
30 Jan 2024


The TWIST method initializes speech language models (SpeechLMs) with weights from pretrained textual language models, improving their ability to process and generate spoken language. This approach enables training of the largest SpeechLMs to date and consistently outperforms randomly initialized models across various linguistic understanding benchmarks and human evaluations, while also requiring significantly less training data.

20 Mar 2025



A survey provides the first comprehensive mapping of evaluation methodologies for LLM-based agents, categorizing benchmarks across fundamental capabilities and application-specific domains. It highlights the field's shift towards more realistic and live evaluation, while identifying critical needs for granular metrics, cost efficiency, scalable automation, and robust safety assessments.
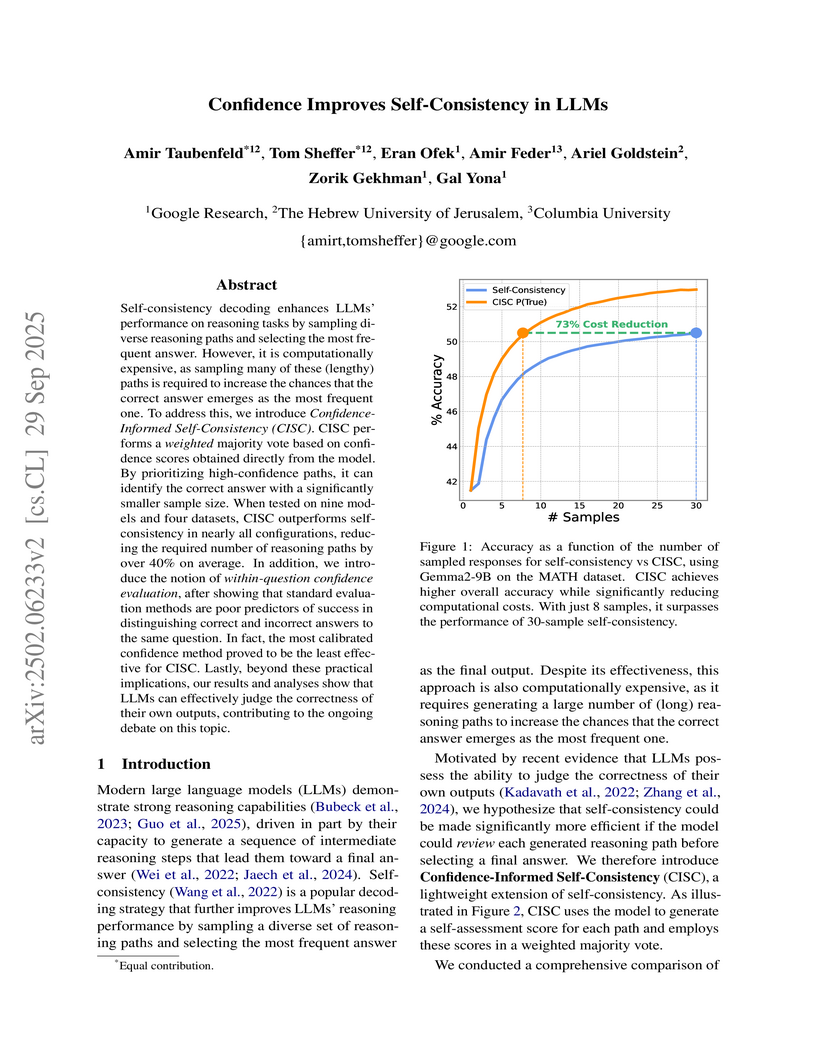
29 Sep 2025



Researchers at Google Research and The Hebrew University of Jerusalem developed Confidence-Informed Self-Consistency (CISC), a decoding strategy that integrates LLM-generated confidence scores into a weighted majority vote to enhance the efficiency of self-consistency. This method reduces the computational cost by over 40% on average, requiring fewer reasoning paths to match or exceed the accuracy of traditional self-consistency across various LLMs and benchmarks.

