
21 Dec 2023

BloombergGPT is a 50 billion-parameter language model developed by Bloomberg, trained on a unique blend of financial and general datasets. It achieves state-of-the-art performance across a range of financial NLP tasks while maintaining strong performance on general language benchmarks.

07 Nov 2024
The M3DOCRAG framework introduces a multi-modal retrieval-augmented generation approach for document understanding, enabling reasoning across multiple pages and documents while preserving visual context. The system improves upon text-based RAG on open-domain DocVQA and achieves state-of-the-art performance on closed-domain benchmarks like MP-DocVQA.

01 Jun 2021

Researchers from NUS, 6Estates, Sichuan University, and Bloomberg introduced TAT-QA, the first large-scale question answering benchmark for numerical reasoning over tightly integrated tabular and textual content from financial reports. This dataset requires models to synthesize information across modalities for complex calculations and scale predictions, demonstrating a significant F1 score gap of over 30% between human performance and the best machine model.

10 Jul 2025


Bloomberg researchers present a systematization of knowledge for red-teaming Large Language Models, introducing a comprehensive threat model and a novel taxonomy that categorizes attacks based on an adversary's level of access to the LLM system. This work provides a structured framework for identifying vulnerabilities and guiding defense efforts across the LLM development lifecycle.

03 Oct 2025
The emergence of reinforcement learning in post-training of large language models has sparked significant interest in reward models. Reward models assess the quality of sampled model outputs to generate training signals. This task is also performed by evaluation metrics that monitor the performance of an AI model. We find that the two research areas are mostly separate, leading to redundant terminology and repeated pitfalls. Common challenges include susceptibility to spurious correlations, impact on downstream reward hacking, methods to improve data quality, and approaches to meta-evaluation. Our position paper argues that a closer collaboration between the fields can help overcome these issues. To that end, we show how metrics outperform reward models on specific tasks and provide an extensive survey of the two areas. Grounded in this survey, we point to multiple research topics in which closer alignment can improve reward models and metrics in areas such as preference elicitation methods, avoidance of spurious correlations and reward hacking, and calibration-aware meta-evaluation.

15 Sep 2025
LLM-as-a-Judge: Rapid Evaluation of Legal Document Recommendation for Retrieval-Augmented Generation
LLM-as-a-Judge: Rapid Evaluation of Legal Document Recommendation for Retrieval-Augmented Generation
The evaluation bottleneck in recommendation systems has become particularly acute with the rise of Generative AI, where traditional metrics fall short of capturing nuanced quality dimensions that matter in specialized domains like legal research. Can we trust Large Language Models to serve as reliable judges of their own kind? This paper investigates LLM-as-a-Judge as a principled approach to evaluating Retrieval-Augmented Generation systems in legal contexts, where the stakes of recommendation quality are exceptionally high.
We tackle two fundamental questions that determine practical viability: which inter-rater reliability metrics best capture the alignment between LLM and human assessments, and how do we conduct statistically sound comparisons between competing systems? Through systematic experimentation, we discover that traditional agreement metrics like Krippendorff's alpha can be misleading in the skewed distributions typical of AI system evaluations. Instead, Gwet's AC2 and rank correlation coefficients emerge as more robust indicators for judge selection, while the Wilcoxon Signed-Rank Test with Benjamini-Hochberg corrections provides the statistical rigor needed for reliable system comparisons.
Our findings suggest a path toward scalable, cost-effective evaluation that maintains the precision demanded by legal applications, transforming what was once a human-intensive bottleneck into an automated, yet statistically principled, evaluation framework.

21 May 2025

Fine-tuning pre-trained language models has become the prevalent paradigm for
building downstream NLP models. Oftentimes fine-tuned models are readily
available but their training data is not, due to data privacy or intellectual
property concerns. This creates a barrier to fusing knowledge across individual
models to yield a better single model. In this paper, we study the problem of
merging individual models built on different training data sets to obtain a
single model that performs well both across all data set domains and can
generalize on out-of-domain data. We propose a dataless knowledge fusion method
that merges models in their parameter space, guided by weights that minimize
prediction differences between the merged model and the individual models. Over
a battery of evaluation settings, we show that the proposed method
significantly outperforms baselines such as Fisher-weighted averaging or model
ensembling. Further, we find that our method is a promising alternative to
multi-task learning that can preserve or sometimes improve over the individual
models without access to the training data. Finally, model merging is more
efficient than training a multi-task model, thus making it applicable to a
wider set of scenarios.

