
28 Oct 2024
Network analysis is increasingly important across various fields, including the fragrance industry, where perfumes are represented as nodes and shared user preferences as edges in perfume networks. Community detection can uncover clusters of similar perfumes, providing insights into consumer preferences, enhancing recommendation systems, and informing targeted marketing strategies.
This study aims to apply community detection techniques to group perfumes favored by users into relevant clusters for better recommendations. We constructed a bipartite network from user reviews on the Persian retail platform "Atrafshan," with nodes representing users and perfumes, and edges formed by positive comments. This network was transformed into a Perfume Co-Preference Network, connecting perfumes liked by the same users. By applying community detection algorithms, we identified clusters based on shared preferences, enhancing our understanding of user sentiment in the fragrance market.
To improve sentiment analysis, we integrated emojis and a user voting system for greater accuracy. Emojis, aligned with their Persian counterparts, captured the emotional tone of reviews, while user ratings for scent, longevity, and sillage refined sentiment classification. Edge weights were adjusted by combining adjacency values with user ratings in a 60:40 ratio, reflecting both connection strength and user preferences. These enhancements led to improved modularity of detected communities, resulting in more accurate perfume groupings.
This research pioneers the use of community detection in perfume networks, offering new insights into consumer preferences. Our advancements in sentiment analysis and edge weight refinement provide actionable insights for optimizing product recommendations and marketing strategies in the fragrance industry.

05 Jun 2024


Sequence modeling plays a vital role across various domains, with recurrent neural networks being historically the predominant method of performing these tasks. However, the emergence of transformers has altered this paradigm due to their superior performance. Built upon these advances, transformers have conjoined CNNs as two leading foundational models for learning visual representations. However, transformers are hindered by the complexity of their attention mechanisms, while CNNs lack global receptive fields and dynamic weight allocation. State Space Models (SSMs), specifically the \textit{\textbf{Mamba}} model with selection mechanisms and hardware-aware architecture, have garnered immense interest lately in sequential modeling and visual representation learning, challenging the dominance of transformers by providing infinite context lengths and offering substantial efficiency maintaining linear complexity in the input sequence. Capitalizing on the advances in computer vision, medical imaging has heralded a new epoch with Mamba models. Intending to help researchers navigate the surge, this survey seeks to offer an encyclopedic review of Mamba models in medical imaging. Specifically, we start with a comprehensive theoretical review forming the basis of SSMs, including Mamba architecture and its alternatives for sequence modeling paradigms in this context. Next, we offer a structured classification of Mamba models in the medical field and introduce a diverse categorization scheme based on their application, imaging modalities, and targeted organs. Finally, we summarize key challenges, discuss different future research directions of the SSMs in the medical domain, and propose several directions to fulfill the demands of this field. In addition, we have compiled the studies discussed in this paper along with their open-source implementations on our GitHub repository.

09 Nov 2024
Medical image segmentation involves identifying and separating object instances in a medical image to delineate various tissues and structures, a task complicated by the significant variations in size, shape, and density of these features. Convolutional neural networks (CNNs) have traditionally been used for this task but have limitations in capturing long-range dependencies. Transformers, equipped with self-attention mechanisms, aim to address this problem. However, in medical image segmentation it is beneficial to merge both local and global features to effectively integrate feature maps across various scales, capturing both detailed features and broader semantic elements for dealing with variations in structures. In this paper, we introduce MSANet, a new deep segmentation framework featuring an expedient design of skip-connections. These connections facilitate feature fusion by dynamically weighting and combining coarse-grained encoder features with fine-grained decoder feature maps. Specifically, we propose a Multi-Scale Adaptive Spatial Attention Gate (MASAG), which dynamically adjusts the receptive field (Local and Global contextual information) to ensure that spatially relevant features are selectively highlighted while minimizing background distractions. Extensive evaluations involving dermatology, and radiological datasets demonstrate that our MSANet outperforms state-of-the-art (SOTA) works or matches their performance. The source code is publicly available at this https URL.

14 Sep 2025
In this paper, we investigate the structural and characterizing properties of the so-called {\it 2-UQ rings}, that are rings such that the square of every unit is the sum of an idempotent and a quasi-nilpotent element that commute with each other. We establish some fundamental connections between 2-UQ rings and relevant widely classes of rings including 2-UJ, 2-UU and tripotent rings. Our novel results include: (1) complete characterizations of 2-UQ group rings, showing that they force underlying groups to be either 2-groups or 3-groups when ; (2) Morita context extensions preserving the 2-UQ property when trace ideals are nilpotent; and (3) the discovery that potent 2-UQ rings are precisely the semi-tripotent rings. Furthermore, we determine how the 2-UQ property interacts with the regularity, cleanness and potent conditions. Likewise, certain examples and counter-examples illuminate the boundaries between 2-UQ rings and their special relatives.
These achievements of ours somewhat substantially expand those obtained by Cui-Yin in Commun. Algebra (2020) and by Danchev {\it et al.} in J. Algebra \& Appl. (2025).