23 Oct 2025
Researchers at The Hebrew University of Jerusalem introduced DYPE, a training-free method that enables pre-trained Diffusion Transformers (DiTs) to generate images at ultra-high resolutions without additional training or inference overhead. It achieves this by dynamically adjusting positional encoding based on the spectral evolution of the diffusion process, leading to improved image fidelity and detail compared to static extrapolation techniques.

15 Mar 2025

Stable Flow introduces a training-free image editing method for Diffusion Transformer (DiT) models like FLUX and SD3, achieving consistent and diverse edits. It leverages an automated vital layer detection and selective attention injection mechanism, combined with a latent nudging technique for robust real-image inversion, outperforming existing baselines in user studies and quantitative metrics.

23 May 2025
Meta FAIR and Hebrew University researchers challenge the assumption that longer reasoning chains improve LLM performance by demonstrating that shorter thinking chains within the same question are up to 34.5% more accurate than longer ones across three leading reasoning models (Llama-3.3-Nemotron-Super-49B, R1-Distill-Qwen-32B, QwQ-32B) on AIME and HMMT math benchmarks, developing short-m@k—an inference method that generates k reasoning chains in parallel and selects answers via majority voting among the first m completed chains—which achieves comparable or superior accuracy while reducing computational costs by up to 50% and demonstrating that fine-tuning on shorter reasoning trajectories produces better performance than training on longer chains, suggesting that "overthinking" degrades reasoning quality in current LLMs.

06 Oct 2025



Large language models experience substantial drops in problem-solving accuracy as context length increases, regardless of retrieval efficacy or token-level distraction, with open-source models showing up to a 24.2% drop in MMLU accuracy despite 97% perfect retrieval.

27 Sep 2025






A collaborative research effort provides a comprehensive review and benchmark of discrete audio tokenizers, proposing a new multi-dimensional taxonomy and conducting controlled ablation studies across speech, music, and general audio domains. It evaluates tokenizers on reconstruction quality, downstream task performance, and acoustic language modeling, offering a unified framework for understanding their varied trade-offs and optimal applications.

03 Mar 2025

Researchers demonstrated that naturally occurring explicit feedback from user interactions with large language models is prevalent and extractable. The automatically collected feedback dataset, when used for finetuning and preference training, improved LLM alignment with human preferences, achieving human evaluation win rates up to 81.5% against pretrained models.

27 Mar 2024
Diffusion models have revolutionized image editing but often generate images that violate physical laws, particularly the effects of objects on the scene, e.g., occlusions, shadows, and reflections. By analyzing the limitations of self-supervised approaches, we propose a practical solution centered on a \q{counterfactual} dataset. Our method involves capturing a scene before and after removing a single object, while minimizing other changes. By fine-tuning a diffusion model on this dataset, we are able to not only remove objects but also their effects on the scene. However, we find that applying this approach for photorealistic object insertion requires an impractically large dataset. To tackle this challenge, we propose bootstrap supervision; leveraging our object removal model trained on a small counterfactual dataset, we synthetically expand this dataset considerably. Our approach significantly outperforms prior methods in photorealistic object removal and insertion, particularly at modeling the effects of objects on the scene.

25 Aug 2025


This research introduces and characterizes CHOKE (Certain Hallucinations Overriding Known Evidence), a category of LLM hallucinations where models confidently generate incorrect information despite possessing the correct knowledge. The study quantifies the prevalence of CHOKE across various models and datasets, demonstrates its distinct nature, and proposes a targeted mitigation strategy that outperforms existing methods in addressing this specific failure mode.

