
17 Oct 2025
Researchers at The University of Electro-Communications demonstrate that an AI agent, when positioned as a co-persuadee that visibly accepts persuasion, can induce a conformity effect in human participants, leading to enhanced attitude change. An initial rapport-building session with the AI peer further amplifies this effect, while an unpersuaded AI can inhibit attitude change.

13 Jun 2025



In this paper, we introduce knowledge image generation as a new task,
alongside the Massive Multi-Discipline Multi-Tier Knowledge-Image Generation
Benchmark (MMMG) to probe the reasoning capability of image generation models.
Knowledge images have been central to human civilization and to the mechanisms
of human learning -- a fact underscored by dual-coding theory and the
picture-superiority effect. Generating such images is challenging, demanding
multimodal reasoning that fuses world knowledge with pixel-level grounding into
clear explanatory visuals. To enable comprehensive evaluation, MMMG offers
4,456 expert-validated (knowledge) image-prompt pairs spanning 10 disciplines,
6 educational levels, and diverse knowledge formats such as charts, diagrams,
and mind maps. To eliminate confounding complexity during evaluation, we adopt
a unified Knowledge Graph (KG) representation. Each KG explicitly delineates a
target image's core entities and their dependencies. We further introduce
MMMG-Score to evaluate generated knowledge images. This metric combines factual
fidelity, measured by graph-edit distance between KGs, with visual clarity
assessment. Comprehensive evaluations of 16 state-of-the-art text-to-image
generation models expose serious reasoning deficits -- low entity fidelity,
weak relations, and clutter -- with GPT-4o achieving an MMMG-Score of only
50.20, underscoring the benchmark's difficulty. To spur further progress, we
release FLUX-Reason (MMMG-Score of 34.45), an effective and open baseline that
combines a reasoning LLM with diffusion models and is trained on 16,000 curated
knowledge image-prompt pairs.

16 Jul 2025

Researchers from Kyoto University, The University of Tokyo, The University of Electro-Communications, and Ritsumeikan University propose that Large Language Models acquire their world knowledge by statistically approximating a "collective world model" implicitly encoded in human language, which itself emerges from the decentralized, embodied interactions of human society. This theoretical framework, called Generative Emergent Communication, explains LLM capabilities like distributional semantics as a reconstruction of this collective human understanding.

07 Oct 2025
Recent Human-object interaction detection (HOID) methods highly require prior knowledge from VLMs to enhance the interaction recognition capabilities. The training strategies and model architectures for connecting the knowledge from VLMs to the HOI instance representations from the object detector are challenging, and the whole framework is complex for further development or application. On the other hand, the inherent reasoning abilities of MLLMs on human-object interaction detection are under-explored. Inspired by the recent success of training MLLMs with reinforcement learning (RL) methods, we propose HOI-R1 and first explore the potential of the language model on the HOID task without any additional detection modules. We introduce an HOI reasoning process and HOID reward functions to solve the HOID task by pure text. The results on the HICO-DET dataset show that HOI-R1 achieves 2x the accuracy of the baseline with great generalization ability. The source code is available at this https URL.

14 Jan 2023
 the University of TokyoKeio University
the University of TokyoKeio University Queen Mary University of LondonThe University of Electro-CommunicationsRitsumeikan UniversityUniversity of EssexDonders Institute for Brain, Cognition, and BehaviourBogazici UniversityNational Autonomous University of MexicoCajal International Neuroscience CenterUniversità Milano-BicoccaUniversidad Autónoma del Estado de MorelosInstitute of Cognitive Sciences and Technologies, National Research Council of Italy
Queen Mary University of LondonThe University of Electro-CommunicationsRitsumeikan UniversityUniversity of EssexDonders Institute for Brain, Cognition, and BehaviourBogazici UniversityNational Autonomous University of MexicoCajal International Neuroscience CenterUniversità Milano-BicoccaUniversidad Autónoma del Estado de MorelosInstitute of Cognitive Sciences and Technologies, National Research Council of Italy
An international consortium of researchers provides a comprehensive survey unifying the concepts of world models from AI and predictive coding from neuroscience, highlighting their shared principles for how agents build and use internal representations to predict and interact with their environment. The paper outlines six key research frontiers for integrating these two fields to advance cognitive and developmental robotics, offering a roadmap for creating more intelligent and adaptable robots.

