
02 Sep 2015
An artificial system based on Deep Neural Networks demonstrates the ability to generate high-perceptual-quality artistic images by effectively separating the content of a photograph from the style of a painting. This method, developed by researchers at Tübingen, recombines these elements using hierarchical feature representations from a pre-trained VGG-19 network.

28 Apr 2025
 Google DeepMind
Google DeepMind University of Cambridge
University of Cambridge New York University
New York University University of Oxford
University of Oxford Georgia Institute of Technology
Georgia Institute of Technology University of California, San Diego
University of California, San Diego Boston UniversityTU DarmstadtHelmholtz Munich
Boston UniversityTU DarmstadtHelmholtz Munich Princeton University
Princeton University University of BaselMax Planck Institute for Human DevelopmentMax Planck Institute for Biological CyberneticsUniversity of TuebingenMax Planck School of Cognition
University of BaselMax Planck Institute for Human DevelopmentMax Planck Institute for Biological CyberneticsUniversity of TuebingenMax Planck School of CognitionCentaur, the first foundation model of human cognition, was created by finetuning Llama 3.1 70B on Psych-101, a new large-scale dataset of human behavioral data. The model accurately predicts human choices and response times across diverse psychological experiments, generalizes to out-of-distribution tasks, and demonstrates increased alignment with human neural activity.

28 Feb 2024
Researchers from the Max Planck Institute, Helmholtz Computational Health Center, and Google DeepMind developed CogBench, a benchmark using seven canonical cognitive psychology experiments to assess Large Language Models' (LLM) decision-making and learning behaviors. This work reveals that while high-performing LLMs can match human task success, none consistently exhibit human-like cognitive profiles across behavioral metrics, and identifies key influences of training paradigms like Reinforcement Learning from Human Feedback.

20 Oct 2025

When conflicting images are presented to either eye, binocular fusion is disrupted. Rather than experiencing a blend of both percepts, often only one eye's image is experienced, whilst the other is suppressed from awareness. Importantly, suppression is transient - the two rival images compete for dominance, with stochastic switches between mutually exclusive percepts occurring every few seconds with law-like regularity. From the perspective of dynamical systems theory, visual rivalry offers an experimentally tractable window into the dynamical mechanisms governing perceptual awareness. In a recently developed visual rivalry paradigm - tracking continuous flash suppression (tCFS) - it was shown that the transition between awareness and suppression is hysteretic, with a higher contrast threshold required for a stimulus to breakthrough suppression into awareness than to be suppressed from awareness. Here, we present an analytically-tractable model of visual rivalry that quantitatively explains the hysteretic transition between periods of awareness and suppression in tCFS. Grounded in the theory of neural dynamics, we derive closed-form expressions for the duration of perceptual dominance and suppression, and for the degree of hysteresis (i.e. the depth of perceptual suppression), as a function of model parameters. Finally, our model yields a series of novel behavioural predictions, the first of which - distributions of dominance and suppression durations during tCFS should be approximately equal - we empirically validate in human psychophysical data.

08 Aug 2024
Multimodal large language models (MMLLMs) were systematically evaluated on tasks designed to probe human-like intuitive physics, causal reasoning, and intuitive psychology, demonstrating that current models consistently fall short of human performance and fail to fully capture human behavioral patterns in these core cognitive domains. The study found that while larger models generally performed better, none achieved human-level understanding, highlighting persistent gaps in their ability to genuinely 'think like people' in visually-grounded scenarios.

07 May 2025

Researchers at Helmholtz Munich and the Max Planck Institute for Biological Cybernetics systematically characterized how large language models (LLMs) interact in repeated social games using behavioral game theory, revealing tendencies towards unforgiveness and coordination failures. They also demonstrated that a "Social Chain-of-Thought" (SCoT) prompting method enhanced LLM social behavior and made LLMs appear more human-like to participants.

