
09 Sep 2024



Starting from a stochastic individual-based description of an SIS epidemic spreading on a random network, we study the dynamics when the size of the network tends to infinity. We recover in the limit an infinite-dimensional integro-differential equation studied by Delmas, Dronnier and Zitt (2022) for an SIS epidemic propagating on a graphon. Our work covers the case of dense and sparse graphs, provided that the number of edges grows faster than , but not the case of very sparse graphs with edges. In order to establish our limit theorem, we have to deal with both the convergence of the random graphs to the graphon and the convergence of the stochastic process spreading on top of these random structures: in particular, we propose a coupling between the process of interest and an epidemic that spreads on the complete graph but with a modified infection rate.
Keywords: Random graph, mathematical models of epidemics, measure-valued process, large network limit, limit theorem, graphon.

07 Feb 2025

Modern medical image registration approaches predict deformations using deep
networks. These approaches achieve state-of-the-art (SOTA) registration
accuracy and are generally fast. However, deep learning (DL) approaches are, in
contrast to conventional non-deep-learning-based approaches, anatomy-specific.
Recently, a universal deep registration approach, uniGradICON, has been
proposed. However, uniGradICON focuses on monomodal image registration. In this
work, we therefore develop multiGradICON as a first step towards universal
*multimodal* medical image registration. Specifically, we show that 1) we can
train a DL registration model that is suitable for monomodal *and* multimodal
registration; 2) loss function randomization can increase multimodal
registration accuracy; and 3) training a model with multimodal data helps
multimodal generalization. Our code and the multiGradICON model are available
at this https URL

21 Oct 2024


We introduce the Seismic Language Model (SeisLM), a foundational model designed to analyze seismic waveforms -- signals generated by Earth's vibrations such as the ones originating from earthquakes. SeisLM is pretrained on a large collection of open-source seismic datasets using a self-supervised contrastive loss, akin to BERT in language modeling. This approach allows the model to learn general seismic waveform patterns from unlabeled data without being tied to specific downstream tasks. When fine-tuned, SeisLM excels in seismological tasks like event detection, phase-picking, onset time regression, and foreshock-aftershock classification. The code has been made publicly available on this https URL.

26 Jun 2023


Researchers at Meta AI - FAIR and New York University introduced RankMe, an unsupervised criterion that assesses the quality of self-supervised representations by quantifying the effective rank of their embeddings. This label-free method enables hyperparameter selection for Joint-Embedding Self-Supervised Learning models, often achieving performance comparable to or exceeding label-guided approaches on various downstream tasks with less than a 0.5-point average performance gap for linear probing on ImageNet.

20 Feb 2025
Online continuous action recognition has emerged as a critical research area
due to its practical implications in real-world applications, such as
human-computer interaction, healthcare, and robotics. Among various modalities,
skeleton-based approaches have gained significant popularity, demonstrating
their effectiveness in capturing 3D temporal data while ensuring robustness to
environmental variations. However, most existing works focus on segment-based
recognition, making them unsuitable for real-time, continuous recognition
scenarios. In this paper, we propose a novel online recognition system designed
for real-time skeleton sequence streaming. Our approach leverages a hybrid
architecture combining Spatial Graph Convolutional Networks (S-GCN) for spatial
feature extraction and a Transformer-based Graph Encoder (TGE) for capturing
temporal dependencies across frames. Additionally, we introduce a continual
learning mechanism to enhance model adaptability to evolving data
distributions, ensuring robust recognition in dynamic environments. We evaluate
our method on the SHREC'21 benchmark dataset, demonstrating its superior
performance in online hand gesture recognition. Our approach not only achieves
state-of-the-art accuracy but also significantly reduces false positive rates,
making it a compelling solution for real-time applications. The proposed system
can be seamlessly integrated into various domains, including human-robot
collaboration and assistive technologies, where natural and intuitive
interaction is crucial.