18 Sep 2025

The minimum sum coloring problem with bundles was introduced by Darbouy and Friggstad (SWAT 2024) as a common generalization of the minimum coloring problem and the minimum sum coloring problem. During their presentation, the following open problem was raised: whether the minimum sum coloring problem with bundles could be solved in polynomial time for trees. We answer their question in the negative by proving that the minimum sum coloring problem with bundles is NP-hard even for paths. We complement this hardness by providing algorithms of the following types. First, we provide a fixed-parameter algorithm for trees when the number of bundles is a parameter; this can be extended to graphs of bounded treewidth. Second, we provide a polynomial-time algorithm for trees when bundles form a partition of the vertex set and the difference between the number of vertices and the number of bundles is constant. Third, we provide a polynomial-time algorithm for trees when bundles form a partition of the vertex set and each bundle induces a connected subgraph. We further show that for bipartite graphs, the problem with weights is NP-hard even when the number of bundles is at least three, but is polynomial-time solvable when the number of bundles is at most two. The threshold shifts to three versus four for the problem without weights.

13 Oct 2025
SceneTextStylizer introduces a training-free framework that applies arbitrary styles to text within scene images using a pre-trained diffusion model and natural language prompts. The framework generates high-fidelity stylized text while preserving its readability and the original background, outperforming existing methods in qualitative and quantitative evaluations.

01 Oct 2025
Graph states are entangled states that are essential for quantum information processing, including measurement-based quantum computation. As experimental advances enable the realization of large-scale graph states, efficient fidelity estimation methods are crucial for assessing their robustness against noise. However, calculations of exact fidelity become intractable for large systems due to the exponential growth in the number of stabilizers. In this work, we show that the fidelity between any ideal graph state and its noisy counterpart under IID Pauli noise can be mapped to the partition function of a classical spin system, enabling efficient computation via statistical mechanical techniques, including transfer matrix methods and Monte Carlo simulations. Using this approach, we analyze the fidelity for regular graph states under depolarizing noise and uncover the emergence of phase transitions in fidelity between the pure-state regime and the noise-dominated regime governed by both the connectivity (degree) and spatial dimensionality of the graph state. Specifically, in 2D, phase transitions occur only when the degree satisfies , while in 3D they already appear at . However, for graph states with excessively high degree, such as fully connected graphs, the phase transition disappears, suggesting that extreme connectivity suppresses critical behavior. These findings reveal that robustness of graph states against noise is determined by their connectivity and spatial dimensionality. Graph states with lower degree and/or dimensionality, which exhibit a smooth crossover rather than a sharp transition, demonstrate greater robustness, while highly connected or higher-dimensional graph states are more fragile. Extreme connectivity, as the fully connected graph state possesses, restores robustness.

26 Jul 2025

Dynamic Facial Expression Recognition (DFER) plays a critical role in affective computing and human-computer interaction. Although existing methods achieve comparable performance, they inevitably suffer from performance degradation under sample heterogeneity caused by multi-source data and individual expression variability. To address these challenges, we propose a novel framework, called Heterogeneity-aware Distributional Framework (HDF), and design two plug-and-play modules to enhance time-frequency modeling and mitigate optimization imbalance caused by hard samples. Specifically, the Time-Frequency Distributional Attention Module (DAM) captures both temporal consistency and frequency robustness through a dual-branch attention design, improving tolerance to sequence inconsistency and visual style shifts. Then, based on gradient sensitivity and information bottleneck principles, an adaptive optimization module Distribution-aware Scaling Module (DSM) is introduced to dynamically balance classification and contrastive losses, enabling more stable and discriminative representation learning. Extensive experiments on two widely used datasets, DFEW and FERV39k, demonstrate that HDF significantly improves both recognition accuracy and robustness. Our method achieves superior weighted average recall (WAR) and unweighted average recall (UAR) while maintaining strong generalization across diverse and imbalanced scenarios. Codes are released at this https URL.