13 Jun 2025
Researchers from Bloomberg and WeNet adapted OpenAI's Whisper into a causal, efficient streaming ASR system using a Unified Two-pass (U2) architecture and a hybrid tokenizer. This approach enables real-time performance on CPUs while maintaining high accuracy, outperforming pseudo-streaming methods in efficiency and latency control.
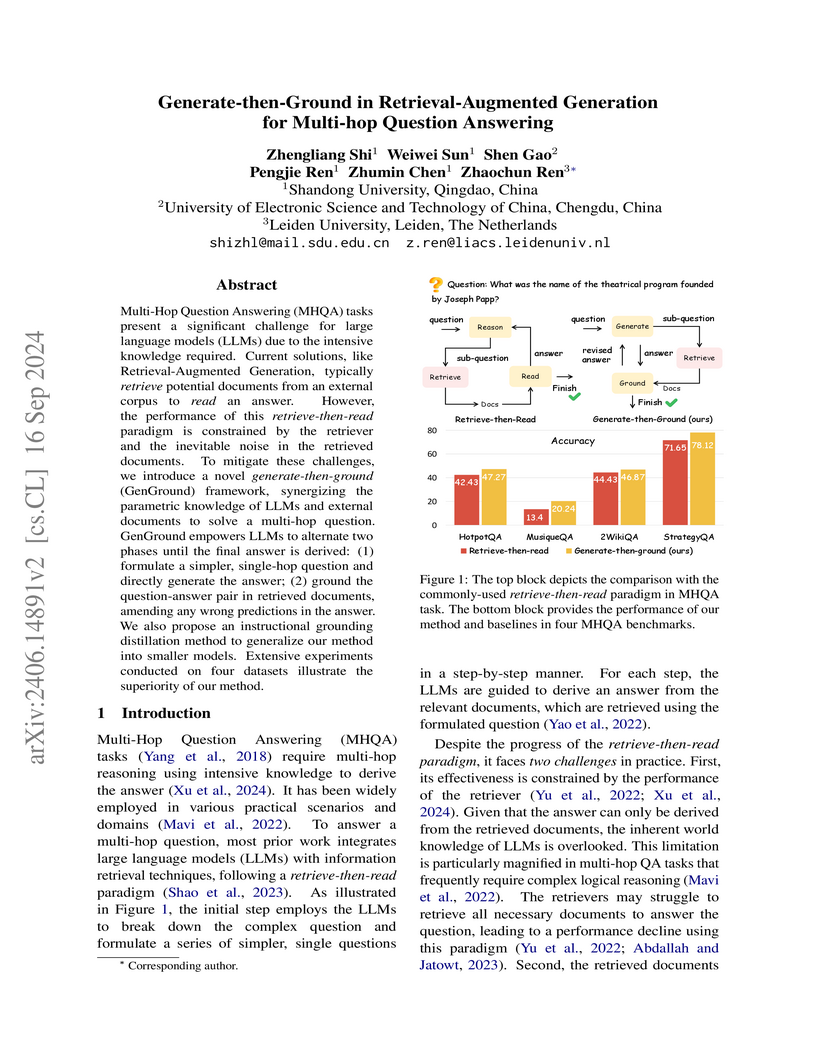
16 Sep 2024



Multi-Hop Question Answering (MHQA) tasks present a significant challenge for large language models (LLMs) due to the intensive knowledge required. Current solutions, like Retrieval-Augmented Generation, typically retrieve potential documents from an external corpus to read an answer. However, the performance of this retrieve-then-read paradigm is constrained by the retriever and the inevitable noise in the retrieved documents. To mitigate these challenges, we introduce a novel generate-then-ground (GenGround) framework, synergizing the parametric knowledge of LLMs and external documents to solve a multi-hop question. GenGround empowers LLMs to alternate two phases until the final answer is derived: (1) formulate a simpler, single-hop question and directly generate the answer; (2) ground the question-answer pair in retrieved documents, amending any wrong predictions in the answer. We also propose an instructional grounding distillation method to generalize our method into smaller models. Extensive experiments conducted on four datasets illustrate the superiority of our method.

