 Stanford University
Stanford University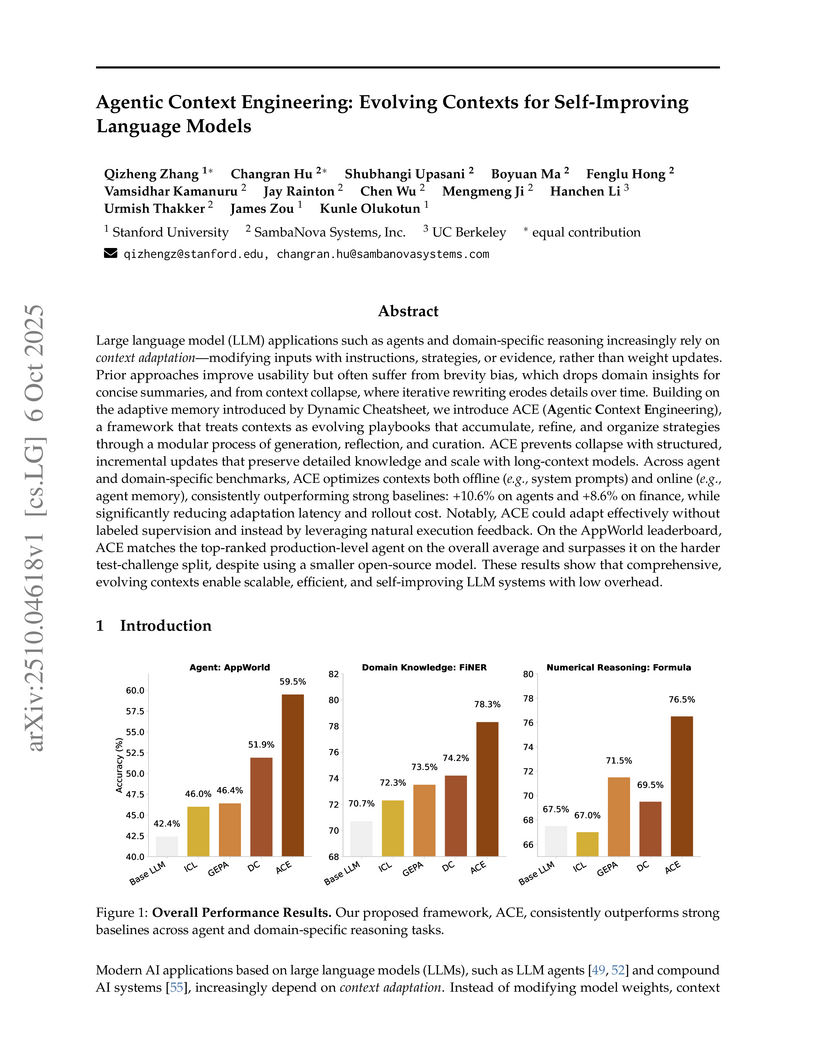
06 Oct 2025

The Agentic Context Engineering (ACE) framework dynamically evolves and curates comprehensive 'playbook' contexts for large language models, allowing them to continuously improve performance. This enables smaller, open-source models to match or exceed proprietary LLM agent performance on benchmarks like AppWorld, simultaneously reducing adaptation latency by up to 91.5% and token cost by 83.6%.
04 Nov 2025







