27 Mar 2024

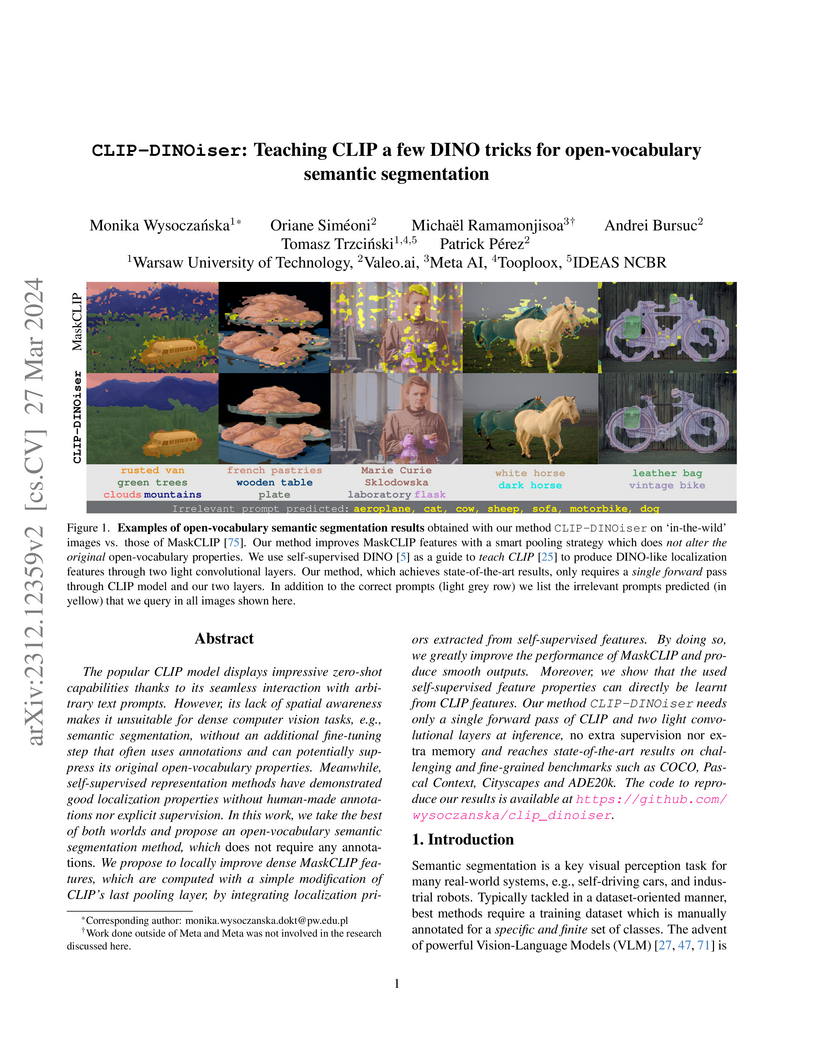
CLIP-DINOiser enhances open-vocabulary semantic segmentation by teaching a frozen CLIP model DINO-like spatial localization properties through two lightweight, annotation-free convolutional layers. The method achieves state-of-the-art performance, producing smoother, more accurate masks with a single CLIP forward pass.

29 Jul 2024
MagMax introduces a model merging strategy for continual learning by combining sequential fine-tuning with maximum magnitude weight selection to mitigate catastrophic forgetting in large pre-trained models. The method consistently outperforms existing continual learning approaches and other merging strategies, achieving an average 2.1% improvement in class-incremental learning, while also demonstrating that sequential fine-tuning universally enhances model merging performance.

02 Jun 2025

This research from Warsaw University of Technology, University of Basel, and Mila investigates how softmax temperature fundamentally influences deep neural network representations. It reveals that higher temperatures lead to compressed, low-rank representations, which improve out-of-distribution detection but degrade out-of-distribution generalization, providing a direct control mechanism for these trade-offs.

07 Dec 2024

LumiGauss reconstructs relightable 3D scenes from unconstrained photo collections by leveraging 2D Gaussian Splatting and spherical harmonics, achieving real-time rendering speeds and improved fidelity compared to NeRF-based methods. The system successfully disentangles albedo and illumination, enabling realistic relighting with accurate shadows.

