
25 Sep 2025


MAPO (Mixed Advantage Policy Optimization) improves Group Relative Policy Optimization (GRPO) by introducing an adaptive advantage function that accounts for varying trajectory certainty in foundation models. This approach leads to higher overall accuracies, such as 51.26% on math reasoning and 66.77% on emotion reasoning tasks, outperforming existing GRPO methods and enhancing generalization.

01 Apr 2025

Research identifies that object hallucinations in large vision-language models stem from inactive or inconsistent visual attention in specific "middle layers" during image processing. Leveraging this insight, a heads-guided attention intervention method, applied during inference, reduces hallucinations by an average of 19.5% on CHAIR_S compared to the next best approach, without requiring retraining.

19 Feb 2025

Token-wise Feature Caching (ToCa) accelerates Diffusion Transformers without requiring model retraining by adaptively caching intermediate features at a granular token and layer level. This method achieves up to 2.75x speedup while preserving or improving generation quality across various text-to-image and text-to-video models.

02 Jul 2025



Researchers introduce OpticalRS-13M, a 13-million-image visible light remote sensing dataset, and SelectiveMAE, an efficient masked image modeling method. This pipeline achieves over a 2x speedup in pre-training and substantial memory reduction while maintaining or improving performance across various downstream remote sensing tasks compared to existing methods.

04 Nov 2025

Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,3768,376) and HighRS-VQA (avg. 2,0001,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key this http URL these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.

08 Aug 2025
We introduce a diffusion-based cross-domain image translator in the absence of paired training data. Unlike GAN-based methods, our approach integrates diffusion models to learn the image translation process, allowing for more coverable modeling of the data distribution and performance improvement of the cross-domain translation. However, incorporating the translation process within the diffusion process is still challenging since the two processes are not aligned exactly, i.e., the diffusion process is applied to the noisy signal while the translation process is conducted on the clean signal. As a result, recent diffusion-based studies employ separate training or shallow integration to learn the two processes, yet this may cause the local minimal of the translation optimization, constraining the effectiveness of diffusion models. To address the problem, we propose a novel joint learning framework that aligns the diffusion and the translation process, thereby improving the global optimality. Specifically, we propose to extract the image components with diffusion models to represent the clean signal and employ the translation process with the image components, enabling an end-to-end joint learning manner. On the other hand, we introduce a time-dependent translation network to learn the complex translation mapping, resulting in effective translation learning and significant performance improvement. Benefiting from the design of joint learning, our method enables global optimization of both processes, enhancing the optimality and achieving improved fidelity and structural consistency. We have conducted extensive experiments on RGBRGB and diverse cross-modality translation tasks including RGBEdge, RGBSemantics and RGBDepth, showcasing better generative performances than the state of the arts.

05 Dec 2025
Forecasting how human hands move in egocentric views is critical for applications like augmented reality and human-robot policy transfer. Recently, several hand trajectory prediction (HTP) methods have been developed to generate future possible hand waypoints, which still suffer from insufficient prediction targets, inherent modality gaps, entangled hand-head motion, and limited validation in downstream tasks. To address these limitations, we present a universal hand motion forecasting framework considering multi-modal input, multi-dimensional and multi-target prediction patterns, and multi-task affordances for downstream applications. We harmonize multiple modalities by vision-language fusion, global context incorporation, and task-aware text embedding injection, to forecast hand waypoints in both 2D and 3D spaces. A novel dual-branch diffusion is proposed to concurrently predict human head and hand movements, capturing their motion synergy in egocentric vision. By introducing target indicators, the prediction model can forecast the specific joint waypoints of the wrist or the fingers, besides the widely studied hand center points. In addition, we enable Uni-Hand to additionally predict hand-object interaction states (contact/separation) to facilitate downstream tasks better. As the first work to incorporate downstream task evaluation in the literature, we build novel benchmarks to assess the real-world applicability of hand motion forecasting algorithms. The experimental results on multiple publicly available datasets and our newly proposed benchmarks demonstrate that Uni-Hand achieves the state-of-the-art performance in multi-dimensional and multi-target hand motion forecasting. Extensive validation in multiple downstream tasks also presents its impressive human-robot policy transfer to enable robotic manipulation, and effective feature enhancement for action anticipation/recognition.

