
01 Aug 2025
 Michigan State University
Michigan State University University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of GeorgiaLehigh University
University of GeorgiaLehigh University The University of Hong Kong
The University of Hong Kong Huazhong University of Science and TechnologySalesforce ResearchUniversity of Illinois at Chicago
Huazhong University of Science and TechnologySalesforce ResearchUniversity of Illinois at Chicago Duke UniversityJilin University
Duke UniversityJilin University Southern University of Science and TechnologyWorcester Polytechnic InstituteLinkedIn CorporationSquirrel Ai Learning
Southern University of Science and TechnologyWorcester Polytechnic InstituteLinkedIn CorporationSquirrel Ai Learning
This survey offers the first comprehensive review of Post-training Language Models (PoLMs), systematically classifying methods, datasets, and applications within a novel intellectual framework. It traces the evolution of LLMs across five core paradigms—Fine-tuning, Alignment, Reasoning, Efficiency, and Integration & Adaptation—and identifies critical future research directions.
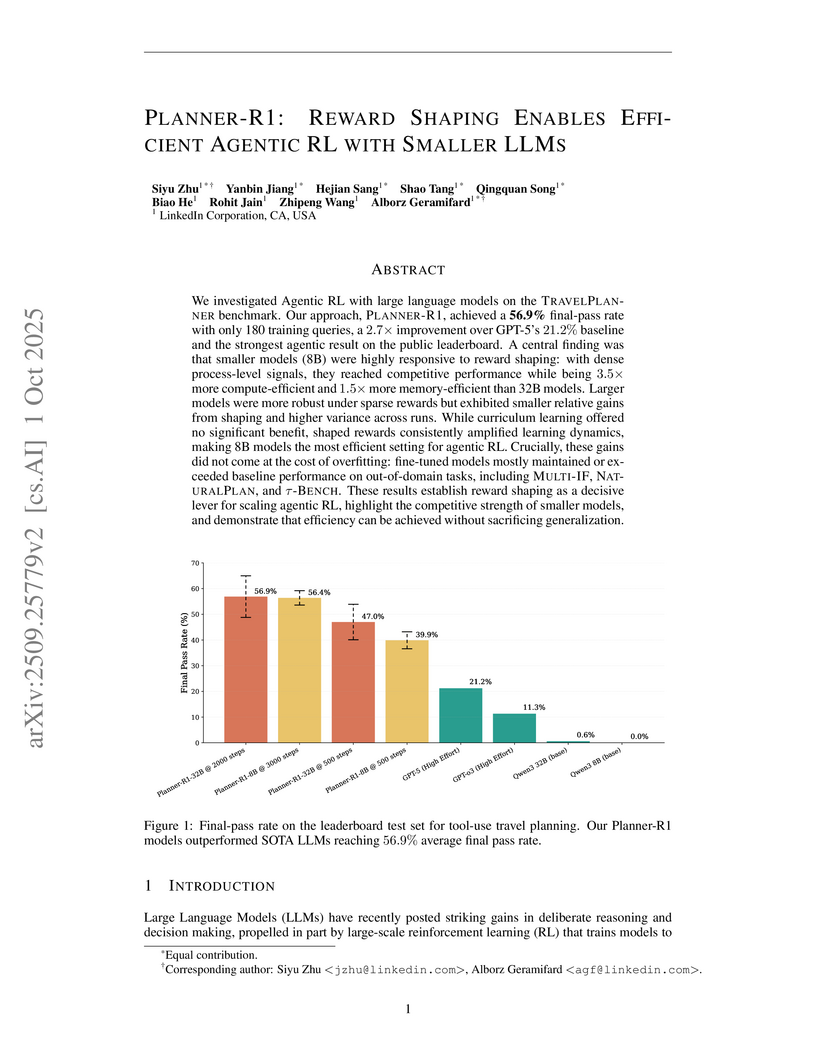
01 Oct 2025
LinkedIn researchers developed PLANNER-R1, an agentic reinforcement learning framework that utilizes multi-stage reward shaping to enable efficient and high-performing LLM agents. This approach allowed an 8B parameter LLM to achieve a 56.4% final pass rate on the complex TRAVELPLANNER benchmark, demonstrating performance comparable to larger models with 3.5x greater compute efficiency while maintaining generalization.