30 Aug 2025
Input-dependent activation sparsity is a notable property of deep learning models, which has been extensively studied in networks with ReLU activations and is associated with efficiency, robustness, and interpretability. However, the approaches developed for ReLU-based models depend on exact zero activations and do not transfer directly to modern large language models~(LLMs), which have abandoned ReLU in favor of other activation functions. As a result, current work on activation sparsity in LLMs is fragmented, model-specific, and lacks consensus on which components to target. We propose a general framework to assess sparsity robustness and present a systematic study of the phenomenon in the FFN layers of modern LLMs, including diffusion LLMs. Our findings reveal universal patterns of activation sparsity in LLMs, provide insights into this phenomenon, and offer practical guidelines for exploiting it in model design and acceleration.

07 Jul 2025
With the rise of LLMs, ensuring model safety and alignment has become a critical concern. While modern instruction-finetuned LLMs incorporate alignment during training, they still frequently require moderation tools to prevent unsafe behavior. The most common approach to moderation are guard models that flag unsafe inputs. However, guards require costly training and are typically limited to fixed-size, pre-trained options, making them difficult to adapt to evolving risks and resource constraints. We hypothesize that instruction-finetuned LLMs already encode safety-relevant information internally and explore training-free safety assessment methods that work with off-the-shelf models. We show that simple prompting allows models to recognize harmful inputs they would otherwise mishandle. We also demonstrate that safe and unsafe prompts are distinctly separable in the models' latent space. Building on this, we introduce the Latent Prototype Moderator (LPM), a training-free moderation method that uses Mahalanobis distance in latent space to assess input safety. LPM is a lightweight, customizable add-on that generalizes across model families and sizes. Our method matches or exceeds state-of-the-art guard models across multiple safety benchmarks, offering a practical and flexible solution for scalable LLM moderation.

29 Jul 2023

Talking face generation has historically struggled to produce head movements and natural facial expressions without guidance from additional reference videos. Recent developments in diffusion-based generative models allow for more realistic and stable data synthesis and their performance on image and video generation has surpassed that of other generative models. In this work, we present an autoregressive diffusion model that requires only one identity image and audio sequence to generate a video of a realistic talking human head. Our solution is capable of hallucinating head movements, facial expressions, such as blinks, and preserving a given background. We evaluate our model on two different datasets, achieving state-of-the-art results on both of them.

28 Nov 2023
The emergence of CLIP has opened the way for open-world image perception. The zero-shot classification capabilities of the model are impressive but are harder to use for dense tasks such as image segmentation. Several methods have proposed different modifications and learning schemes to produce dense output. Instead, we propose in this work an open-vocabulary semantic segmentation method, dubbed CLIP-DIY, which does not require any additional training or annotations, but instead leverages existing unsupervised object localization approaches. In particular, CLIP-DIY is a multi-scale approach that directly exploits CLIP classification abilities on patches of different sizes and aggregates the decision in a single map. We further guide the segmentation using foreground/background scores obtained using unsupervised object localization methods. With our method, we obtain state-of-the-art zero-shot semantic segmentation results on PASCAL VOC and perform on par with the best methods on COCO. The code is available at this http URL