12 Jul 2025
Human pose estimation traditionally relies on architectures that encode keypoint priors, limiting their generalization to novel poses or unseen keypoints. Recent language-guided approaches like LocLLM reformulate keypoint localization as a vision-language task, enabling zero-shot generalization through textual descriptions. However, LocLLM's linear projector fails to capture complex spatial-textual interactions critical for high-precision localization. To address this, we propose PoseLLM, the first Large Language Model (LLM)-based pose estimation framework that replaces the linear projector with a nonlinear MLP vision-language connector. This lightweight two-layer MLP with GELU activation enables hierarchical cross-modal feature transformation, enhancing the fusion of visual patches and textual keypoint descriptions. Trained exclusively on COCO data, PoseLLM achieves 77.8 AP on the COCO validation set, outperforming LocLLM by +0.4 AP, while maintaining strong zero-shot generalization on Human-Art and MPII. Our work demonstrates that a simple yet powerful nonlinear connector significantly boosts localization accuracy without sacrificing generalization, advancing the state-of-the-art in language-guided pose estimation. Code is available at this https URL.
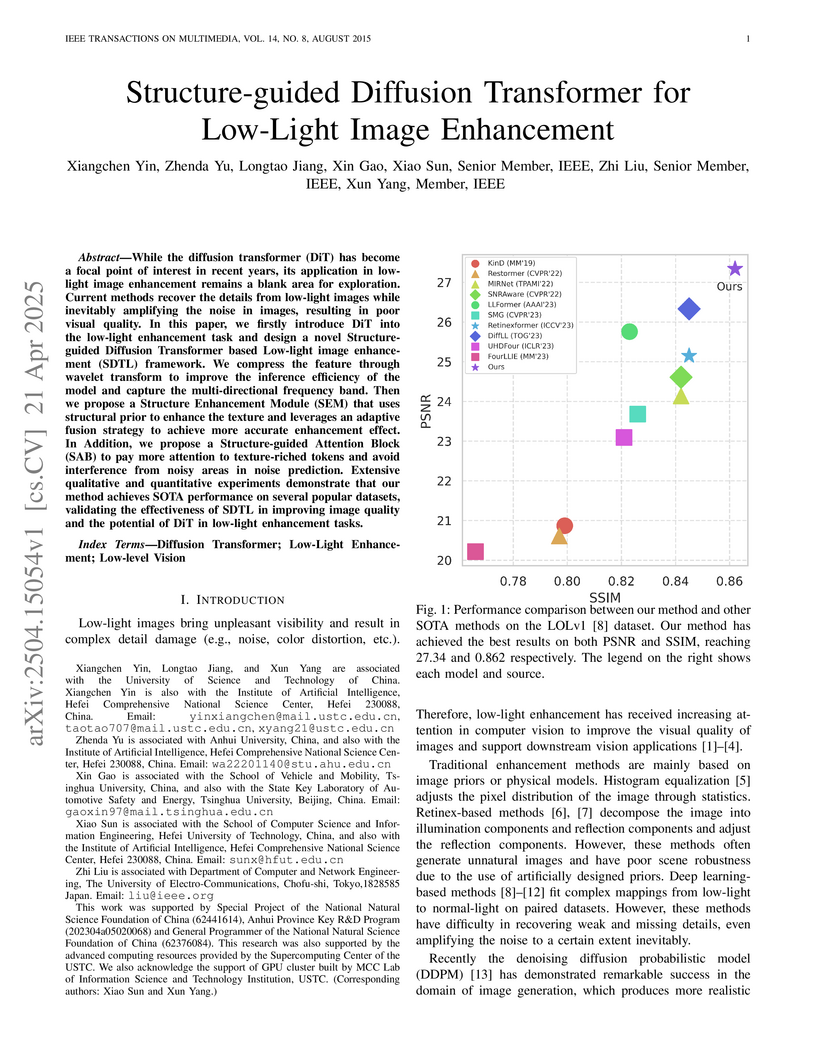
21 Apr 2025

Researchers from the University of Science and Technology of China and collaborators developed SDTL, a framework that integrates Diffusion Transformers with wavelet feature compression and structure-guided attention for low-light image enhancement. The model achieved state-of-the-art performance on various datasets, improving PSNR on LSRW by 1.95dB and increasing mIoU for night segmentation by 2.68% over baselines.

26 Jun 2025
LLaVA-Pose: Enhancing Human Pose and Action Understanding via Keypoint-Integrated Instruction Tuning
LLaVA-Pose: Enhancing Human Pose and Action Understanding via Keypoint-Integrated Instruction Tuning
Researchers from The University of Electro-Communications and TikTok Inc. developed LLaVA-Pose, a Vision-Language Model that leverages keypoint-integrated instruction tuning to achieve enhanced human pose and action understanding. The model demonstrated a 33.2% performance improvement over its LLaVA-1.5-7B baseline and surpassed other leading multimodal models on a new human-centric benchmark.