31 Mar 2025
Researchers from multiple Chinese institutions introduce XLRS-Bench, a benchmark dataset of 1,400 ultra-high-resolution (8,500x8,500 pixel) remote sensing images with expert annotations across 16 perception and reasoning tasks, revealing significant limitations in current multimodal language models' ability to process large-scale satellite imagery.

28 Aug 2025

Object goal navigation (ObjectNav) is a fundamental task in embodied AI, requiring an agent to locate a target object in previously unseen environments. This task is particularly challenging because it requires both perceptual and cognitive processes, including object recognition and decision-making. While substantial advancements in perception have been driven by the rapid development of visual foundation models, progress on the cognitive aspect remains constrained, primarily limited to either implicit learning through simulator rollouts or explicit reliance on predefined heuristic rules. Inspired by neuroscientific findings demonstrating that humans maintain and dynamically update fine-grained cognitive states during object search tasks in novel environments, we propose CogNav, a framework designed to mimic this cognitive process using large language models. Specifically, we model the cognitive process using a finite state machine comprising fine-grained cognitive states, ranging from exploration to identification. Transitions between states are determined by a large language model based on a dynamically constructed heterogeneous cognitive map, which contains spatial and semantic information about the scene being explored. Extensive evaluations on the HM3D, MP3D, and RoboTHOR benchmarks demonstrate that our cognitive process modeling significantly improves the success rate of ObjectNav at least by relative 14% over the state-of-the-arts.

03 Nov 2025
LiDAR-VGGT: Cross-Modal Coarse-to-Fine Fusion for Globally Consistent and Metric-Scale Dense Mapping
LiDAR-VGGT: Cross-Modal Coarse-to-Fine Fusion for Globally Consistent and Metric-Scale Dense Mapping

LiDAR-VGGT is a new system that merges LiDAR-inertial odometry with the Visual Geometry Grounded Transformer to create large-scale, dense, and globally consistent 3D colored point cloud reconstructions at a metric scale. This framework improves upon the sparsity of LiDAR maps and the unscaled nature of visual-only reconstructions, showing enhanced geometric and color fidelity on diverse datasets.

25 Aug 2025

Researchers from HKUST, CAS, NUDT, and the University of Sydney developed LLM-Rsum, a method that allows large language models to self-manage long-term dialogue memory by recursively summarizing conversational history. This approach enables dynamic memory updates, leading to improved consistency and coherence in responses across extended interactions, surpassing existing memory-based and retrieval-based baselines.