02 Oct 2024
In-context learning, the ability to adapt based on a few examples in the input prompt, is a ubiquitous feature of large language models (LLMs). However, as LLMs' in-context learning abilities continue to improve, understanding this phenomenon mechanistically becomes increasingly important. In particular, it is not well-understood how LLMs learn to solve specific classes of problems, such as reinforcement learning (RL) problems, in-context. Through three different tasks, we first show that Llama B can solve simple RL problems in-context. We then analyze the residual stream of Llama using Sparse Autoencoders (SAEs) and find representations that closely match temporal difference (TD) errors. Notably, these representations emerge despite the model only being trained to predict the next token. We verify that these representations are indeed causally involved in the computation of TD errors and -values by performing carefully designed interventions on them. Taken together, our work establishes a methodology for studying and manipulating in-context learning with SAEs, paving the way for a more mechanistic understanding.

06 Jun 2023
Large language models are powerful systems that excel at many tasks, ranging from translation to mathematical reasoning. Yet, at the same time, these models often show unhuman-like characteristics. In the present paper, we address this gap and ask whether large language models can be turned into cognitive models. We find that -- after finetuning them on data from psychological experiments -- these models offer accurate representations of human behavior, even outperforming traditional cognitive models in two decision-making domains. In addition, we show that their representations contain the information necessary to model behavior on the level of individual subjects. Finally, we demonstrate that finetuning on multiple tasks enables large language models to predict human behavior in a previously unseen task. Taken together, these results suggest that large, pre-trained models can be adapted to become generalist cognitive models, thereby opening up new research directions that could transform cognitive psychology and the behavioral sciences as a whole.

07 Nov 2025
Computational cognitive models, which formalize theories of cognition, enable researchers to quantify cognitive processes and arbitrate between competing theories by fitting models to behavioral data. Traditionally, these models are handcrafted, which requires significant domain knowledge, coding expertise, and time investment. However, recent advances in machine learning offer solutions to these challenges. In particular, Large Language Models (LLMs) have demonstrated remarkable capabilities for in-context pattern recognition, leveraging knowledge from diverse domains to solve complex problems, and generating executable code that can be used to facilitate the generation of cognitive models. Building on this potential, we introduce a pipeline for Guided generation of Computational Cognitive Models (GeCCo). Given task instructions, participant data, and a template function, GeCCo prompts an LLM to propose candidate models, fits proposals to held-out data, and iteratively refines them based on feedback constructed from their predictive performance. We benchmark this approach across four different cognitive domains -- decision making, learning, planning, and memory -- using three open-source LLMs, spanning different model sizes, capacities, and families. On four human behavioral data sets, the LLM generated models that consistently matched or outperformed the best domain-specific models from the cognitive science literature. Taken together, our results suggest that LLMs can generate cognitive models with conceptually plausible theories that rival -- or even surpass -- the best models from the literature across diverse task domains.

06 Nov 2015
Here we introduce a new model of natural textures based on the feature spaces of convolutional neural networks optimised for object recognition. Samples from the model are of high perceptual quality demonstrating the generative power of neural networks trained in a purely discriminative fashion. Within the model, textures are represented by the correlations between feature maps in several layers of the network. We show that across layers the texture representations increasingly capture the statistical properties of natural images while making object information more and more explicit. The model provides a new tool to generate stimuli for neuroscience and might offer insights into the deep representations learned by convolutional neural networks.

10 Jul 2025
What drives an agent to explore the world while also maintaining control over the environment? From a child at play to scientists in the lab, intelligent agents must balance curiosity (the drive to seek knowledge) with competence (the drive to master and control the environment). Bridging cognitive theories of intrinsic motivation with reinforcement learning, we ask how evolving internal representations mediate the trade-off between curiosity (novelty or information gain) and competence (empowerment). We compare two model-based agents using handcrafted state abstractions (Tabular) or learning an internal world model (Dreamer). The Tabular agent shows curiosity and competence guide exploration in distinct patterns, while prioritizing both improves exploration. The Dreamer agent reveals a two-way interaction between exploration and representation learning, mirroring the developmental co-evolution of curiosity and competence. Our findings formalize adaptive exploration as a balance between pursuing the unknown and the controllable, offering insights for cognitive theories and efficient reinforcement learning.