23 May 2025
Medical image segmentation, particularly in multi-domain scenarios, requires
precise preservation of anatomical structures across diverse representations.
While deep learning has advanced this field, existing models often struggle
with accurate boundary representation, variability in organ morphology, and
information loss during downsampling, limiting their accuracy and robustness.
To address these challenges, we propose the Context Enhancement Network
(CENet), a novel segmentation framework featuring two key innovations. First,
the Dual Selective Enhancement Block (DSEB) integrated into skip connections
enhances boundary details and improves the detection of smaller organs in a
context-aware manner. Second, the Context Feature Attention Module (CFAM) in
the decoder employs a multi-scale design to maintain spatial integrity, reduce
feature redundancy, and mitigate overly enhanced representations. Extensive
evaluations on both radiology and dermoscopic datasets demonstrate that CENet
outperforms state-of-the-art (SOTA) methods in multi-organ segmentation and
boundary detail preservation, offering a robust and accurate solution for
complex medical image analysis tasks. The code is publicly available at
this https URL

07 Oct 2025
In financial mathematics, the calculation of the Greeks, especially the delta, is emphasized due to its role in risk management. In this article, we employ Malliavin calculus to determine the delta of European and Asian options, where the underlying asset evolves according to a Hawkes jump-diffusion process. A central feature is that the Hawkes jump intensity is stochastic, which substantially affects the delta representation.

15 Jul 2025
Training deep neural networks, particularly in computer vision tasks, often suffers from noisy gradients and unstable convergence, which hinder performance and generalization. In this paper, we propose LyAm, a novel optimizer that integrates Adam's adaptive moment estimation with Lyapunov-based stability mechanisms. LyAm dynamically adjusts the learning rate using Lyapunov stability theory to enhance convergence robustness and mitigate training noise. We provide a rigorous theoretical framework proving the convergence guarantees of LyAm in complex, non-convex settings. Extensive experiments on like as CIFAR-10 and CIFAR-100 show that LyAm consistently outperforms state-of-the-art optimizers in terms of accuracy, convergence speed, and stability, establishing it as a strong candidate for robust deep learning optimization.
08 Aug 2022

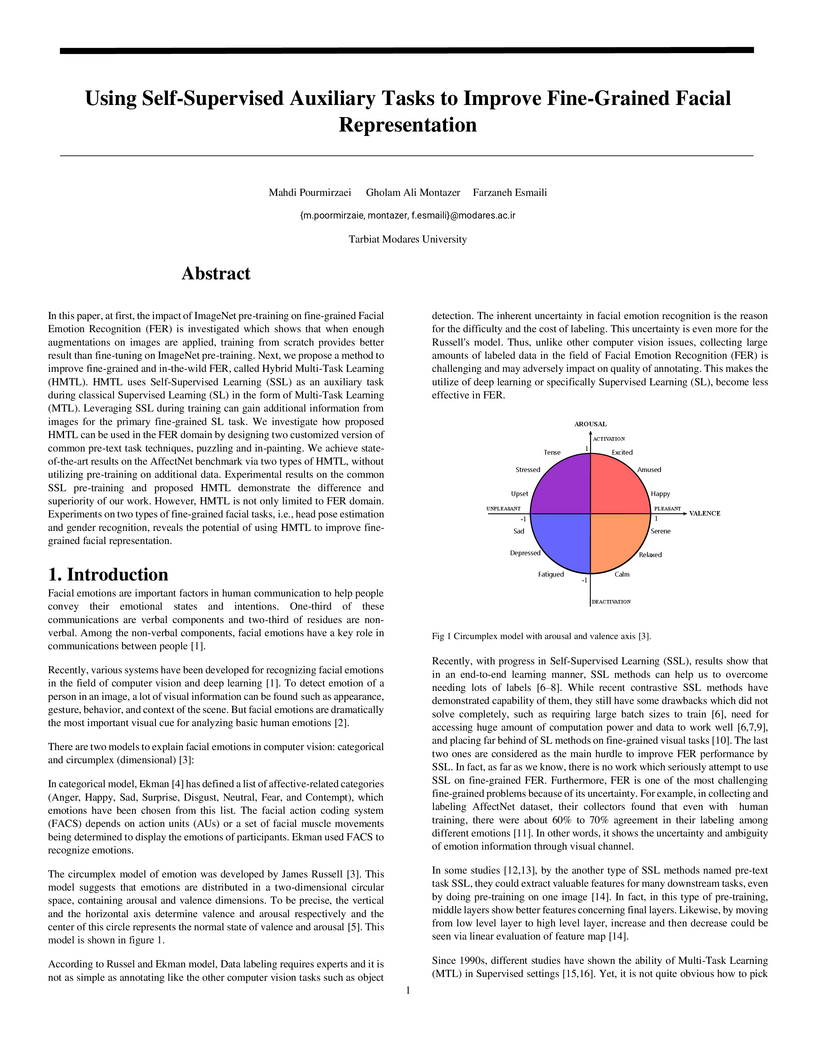
In this paper, at first, the impact of ImageNet pre-training on fine-grained Facial Emotion Recognition (FER) is investigated which shows that when enough augmentations on images are applied, training from scratch provides better result than fine-tuning on ImageNet pre-training. Next, we propose a method to improve fine-grained and in-the-wild FER, called Hybrid Multi-Task Learning (HMTL). HMTL uses Self-Supervised Learning (SSL) as an auxiliary task during classical Supervised Learning (SL) in the form of Multi-Task Learning (MTL). Leveraging SSL during training can gain additional information from images for the primary fine-grained SL task. We investigate how proposed HMTL can be used in the FER domain by designing two customized version of common pre-text task techniques, puzzling and in-painting. We achieve state-of-the-art results on the AffectNet benchmark via two types of HMTL, without utilizing pre-training on additional data. Experimental results on the common SSL pre-training and proposed HMTL demonstrate the difference and superiority of our work. However, HMTL is not only limited to FER domain. Experiments on two types of fine-grained facial tasks, i.e., head pose estimation and gender recognition, reveals the potential of using HMTL to improve fine-grained facial representation.