06 May 2024
Researchers at LinkedIn developed a Retrieval-Augmented Generation (RAG) system integrated with Knowledge Graphs (KGs) to enhance question answering for customer service inquiries. This approach improved retrieval accuracy by 77.6% MRR and reduced median issue resolution time by 28.6% in a production environment.

03 Aug 2025

Autoregressive models (ARMs) have long dominated the landscape of biomedical vision-language models (VLMs). Recently, masked diffusion models such as LLaDA have emerged as promising alternatives, yet their application in the biomedical domain remains largely underexplored. To bridge this gap, we introduce \textbf{LLaDA-MedV}, the first large language diffusion model tailored for biomedical image understanding through vision instruction tuning. LLaDA-MedV achieves relative performance gains of 7.855\% over LLaVA-Med and 1.867\% over LLaDA-V in the open-ended biomedical visual conversation task, and sets new state-of-the-art accuracy on the closed-form subset of three VQA benchmarks: 84.93\% on VQA-RAD, 92.31\% on SLAKE, and 95.15\% on PathVQA. Furthermore, a detailed comparison with LLaVA-Med suggests that LLaDA-MedV is capable of generating reasonably longer responses by explicitly controlling response length, which can lead to more informative outputs. We also conduct an in-depth analysis of both the training and inference stages, highlighting the critical roles of initialization weight selection, fine-tuning strategies, and the interplay between sampling steps and response repetition. The code and model weight is released at this https URL.

19 Aug 2025
LinkedIn developed an LLM-powered framework to unify query understanding in its job matching systems, replacing a fragmented architecture of task-specific models. This approach achieved improved search relevance, significantly reduced operational overhead, and met stringent latency requirements for a large-scale platform.

08 Oct 2025
In large-scale industrial LLM systems, prompt templates often expand to thousands of tokens as teams iteratively incorporate sections such as task instructions, few-shot examples, and heuristic rules to enhance robustness and coverage. This expansion leads to bloated prompts that are difficult to maintain and incur significant inference latency and serving costs. To address this, we introduce Prompt Compression via Attribution Estimation (ProCut), a flexible, LLM-agnostic, training-free framework that compresses prompts through attribution analysis. ProCut segments prompt templates into semantically meaningful units, quantifies their impact on task performance, and prunes low-utility components. Through extensive experiments on five public benchmark datasets and real-world industrial prompts, we show that ProCut achieves substantial prompt size reductions (78% fewer tokens in production) while maintaining or even slightly improving task performance (up to 62% better than alternative methods). We further introduce an LLM-driven attribution estimator that reduces compression latency by over 50%, and demonstrate that ProCut integrates seamlessly with existing prompt-optimization frameworks to produce concise, high-performing prompts.

21 May 2025
Data Driven Attribution, which assigns conversion credits to marketing
interactions based on causal patterns learned from data, is the foundation of
modern marketing intelligence and vital to any marketing businesses and
advertising platform. In this paper, we introduce a unified transformer-based
attribution approach that can handle member-level data, aggregate-level data,
and integration of external macro factors. We detail the large scale
implementation of the approach at LinkedIn, showcasing significant impact. We
also share learning and insights that are broadly applicable to the marketing
and ad tech fields.

16 Oct 2025
LinkedIn engineers successfully deployed a fine-tuned causal language model (Meta LLaMA 3) as a dual encoder for their Feed retrieval system, streamlining a complex architecture and achieving a 0.8% increase in revenue and a 0.2% rise in daily unique professional interactors, with particular benefits for new members.

30 May 2025
Reinforcement Learning with Human Feedback (RLHF) and its variants have made
huge strides toward the effective alignment of large language models (LLMs) to
follow instructions and reflect human values. More recently, Direct Alignment
Algorithms (DAAs) have emerged in which the reward modeling stage of RLHF is
skipped by characterizing the reward directly as a function of the policy being
learned. Some popular examples of DAAs include Direct Preference Optimization
(DPO) and Simple Preference Optimization (SimPO). These methods often suffer
from likelihood displacement, a phenomenon by which the probabilities of
preferred responses are often reduced undesirably. In this paper, we argue
that, for DAAs the reward (function) shape matters. We introduce
\textbf{AlphaPO}, a new DAA method that leverages an -parameter to help
change the shape of the reward function beyond the standard log reward. AlphaPO
helps maintain fine-grained control over likelihood displacement and
over-optimization. Compared to SimPO, one of the best performing DAAs, AlphaPO
leads to about 7\% to 10\% relative improvement in alignment performance for
the instruct versions of Mistral-7B and Llama3-8B while achieving 15\% to 50\%
relative improvement over DPO on the same models. The analysis and results
presented highlight the importance of the reward shape and how one can
systematically change it to affect training dynamics, as well as improve
alignment performance.