26 Jun 2023
Recent approaches in self-supervised learning of image representations can be
categorized into different families of methods and, in particular, can be
divided into contrastive and non-contrastive approaches. While differences
between the two families have been thoroughly discussed to motivate new
approaches, we focus more on the theoretical similarities between them. By
designing contrastive and covariance based non-contrastive criteria that can be
related algebraically and shown to be equivalent under limited assumptions, we
show how close those families can be. We further study popular methods and
introduce variations of them, allowing us to relate this theoretical result to
current practices and show the influence (or lack thereof) of design choices on
downstream performance. Motivated by our equivalence result, we investigate the
low performance of SimCLR and show how it can match VICReg's with careful
hyperparameter tuning, improving significantly over known baselines. We also
challenge the popular assumption that non-contrastive methods need large output
dimensions. Our theoretical and quantitative results suggest that the numerical
gaps between contrastive and non-contrastive methods in certain regimes can be
closed given better network design choices and hyperparameter tuning. The
evidence shows that unifying different SOTA methods is an important direction
to build a better understanding of self-supervised learning.

16 Dec 2024
Entropic Optimal Transport (EOT), also referred to as the Schrödinger problem, seeks to find a random processes with prescribed initial/final marginals and with minimal relative entropy with respect to a reference measure. The relative entropy forces the two measures to share the same support and only the drift of the controlled process can be adjusted, the diffusion being imposed by the reference measure. Therefore, at first sight, Semi-Martingale Optimal Transport (SMOT) problems (see [1]) seem out of the scope of applications of Entropic regularization techniques, which are otherwise very attractive from a computational point of view. However, when the process is observed only at discrete times, and become therefore a Markov chain, its relative entropy can remain finite even with variable diffusion coefficients, and discrete semi-martingales can be obtained as solutions of (multi-marginal) EOT this http URL a (smooth) semi-martingale, the limit of the relative entropy of its time discretizations, scaled by the time step converges to the so-called ``specific relative entropy'', a convex functional of its variance process, similar to those used in this http URL this paper we use this observation to build an entropic time discretization of continuous SMOT problems. This allows to compute discrete approximations of solutions to continuous SMOT problems by a multi-marginal Sinkhorn algorithm, without the need of solving the non-linear Hamilton-Jacobi-Bellman pde's associated to the dual problem, as done for example in [1, 2]. We prove a convergence result of the time discrete entropic problem to the continuous time problem, we propose an implementation and provide numerical experiments supporting the theoretical convergence.

24 May 2025


We present the first global-scale database of 4.3 billion P- and S-wave picks
extracted from 1.3 PB continuous seismic data via a cloud-native workflow.
Using cloud computing services on Amazon Web Services, we launched ~145,000
containerized jobs on continuous records from 47,354 stations spanning
2002-2025, completing in under three days. Phase arrivals were identified with
a deep learning model, PhaseNet, through an open-source Python ecosystem for
deep learning, SeisBench. To visualize and gain a global understanding of these
picks, we present preliminary results about pick time series revealing
Omori-law aftershock decay, seasonal variations linked to noise levels, and
dense regional coverage that will enhance earthquake catalogs and
machine-learning datasets. We provide all picks in a publicly queryable
database, providing a powerful resource for researchers studying seismicity
around the world. This report provides insights into the database and the
underlying workflow, demonstrating the feasibility of petabyte-scale seismic
data mining on the cloud and of providing intelligent data products to the
community in an automated manner.