26 Nov 2023
In everyday conversations, humans can take on different roles and adapt their vocabulary to their chosen roles. We explore whether LLMs can take on, that is impersonate, different roles when they generate text in-context. We ask LLMs to assume different personas before solving vision and language tasks. We do this by prefixing the prompt with a persona that is associated either with a social identity or domain expertise. In a multi-armed bandit task, we find that LLMs pretending to be children of different ages recover human-like developmental stages of exploration. In a language-based reasoning task, we find that LLMs impersonating domain experts perform better than LLMs impersonating non-domain experts. Finally, we test whether LLMs' impersonations are complementary to visual information when describing different categories. We find that impersonation can improve performance: an LLM prompted to be a bird expert describes birds better than one prompted to be a car expert. However, impersonation can also uncover LLMs' biases: an LLM prompted to be a man describes cars better than one prompted to be a woman. These findings demonstrate that LLMs are capable of taking on diverse roles and that this in-context impersonation can be used to uncover their hidden strengths and biases.
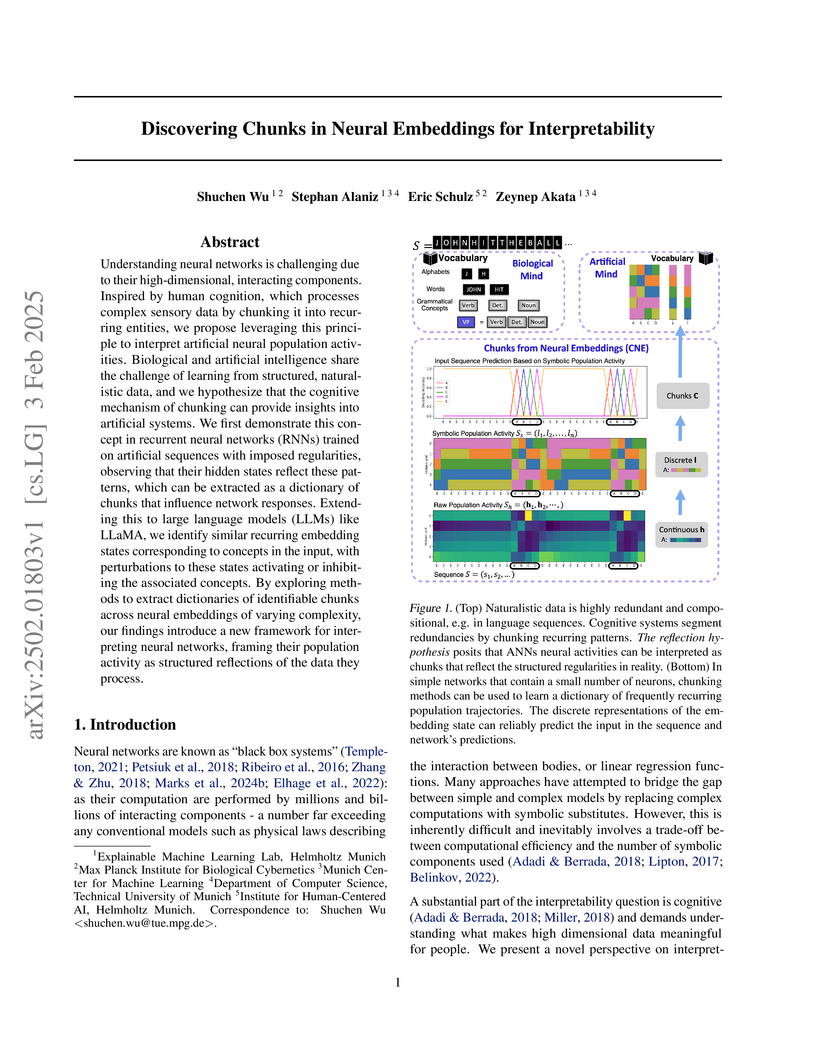
03 Feb 2025

Understanding neural networks is challenging due to their high-dimensional, interacting components. Inspired by human cognition, which processes complex sensory data by chunking it into recurring entities, we propose leveraging this principle to interpret artificial neural population activities. Biological and artificial intelligence share the challenge of learning from structured, naturalistic data, and we hypothesize that the cognitive mechanism of chunking can provide insights into artificial systems. We first demonstrate this concept in recurrent neural networks (RNNs) trained on artificial sequences with imposed regularities, observing that their hidden states reflect these patterns, which can be extracted as a dictionary of chunks that influence network responses. Extending this to large language models (LLMs) like LLaMA, we identify similar recurring embedding states corresponding to concepts in the input, with perturbations to these states activating or inhibiting the associated concepts. By exploring methods to extract dictionaries of identifiable chunks across neural embeddings of varying complexity, our findings introduce a new framework for interpreting neural networks, framing their population activity as structured reflections of the data they process.

