
25 Jun 2024
A Generative Adversarial Network (GAN) transforms low-resolution, noisy Raman spectra from portable spectrometers into high-resolution, high signal-to-noise ratio (SNR) counterparts. This approach enables accurate molecular feature recognition, achieving over 88% classification accuracy and nearly 100% identification accuracy for pharmaceutical drugs and organic compounds with enhanced spectral quality.

11 Jun 2014

This paper introduces Generative Adversarial Networks (GANs), a novel framework for training generative models through an adversarial process between a generator and discriminator
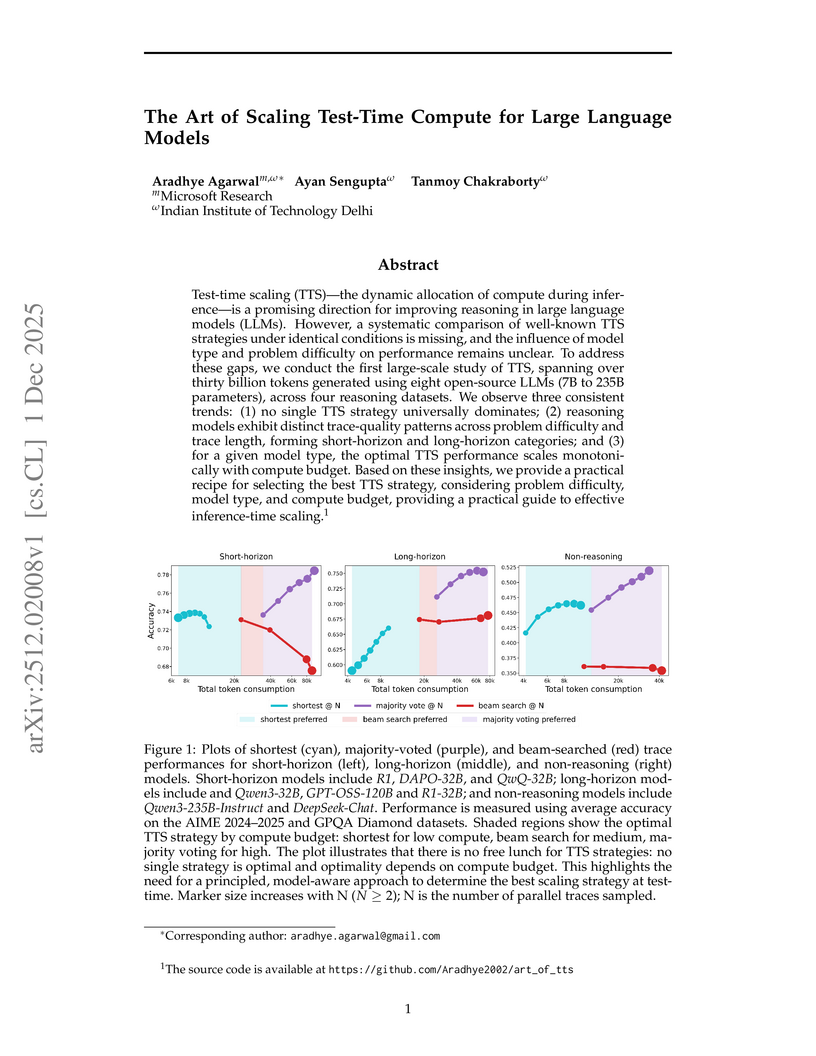
01 Dec 2025

This study systematically investigates test-time compute scaling strategies for Large Language Models across diverse architectures and reasoning tasks. The research identifies distinct "reasoning horizons" in models, challenging the notion that more compute always improves performance and providing a practical guide for optimal strategy selection.

18 Sep 2025
Researchers at IIT Delhi developed CurDKV, a value-centric KV cache compression method utilizing approximated CUR decomposition and leverage scores, to improve the efficiency of Large Language Models. This approach consistently yields higher accuracy under aggressive compression ratios and reduces LLM generation latency by up to 40%.