16 Oct 2025

In Omnimatte, one aims to decompose a given video into semantically meaningful layers, including the background and individual objects along with their associated effects, such as shadows and reflections. Existing methods often require extensive training or costly self-supervised optimization. In this paper, we present OmnimatteZero, a training-free approach that leverages off-the-shelf pre-trained video diffusion models for omnimatte. It can remove objects from videos, extract individual object layers along with their effects, and composite those objects onto new videos. These are accomplished by adapting zero-shot image inpainting techniques for video object removal, a task they fail to handle effectively out-of-the-box. To overcome this, we introduce temporal and spatial attention guidance modules that steer the diffusion process for accurate object removal and temporally consistent background reconstruction. We further show that self-attention maps capture information about the object and its footprints and use them to inpaint the object's effects, leaving a clean background. Additionally, through simple latent arithmetic, object layers can be isolated and recombined seamlessly with new video layers to produce new videos. Evaluations show that OmnimatteZero not only achieves superior performance in terms of background reconstruction but also sets a new record for the fastest Omnimatte approach, achieving real-time performance with minimal frame runtime.

12 Jul 2025
Large language models (LLMs) exhibit cognitive biases -- systematic tendencies of irrational decision-making, similar to those seen in humans. Prior work has found that these biases vary across models and can be amplified by instruction tuning. However, it remains unclear if these differences in biases stem from pretraining, finetuning, or even random noise due to training stochasticity. We propose a two-step causal experimental approach to disentangle these factors. First, we finetune models multiple times using different random seeds to study how training randomness affects over cognitive biases. Second, we introduce \emph{cross-tuning} -- swapping instruction datasets between models to isolate bias sources. This swap uses datasets that led to different bias patterns, directly testing whether biases are dataset-dependent. Our findings reveal that while training randomness introduces some variability, biases are mainly shaped by pretraining: models with the same pretrained backbone exhibit more similar bias patterns than those sharing only finetuning data. These insights suggest that understanding biases in finetuned models requires considering their pretraining origins beyond finetuning effects. This perspective can guide future efforts to develop principled strategies for evaluating and mitigating bias in LLMs.

10 Mar 2025
Researchers introduce and evaluate "jamming," a novel denial-of-service attack against Retrieval-Augmented Generation (RAG) systems. The attack leverages a single, intelligently crafted "blocker document" to cause the RAG system to refuse answering targeted queries, achieving up to a 73% success rate on Llama-3.1 8B and revealing that existing LLM safety benchmarks do not adequately capture this vulnerability.

20 Feb 2025
A method is introduced for structurally disentangling 3D semantic feature fields into view-dependent and view-independent components within a Neural Radiance Field framework. This approach enhances 3D segmentation accuracy and enables novel physically-aware 3D editing capabilities, such as manipulating reflections or material roughness.

30 Apr 2023
Blended Latent Diffusion adapts an existing blending technique to latent diffusion models, enabling local text-driven image editing that is 10-20 times faster and more precise than prior pixel-based approaches. This method produces seamless, high-fidelity edits by addressing challenges like imperfect VAE reconstruction and thin masks in latent space.