29 Oct 2025
Current text-to-image generative models are trained on large uncurated datasets to enable diverse generation capabilities. However, this does not align well with user preferences. Recently, reward models have been specifically designed to perform post-hoc selection of generated images and align them to a reward, typically user preference. This discarding of informative data together with the optimizing for a single reward tend to harm diversity, semantic fidelity and efficiency. Instead of this post-processing, we propose to condition the model on multiple reward models during training to let the model learn user preferences directly. We show that this not only dramatically improves the visual quality of the generated images but it also significantly speeds up the training. Our proposed method, called MIRO, achieves state-of-the-art performances on the GenEval compositional benchmark and user-preference scores (PickAScore, ImageReward, HPSv2).
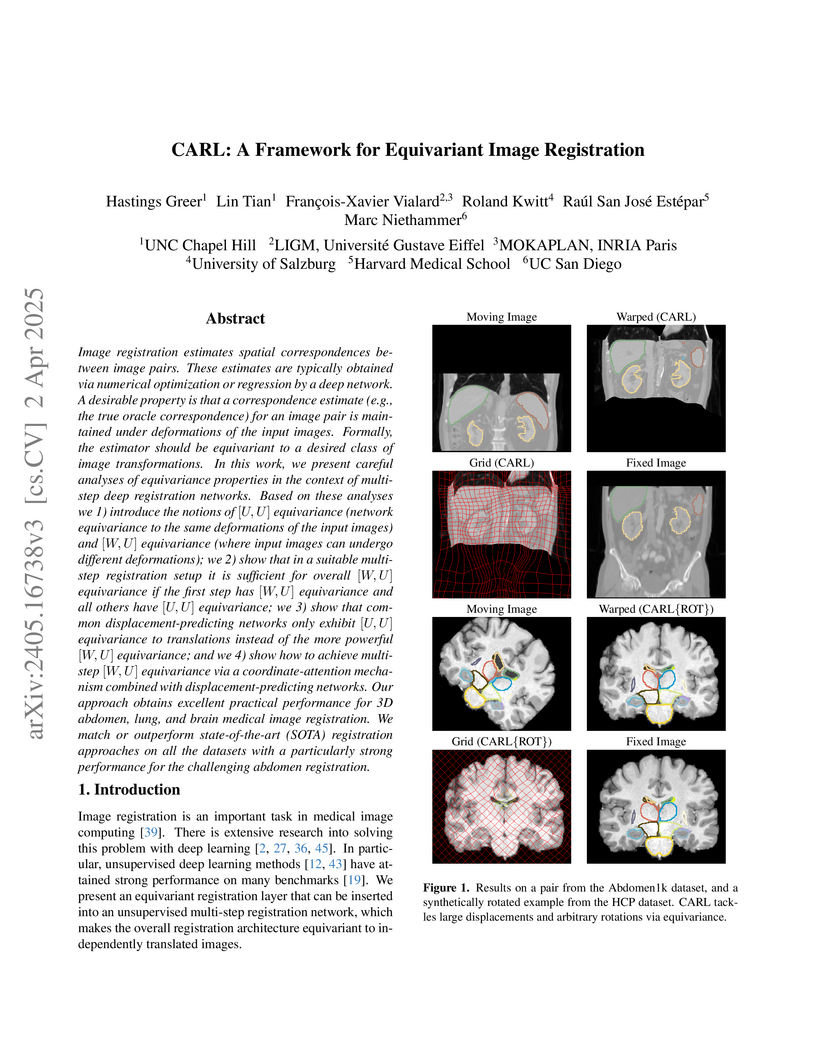
02 Apr 2025

Image registration estimates spatial correspondences between a pair of
images. These estimates are typically obtained via numerical optimization or
regression by a deep network. A desirable property of such estimators is that a
correspondence estimate (e.g., the true oracle correspondence) for an image
pair is maintained under deformations of the input images. Formally, the
estimator should be equivariant to a desired class of image transformations. In
this work, we present careful analyses of the desired equivariance properties
in the context of multi-step deep registration networks. Based on these
analyses we 1) introduce the notions of equivariance (network
equivariance to the same deformations of the input images) and
equivariance (where input images can undergo different deformations); we 2)
show that in a suitable multi-step registration setup it is sufficient for
overall equivariance if the first step has equivariance and all
others have equivariance; we 3) show that common
displacement-predicting networks only exhibit equivariance to
translations instead of the more powerful equivariance; and we 4) show
how to achieve multi-step equivariance via a coordinate-attention
mechanism combined with displacement-predicting refinement layers (CARL).
Overall, our approach obtains excellent practical registration performance on
several 3D medical image registration tasks and outperforms existing
unsupervised approaches for the challenging problem of abdomen registration.