27 Mar 2023

Diffusion models have achieved remarkable success in generating high-quality images thanks to their novel training procedures applied to unprecedented amounts of data. However, training a diffusion model from scratch is computationally expensive. This highlights the need to investigate the possibility of training these models iteratively, reusing computation while the data distribution changes. In this study, we take the first step in this direction and evaluate the continual learning (CL) properties of diffusion models. We begin by benchmarking the most common CL methods applied to Denoising Diffusion Probabilistic Models (DDPMs), where we note the strong performance of the experience replay with the reduced rehearsal coefficient. Furthermore, we provide insights into the dynamics of forgetting, which exhibit diverse behavior across diffusion timesteps. We also uncover certain pitfalls of using the bits-per-dimension metric for evaluating CL.
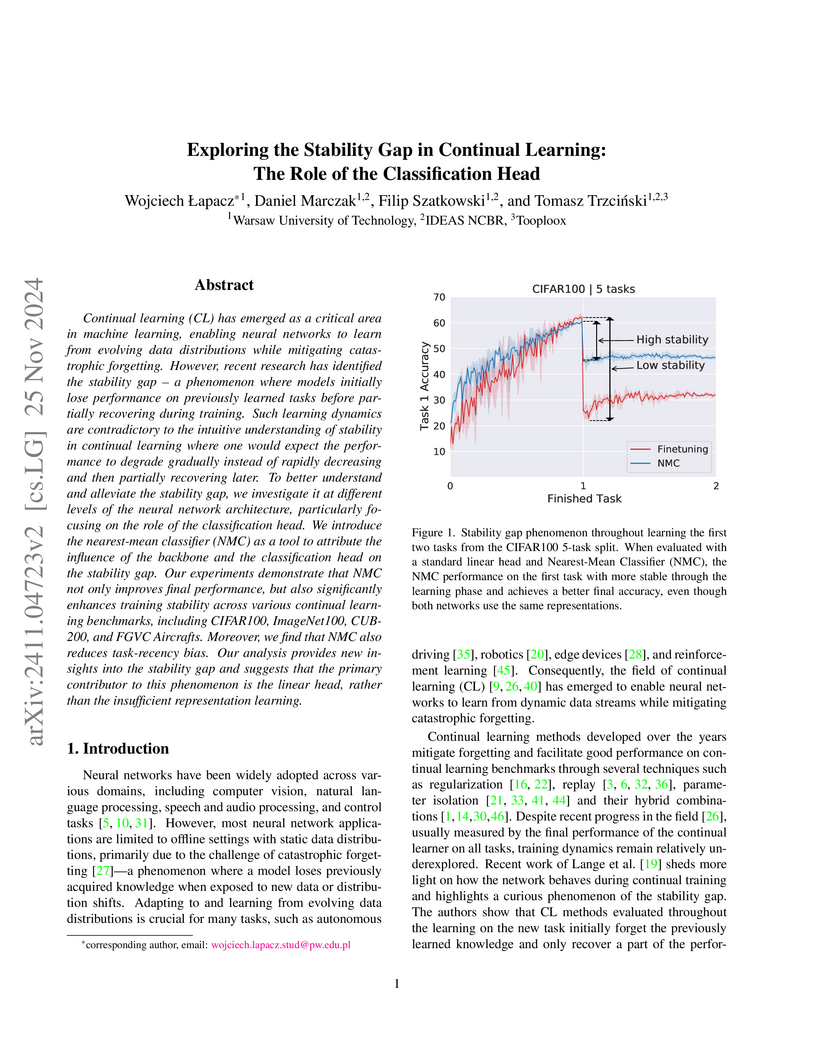
25 Nov 2024
Continual learning (CL) has emerged as a critical area in machine learning, enabling neural networks to learn from evolving data distributions while mitigating catastrophic forgetting. However, recent research has identified the stability gap -- a phenomenon where models initially lose performance on previously learned tasks before partially recovering during training. Such learning dynamics are contradictory to the intuitive understanding of stability in continual learning where one would expect the performance to degrade gradually instead of rapidly decreasing and then partially recovering later. To better understand and alleviate the stability gap, we investigate it at different levels of the neural network architecture, particularly focusing on the role of the classification head. We introduce the nearest-mean classifier (NMC) as a tool to attribute the influence of the backbone and the classification head on the stability gap. Our experiments demonstrate that NMC not only improves final performance, but also significantly enhances training stability across various continual learning benchmarks, including CIFAR100, ImageNet100, CUB-200, and FGVC Aircrafts. Moreover, we find that NMC also reduces task-recency bias. Our analysis provides new insights into the stability gap and suggests that the primary contributor to this phenomenon is the linear head, rather than the insufficient representation learning.

14 Oct 2023
Enhancing low-light images while maintaining natural colors is a challenging problem due to camera processing variations and limited access to photos with ground-truth lighting conditions. The latter is a crucial factor for supervised methods that achieve good results on paired datasets but do not handle out-of-domain data well. On the other hand, unsupervised methods, while able to generalize, often yield lower-quality enhancements. To fill this gap, we propose Dimma, a semi-supervised approach that aligns with any camera by utilizing a small set of image pairs to replicate scenes captured under extreme lighting conditions taken by that specific camera. We achieve that by introducing a convolutional mixture density network that generates distorted colors of the scene based on the illumination differences. Additionally, our approach enables accurate grading of the dimming factor, which provides a wide range of control and flexibility in adjusting the brightness levels during the low-light image enhancement process. To further improve the quality of our results, we introduce an architecture based on a conditional UNet. The lightness value provided by the user serves as the conditional input to generate images with the desired lightness. Our approach using only few image pairs achieves competitive results compared to fully supervised methods. Moreover, when trained on the full dataset, our model surpasses state-of-the-art methods in some metrics and closely approaches them in others.