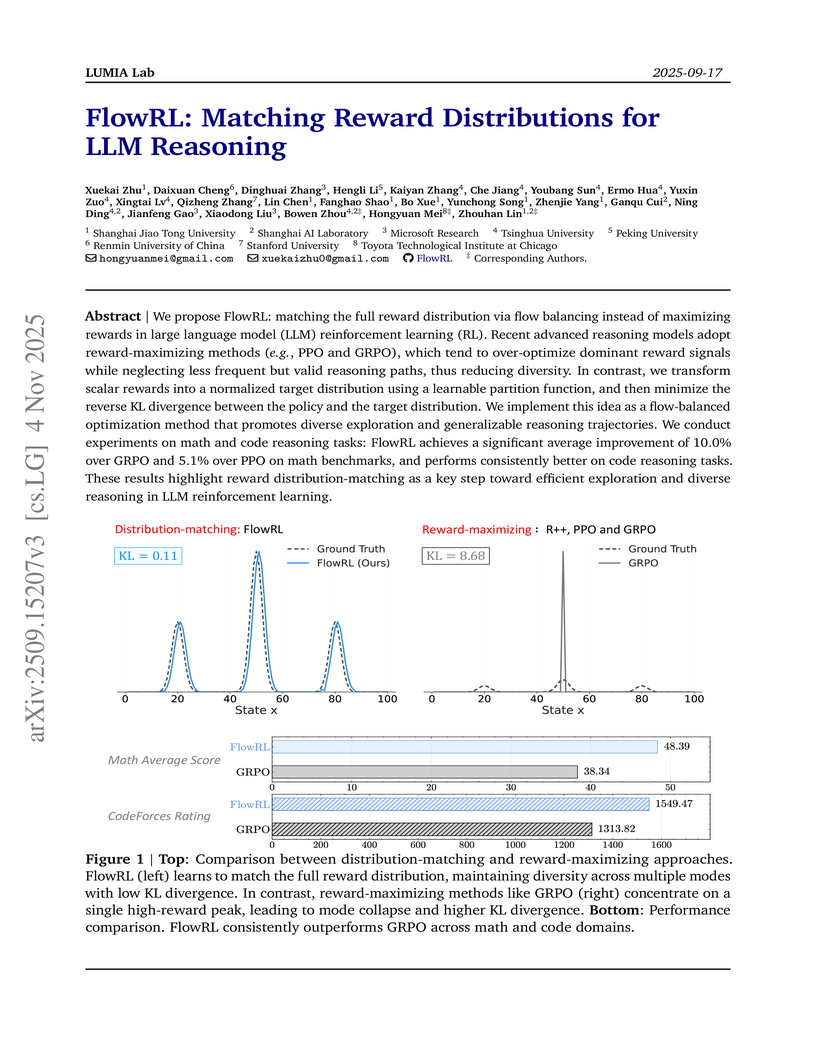
FlowRL presents a policy optimization algorithm for large language models that leverages GFlowNet principles to match reward distributions rather than merely maximizing expected reward. This approach yielded superior performance on math and code reasoning benchmarks and notably increased the diversity of generated solutions.

10 May 2025



A gating mechanism applied to the output of scaled dot-product attention in large language models improves training stability and performance across benchmarks while mitigating attention sink issues, demonstrated through extensive experiments on 15B parameter MoE models and 1.7B dense models trained on 3.5 trillion tokens.

30 Jul 2024
Direct Preference Optimization (DPO) introduces a method for fine-tuning large language models to align with human preferences that avoids the complexity of Reinforcement Learning from Human Feedback (RLHF). It reparameterizes the RLHF objective, allowing direct policy optimization and matching or exceeding PPO-based methods in performance and stability across summarization and dialogue tasks.

05 Sep 2024

OpenVLA introduces a fully open-source, 7B-parameter Vision-Language-Action model that sets a new state of the art for generalist robot manipulation, outperforming larger closed-source models by 16.5% absolute success rate. The model also demonstrates effective and efficient fine-tuning strategies for adapting to new robot setups and tasks on commodity hardware.

30 Jul 2025
Researchers from Tsinghua University, Stanford University, and the Max Planck Institute for Informatics developed a deterministic algorithm for the single-source shortest path problem on directed graphs with non-negative real edge weights. The algorithm achieves O(m log^(2/3) n) time complexity, marking the first time the long-standing O(m + n log n) sorting barrier has been surpassed in the comparison-addition model for this problem.

02 Oct 2025

The RLAD framework enables large language models to self-discover and leverage high-level reasoning abstractions, leading to substantial improvements in accuracy and compute efficiency on challenging mathematical reasoning tasks. This approach teaches models to propose and utilize concise procedural and factual knowledge to guide complex problem-solving.

20 Nov 2025
Agent0, developed by researchers at UNC-Chapel Hill, Salesforce Research, and Stanford University, introduces a fully autonomous framework for evolving high-performing LLM agents from scratch, without human-curated data. The system achieves substantial improvements, such as an 18% increase in mathematical reasoning and a 24% boost in general reasoning for Qwen3-8B-Base models, through a co-evolutionary loop and tool-integrated learning.

23 Feb 2024
Co-Supervised Learning: Improving Weak-to-Strong Generalization with Hierarchical Mixture of Experts
Co-Supervised Learning: Improving Weak-to-Strong Generalization with Hierarchical Mixture of Experts
The Co-Supervised Learning (CSL) framework enhances weak-to-strong generalization by leveraging a hierarchical mixture of specialized weak teachers and an iterative, student-guided assignment process. This approach, which also incorporates a conservative noise reduction mechanism, achieves over 15% improvement in Performance Gap Recovery (PGR) on ImageNet and 17% PGR on DomainNet compared to vanilla single-teacher methods.

31 Jan 2024
RAPTOR, developed by researchers at Stanford University, introduces a method for creating a hierarchical tree-structured index of documents to improve retrieval for large language models. This approach enables the retrieval of information at various levels of abstraction, leading to superior performance on challenging long-document question-answering tasks.