20 Aug 2025
The rapid expansion of the fashion industry and the growing variety of products have made it increasingly challenging for users to identify compatible items on e-commerce platforms. Effective fashion recommendation systems are therefore crucial for filtering irrelevant options and suggesting suitable ones. However, simultaneously addressing outfit compatibility and personalized recommendations remains a significant challenge, as these aspects are typically treated independently in existing studies, thereby overlooking the complex interactions between items and user preferences. This research introduces a new framework named FGAT, which leverages a hierarchical graph representation together with graph attention mechanisms to address this problem. The framework constructs a three-tier graph of users, outfits, and items, integrating visual and textual features to jointly model outfit compatibility and user preferences. By dynamically weighting node importance during representation propagation, the graph attention mechanism captures key interactions and produces precise embeddings for both user preferences and outfit compatibility. Evaluated on the POG dataset, FGAT outperforms strong baselines such as HFGN, achieving notable improvements in accuracy, precision, HR, recall, and NDCG. These results demonstrate that combining multimodal visual and textual features with a hierarchical graph structure and attention mechanisms significantly enhances the effectiveness and efficiency of personalized fashion recommendation systems.

17 Mar 2024
Recently, there has been a growing interest in the use of deep learning
techniques for tasks in natural language processing (NLP), with sentiment
analysis being one of the most challenging areas, particularly in the Persian
language. The vast amounts of content generated by Persian users on thousands
of websites, blogs, and social networks such as Telegram, Instagram, and
Twitter present a rich resource of information. Deep learning techniques have
become increasingly favored for extracting insights from this extensive pool of
raw data, although they face several challenges. In this study, we introduced
and implemented a hybrid deep learning-based model for sentiment analysis,
using customer review data from the Digikala Online Retailer website. We
employed a variety of deep learning networks and regularization techniques as
classifiers. Ultimately, our hybrid approach yielded an impressive performance,
achieving an F1 score of 78.3 across three sentiment categories: positive,
negative, and neutral.

28 Mar 2024

Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our \href{this https URL}{GitHub}\footnote{\url{this https URL}}. We aim to regularly update it with the most recent relevant papers.

08 Jul 2025
The two-dimensional MZ materials are proposed as suitable replacements for silicon channels in field-effect transistors (FETs). In the present work, the ThSiN monolayer from the family, with the very appropriate electron mobility, is thermally investigated using the non-equilibrium Monte Carlo simulation of the phonon Boltzmann transport equation. The reliability of the MOSFET with the ThSiN channel has been reassessed and determined to be low due to the high maximum temperature achieved. The phonon analysis is performed and reveals that the dominant contribution of fast and energetic LA and also slow and low energy ZA phonons alongside the minor participation of the TA phonons is responsible for the peak temperature rise reaching 800 K. This finding presents that the ThSiN monolayer is not a good candidate for replacing as silicon channel but alternatively is capable of generating a significant temperature gradient, which makes it, a suitable candidate for using as a thermoelectric material in thermoelectric generators.