13 Jul 2025
LinkedIn's STAR (Signal Integration for Talent and Recruiters) system integrates large language model (LLM) embeddings with graph neural networks (GNNs) to enhance large-scale job matching. This approach led to a +1.5% increase in total job applications, a +2.7% rise in recruiter InMail replies, and a +1.0% improvement in successful job search sessions in online A/B tests.

12 May 2025

A new regularization technique called Batch-wise Sum-to-Zero Regularization (BSR) improves the robustness of reward models used in language model alignment by controlling hidden state norm dispersion, achieving better generalization across multiple scenarios while reducing verbosity in generated responses when tested on Llama-3 and Qwen2.5 models.

20 Feb 2024
We present LinkSAGE, an innovative framework that integrates Graph Neural
Networks (GNNs) into large-scale personalized job matching systems, designed to
address the complex dynamics of LinkedIns extensive professional network. Our
approach capitalizes on a novel job marketplace graph, the largest and most
intricate of its kind in industry, with billions of nodes and edges. This graph
is not merely extensive but also richly detailed, encompassing member and job
nodes along with key attributes, thus creating an expansive and interwoven
network. A key innovation in LinkSAGE is its training and serving methodology,
which effectively combines inductive graph learning on a heterogeneous,
evolving graph with an encoder-decoder GNN model. This methodology decouples
the training of the GNN model from that of existing Deep Neural Nets (DNN)
models, eliminating the need for frequent GNN retraining while maintaining
up-to-date graph signals in near realtime, allowing for the effective
integration of GNN insights through transfer learning. The subsequent nearline
inference system serves the GNN encoder within a real-world setting,
significantly reducing online latency and obviating the need for costly
real-time GNN infrastructure. Validated across multiple online A/B tests in
diverse product scenarios, LinkSAGE demonstrates marked improvements in member
engagement, relevance matching, and member retention, confirming its
generalizability and practical impact.