10 Oct 2024

In this paper we study the Spanning Tree Congestion problem, where we are given a graph and are asked to find a spanning tree of minimum maximum congestion. Here, the congestion of an edge is the number of edges such that the (unique) path from to in traverses . We consider this well-studied NP-hard problem from the point of view of (structural) parameterized complexity and obtain the following results.
We resolve a natural open problem by showing that Spanning Tree Congestion is not FPT parameterized by treewidth (under standard assumptions). More strongly, we present a generic reduction which applies to (almost) any parameter of the form ``vertex-deletion distance to class '', thus obtaining W[1]-hardness for parameters more restricted than treewidth, including tree-depth plus feedback vertex set, or incomparable to treewidth, such as twin cover. Via a slight tweak of the same reduction we also show that the problem is NP-complete on graphs of modular-width .
Even though it is known that Spanning Tree Congestion remains NP-hard on instances with only one vertex of unbounded degree, it is currently open whether the problem remains hard on bounded-degree graphs. We resolve this question by showing NP-hardness on graphs of maximum degree 8.
Complementing the problem's W[1]-hardness for treewidth...
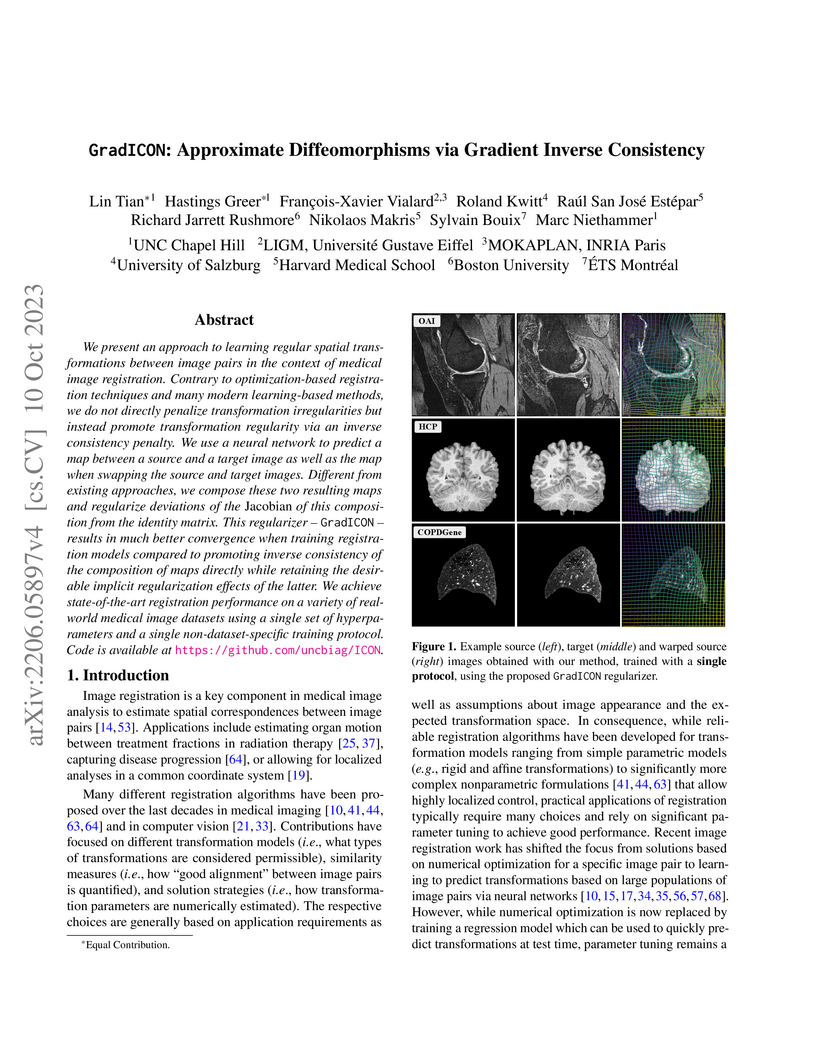
10 Oct 2023
We present an approach to learning regular spatial transformations between image pairs in the context of medical image registration. Contrary to optimization-based registration techniques and many modern learning-based methods, we do not directly penalize transformation irregularities but instead promote transformation regularity via an inverse consistency penalty. We use a neural network to predict a map between a source and a target image as well as the map when swapping the source and target images. Different from existing approaches, we compose these two resulting maps and regularize deviations of the of this composition from the identity matrix. This regularizer -- -- results in much better convergence when training registration models compared to promoting inverse consistency of the composition of maps directly while retaining the desirable implicit regularization effects of the latter. We achieve state-of-the-art registration performance on a variety of real-world medical image datasets using a single set of hyperparameters and a single non-dataset-specific training protocol.