23 Sep 2025
Semantic parsing methods for converting text to SQL queries enable question answering over structured data and can greatly benefit analysts who routinely perform complex analytics on vast data stored in specialized relational databases. Although several benchmarks measure the abilities of text to SQL, the complexity of their questions is inherently limited by the level of expressiveness in query languages and none focus explicitly on questions involving complex analytical reasoning which require operations such as calculations over aggregate analytics, time series analysis or scenario understanding. In this paper, we introduce STARQA, the first public human-created dataset of complex analytical reasoning questions and answers on three specialized-domain databases. In addition to generating SQL directly using LLMs, we evaluate a novel approach (Text2SQLCode) that decomposes the task into a combination of SQL and Python: SQL is responsible for data fetching, and Python more naturally performs reasoning. Our results demonstrate that identifying and combining the abilities of SQL and Python is beneficial compared to using SQL alone, yet the dataset still remains quite challenging for the existing state-of-the-art LLMs.

19 Sep 2025
OHLC bar data is a widely used format for representing financial asset prices over time due to its balance of simplicity and informativeness. Bloomberg has recently introduced a new bar data product that includes additional timing information-specifically, the timestamps of the open, high, low, and close prices within each bar. In this paper, we investigate the impact of incorporating this timing data into machine learning models for predicting volume-weighted average price (VWAP). Our experiments show that including these features consistently improves predictive performance across multiple ML architectures. We observe gains across several key metrics, including log-likelihood, mean squared error (MSE), , conditional variance estimation, and directional accuracy.
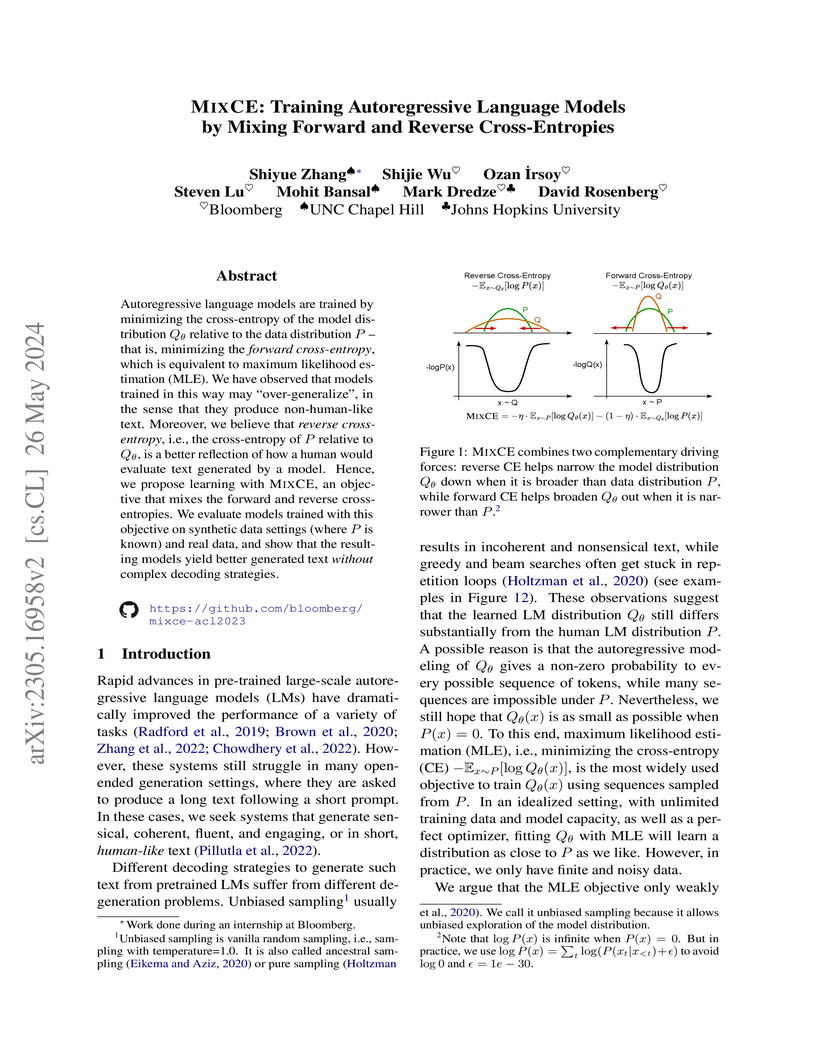
26 May 2024
Researchers at Bloomberg and UNC Chapel Hill developed MIXCE, a new training objective for autoregressive language models that mixes forward and reverse cross-entropies. This method leads to models that produce higher quality, more human-like text with simpler decoding strategies, as evidenced by improved automatic metrics and strong human evaluation scores on GPT-2 finetuning.