09 Jan 2022

Building a humanlike integrative artificial cognitive system, that is, an artificial general intelligence (AGI), is the holy grail of the artificial intelligence (AI) field. Furthermore, a computational model that enables an artificial system to achieve cognitive development will be an excellent reference for brain and cognitive science. This paper describes an approach to develop a cognitive architecture by integrating elemental cognitive modules to enable the training of the modules as a whole. This approach is based on two ideas: (1) brain-inspired AI, learning human brain architecture to build human-level intelligence, and (2) a probabilistic generative model(PGM)-based cognitive system to develop a cognitive system for developmental robots by integrating PGMs. The development framework is called a whole brain PGM (WB-PGM), which differs fundamentally from existing cognitive architectures in that it can learn continuously through a system based on sensory-motor information. In this study, we describe the rationale of WB-PGM, the current status of PGM-based elemental cognitive modules, their relationship with the human brain, the approach to the integration of the cognitive modules, and future challenges. Our findings can serve as a reference for brain studies. As PGMs describe explicit informational relationships between variables, this description provides interpretable guidance from computational sciences to brain science. By providing such information, researchers in neuroscience can provide feedback to researchers in AI and robotics on what the current models lack with reference to the brain. Further, it can facilitate collaboration among researchers in neuro-cognitive sciences as well as AI and robotics.

22 Dec 2024
Symmetry imposes constraints on open quantum systems, affecting the dissipative properties in nonequilibrium processes. Superradiance is a typical example in which the decay rate of the system is enhanced via a collective system-bath coupling that respects permutation symmetry. Such model has also been applied to heat engines. However, a generic framework that addresses the impact of symmetry in finite-time thermodynamics is not well established. Here, we show a symmetry-based framework that describes the fundamental limit of collective enhancement in finite-time thermodynamics. Specifically, we derive a general upper bound on the average jump rate, which quantifies the fundamental speed set by thermodynamic speed limits and trade-off relations. We identify the symmetry condition which achieves the obtained bound, and explicitly construct an open quantum system model that goes beyond the enhancement realized by the conventional superradiance model.

29 Sep 2025
Micro-action Recognition is vital for psychological assessment and human-computer interaction. However, existing methods often fail in real-world scenarios because inter-person variability causes the same action to manifest differently, hindering robust generalization. To address this, we propose the Person Independence Universal Micro-action Recognition Framework, which integrates Distributionally Robust Optimization principles to learn person-agnostic representations. Our framework contains two plug-and-play components operating at the feature and loss levels. At the feature level, the Temporal-Frequency Alignment Module normalizes person-specific motion characteristics with a dual-branch design: the temporal branch applies Wasserstein-regularized alignment to stabilize dynamic trajectories, while the frequency branch introduces variance-guided perturbations to enhance robustness against person-specific spectral differences. A consistency-driven fusion mechanism integrates both branches. At the loss level, the Group-Invariant Regularized Loss partitions samples into pseudo-groups to simulate unseen person-specific distributions. By up-weighting boundary cases and regularizing subgroup variance, it forces the model to generalize beyond easy or frequent samples, thus enhancing robustness to difficult variations. Experiments on the large-scale MA-52 dataset demonstrate that our framework outperforms existing methods in both accuracy and robustness, achieving stable generalization under fine-grained conditions.

29 Sep 2015

Humans can learn the use of language through physical interaction with their
environment and semiotic communication with other people. It is very important
to obtain a computational understanding of how humans can form a symbol system
and obtain semiotic skills through their autonomous mental development.
Recently, many studies have been conducted on the construction of robotic
systems and machine-learning methods that can learn the use of language through
embodied multimodal interaction with their environment and other systems.
Understanding human social interactions and developing a robot that can
smoothly communicate with human users in the long term, requires an
understanding of the dynamics of symbol systems and is crucially important. The
embodied cognition and social interaction of participants gradually change a
symbol system in a constructive manner. In this paper, we introduce a field of
research called symbol emergence in robotics (SER). SER is a constructive
approach towards an emergent symbol system. The emergent symbol system is
socially self-organized through both semiotic communications and physical
interactions with autonomous cognitive developmental agents, i.e., humans and
developmental robots. Specifically, we describe some state-of-art research
topics concerning SER, e.g., multimodal categorization, word discovery, and a
double articulation analysis, that enable a robot to obtain words and their
embodied meanings from raw sensory--motor information, including visual
information, haptic information, auditory information, and acoustic speech
signals, in a totally unsupervised manner. Finally, we suggest future
directions of research in SER.