05 Nov 2025
The efficient deployment of large language models (LLMs) in online settings requires optimizing inference performance under stringent latency constraints, particularly the time-to-first-token (TTFT) and time-per-output-token (TPOT). This paper focuses on the query scheduling problem for LLM inference with prefix reuse, a technique that leverages shared prefixes across queries to reduce computational overhead. Our work reveals previously unknown limitations of the existing first-come-first-serve (FCFS) and longest-prefix-match (LPM) scheduling strategies with respect to satisfying latency constraints. We present a formal theoretical framework for LLM query scheduling under RadixAttention, a prefix reuse mechanism that stores and reuses intermediate representations in a radix tree structure. Our analysis establishes the NP-hardness of the scheduling problem with prefix reuse under TTFT constraints and proposes a novel scheduling algorithm, -LPM, which generalizes existing methods by balancing prefix reuse and fairness in query processing. Theoretical guarantees demonstrate that -LPM achieves improved TTFT performance under realistic traffic patterns captured by a data generative model. Empirical evaluations in a realistic serving setting validates our findings, showing significant reductions in P99 TTFT compared to baseline methods.
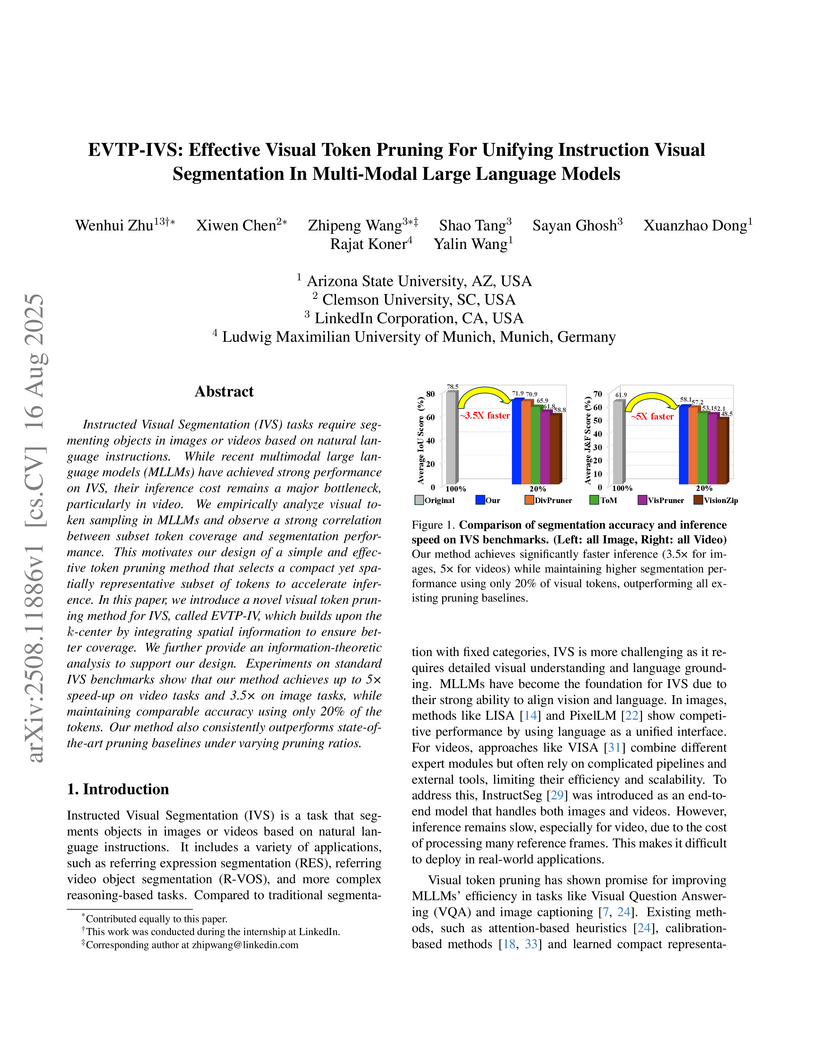
16 Aug 2025
Instructed Visual Segmentation (IVS) tasks require segmenting objects in images or videos based on natural language instructions. While recent multimodal large language models (MLLMs) have achieved strong performance on IVS, their inference cost remains a major bottleneck, particularly in video. We empirically analyze visual token sampling in MLLMs and observe a strong correlation between subset token coverage and segmentation performance. This motivates our design of a simple and effective token pruning method that selects a compact yet spatially representative subset of tokens to accelerate inference. In this paper, we introduce a novel visual token pruning method for IVS, called EVTP-IV, which builds upon the k-center by integrating spatial information to ensure better coverage. We further provide an information-theoretic analysis to support our design. Experiments on standard IVS benchmarks show that our method achieves up to 5X speed-up on video tasks and 3.5X on image tasks, while maintaining comparable accuracy using only 20% of the tokens. Our method also consistently outperforms state-of-the-art pruning baselines under varying pruning ratios.

25 Apr 2020

Learning knowledge graph (KG) embeddings is an emerging technique for a
variety of downstream tasks such as summarization, link prediction, information
retrieval, and question answering. However, most existing KG embedding models
neglect space and, therefore, do not perform well when applied to (geo)spatial
data and tasks. For those models that consider space, most of them primarily
rely on some notions of distance. These models suffer from higher computational
complexity during training while still losing information beyond the relative
distance between entities. In this work, we propose a location-aware KG
embedding model called SE-KGE. It directly encodes spatial information such as
point coordinates or bounding boxes of geographic entities into the KG
embedding space. The resulting model is capable of handling different types of
spatial reasoning. We also construct a geographic knowledge graph as well as a
set of geographic query-answer pairs called DBGeo to evaluate the performance
of SE-KGE in comparison to multiple baselines. Evaluation results show that
SE-KGE outperforms these baselines on the DBGeo dataset for geographic logic
query answering task. This demonstrates the effectiveness of our
spatially-explicit model and the importance of considering the scale of
different geographic entities. Finally, we introduce a novel downstream task
called spatial semantic lifting which links an arbitrary location in the study
area to entities in the KG via some relations. Evaluation on DBGeo shows that
our model outperforms the baseline by a substantial margin.