03 Jun 2025



Recent advancements in diffusion models have been leveraged to address inverse problems without additional training, and Diffusion Posterior Sampling (DPS) (Chung et al., 2022a) is among the most popular approaches. Previous analyses suggest that DPS accomplishes posterior sampling by approximating the conditional score. While in this paper, we demonstrate that the conditional score approximation employed by DPS is not as effective as previously assumed, but rather aligns more closely with the principle of maximizing a posterior (MAP). This assertion is substantiated through an examination of DPS on 512x512 ImageNet images, revealing that: 1) DPS's conditional score estimation significantly diverges from the score of a well-trained conditional diffusion model and is even inferior to the unconditional score; 2) The mean of DPS's conditional score estimation deviates significantly from zero, rendering it an invalid score estimation; 3) DPS generates high-quality samples with significantly lower diversity. In light of the above findings, we posit that DPS more closely resembles MAP than a conditional score estimator, and accordingly propose the following enhancements to DPS: 1) we explicitly maximize the posterior through multi-step gradient ascent and projection; 2) we utilize a light-weighted conditional score estimator trained with only 100 images and 8 GPU hours. Extensive experimental results indicate that these proposed improvements significantly enhance DPS's performance. The source code for these improvements is provided in this https URL.

21 Jul 2023
 Carnegie Mellon University
Carnegie Mellon University GoogleJapan Advanced Institute of Science and Technology
GoogleJapan Advanced Institute of Science and Technology Emory University
Emory University Mohamed bin Zayed University of Artificial Intelligence
Mohamed bin Zayed University of Artificial Intelligence HKUSTKorea Advanced Institute of Science and TechnologyUniversity of TsukubaNara Institute of Science and TechnologyUniversitas IndonesiaTelkom UniversityInstitut Teknologi BandungKumamoto UniversityBloombergBina Nusantara UniversityProsa.aiKanda University of International StudiesTanjungpura UniversityJULOAI-Research.idBahasa.aiUniversitas Al Azhar IndonesiaSurface DataState University of Medan
HKUSTKorea Advanced Institute of Science and TechnologyUniversity of TsukubaNara Institute of Science and TechnologyUniversitas IndonesiaTelkom UniversityInstitut Teknologi BandungKumamoto UniversityBloombergBina Nusantara UniversityProsa.aiKanda University of International StudiesTanjungpura UniversityJULOAI-Research.idBahasa.aiUniversitas Al Azhar IndonesiaSurface DataState University of Medan
We present NusaCrowd, a collaborative initiative to collect and unify existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have brought together 137 datasets and 118 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their value is demonstrated through multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and the local languages of Indonesia. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and the local languages of Indonesia. Our work strives to advance natural language processing (NLP) research for languages that are under-represented despite being widely spoken.

16 Sep 2024

Bilevel optimization methods are increasingly relevant within machine learning, especially for tasks such as hyperparameter optimization and meta-learning. Compared to the offline setting, online bilevel optimization (OBO) offers a more dynamic framework by accommodating time-varying functions and sequentially arriving data. This study addresses the online nonconvex-strongly convex bilevel optimization problem. In deterministic settings, we introduce a novel online Bregman bilevel optimizer (OBBO) that utilizes adaptive Bregman divergences. We demonstrate that OBBO enhances the known sublinear rates for bilevel local regret through a novel hypergradient error decomposition that adapts to the underlying geometry of the problem. In stochastic contexts, we introduce the first stochastic online bilevel optimizer (SOBBO), which employs a window averaging method for updating outer-level variables using a weighted average of recent stochastic approximations of hypergradients. This approach not only achieves sublinear rates of bilevel local regret but also serves as an effective variance reduction strategy, obviating the need for additional stochastic gradient samples at each timestep. Experiments on online hyperparameter optimization and online meta-learning highlight the superior performance, efficiency, and adaptability of our Bregman-based algorithms compared to established online and offline bilevel benchmarks.