13 Jan 2025
Bearing fault diagnosis under varying working conditions faces challenges, including a lack of labeled data, distribution discrepancies, and resource constraints. To address these issues, we propose a progressive knowledge distillation framework that transfers knowledge from a complex teacher model, utilizing a Graph Convolutional Network (GCN) with Autoregressive moving average (ARMA) filters, to a compact and efficient student model. To mitigate distribution discrepancies and labeling uncertainty, we introduce Enhanced Local Maximum Mean Squared Discrepancy (ELMMSD), which leverages mean and variance statistics in the Reproducing Kernel Hilbert Space (RKHS) and incorporates a priori probability distributions between labels. This approach increases the distance between clustering centers, bridges subdomain gaps, and enhances subdomain alignment reliability. Experimental results on benchmark datasets (CWRU and JNU) demonstrate that the proposed method achieves superior diagnostic accuracy while significantly reducing computational costs. Comprehensive ablation studies validate the effectiveness of each component, highlighting the robustness and adaptability of the approach across diverse working conditions.

08 Sep 2024
This paper presents a fast and cost-effective method for diagnosing cardiac abnormalities with high accuracy and reliability using low-cost systems in clinics. The primary limitation of automatic diagnosing of cardiac diseases is the rarity of correct and acceptable labeled samples, which can be expensive to prepare. To address this issue, two methods are proposed in this work. The first method is a unique Multi-Branch Deep Convolutional Neural Network (MBDCN) architecture inspired by human auditory processing, specifically designed to optimize feature extraction by employing various sizes of convolutional filters and audio signal power spectrum as input. In the second method, called as Long short-term memory-Convolutional Neural (LSCN) model, Additionally, the network architecture includes Long Short-Term Memory (LSTM) network blocks to improve feature extraction in the time domain. The innovative approach of combining multiple parallel branches consisting of the one-dimensional convolutional layers along with LSTM blocks helps in achieving superior results in audio signal processing tasks. The experimental results demonstrate superiority of the proposed methods over the state-of-the-art techniques. The overall classification accuracy of heart sounds with the LSCN network is more than 96%. The efficiency of this network is significant compared to common feature extraction methods such as Mel Frequency Cepstral Coefficients (MFCC) and wavelet transform. Therefore, the proposed method shows promising results in the automatic analysis of heart sounds and has potential applications in the diagnosis and early detection of cardiovascular diseases.

05 Jun 2023
Sparse Neural Networks (SNNs) can potentially demonstrate similar performance
to their dense counterparts while saving significant energy and memory at
inference. However, the accuracy drop incurred by SNNs, especially at high
pruning ratios, can be an issue in critical deployment conditions. While recent
works mitigate this issue through sophisticated pruning techniques, we shift
our focus to an overlooked factor: hyperparameters and activation functions.
Our analyses have shown that the accuracy drop can additionally be attributed
to (i) Using ReLU as the default choice for activation functions unanimously,
and (ii) Fine-tuning SNNs with the same hyperparameters as dense counterparts.
Thus, we focus on learning a novel way to tune activation functions for sparse
networks and combining these with a separate hyperparameter optimization (HPO)
regime for sparse networks. By conducting experiments on popular DNN models
(LeNet-5, VGG-16, ResNet-18, and EfficientNet-B0) trained on MNIST, CIFAR-10,
and ImageNet-16 datasets, we show that the novel combination of these two
approaches, dubbed Sparse Activation Function Search, short: SAFS, results in
up to 15.53%, 8.88%, and 6.33% absolute improvement in the accuracy for
LeNet-5, VGG-16, and ResNet-18 over the default training protocols, especially
at high pruning ratios. Our code can be found at this https URL