04 Nov 2023
In this work, we investigate exemplar-free class incremental learning (CIL) with knowledge distillation (KD) as a regularization strategy, aiming to prevent forgetting. KD-based methods are successfully used in CIL, but they often struggle to regularize the model without access to exemplars of the training data from previous tasks. Our analysis reveals that this issue originates from substantial representation shifts in the teacher network when dealing with out-of-distribution data. This causes large errors in the KD loss component, leading to performance degradation in CIL models. Inspired by recent test-time adaptation methods, we introduce Teacher Adaptation (TA), a method that concurrently updates the teacher and the main models during incremental training. Our method seamlessly integrates with KD-based CIL approaches and allows for consistent enhancement of their performance across multiple exemplar-free CIL benchmarks. The source code for our method is available at this https URL.

11 Jul 2023
Self-supervised methods have been proven effective for learning deep
representations of 3D point cloud data. Although recent methods in this domain
often rely on random masking of inputs, the results of this approach can be
improved. We introduce PointCAM, a novel adversarial method for learning a
masking function for point clouds. Our model utilizes a self-distillation
framework with an online tokenizer for 3D point clouds. Compared to previous
techniques that optimize patch-level and object-level objectives, we postulate
applying an auxiliary network that learns how to select masks instead of
choosing them randomly. Our results show that the learned masking function
achieves state-of-the-art or competitive performance on various downstream
tasks. The source code is available at https://github.com/szacho/pointcam.

16 Jul 2024
In the field of continual learning, models are designed to learn tasks one after the other. While most research has centered on supervised continual learning, there is a growing interest in unsupervised continual learning, which makes use of the vast amounts of unlabeled data. Recent studies have highlighted the strengths of unsupervised methods, particularly self-supervised learning, in providing robust representations. The improved transferability of those representations built with self-supervised methods is often associated with the role played by the multi-layer perceptron projector. In this work, we depart from this observation and reexamine the role of supervision in continual representation learning. We reckon that additional information, such as human annotations, should not deteriorate the quality of representations. Our findings show that supervised models when enhanced with a multi-layer perceptron head, can outperform self-supervised models in continual representation learning. This highlights the importance of the multi-layer perceptron projector in shaping feature transferability across a sequence of tasks in continual learning. The code is available on github: this https URL.

30 Oct 2023


This research identifies the "tunnel effect" in deep neural networks, where initial layers extract features and subsequent layers compress these representations into a low-dimensional subspace. This functional split negatively impacts out-of-distribution generalization and clarifies the roles of different network parts in catastrophic forgetting during continual learning.

07 Feb 2025
In computer graphics and vision, recovering easily modifiable scene
appearance from image data is crucial for applications such as content
creation. We introduce a novel method that integrates 3D Gaussian Splatting
with an implicit surface representation, enabling intuitive editing of
recovered scenes through mesh manipulation. Starting with a set of input images
and camera poses, our approach reconstructs the scene surface using a neural
signed distance field. This neural surface acts as a geometric prior guiding
the training of Gaussian Splatting components, ensuring their alignment with
the scene geometry. To facilitate editing, we encode the visual and geometric
information into a lightweight triangle soup proxy. Edits applied to the mesh
extracted from the neural surface propagate seamlessly through this
intermediate structure to update the recovered appearance. Unlike previous
methods relying on the triangle soup proxy representation, our approach
supports a wider range of modifications and fully leverages the mesh topology,
enabling a more flexible and intuitive editing process. The complete source
code for this project can be accessed at:
this https URL

03 May 2022
In this paper, we propose an end-to-end multi-task neural network called
FetalNet with an attention mechanism and stacked module for spatio-temporal
fetal ultrasound scan video analysis. Fetal biometric measurement is a standard
examination during pregnancy used for the fetus growth monitoring and
estimation of gestational age and fetal weight. The main goal in fetal
ultrasound scan video analysis is to find proper standard planes to measure the
fetal head, abdomen and femur. Due to natural high speckle noise and shadows in
ultrasound data, medical expertise and sonographic experience are required to
find the appropriate acquisition plane and perform accurate measurements of the
fetus. In addition, existing computer-aided methods for fetal US biometric
measurement address only one single image frame without considering temporal
features. To address these shortcomings, we propose an end-to-end multi-task
neural network for spatio-temporal ultrasound scan video analysis to
simultaneously localize, classify and measure the fetal body parts. We propose
a new encoder-decoder segmentation architecture that incorporates a
classification branch. Additionally, we employ an attention mechanism with a
stacked module to learn salient maps to suppress irrelevant US regions and
efficient scan plane localization. We trained on the fetal ultrasound video
comes from routine examinations of 700 different patients. Our method called
FetalNet outperforms existing state-of-the-art methods in both classification
and segmentation in fetal ultrasound video recordings.