01 Mar 2022
Covariate shifts are a common problem in predictive modeling on real-world problems. This paper proposes addressing the covariate shift problem by minimizing Maximum Mean Discrepancy (MMD) statistics between the training and test sets in either feature input space, feature representation space, or both. We designed three techniques that we call MMD Representation, MMD Mask, and MMD Hybrid to deal with the scenarios where only a distribution shift exists, only a missingness shift exists, or both types of shift exist, respectively. We find that integrating an MMD loss component helps models use the best features for generalization and avoid dangerous extrapolation as much as possible for each test sample. Models treated with this MMD approach show better performance, calibration, and extrapolation on the test set.

20 Mar 2025

Structural extraction of events within discourse is critical since it avails
a deeper understanding of communication patterns and behavior trends. Event
argument extraction (EAE), at the core of event-centric understanding, is the
task of identifying role-specific text spans (i.e., arguments) for a given
event. Document-level EAE (DocEAE) focuses on arguments that are scattered
across an entire document. In this work, we explore open-source Large Language
Models (LLMs) for DocEAE, and propose ULTRA, a hierarchical framework that
extracts event arguments more cost-effectively. Further, it alleviates the
positional bias issue intrinsic to LLMs. ULTRA sequentially reads text chunks
of a document to generate a candidate argument set, upon which non-pertinent
candidates are dropped through self-refinement. We introduce LEAFER to address
the challenge LLMs face in locating the exact boundary of an argument. ULTRA
outperforms strong baselines, including strong supervised models and ChatGPT,
by 9.8% when evaluated by Exact Match (EM).

18 Sep 2023

Evaluating open-domain dialogue systems is challenging for reasons such as the one-to-many problem, i.e., many appropriate responses other than just the golden response. As of now, automatic evaluation methods need better consistency with humans, while reliable human evaluation can be time- and cost-intensive. To this end, we propose the Reference-Assisted Dialogue Evaluation (RADE) approach under the multi-task learning framework, which leverages the pre-created utterance as reference other than the gold response to relief the one-to-many problem. Specifically, RADE explicitly compares reference and the candidate response to predict their overall scores. Moreover, an auxiliary response generation task enhances prediction via a shared encoder. To support RADE, we extend three datasets with additional rated responses other than just a golden response by human annotation. Experiments on our three datasets and two existing benchmarks demonstrate the effectiveness of our method, where Pearson, Spearman, and Kendall correlations with human evaluation outperform state-of-the-art baselines.

10 Jul 2025
Researchers at Bloomberg, USA, developed an LLM-agent driven approach to dynamically identify and structure emerging topics from corporate earnings call transcripts. This system constructs a hierarchical topic ontology that provides financial analysts with timely and actionable insights into evolving industry trends and company-specific narratives.

09 Jun 2025

Image-Text Retrieval (ITR) systems are central to multimodal information access, with Vision-Language Models (VLMs) showing strong performance on standard benchmarks. However, these benchmarks predominantly rely on coarse-grained annotations, limiting their ability to reveal how models perform under real-world conditions, where query granularity varies. Motivated by this gap, we examine how dataset granularity and query perturbations affect retrieval performance and robustness across four architecturally diverse VLMs (ALIGN, AltCLIP, CLIP, and GroupViT). Using both standard benchmarks (MS-COCO, Flickr30k) and their fine-grained variants, we show that richer captions consistently enhance retrieval, especially in text-to-image tasks, where we observe an average improvement of 16.23%, compared to 6.44% in image-to-text. To assess robustness, we introduce a taxonomy of perturbations and conduct extensive experiments, revealing that while perturbations typically degrade performance, they can also unexpectedly improve retrieval, exposing nuanced model behaviors. Notably, word order emerges as a critical factor -- contradicting prior assumptions of model insensitivity to it. Our results highlight variation in model robustness and a dataset-dependent relationship between caption granularity and perturbation sensitivity and emphasize the necessity of evaluating models on datasets of varying granularity.
There are no more papers matching your filters at the moment.