16 Aug 2005

We propose new bounds on the error of learning algorithms in terms of a data-dependent notion of complexity. The estimates we establish give optimal rates and are based on a local and empirical version of Rademacher averages, in the sense that the Rademacher averages are computed from the data, on a subset of functions with small empirical error. We present some applications to classification and prediction with convex function classes, and with kernel classes in particular.

15 Oct 2024
Large language models (LLMs) are transforming research on machine learning while galvanizing public debates. Understanding not only when these models work well and succeed but also why they fail and misbehave is of great societal relevance. We propose to turn the lens of psychiatry, a framework used to describe and modify maladaptive behavior, to the outputs produced by these models. We focus on twelve established LLMs and subject them to a questionnaire commonly used in psychiatry. Our results show that six of the latest LLMs respond robustly to the anxiety questionnaire, producing comparable anxiety scores to humans. Moreover, the LLMs' responses can be predictably changed by using anxiety-inducing prompts. Anxiety-induction not only influences LLMs' scores on an anxiety questionnaire but also influences their behavior in a previously-established benchmark measuring biases such as racism and ageism. Importantly, greater anxiety-inducing text leads to stronger increases in biases, suggesting that how anxiously a prompt is communicated to large language models has a strong influence on their behavior in applied settings. These results demonstrate the usefulness of methods taken from psychiatry for studying the capable algorithms to which we increasingly delegate authority and autonomy.

18 Jul 2025

Formal frameworks of causality have operated largely parallel to modern trends in deep reinforcement learning (RL). However, there has been a revival of interest in formally grounding the representations learned by neural networks in causal concepts. Yet, most attempts at neural models of causality assume static causal graphs and ignore the dynamic nature of causal interactions. In this work, we introduce Causal Process framework as a novel theory for representing dynamic hypotheses about causal structure. Furthermore, we present Causal Process Model as an implementation of this framework. This allows us to reformulate the attention mechanism popularized by Transformer networks within an RL setting with the goal to infer interpretable causal processes from visual observations. Here, causal inference corresponds to constructing a causal graph hypothesis which itself becomes an RL task nested within the original RL problem. To create an instance of such hypothesis, we employ RL agents. These agents establish links between units similar to the original Transformer attention mechanism. We demonstrate the effectiveness of our approach in an RL environment where we outperform current alternatives in causal representation learning and agent performance, and uniquely recover graphs of dynamic causal processes.

06 Feb 2024
We study the in-context learning dynamics of large language models (LLMs) using three instrumental learning tasks adapted from cognitive psychology. We find that LLMs update their beliefs in an asymmetric manner and learn more from better-than-expected outcomes than from worse-than-expected ones. Furthermore, we show that this effect reverses when learning about counterfactual feedback and disappears when no agency is implied. We corroborate these findings by investigating idealized in-context learning agents derived through meta-reinforcement learning, where we observe similar patterns. Taken together, our results contribute to our understanding of how in-context learning works by highlighting that the framing of a problem significantly influences how learning occurs, a phenomenon also observed in human cognition.

23 Oct 2020
We compare the robustness of humans and current convolutional deep neural networks (DNNs) on object recognition under twelve different types of image degradations. First, using three well known DNNs (ResNet-152, VGG-19, GoogLeNet) we find the human visual system to be more robust to nearly all of the tested image manipulations, and we observe progressively diverging classification error-patterns between humans and DNNs when the signal gets weaker. Secondly, we show that DNNs trained directly on distorted images consistently surpass human performance on the exact distortion types they were trained on, yet they display extremely poor generalisation abilities when tested on other distortion types. For example, training on salt-and-pepper noise does not imply robustness on uniform white noise and vice versa. Thus, changes in the noise distribution between training and testing constitutes a crucial challenge to deep learning vision systems that can be systematically addressed in a lifelong machine learning approach. Our new dataset consisting of 83K carefully measured human psychophysical trials provide a useful reference for lifelong robustness against image degradations set by the human visual system.