29 Feb 2024
The Spectral Manifold Alignment and Inference (SMAI) framework enables principled and interpretable integration of single-cell data by first rigorously assessing dataset alignability and then applying a structure-preserving alignment. This approach reduces data distortion, improves the reliability of downstream analyses such as differential expression and spatial gene prediction, and provides a clear, quantitative interpretation of batch effects as combinations of scaling, translation, and rotation.
19 Sep 2025

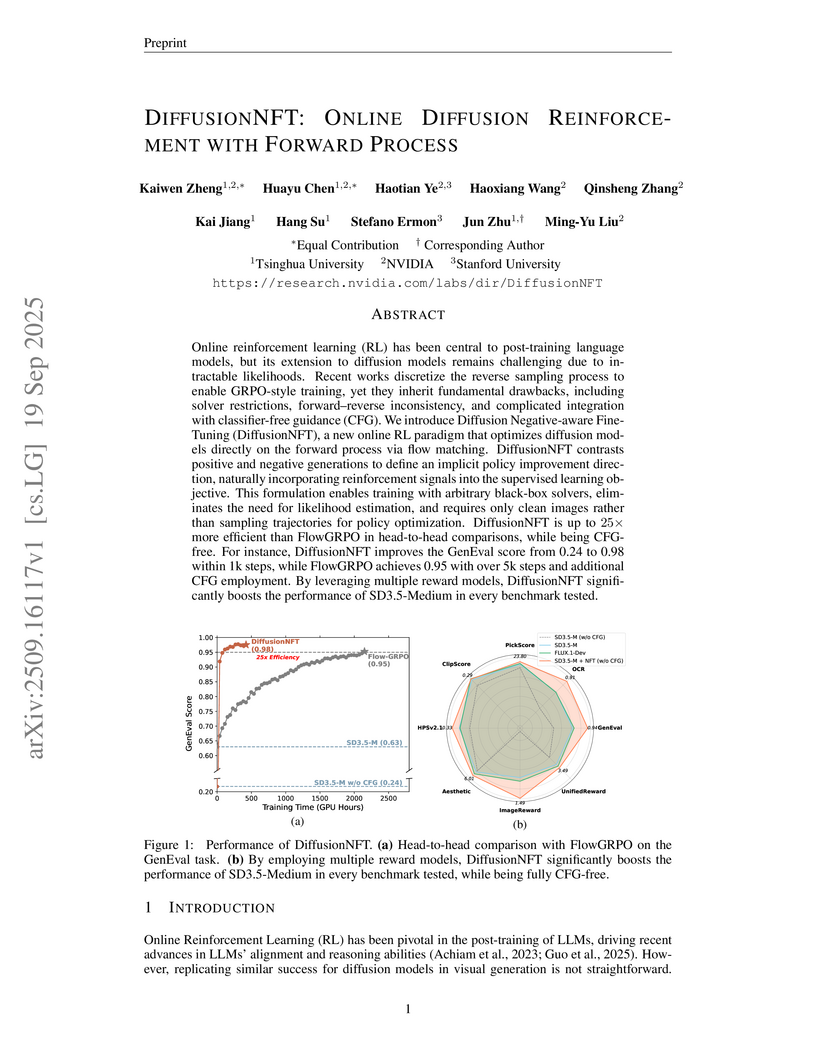
DiffusionNFT presents an online reinforcement learning framework that optimizes diffusion models on the forward process through negative-aware fine-tuning. This method achieves 3x to 25x higher efficiency than previous state-of-the-art methods and significantly improves image generation quality and alignment, notably enabling Classifier-Free Guidance-free operation.

06 Nov 2025

Researchers from NYU and Stanford introduce a "spatial supersensing" hierarchy for video-based Multimodal Large Language Models (MLLMs) and new VSI-SUPER benchmarks to reveal current models' limitations in genuine spatial and temporal reasoning. They develop Cambrian-S, a specialized MLLM trained on a large spatial dataset achieving state-of-the-art on VSI-Bench, and prototype a "predictive sensing" paradigm that leverages prediction error ("surprise") to robustly improve memory management and event segmentation in arbitrarily long videos.
07 Oct 2025