18 Mar 2025
In this paper, we propose RFUAV as a new benchmark dataset for
radio-frequency based (RF-based) unmanned aerial vehicle (UAV) identification
and address the following challenges: Firstly, many existing datasets feature a
restricted variety of drone types and insufficient volumes of raw data, which
fail to meet the demands of practical applications. Secondly, existing datasets
often lack raw data covering a broad range of signal-to-noise ratios (SNR), or
do not provide tools for transforming raw data to different SNR levels. This
limitation undermines the validity of model training and evaluation. Lastly,
many existing datasets do not offer open-access evaluation tools, leading to a
lack of unified evaluation standards in current research within this field.
RFUAV comprises approximately 1.3 TB of raw frequency data collected from 37
distinct UAVs using the Universal Software Radio Peripheral (USRP) device in
real-world environments. Through in-depth analysis of the RF data in RFUAV, we
define a drone feature sequence called RF drone fingerprint, which aids in
distinguishing drone signals. In addition to the dataset, RFUAV provides a
baseline preprocessing method and model evaluation tools. Rigorous experiments
demonstrate that these preprocessing methods achieve state-of-the-art (SOTA)
performance using the provided evaluation tools. The RFUAV dataset and baseline
implementation are publicly available at this https URL
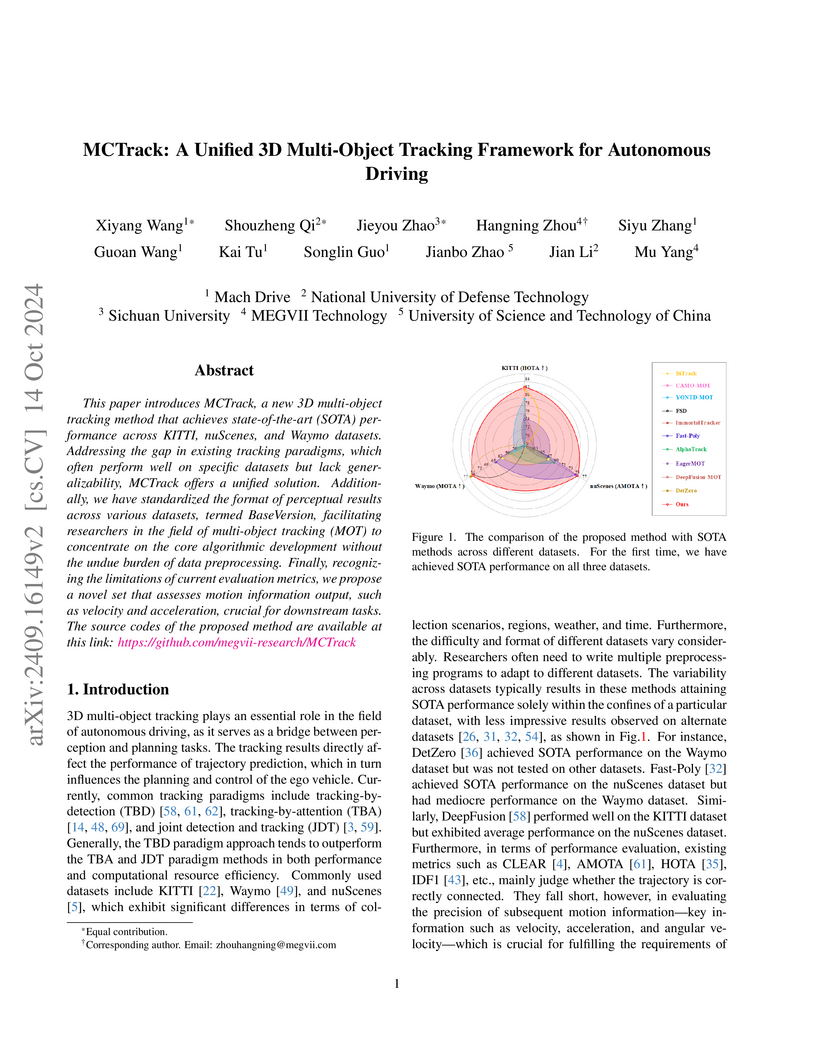
14 Oct 2024

MCTrack introduces a unified 3D multi-object tracking framework designed to achieve state-of-the-art performance across KITTI, nuScenes, and Waymo datasets. It also proposes a standardized data format and novel motion-centric evaluation metrics, enhancing generalizability and comprehensive assessment for autonomous driving.

03 May 2025
This paper introduces PIN-WM, a framework that learns a physics-informed world model directly from visual observations to enable robust Sim2Real transfer for non-prehensile manipulation. The approach integrates differentiable physics and rendering to accurately identify physical properties and object appearance, achieving high success rates of 75% in real-world push and 65% in flip tasks with a physical robot.

24 Nov 2023

This survey systematically reviews recent advancements in Spatio-Temporal Graph Neural Networks (STGNNs) for predictive learning across various urban computing domains, including transportation and environmental modeling. It provides a structured analysis of STGNN architectures, their methods for spatio-temporal dependency capture, and integrations with advanced learning frameworks, while also identifying current limitations and outlining future research directions in the field.

03 Oct 2025
HumanoidExo, a system developed by researchers from National University of Defense Technology and Midea Group, provides scalable whole-body humanoid manipulation data via a wearable exoskeleton and motion retargeting. This system enables a Unitree G1 humanoid robot to acquire new skills like walking solely from exoskeleton data and achieve 80% success rates in complex manipulation tasks using significantly fewer real-robot demonstrations.