03 Jun 2025
Public model repositories now contain millions of models, yet most models
remain undocumented and effectively lost. In this position paper, we advocate
for charting the world's model population in a unified structure we call the
Model Atlas: a graph that captures models, their attributes, and the weight
transformations that connect them. The Model Atlas enables applications in
model forensics, meta-ML research, and model discovery, challenging tasks given
today's unstructured model repositories. However, because most models lack
documentation, large atlas regions remain uncharted. Addressing this gap
motivates new machine learning methods that treat models themselves as data,
inferring properties such as functionality, performance, and lineage directly
from their weights. We argue that a scalable path forward is to bypass the
unique parameter symmetries that plague model weights. Charting all the world's
models will require a community effort, and we hope its broad utility will
rally researchers toward this goal.
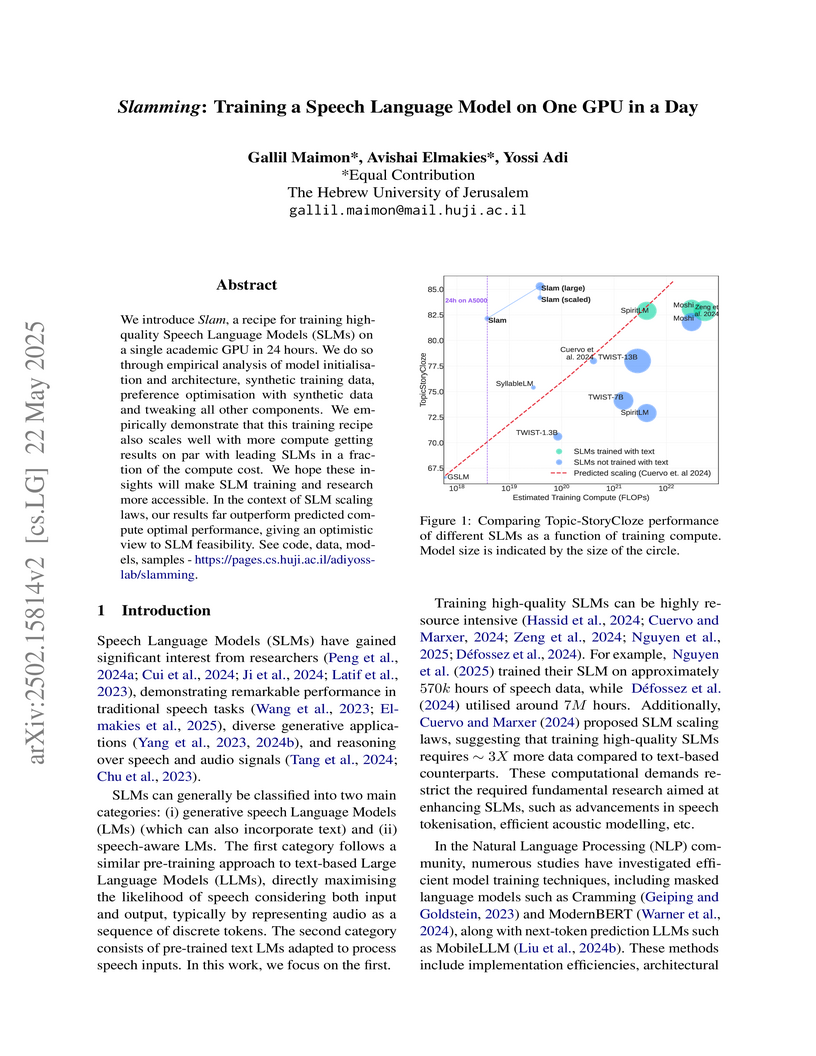
22 May 2025
The 'Slamming' recipe enables training high-quality Speech Language Models (SLMs) on a single NVIDIA A5000 GPU within 24 hours, achieving performance competitive with models requiring significantly more computational resources. This work provides an optimized framework that effectively democratizes access to cutting-edge SLM research.