25 Feb 2022

We establish a general optimization framework for the design of automated
bidding agent in dynamic online marketplaces. It optimizes solely for the
buyer's interest and is agnostic to the auction mechanism imposed by the
seller. As a result, the framework allows, for instance, the joint optimization
of a group of ads across multiple platforms each running its own auction
format. Bidding strategy derived from this framework automatically guarantees
the optimality of budget allocation across ad units and platforms. Common
constraints such as budget delivery schedule, return on investments and
guaranteed results, directly translates to additional parameters in the bidding
formula. We share practical learnings of the deployed bidding system in the
LinkedIn ad marketplace based on this framework.

06 Nov 2023
Recommender systems have become an integral part of online platforms, providing personalized recommendations for purchases, content consumption, and interpersonal connections. These systems consist of two sides: the producer side comprises product sellers, content creators, or service providers, etc., and the consumer side includes buyers, viewers, or customers, etc. To optimize online recommender systems, A/B tests serve as the golden standard for comparing different ranking models and evaluating their impact on both the consumers and producers. While consumer-side experiments is relatively straightforward to design and commonly employed to assess the impact of ranking changes on the behavior of consumers (buyers, viewers, etc.), designing producer-side experiments for an online recommender/ranking system is notably more intricate because producer items in the treatment and control groups need to be ranked by different models and then merged into a unified ranking to be presented to each consumer. Current design solutions in the literature are ad hoc and lacking rigorous guiding principles. In this paper, we examine limitations of these existing methods and propose the principle of consistency and principle of monotonicity for designing producer-side experiments of online recommender systems. Building upon these principles, we also present a systematic solution based on counterfactual interleaving designs to accurately measure the impacts of ranking changes on the producers (sellers, creators, etc.).

16 Dec 2020
The Budget-split design, developed at LinkedIn Corporation, introduces an experimental framework for online marketplaces that simulates two independent marketplaces by proportionally splitting member populations and buyer budgets. This approach effectively eliminates cannibalization bias and substantially increases statistical power for measuring treatment effects, enabling the detection of financially impactful product changes previously undetectable.

02 Sep 2022

We study optimal variance reduction solutions for count and ratio metrics in online controlled experiments. Our methods leverage flexible machine learning tools to incorporate covariates that are independent from the treatment but have predictive power for the outcomes, and employ the cross-fitting technique to remove the bias in complex machine learning models. We establish CLT-type asymptotic inference based on our estimators under mild convergence conditions. Our procedures are optimal (efficient) for the corresponding targets as long as the machine learning estimators are consistent, without any requirement for their convergence rates. In complement to the general optimal procedure, we also derive a linear adjustment method for ratio metrics as a special case that is computationally efficient and can flexibly incorporate any pre-treatment covariates. We evaluate the proposed variance reduction procedures with comprehensive simulation studies and provide practical suggestions regarding commonly adopted assumptions in computing ratio metrics. When tested on real online experiment data from LinkedIn, the proposed optimal procedure for ratio metrics can reduce up to 80\% of variance compared to the standard difference-in-mean estimator and also further reduce up to 30\% of variance compared to the CUPED approach by going beyond linearity and incorporating a large number of extra covariates.

18 Sep 2018
Previous efforts in recommendation of candidates for talent search followed
the general pattern of receiving an initial search criteria and generating a
set of candidates utilizing a pre-trained model. Traditionally, the generated
recommendations are final, that is, the list of potential candidates is not
modified unless the user explicitly changes his/her search criteria. In this
paper, we are proposing a candidate recommendation model which takes into
account the immediate feedback of the user, and updates the candidate
recommendations at each step. This setting also allows for very uninformative
initial search queries, since we pinpoint the user's intent due to the feedback
during the search session. To achieve our goal, we employ an intent clustering
method based on topic modeling which separates the candidate space into
meaningful, possibly overlapping, subsets (which we call intent clusters) for
each position. On top of the candidate segments, we apply a multi-armed bandit
approach to choose which intent cluster is more appropriate for the current
session. We also present an online learning scheme which updates the intent
clusters within the session, due to user feedback, to achieve further
personalization. Our offline experiments as well as the results from the online
deployment of our solution demonstrate the benefits of our proposed
methodology.
There are no more papers matching your filters at the moment.