08 Jun 2025
Equivalence checking of SQL queries is an intractable problem often
encountered in settings ranging from grading SQL submissions to debugging query
optimizers. Despite recent work toward developing practical solutions, only
simple queries written using a small subset of SQL are supported, leaving the
equivalence checking of sophisticated SQL queries at the mercy of intensive,
potentially error-prone, manual analysis. In this paper, we explore how LLMs
can be used to reason with SQL queries to address this challenging problem.
Towards this, we introduce a novel, realistic, and sufficiently complex
benchmark called SQLEquiQuest for SQL query equivalence checking that reflects
real-world settings. We establish strong baselines for SQL equivalence checking
by leveraging the ability of LLMs to reason with SQL queries. We conduct a
detailed evaluation of several state-of-the-art LLMs using various prompting
strategies and carefully constructed in-context learning examples, including
logical plans generated by SQL query processors. Our empirical evaluation shows
that LLMs go well beyond the current capabilities of formal models for SQL
equivalence, going from a mere 30% supported query pairs to full coverage,
achieving up to 82% accuracy on Spider+DIN. However, a critical limitation of
LLMs revealed by our analysis is that they exhibit a strong bias for
equivalence predictions, with consistently poor performance over non-equivalent
pairs, opening a new direction for potential future research.

06 Oct 2025






Camellia introduces a new benchmark to quantify entity-centric cultural biases in Large Language Models across nine Asian languages and six distinct Asian cultures. The evaluation reveals that current LLMs exhibit a 30-40% preference for Western entities in culturally-grounded contexts, demonstrate varied sentiment associations, and show significant performance disparities (12-20% accuracy gaps) in extracting Asian-associated entities.

28 Jan 2025
Materials discovery and development are critical for addressing global challenges. Yet, the exponential growth in materials science literature comprising vast amounts of textual data has created significant bottlenecks in knowledge extraction, synthesis, and scientific reasoning. Large Language Models (LLMs) offer unprecedented opportunities to accelerate materials research through automated analysis and prediction. Still, their effective deployment requires domain-specific adaptation for understanding and solving domain-relevant tasks. Here, we present LLaMat, a family of foundational models for materials science developed through continued pretraining of LLaMA models on an extensive corpus of materials literature and crystallographic data. Through systematic evaluation, we demonstrate that LLaMat excels in materials-specific NLP and structured information extraction while maintaining general linguistic capabilities. The specialized LLaMat-CIF variant demonstrates unprecedented capabilities in crystal structure generation, predicting stable crystals with high coverage across the periodic table. Intriguingly, despite LLaMA-3's superior performance in comparison to LLaMA-2, we observe that LLaMat-2 demonstrates unexpectedly enhanced domain-specific performance across diverse materials science tasks, including structured information extraction from text and tables, more particularly in crystal structure generation, a potential adaptation rigidity in overtrained LLMs. Altogether, the present work demonstrates the effectiveness of domain adaptation towards developing practically deployable LLM copilots for materials research. Beyond materials science, our findings reveal important considerations for domain adaptation of LLMs, such as model selection, training methodology, and domain-specific performance, which may influence the development of specialized scientific AI systems.

25 Sep 2024
Researchers from Intel Labs and IIT Delhi analyze the current capabilities of Large Language Models (LLMs) in materials science, identifying specific limitations in domain knowledge and multi-modal information extraction. The work outlines critical requirements for specialized Materials Science LLMs (MatSci-LLMs) and proposes a six-step roadmap for accelerating real-world materials discovery.

23 Sep 2025
Semantic parsing methods for converting text to SQL queries enable question answering over structured data and can greatly benefit analysts who routinely perform complex analytics on vast data stored in specialized relational databases. Although several benchmarks measure the abilities of text to SQL, the complexity of their questions is inherently limited by the level of expressiveness in query languages and none focus explicitly on questions involving complex analytical reasoning which require operations such as calculations over aggregate analytics, time series analysis or scenario understanding. In this paper, we introduce STARQA, the first public human-created dataset of complex analytical reasoning questions and answers on three specialized-domain databases. In addition to generating SQL directly using LLMs, we evaluate a novel approach (Text2SQLCode) that decomposes the task into a combination of SQL and Python: SQL is responsible for data fetching, and Python more naturally performs reasoning. Our results demonstrate that identifying and combining the abilities of SQL and Python is beneficial compared to using SQL alone, yet the dataset still remains quite challenging for the existing state-of-the-art LLMs.
27 May 2025

Neural scaling laws have revolutionized the design and optimization of
large-scale AI models by revealing predictable relationships between model
size, dataset volume, and computational resources. Early research established
power-law relationships in model performance, leading to compute-optimal
scaling strategies. However, recent studies highlighted their limitations
across architectures, modalities, and deployment contexts. Sparse models,
mixture-of-experts, retrieval-augmented learning, and multimodal models often
deviate from traditional scaling patterns. Moreover, scaling behaviors vary
across domains such as vision, reinforcement learning, and fine-tuning,
underscoring the need for more nuanced approaches. In this survey, we
synthesize insights from over 50 studies, examining the theoretical
foundations, empirical findings, and practical implications of scaling laws. We
also explore key challenges, including data efficiency, inference scaling, and
architecture-specific constraints, advocating for adaptive scaling strategies
tailored to real-world applications. We suggest that while scaling laws provide
a useful guide, they do not always generalize across all architectures and
training strategies.