30 Sep 2025
 Stanford UniversityHarvard Medical SchoolRadboud UniversityMassachusetts General Hospital
Stanford UniversityHarvard Medical SchoolRadboud UniversityMassachusetts General Hospital Université Paris-Saclay
Université Paris-Saclay University of Alberta
University of Alberta King’s College LondonThe University of Sydney
King’s College LondonThe University of Sydney CEAEindhoven University of TechnologyUniversity of VeronaUniversity of ParmaTechnical University of DenmarkINSERMUniversity of LausanneUniversity of Eastern FinlandÉcole Polytechnique Fédérale de LausannePhilipps-Universität MarburgMax Planck Institute for Biological CyberneticsUniversity of California San FranciscoVanderbilt University Medical CenterNIHBrigham and Women’s HospitalIcahn School of Medicine at Mount SinaiMcLean HospitalMax Planck Institute for PsycholinguisticsUniversité du Québec à Montréal (UQAM)Lausanne University HospitalNational Institute of Biomedical Imaging and BioengineeringUniversity of GießenUniversity Medical Centre UtrechtUniversidad de ConcepciٞnCopenhagen University Hospital - Amager and HvidovreSorbonne UniversitiesUniversity of Rochester School of MedicineUniversity of DarmstadtNational Yang Ming-Chiao Tung UniversityUniversit
LavalUniversit
de SherbrookeUniversit
Paris Cit
CEAEindhoven University of TechnologyUniversity of VeronaUniversity of ParmaTechnical University of DenmarkINSERMUniversity of LausanneUniversity of Eastern FinlandÉcole Polytechnique Fédérale de LausannePhilipps-Universität MarburgMax Planck Institute for Biological CyberneticsUniversity of California San FranciscoVanderbilt University Medical CenterNIHBrigham and Women’s HospitalIcahn School of Medicine at Mount SinaiMcLean HospitalMax Planck Institute for PsycholinguisticsUniversité du Québec à Montréal (UQAM)Lausanne University HospitalNational Institute of Biomedical Imaging and BioengineeringUniversity of GießenUniversity Medical Centre UtrechtUniversidad de ConcepciٞnCopenhagen University Hospital - Amager and HvidovreSorbonne UniversitiesUniversity of Rochester School of MedicineUniversity of DarmstadtNational Yang Ming-Chiao Tung UniversityUniversit
LavalUniversit
de SherbrookeUniversit
Paris CitIn the spirit of the historic Millennium Prize Problems that heralded a new era for mathematics, the newly formed International Society for Tractography (IST) has launched the Millennium Pathways for Tractography, a community-driven roadmap designed to shape the future of the field. Conceived during the inaugural Tract-Anat Retreat, this initiative reflects a collective vision for advancing tractography over the coming decade and beyond. The roadmap consists of 40 grand challenges, developed by international experts and organized into seven categories spanning three overarching themes: neuroanatomy, tractography methods, and clinical applications. By defining shared short-, medium-, and long-term goals, these pathways provide a structured framework to confront fundamental limitations, promote rigorous validation, and accelerate the translation of tractography into a robust tool for neuroscience and medicine. Ultimately, the Millennium Pathways aim to guide and inspire future research and collaboration, ensuring the continued scientific and clinical relevance of tractography well into the future.

03 Sep 2025
Researchers introduced Ecologically Rational Meta-learned Inference (ERMI), a computational framework leveraging large language models (LLMs) to generate ecologically valid cognitive tasks and meta-learning to derive adaptive models. ERMI successfully replicated diverse human learning and decision-making behaviors across 15 experiments, demonstrating superior fit to human data compared to established cognitive models.
There are no more papers matching your filters at the moment.