22 Sep 2025
This paper proposes a joint optimization of pilot subcarrier allocation and non-orthogonal sequence for multiple-input-multiple-output (MIMO)-orthogonal frequency-division multiplexing (OFDM) systems under compressed sensing (CS)-based channel estimation exploiting delay and angle sparsity. Since the performance of CS-based approaches depends on a coherence metric of the sensing matrix in the measurement process, we formulate a joint optimization problem to minimize this coherence. Due to the discrete nature of subcarrier allocation, a straightforward formulation of the joint optimization results in a mixed-integer nonlinear program (MINLP), which is computationally intractable due to the combinatorial explosion of allocation candidates. To overcome the intractability of discrete variables, we introduce a block sparse penalty for pilots across all subcarriers, which ensures that the power of some unnecessary pilots approaches zero. This framework enables joint optimization using only continuous variables. In addition, we propose an efficient computation method for the coherence metric by exploiting the structure of the sensing matrix, which allows its gradient to be derived in closed form, making the joint optimization problem solvable in an efficient way via a gradient descent approach. Numerical results confirm that the proposed pilot sequence exhibits superior coherence properties and enhances the CS-based channel estimation performance.

16 Oct 2025
This paper presents the 5th place solution by our team, y3h2, for the Meta CRAG-MM Challenge at KDD Cup 2025. The CRAG-MM benchmark is a visual question answering (VQA) dataset focused on factual questions about images, including egocentric images. The competition was contested based on VQA accuracy, as judged by an LLM-based automatic evaluator. Since incorrect answers result in negative scores, our strategy focused on reducing hallucinations from the internal representations of the VLM. Specifically, we trained logistic regression-based hallucination detection models using both the hidden_state and the outputs of specific attention heads. We then employed an ensemble of these models. As a result, while our method sacrificed some correct answers, it significantly reduced hallucinations and allowed us to place among the top entries on the final leaderboard. For implementation details and code, please refer to this https URL.

29 Aug 2025
Conversational Recommender Systems (CRSs) aim to elicit user preferences via natural dialogue to provide suitable item recommendations. However, current CRSs often deviate from realistic human interactions by rapidly recommending items in brief sessions. This work addresses this gap by leveraging Large Language Models (LLMs) to generate dialogue summaries from dialogue history and item recommendation information from item description. This approach enables the extraction of both explicit user statements and implicit preferences inferred from the dialogue context. We introduce a method using Direct Preference Optimization (DPO) to ensure dialogue summary and item recommendation information are rich in information crucial for effective recommendations. Experiments on two public datasets validate our method's effectiveness in fostering more natural and realistic conversational recommendation processes. Our implementation is publicly available at: this https URL

25 Aug 2025
Serendipity in recommender systems (RSs) has attracted increasing attention as a concept that enhances user satisfaction by presenting unexpected and useful items. However, evaluating serendipitous performance remains challenging because its ground truth is generally unobservable. The existing offline metrics often depend on ambiguous definitions or are tailored to specific datasets and RSs, thereby limiting their generalizability. To address this issue, we propose a universally applicable evaluation framework that leverages large language models (LLMs) known for their extensive knowledge and reasoning capabilities, as evaluators. First, to improve the evaluation performance of the proposed framework, we assessed the serendipity prediction accuracy of LLMs using four different prompt strategies on a dataset containing user-annotated serendipitous ground truth and found that the chain-of-thought prompt achieved the highest accuracy. Next, we re-evaluated the serendipitous performance of both serendipity-oriented and general RSs using the proposed framework on three commonly used real-world datasets, without the ground truth. The results indicated that there was no serendipity-oriented RS that consistently outperformed across all datasets, and even a general RS sometimes achieved higher performance than the serendipity-oriented RS.
There are no more papers matching your filters at the moment.