19 Dec 2020
In this document, we propose a description, via a Haskell implementation, of a generalization of the notion of regular expression allowing us to group the definitions and the methods of (tree or word) automata constructions over one generic structure, based on enriched category theory tools. We first recall several methods of conversion from expressions to automata, enlightening the similarities between the words and trees cases. We then produce an original study of the power of enriched category theory applied 1) to automata and expressions implementation, and 2) to the study of associated algorithms, using advanced concepts of functional programming, while simultaneously constructing a Haskell implementation of notions of enriched category theory and associated automata. More precisely, the Haskell implementation and the algebraic definition of the generic automaton structure are based on the following ideas:
- enriched categories, enriched functors, enriched monads, etc. can be implemented in Haskell;
- Type level programming can be used to properly encode function arity;
- monoids (word structure) and operads (tree structure) can be encoded as monoid objects;
- tree and word automata can be represented by the same algebraic structure, via enriched categories.
This generalization leads to surprising remarks. As an example, some classical algorithms (determinization, completion, conversion from alternating to deterministic automaton) can be regrouped in only one function. We will then define a notion of generalized expressions based on the notion of monoidal tensor product.
Haskell sources are available at: this http URL
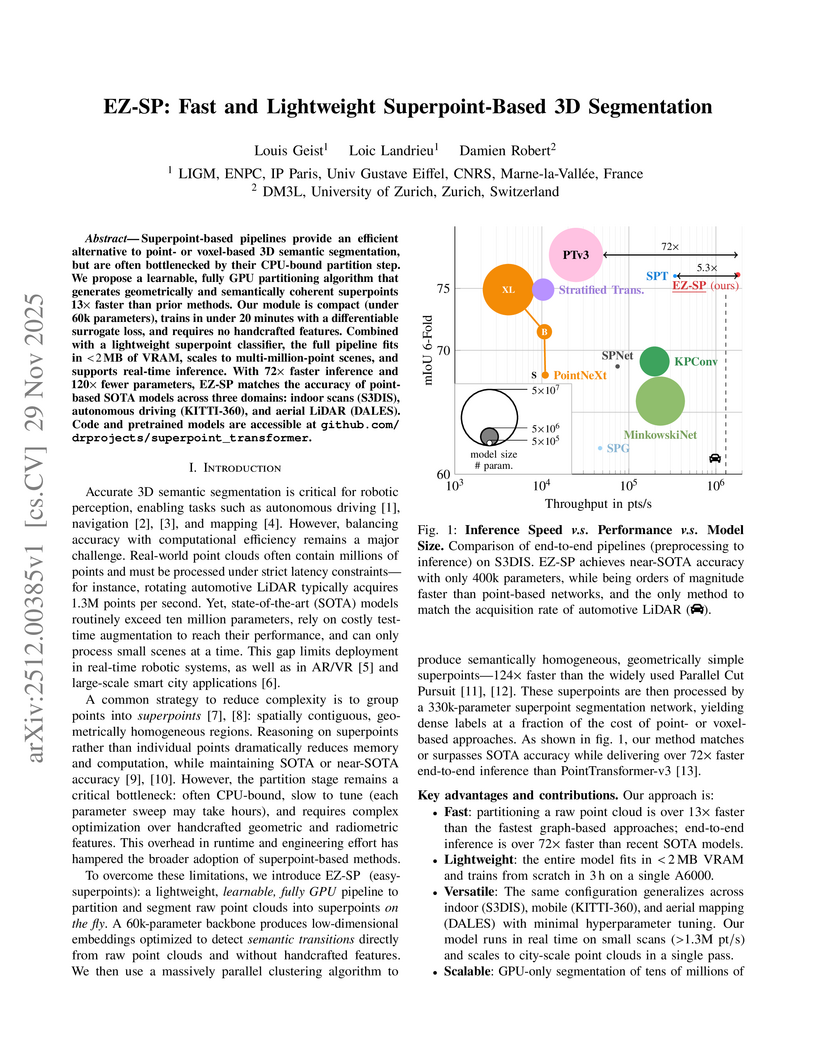
29 Nov 2025