29 Apr 2024



Researchers from The Hong Kong Polytechnic University, Michigan State University, and Amazon present a systematic survey of LLM-empowered recommender systems, categorizing current methodologies for representation learning and LLM adaptation. The work also outlines the field's advancements, challenges, and future research directions.

06 Mar 2025
The paper "Keeping Yourself is Important in Downstream Tuning Multimodal Large Language Model" provides a systematic review and unified benchmark for tuning MLLMs, classifying methods into Selective, Additive, and Reparameterization paradigms. It empirically analyzes the trade-offs between task-expert specialization and open-world stabilization, offering practical guidelines for MLLM deployment.
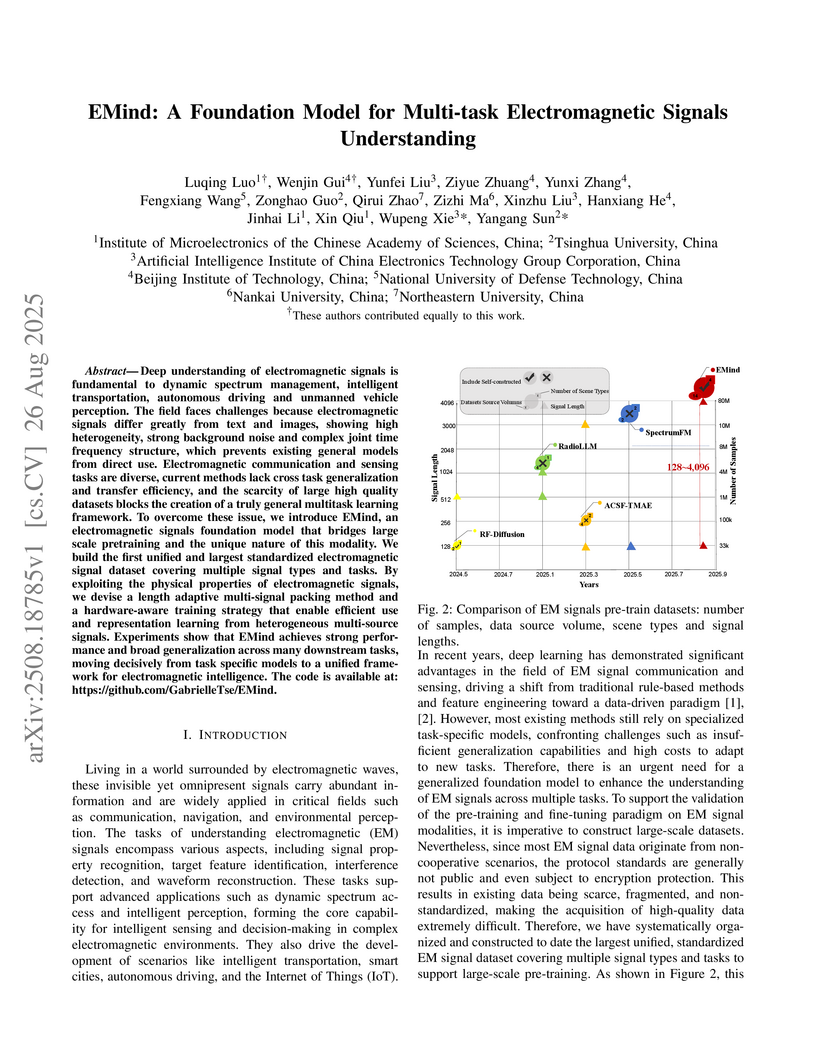
26 Aug 2025

Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: this https URL.

15 Oct 2025
Researchers at Peking University and collaborators introduced MaskDCPT, a pre-training framework for universal image restoration that leverages inherent degradation classification and masked image modeling. This approach achieves state-of-the-art performance across diverse degradation types, showing strong generalization to unseen conditions and yielding significant PSNR gains (e.g., >3.77 dB average in 5D tasks).
There are no more papers matching your filters at the moment.