28 Feb 2025

Recent advancements in artificial intelligence have sparked interest in
scientific assistants that could support researchers across the full spectrum
of scientific workflows, from literature review to experimental design and data
analysis. A key capability for such systems is the ability to process and
reason about scientific information in both visual and textual forms - from
interpreting spectroscopic data to understanding laboratory setups. Here, we
introduce MaCBench, a comprehensive benchmark for evaluating how
vision-language models handle real-world chemistry and materials science tasks
across three core aspects: data extraction, experimental understanding, and
results interpretation. Through a systematic evaluation of leading models, we
find that while these systems show promising capabilities in basic perception
tasks - achieving near-perfect performance in equipment identification and
standardized data extraction - they exhibit fundamental limitations in spatial
reasoning, cross-modal information synthesis, and multi-step logical inference.
Our insights have important implications beyond chemistry and materials
science, suggesting that developing reliable multimodal AI scientific
assistants may require advances in curating suitable training data and
approaches to training those models.

31 May 2025
Speech translation for Indian languages remains a challenging task due to the scarcity of large-scale, publicly available datasets that capture the linguistic diversity and domain coverage essential for real-world applications. Existing datasets cover a fraction of Indian languages and lack the breadth needed to train robust models that generalize beyond curated benchmarks. To bridge this gap, we introduce BhasaAnuvaad, the largest speech translation dataset for Indian languages, spanning over 44 thousand hours of audio and 17 million aligned text segments across 14 Indian languages and English. Our dataset is built through a threefold methodology: (a) aggregating high-quality existing sources, (b) large-scale web crawling to ensure linguistic and domain diversity, and (c) creating synthetic data to model real-world speech disfluencies. Leveraging BhasaAnuvaad, we train IndicSeamless, a state-of-the-art speech translation model for Indian languages that performs better than existing models. Our experiments demonstrate improvements in the translation quality, setting a new standard for Indian language speech translation. We will release all the code, data and model weights in the open-source, with permissive licenses to promote accessibility and collaboration.

09 Oct 2025

PANORAMA accelerates Approximate Nearest-Neighbor Search by tackling the increasingly dominant refinement bottleneck using a learned orthogonal transform and an accretive bounding framework. It achieves substantial speedups ranging from 2x to 40x across various state-of-the-art ANNS indexes, including IVFFlat and IVFPQ, while maintaining 100% recall.

16 Oct 2025
Tracking devices, while designed to help users find their belongings in case of loss/theft, bring in new questions about privacy and surveillance of not just their own users, but in the case of crowd-sourced location tracking, even that of others even orthogonally associated with these platforms. Apple's Find My is perhaps the most ubiquitous such system which can even locate devices which do not possess any cellular support or GPS, running on millions of devices worldwide. Apple claims that this system is private and secure, but the code is proprietary, and such claims have to be taken on faith. It is well known that even with perfect cryptographic guarantees, logical flaws might creep into protocols, and allow undesirable attacks. In this paper, we present a symbolic model of the Find My protocol, as well as a precise formal specification of desirable properties, and provide automated, machine-checkable proofs of these properties in the Tamarin prover.

19 Sep 2025
Researchers at the Indian Institute of Technology Delhi introduced SABER, a white-box jailbreak method that bypasses safety alignment in Large Language Models by introducing a strategically scaled cross-layer residual connection during the forward pass. This architectural intervention achieves substantially higher attack success rates on prominent benchmarks compared to existing methods, while revealing that safety mechanisms are localized within middle-to-late model layers.
25 May 2025
We challenge the dominant focus on neural scaling laws and advocate for a
paradigm shift toward downscaling in the development of large language models
(LLMs). While scaling laws have provided critical insights into performance
improvements through increasing model and dataset size, we emphasize the
significant limitations of this approach, particularly in terms of
computational inefficiency, environmental impact, and deployment constraints.
To address these challenges, we propose a holistic framework for downscaling
LLMs that seeks to maintain performance while drastically reducing resource
demands. This paper outlines practical strategies for transitioning away from
traditional scaling paradigms, advocating for a more sustainable, efficient,
and accessible approach to LLM development.