Superpoint-based pipelines provide an efficient alternative to point- or voxel-based 3D semantic segmentation, but are often bottlenecked by their CPU-bound partition step. We propose a learnable, fully GPU partitioning algorithm that generates geometrically and semantically coherent superpoints 13 faster than prior methods. Our module is compact (under 60k parameters), trains in under 20 minutes with a differentiable surrogate loss, and requires no handcrafted features. Combine with a lightweight superpoint classifier, the full pipeline fits in <2 MB of VRAM, scales to multi-million-point scenes, and supports real-time inference. With 72 faster inference and 120 fewer parameters, EZ-SP matches the accuracy of point-based SOTA models across three domains: indoor scans (S3DIS), autonomous driving (KITTI-360), and aerial LiDAR (DALES). Code and pretrained models are accessible at this http URL.
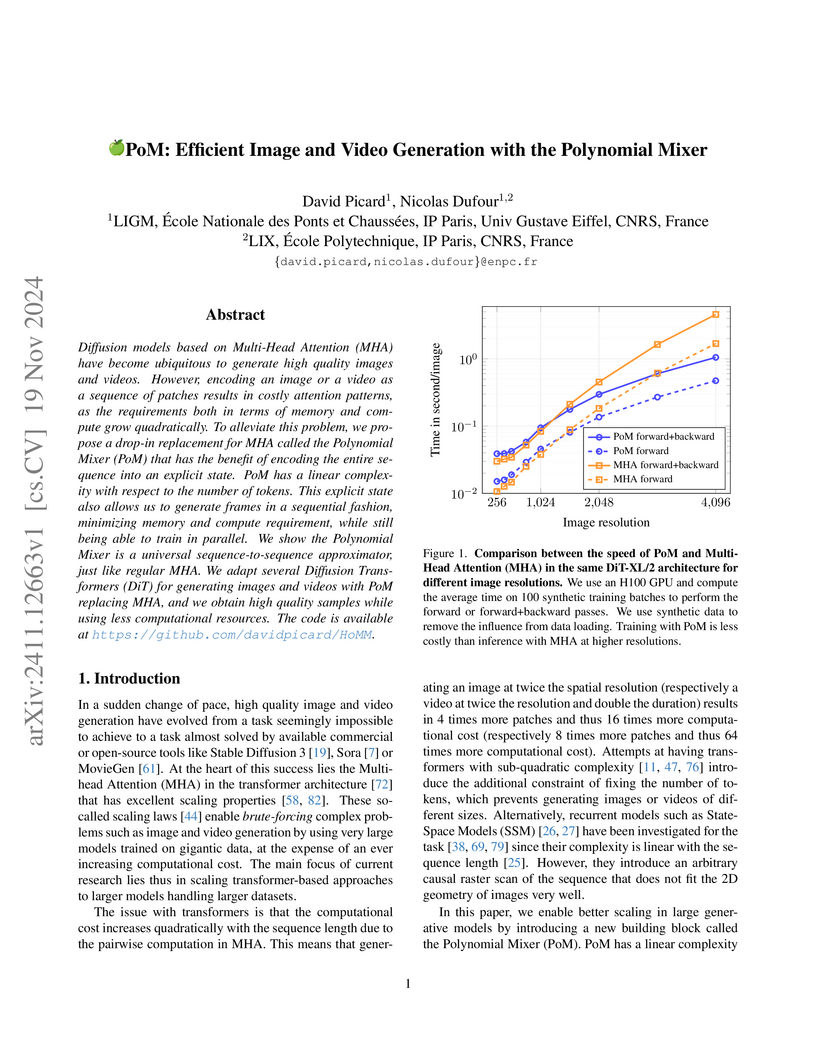
19 Nov 2024
Diffusion models based on Multi-Head Attention (MHA) have become ubiquitous to generate high quality images and videos. However, encoding an image or a video as a sequence of patches results in costly attention patterns, as the requirements both in terms of memory and compute grow quadratically. To alleviate this problem, we propose a drop-in replacement for MHA called the Polynomial Mixer (PoM) that has the benefit of encoding the entire sequence into an explicit state. PoM has a linear complexity with respect to the number of tokens. This explicit state also allows us to generate frames in a sequential fashion, minimizing memory and compute requirement, while still being able to train in parallel. We show the Polynomial Mixer is a universal sequence-to-sequence approximator, just like regular MHA. We adapt several Diffusion Transformers (DiT) for generating images and videos with PoM replacing MHA, and we obtain high quality samples while using less computational resources. The code is available at this https URL.

