two-dimensional partial response channel defined by twisted convolution, and we develop a novel precoding technique for this channel. The proposed precoder leads to separate equalization of each DD carrier which has significantly lower complexity than joint equalization of all carriers. Further, the effective precoded channel results in non-interfering DD carriers which significantly reduces the overhead of guard carriers separating data and pilot carriers, which improves the spectral efficiency significantly.

10 Dec 2021

We address the problem of model selection for the finite horizon episodic Reinforcement Learning (RL) problem where the transition kernel belongs to a family of models with finite metric entropy. In the model selection framework, instead of , we are given nested families of transition kernels . We propose and analyze a novel algorithm, namely \emph{Adaptive Reinforcement Learning (General)} (\texttt{ARL-GEN}) that adapts to the smallest such family where the true transition kernel lies. \texttt{ARL-GEN} uses the Upper Confidence Reinforcement Learning (\texttt{UCRL}) algorithm with value targeted regression as a blackbox and puts a model selection module at the beginning of each epoch. Under a mild separability assumption on the model classes, we show that \texttt{ARL-GEN} obtains a regret of , with high probability, where is the horizon length, is the total number of steps, is the Eluder dimension and is the metric entropy corresponding to . Note that this regret scaling matches that of an oracle that knows in advance. We show that the cost of model selection for \texttt{ARL-GEN} is an additive term in the regret having a weak dependence on . Subsequently, we remove the separability assumption and consider the setup of linear mixture MDPs, where the transition kernel has a linear function approximation. With this low rank structure, we propose novel adaptive algorithms for model selection, and obtain (order-wise) regret identical to that of an oracle with knowledge of the true model class.

17 Jun 2016

Researchers at Harvard University and others developed new peer prediction mechanisms to elicit truthful information in multi-signal settings where ground truth is unavailable, a long-standing challenge in crowdsourcing. Their Correlated Agreement (CA) mechanism achieves 'informed truthfulness' for all signal distributions, meaning agents are strictly incentivized to exert effort and report truthfully. They also provided a practical 'detail-free' version that learns signal correlations from data, making it deployable in real-world systems like MOOC peer assessment, and empirically showed that common multi-signal data do not satisfy conditions for prior strong truthfulness guarantees.

09 Jun 2024
The need for abundant labelled data in supervised Adversarial Training (AT)
has prompted the use of Self-Supervised Learning (SSL) techniques with AT.
However, the direct application of existing SSL methods to adversarial training
has been sub-optimal due to the increased training complexity of combining SSL
with AT. A recent approach, DeACL, mitigates this by utilizing supervision from
a standard SSL teacher in a distillation setting, to mimic supervised AT.
However, we find that there is still a large performance gap when compared to
supervised adversarial training, specifically on larger models. In this work,
investigate the key reason for this gap and propose Projected Feature
Adversarial Training (ProFeAT) to bridge the same. We show that the sub-optimal
distillation performance is a result of mismatch in training objectives of the
teacher and student, and propose to use a projection head at the student, that
allows it to leverage weak supervision from the teacher while also being able
to learn adversarially robust representations that are distinct from the
teacher. We further propose appropriate attack and defense losses at the
feature and projector, alongside a combination of weak and strong augmentations
for the teacher and student respectively, to improve the training data
diversity without increasing the training complexity. Through extensive
experiments on several benchmark datasets and models, we demonstrate
significant improvements in both clean and robust accuracy when compared to
existing SSL-AT methods, setting a new state-of-the-art. We further report
on-par/ improved performance when compared to TRADES, a popular supervised-AT
method.

05 Aug 2025
Zak-Orthogonal Time Frequency Space (Zak-OTFS) modulation has been shown to achieve significantly better performance compared to the standardized Cyclic-Prefix Orthogonal Frequency Division Multiplexing (CP-OFDM), in high delay/Doppler spread scenarios envisaged in next generation communication systems. Zak-OTFS carriers are quasi-periodic pulses in the delay-Doppler (DD) domain, characterized by two parameters, (i) the pulse period along the delay axis (``delay period") (Doppler period is related to the delay period), and (ii) the pulse shaping filter. An important practical challenge is enabling support for Zak-OTFS modulation in existing CP-OFDM based modems. In this paper we show that Zak-OTFS modulation with pulse shaping constrained to sinc filtering (filter bandwidth equal to the communication bandwidth ) followed by time-windowing with a rectangular window of duration ( is the symbol duration and is the CP duration), can be implemented as a low-complexity precoder over standard CP-OFDM. We also show that the Zak-OTFS de-modulator with matched filtering constrained to sinc filtering (filter bandwidth ) followed by rectangular time windowing over duration can be implemented as a low-complexity post-processing of the CP-OFDM de-modulator output. This proposed ``Zak-OTFS over CP-OFDM" architecture enables us to harness the benefits of Zak-OTFS in existing network infrastructure. We also show that the proposed Zak-OTFS over CP-OFDM is a family of modulations, with CP-OFDM being a special case when the delay period takes its minimum possible value equal to the inverse bandwidth, i.e., Zak-OTFS over CP-OFDM with minimum delay period.

06 Sep 2025
Rotating the clamped ends of a buckled elastica induces a snap-through instability. Predicting the limit point and determining the equilibria at the start and end of the snap are routine computations in the quasi-static setting. The instability itself, however, is dynamic, and quite violently so. We propose an energy-preserving nonlinear single degree of freedom model for this dynamic phenomenon in the case of a symmetrically deforming elastica. The model hinges on a surprising observation relating elastica profiles during the free dynamic snap with a specific sequence of geometrically-constrained elastic energy minimizing configurations. We corroborate this phenomenological observation over a significant range of arch depths through experiments and finite element simulations. The resulting model does not rely on modal expansions, explicit slowness assumptions, or linearization of the arch's kinematics. Instead, the model is effective because its solutions approximate the action integral well. The model provides distinctive computational benefits and new insights into the snap-through phenomenon. Our study is motivated by an application harnessing snap-through instabilities in submerged ribbons for underwater propulsion. We briefly describe its novel working principle and discuss its relationship to the problem studied.

25 Nov 2023
Inspired by the human brain's structure and function, neuromorphic computing has emerged as a promising approach for developing energy-efficient and powerful computing systems. Neuromorphic computing offers significant processing speed and power consumption advantages in aerospace applications. These two factors are crucial for real-time data analysis and decision-making. However, the harsh space environment, particularly with the presence of radiation, poses significant challenges to the reliability and performance of these computing systems. This paper comprehensively surveys the integration of radiation-resistant neuromorphic computing systems in aerospace applications. We explore the challenges posed by space radiation, review existing solutions and developments, present case studies of neuromorphic computing systems used in space applications, discuss future directions, and discuss the potential benefits of this technology in future space missions.
There are no more papers matching your filters at the moment.