08 Jan 2025
This paper examines the specific obstacles of constructing Retrieval-Augmented Generation(RAG) systems in low-resource languages, with a focus on Persian's complicated morphology and versatile syntax. The research aims to improve retrieval and generation accuracy by introducing Persian-specific models, namely MatinaRoberta(a masked language model) and MatinaSRoberta(a fine-tuned Sentence-BERT), along with a comprehensive benchmarking framework. Three datasets-general knowledge(PQuad), scientifically specialized texts, and organizational reports, were used to assess these models after they were trained on a varied corpus of 73.11 billion Persian tokens. The methodology involved extensive pretraining, fine-tuning with tailored loss functions, and systematic evaluations using both traditional metrics and the Retrieval-Augmented Generation Assessment framework. The results show that MatinaSRoberta outperformed previous embeddings, achieving superior contextual relevance and retrieval accuracy across datasets. Temperature tweaking, chunk size modifications, and document summary indexing were explored to enhance RAG setups. Larger models like Llama-3.1 (70B) consistently demonstrated the highest generation accuracy, while smaller models faced challenges with domain-specific and formal contexts. The findings underscore the potential for developing RAG systems in Persian through customized embeddings and retrieval-generation settings and highlight the enhancement of NLP applications such as search engines and legal document analysis in low-resource languages.

18 Aug 2025
In this paper, we consider the jumps in the complexity growth rate (CGR) through the complexity=anything proposal. It is revealed that bulk fields are in charge of the height and the location of these jumps. To put it accurately, their counterparts are divergence of energy momentum tensor, shear viscosity and the Weyl anomaly of the boundary theory. The behavior of CGR around these jumps manifests a critical behavior and critical exponents. Moreover, it is figured out that CGR satisfies a Callan-Symanzik-like equation around these jumps. This equation suggests that the speed of information processing could be changed by the scale of energy. Put it another way, by change of the scale of energy one could turn the classical computers into faster processor computers even faster than our current quantum computers.

03 Sep 2024
The lack of a suitable tool for the analysis of conversational texts in the
Persian language has made various analyses of these texts, including Sentiment
Analysis, difficult. In this research, we tried to make the understanding of
these texts easier for the machine by providing PSC, Persian Slang Converter, a
tool for converting conversational texts into formal ones, and by using the
most up-to-date and best deep learning methods along with the PSC, the
sentiment learning of short Persian language texts for the machine in a better
way. be made More than 10 million unlabeled texts from various social networks
and movie subtitles (as Conversational texts) and about 10 million news texts
(as formal texts) have been used for training unsupervised models and formal
implementation of the tool. 60,000 texts from the comments of Instagram social
network users with positive, negative, and neutral labels are considered
supervised data for training the emotion classification model of short texts.
Using the formal tool, 57% of the words of the corpus of conversation were
converted. Finally, by using the formalizer, FastText model, and deep LSTM
network, an accuracy of 81.91 was obtained on the test data.

26 Jun 2023
Background: People's health depends on the use of proper diet as an important factor. Today, with the increasing mechanization of people's lives, proper eating habits and behaviors are neglected. On the other hand, food recommendations in the field of health have also tried to deal with this issue. But with the introduction of the Western nutrition style and the advancement of Western chemical medicine, many issues have emerged in the field of disease treatment and nutrition. Recent advances in technology and the use of artificial intelligence methods in information systems have led to the creation of recommender systems in order to improve people's health. Methods: A hybrid recommender system including, collaborative filtering, content-based, and knowledge-based models was used. Machine learning models such as Decision Tree, k-Nearest Neighbors (kNN), AdaBoost, and Bagging were investigated in the field of food recommender systems on 2519 students in the nutrition management system of a university. Student information including profile information for basal metabolic rate, student reservation records, and selected diet type is received online. Among the 15 features collected and after consulting nutrition experts, the most effective features are selected through feature engineering. Using machine learning models based on energy indicators and food selection history by students, food from the university menu is recommended to students. Results: The AdaBoost model has the highest performance in terms of accuracy with a rate of 73.70 percent. Conclusion: Considering the importance of diet in people's health, recommender systems are effective in obtaining useful information from a huge amount of data. Keywords: Recommender system, Food behavior and habits, Machine learning, Classification

28 Oct 2022
Stereo Matching is one of the classical problems in computer vision for the extraction of 3D information but still controversial for accuracy and processing costs. The use of matching techniques and cost functions is crucial in the development of the disparity map. This paper presents a comparative study of six different stereo matching algorithms including Block Matching (BM), Block Matching with Dynamic Programming (BMDP), Belief Propagation (BP), Gradient Feature Matching (GF), Histogram of Oriented Gradient (HOG), and the proposed method. Also three cost functions namely Mean Squared Error (MSE), Sum of Absolute Differences (SAD), Normalized Cross-Correlation (NCC) were used and compared. The stereo images used in this study were from the Middlebury Stereo Datasets provided with perfect and imperfect calibrations. Results show that the selection of matching function is quite important and also depends on the images properties. Results showed that the BP algorithm in most cases provided better results getting accuracies over 95%.
There are no more papers matching your filters at the moment.