14 Apr 2021
We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: this https URL.

18 Sep 2023
In this work, we improve the generative replay in a continual learning
setting to perform well on challenging scenarios. Current generative rehearsal
methods are usually benchmarked on small and simple datasets as they are not
powerful enough to generate more complex data with a greater number of classes.
We notice that in VAE-based generative replay, this could be attributed to the
fact that the generated features are far from the original ones when mapped to
the latent space. Therefore, we propose three modifications that allow the
model to learn and generate complex data. More specifically, we incorporate the
distillation in latent space between the current and previous models to reduce
feature drift. Additionally, a latent matching for the reconstruction and
original data is proposed to improve generated features alignment. Further,
based on the observation that the reconstructions are better for preserving
knowledge, we add the cycling of generations through the previously trained
model to make them closer to the original data. Our method outperforms other
generative replay methods in various scenarios. Code available at
this https URL
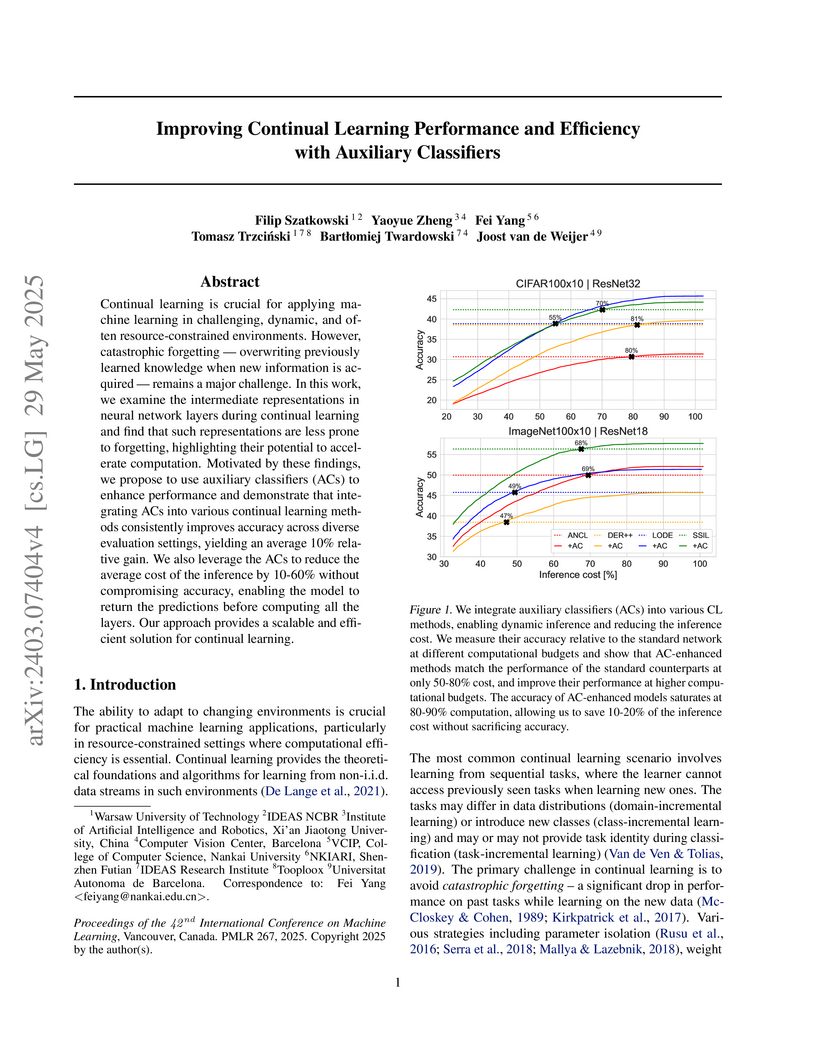
29 May 2025
Continual learning is crucial for applying machine learning in challenging,
dynamic, and often resource-constrained environments. However, catastrophic
forgetting - overwriting previously learned knowledge when new information is
acquired - remains a major challenge. In this work, we examine the intermediate
representations in neural network layers during continual learning and find
that such representations are less prone to forgetting, highlighting their
potential to accelerate computation. Motivated by these findings, we propose to
use auxiliary classifiers(ACs) to enhance performance and demonstrate that
integrating ACs into various continual learning methods consistently improves
accuracy across diverse evaluation settings, yielding an average 10% relative
gain. We also leverage the ACs to reduce the average cost of the inference by
10-60% without compromising accuracy, enabling the model to return the
predictions before computing all the layers. Our approach provides a scalable
and efficient solution for continual learning.
There are no more papers matching your filters at the moment.