04 Dec 2025
Large language models (LLMs) are increasingly deployed with hierarchical instruction schemes, where certain instructions (e.g., system-level directives) are expected to take precedence over others (e.g., user messages). Yet, we lack a systematic understanding of how effectively these hierarchical control mechanisms work. We introduce a systematic evaluation framework based on constraint prioritization to assess how well LLMs enforce instruction hierarchies. Our experiments across six state-of-the-art LLMs reveal that models struggle with consistent instruction prioritization, even for simple formatting conflicts. We find that the widely-adopted system/user prompt separation fails to establish a reliable instruction hierarchy, and models exhibit strong inherent biases toward certain constraint types regardless of their priority designation. Interestingly, we also find that societal hierarchy framings (e.g., authority, expertise, consensus) show stronger influence on model behavior than system/user roles, suggesting that pretraining-derived social structures function as latent behavioral priors with potentially greater impact than post-training guardrails.
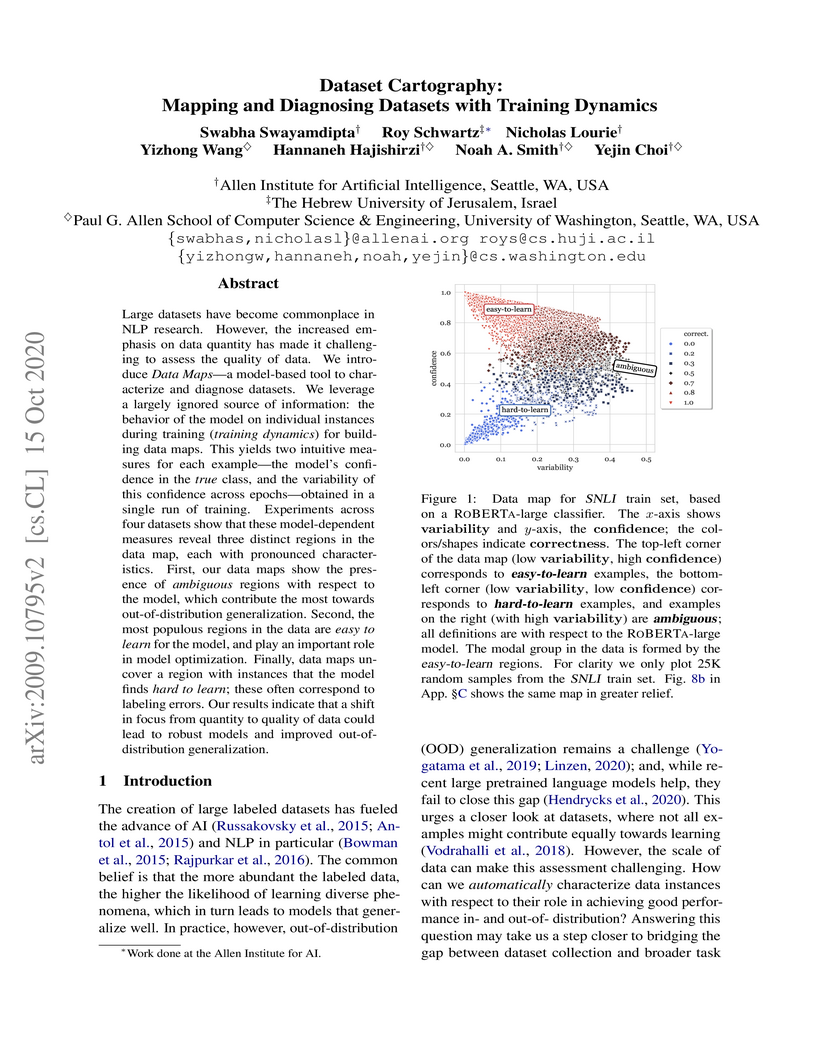
15 Oct 2020

Large datasets have become commonplace in NLP research. However, the
increased emphasis on data quantity has made it challenging to assess the
quality of data. We introduce Data Maps---a model-based tool to characterize
and diagnose datasets. We leverage a largely ignored source of information: the
behavior of the model on individual instances during training (training
dynamics) for building data maps. This yields two intuitive measures for each
example---the model's confidence in the true class, and the variability of this
confidence across epochs---obtained in a single run of training. Experiments
across four datasets show that these model-dependent measures reveal three
distinct regions in the data map, each with pronounced characteristics. First,
our data maps show the presence of "ambiguous" regions with respect to the
model, which contribute the most towards out-of-distribution generalization.
Second, the most populous regions in the data are "easy to learn" for the
model, and play an important role in model optimization. Finally, data maps
uncover a region with instances that the model finds "hard to learn"; these
often correspond to labeling errors. Our results indicate that a shift in focus
from quantity to quality of data could lead to robust models and improved
out-of-distribution generalization.
There are no more papers matching your filters at the moment.