09 Jul 2025
Conformal prediction methods are statistical tools designed to quantify uncertainty and generate predictive sets with guaranteed coverage probabilities. This work introduces an innovative refinement to these methods for classification tasks, specifically tailored for scenarios where multiple observations (multi-inputs) of a single instance are available at prediction time. Our approach is particularly motivated by applications in citizen science, where multiple images of the same plant or animal are captured by individuals. Our method integrates the information from each observation into conformal prediction, enabling a reduction in the size of the predicted label set while preserving the required class-conditional coverage guarantee. The approach is based on the aggregation of conformal p-values computed from each observation of a multi-input. By exploiting the exact distribution of these p-values, we propose a general aggregation framework using an abstract scoring function, encompassing many classical statistical tools. Knowledge of this distribution also enables refined versions of standard strategies, such as majority voting. We evaluate our method on simulated and real data, with a particular focus on Pl@ntNet, a prominent citizen science platform that facilitates the collection and identification of plant species through user-submitted images.

21 Apr 2024
In this work we study symmetric random matrices with variance profile
satisfying certain conditions. We establish the convergence of the operator
norm of these matrices to the largest element of the support of the limiting
empirical spectral distribution. We prove that it is sufficient for the entries
of the matrix to have finite only the -th moment or the moment
in order for the convergence to hold in probability or almost surely
respectively. Our approach determines the behaviour of the operator norm for
random symmetric or non-symmetric matrices whose variance profile is given by a
step or a continuous function, random band matrices whose bandwidth is
proportional to their dimension, random Gram matrices, triangular matrices and
more.

26 Feb 2025
Time series data, defined by equally spaced points over time, is essential in
fields like medicine, telecommunications, and energy. Analyzing it involves
tasks such as classification, clustering, prototyping, and regression.
Classification identifies normal vs. abnormal movements in skeleton-based
motion sequences, clustering detects stock market behavior patterns,
prototyping expands physical therapy datasets, and regression predicts patient
recovery. Deep learning has recently gained traction in time series analysis
due to its success in other domains. This thesis leverages deep learning to
enhance classification with feature engineering, introduce foundation models,
and develop a compact yet state-of-the-art architecture. We also address
limited labeled data with self-supervised learning. Our contributions apply to
real-world tasks, including human motion analysis for action recognition and
rehabilitation. We introduce a generative model for human motion data, valuable
for cinematic production and gaming. For prototyping, we propose a shape-based
synthetic sample generation method to support regression models when data is
scarce. Lastly, we critically evaluate discriminative and generative models,
identifying limitations in current methodologies and advocating for a robust,
standardized evaluation framework. Our experiments on public datasets provide
novel insights and methodologies, advancing time series analysis with practical
applications.

08 Dec 2022
A classical tool for approximating integrals is the Laplace method. The
first-order, as well as the higher-order Laplace formula is most often written
in coordinates without any geometrical interpretation. In this article,
motivated by a situation arising, among others, in optimal transport, we give a
geometric formulation of the first-order term of the Laplace method. The
central tool is the Kim-McCann Riemannian metric which was introduced in the
field of optimal transportation. Our main result expresses the first-order term
with standard geometric objects such as volume forms, Laplacians, covariant
derivatives and scalar curvatures of two different metrics arising naturally in
the Kim-McCann framework. Passing by, we give an explicitly quantified version
of the Laplace formula, as well as examples of applications.

05 Feb 2024
A major challenge in designing efficient statistical supervised learning algorithms is finding representations that perform well not only on available training samples but also on unseen data. While the study of representation learning has spurred much interest, most existing such approaches are heuristic; and very little is known about theoretical generalization guarantees.
In this paper, we establish a compressibility framework that allows us to derive upper bounds on the generalization error of a representation learning algorithm in terms of the "Minimum Description Length" (MDL) of the labels or the latent variables (representations). Rather than the mutual information between the encoder's input and the representation, which is often believed to reflect the algorithm's generalization capability in the related literature but in fact, falls short of doing so, our new bounds involve the "multi-letter" relative entropy between the distribution of the representations (or labels) of the training and test sets and a fixed prior. In particular, these new bounds reflect the structure of the encoder and are not vacuous for deterministic algorithms. Our compressibility approach, which is information-theoretic in nature, builds upon that of Blum-Langford for PAC-MDL bounds and introduces two essential ingredients: block-coding and lossy-compression. The latter allows our approach to subsume the so-called geometrical compressibility as a special case. To the best knowledge of the authors, the established generalization bounds are the first of their kind for Information Bottleneck (IB) type encoders and representation learning. Finally, we partly exploit the theoretical results by introducing a new data-dependent prior. Numerical simulations illustrate the advantages of well-chosen such priors over classical priors used in IB.
There are no more papers matching your filters at the moment.