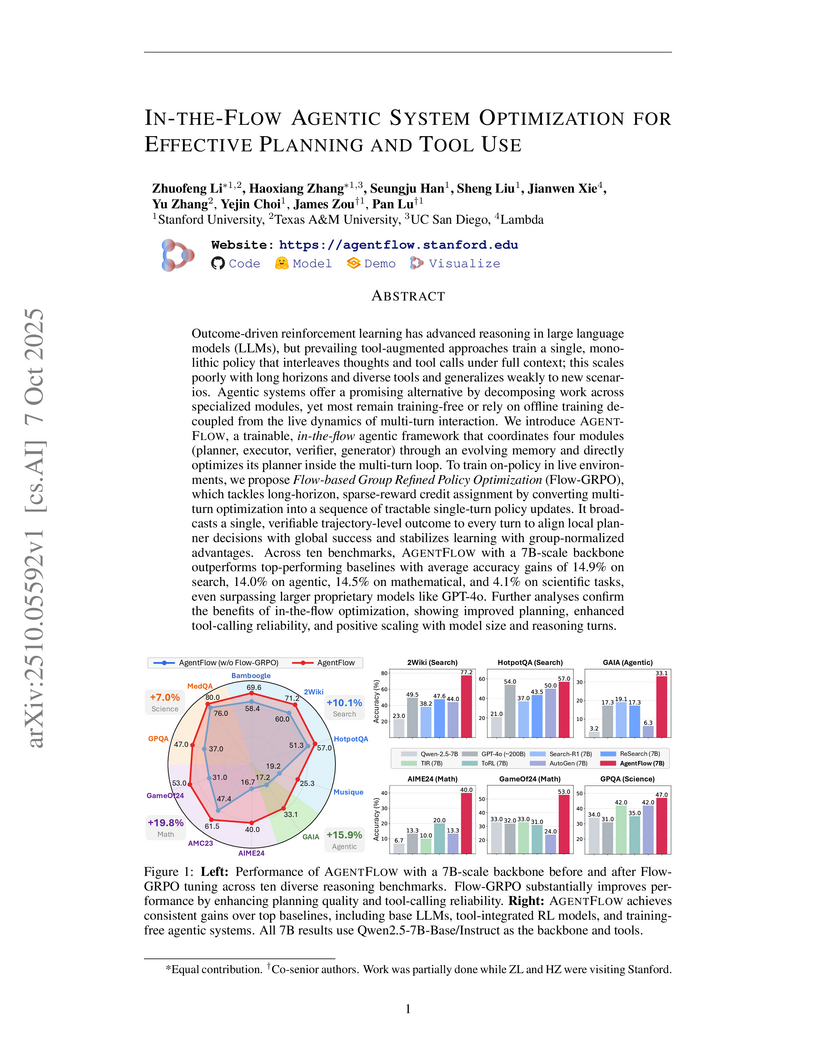
AGENTFLOW introduces a trainable agentic framework for large language models that integrates specialized modules with in-the-flow reinforcement learning for effective planning and tool use. Utilizing a 7B-scale backbone, this system surpassed GPT-4o's performance across diverse complex reasoning tasks.

24 Jun 2022
FlashAttention, developed at Stanford's Hazy Research lab, introduces an exact attention algorithm that optimizes memory access patterns to mitigate the IO bottleneck on GPUs. This method achieves substantial speedups and reduces memory footprint for Transformer models, enabling processing of significantly longer sequence lengths.

27 Oct 2024

Researchers introduce spectral regularization, a method that maintains neural network plasticity and trainability by explicitly controlling the spectral norms of layer weights. This technique consistently improved performance in diverse continual supervised and reinforcement learning tasks while demonstrating robustness across various non-stationarities and reduced hyperparameter sensitivity.

23 May 2024


Researchers from Fudan University and Shanghai AI Laboratory introduce "Make-it-Real," a framework that leverages GPT-4V to automatically paint 3D objects with realistic materials from albedo-only inputs. It generates a full suite of SVBRDF maps, achieving up to 77.8% human user preference and 84.8% GPT evaluation preference for refined objects over unrefined ones, significantly enhancing visual authenticity.

02 Dec 2024

Researchers from the Stanford Center for Artificial Intelligence in Medicine and Imaging present a comprehensive guide outlining best practices for integrating Large Language Models (LLMs) into radiology workflows. The work synthesizes technical foundations, identifies critical applications and challenges, and recommends strategies for responsible development, evaluation, and deployment, emphasizing techniques like Retrieval-Augmented Generation for improved factual accuracy and safety.

11 Mar 2024

This research develops a method for robots to generate high-level semantic region maps of indoor environments (e.g., "kitchen," "bedroom") without relying on explicit object recognition. The approach adapts Vision-Language Models for embodied perception, outperforming object-based and traditional scene classification baselines in online mapping.

11 Apr 2024

Researchers from Stanford University and NVIDIA developed a contact retargeting framework that enables one-shot transfer of long-horizon extrinsic manipulation skills to diverse objects and environments. This method achieved an 80.5% success rate on hardware across various complex tasks, significantly outperforming prior reinforcement learning approaches by effectively generalizing from a single human demonstration.
There are no more papers matching your filters at the moment.