12 Sep 2025
In several capillary dynamics experiments, the liquid domain is confined by pinning the three-phase contact line along a sharp edge or a discontinuity on the substrate. Simulating the dynamics of pinned droplets can offer valuable insights into capillary flow phenomena involving wetting of inhomogeneous substrates. However, Eulerian multi-phase flow solvers are usually not able to directly implement pinning of three-phase contact lines. We present the implementation of a model for pinning the contact line of a liquid along an arbitrary pinning curve on the substrate, in an updated Lagrangian, meshless flow solver based on the smoothed particle hydrodynamics (SPH) method. We develop the pinning model for a continuum surface force scheme and assume a free surface for the liquid-gas interface. We validate the model against several capillary dynamics experiments involving pinned three phase contact lines with fixed and dynamic substrates to demonstrate the robustness and accuracy of the solver.

18 Aug 2025
Mental health disorders are rising worldwide. However, the availability of trained clinicians has not scaled proportionally, leaving many people without adequate or timely support. To bridge this gap, recent studies have shown the promise of Artificial Intelligence (AI) to assist mental health diagnosis, monitoring, and intervention. However, the development of efficient, reliable, and ethical AI to assist clinicians is heavily dependent on high-quality clinical training datasets. Despite growing interest in data curation for training clinical AI assistants, existing datasets largely remain scattered, under-documented, and often inaccessible, hindering the reproducibility, comparability, and generalizability of AI models developed for clinical mental health care. In this paper, we present the first comprehensive survey of clinical mental health datasets relevant to the training and development of AI-powered clinical assistants. We categorize these datasets by mental disorders (e.g., depression, schizophrenia), data modalities (e.g., text, speech, physiological signals), task types (e.g., diagnosis prediction, symptom severity estimation, intervention generation), accessibility (public, restricted or private), and sociocultural context (e.g., language and cultural background). Along with these, we also investigate synthetic clinical mental health datasets. Our survey identifies critical gaps such as a lack of longitudinal data, limited cultural and linguistic representation, inconsistent collection and annotation standards, and a lack of modalities in synthetic data. We conclude by outlining key challenges in curating and standardizing future datasets and provide actionable recommendations to facilitate the development of more robust, generalizable, and equitable mental health AI systems.

23 Jun 2025
Fine-tuning large language models (LLMs) on downstream tasks requires substantial computational resources. Selective PEFT, a class of parameter-efficient fine-tuning (PEFT) methodologies, aims to mitigate these computational challenges by selectively fine-tuning only a small fraction of the model parameters. Although parameter-efficient, these techniques often fail to match the performance of fully fine-tuned models, primarily due to inherent biases introduced during parameter selection. Traditional selective PEFT techniques use a fixed set of parameters selected using different importance heuristics, failing to capture parameter importance dynamically and often leading to suboptimal performance. We introduce , a novel selective PEFT method that calculates parameter importance continually, and dynamically unmasks parameters by balancing exploration and exploitation in parameter selection. Our empirical study on 16 tasks spanning natural language understanding, mathematical reasoning and summarization demonstrates the effectiveness of our method compared to fixed-masking selective PEFT techniques. We analytically show that reduces the number of gradient updates by a factor of two, enhancing computational efficiency. Since is robust to random initialization of neurons and operates directly on the optimization process, it is highly flexible and can be integrated with existing additive and reparametrization-based PEFT techniques such as adapters and LoRA respectively.

28 Feb 2025
The ever-increasing size of large language models (LLMs) presents significant
challenges for deployment due to their heavy computational and memory
requirements. Current model pruning techniques attempt to alleviate these
issues by relying heavily on external calibration datasets to determine which
parameters to prune or compress, thus limiting their flexibility and
scalability across different compression ratios. Moreover, these methods often
cause severe performance degradation, particularly in downstream tasks, when
subjected to higher compression rates. In this paper, we propose PruneNet, a
novel model compression method that addresses these limitations by
reformulating model pruning as a policy learning process. PruneNet decouples
the pruning process from the model architecture, eliminating the need for
calibration datasets. It learns a stochastic pruning policy to assess parameter
importance solely based on intrinsic model properties while preserving the
spectral structure to minimize information loss. PruneNet can compress the
LLaMA-2-7B model in just 15 minutes, achieving over 80% retention of its
zero-shot performance with a 30% compression ratio, outperforming existing
methods that retain only 75% performance. Furthermore, on complex multitask
language understanding tasks, PruneNet demonstrates its robustness by
preserving up to 80% performance of the original model, proving itself a
superior alternative to conventional structured compression techniques.
There are no more papers matching your filters at the moment.
