
05 Oct 2024
LEFUSION introduces a lesion-focused diffusion model that synthesizes high-fidelity pathological medical images with controllable lesion properties, significantly improving the performance of state-of-the-art segmentation models on lung nodule CT and cardiac lesion MRI datasets. The method ensures perfect background preservation while enabling fine-grained control over lesion texture, size, location, and boundary.

09 Mar 2025

Accurate medical image segmentation is crucial for precise anatomical
delineation. Deep learning models like U-Net have shown great success but
depend heavily on large datasets and struggle with domain shifts, complex
structures, and limited training samples. Recent studies have explored
diffusion models for segmentation by iteratively refining masks. However, these
methods still retain the conventional image-to-mask mapping, making them highly
sensitive to input data, which hampers stability and generalization. In
contrast, we introduce DiffAtlas, a novel generative framework that models both
images and masks through diffusion during training, effectively ``GenAI-fying''
atlas-based segmentation. During testing, the model is guided to generate a
specific target image-mask pair, from which the corresponding mask is obtained.
DiffAtlas retains the robustness of the atlas paradigm while overcoming its
scalability and domain-specific limitations. Extensive experiments on CT and
MRI across same-domain, cross-modality, varying-domain, and different
data-scale settings using the MMWHS and TotalSegmentator datasets demonstrate
that our approach outperforms existing methods, particularly in limited-data
and zero-shot modality segmentation. Code is available at
this https URL

26 Sep 2025
 University of Science and Technology of ChinaUniversity of Science and Technology of China (USTC)Suzhou Institute for Advanced ResearchThe First Affiliated Hospital of USTCState Key Laboratory of Precision and Intelligent ChemistryCenter for Medical Imaging, Robotics, Analytic Computing & Learning (MIRACLE)Jiangsu Provincial Key Laboratory of Multimodal Digital Twin Technology
University of Science and Technology of ChinaUniversity of Science and Technology of China (USTC)Suzhou Institute for Advanced ResearchThe First Affiliated Hospital of USTCState Key Laboratory of Precision and Intelligent ChemistryCenter for Medical Imaging, Robotics, Analytic Computing & Learning (MIRACLE)Jiangsu Provincial Key Laboratory of Multimodal Digital Twin TechnologyLarge language models (LLMs) have demonstrated notable potential in medical applications, yet they face substantial challenges in handling complex real-world clinical diagnoses using conventional prompting methods. Current prompt engineering and multi-agent approaches typically optimize isolated inferences, neglecting the accumulation of reusable clinical experience. To address this, this study proposes a novel Multi-Agent Clinical Diagnosis (MACD) framework, which allows LLMs to self-learn clinical knowledge via a multi-agent pipeline that summarizes, refines, and applies diagnostic insights. It mirrors how physicians develop expertise through experience, enabling more focused and accurate diagnosis on key disease-specific cues. We further extend it to a MACD-human collaborative workflow, where multiple LLM-based diagnostician agents engage in iterative consultations, supported by an evaluator agent and human oversight for cases where agreement is not reached. Evaluated on 4,390 real-world patient cases across seven diseases using diverse open-source LLMs (Llama-3.1 8B/70B, DeepSeek-R1-Distill-Llama 70B), MACD significantly improves primary diagnostic accuracy, outperforming established clinical guidelines with gains up to 22.3% (MACD). In direct comparison with physician-only diagnosis under the same evaluation protocol, MACD achieves comparable or superior performance, with improvements up to 16%. Furthermore, the MACD-human workflow yields an 18.6% improvement over physician-only diagnosis, demonstrating the synergistic potential of human-AI collaboration. Notably, the self-learned clinical knowledge exhibits strong cross-model stability, transferability across LLMs, and capacity for model-specific this http URL work thus presents a scalable self-learning paradigm that bridges the gap between the intrinsic knowledge of LLMs.

28 Feb 2025


I2VControl-Camera introduces a method for image-to-video generation that offers precise control over camera movements and adjustable strength for subject motion. It achieves this by using 2D point trajectories for camera control and higher-order trajectory components for subject dynamics, integrated within an adapter-based architecture. The approach significantly reduces rotational and translational errors in camera control while enabling explicit modulation of subject motion from static to dynamic.

12 Feb 2025


Medical image segmentation remains a formidable challenge due to the label
scarcity. Pre-training Vision Transformer (ViT) through masked image modeling
(MIM) on large-scale unlabeled medical datasets presents a promising solution,
providing both computational efficiency and model generalization for various
downstream tasks. However, current ViT-based MIM pre-training frameworks
predominantly emphasize local aggregation representations in output layers and
fail to exploit the rich representations across different ViT layers that
better capture fine-grained semantic information needed for more precise
medical downstream tasks. To fill the above gap, we hereby present Hierarchical
Encoder-driven MAE (Hi-End-MAE), a simple yet effective ViT-based pre-training
solution, which centers on two key innovations: (1) Encoder-driven
reconstruction, which encourages the encoder to learn more informative features
to guide the reconstruction of masked patches; and (2) Hierarchical dense
decoding, which implements a hierarchical decoding structure to capture rich
representations across different layers. We pre-train Hi-End-MAE on a
large-scale dataset of 10K CT scans and evaluated its performance across seven
public medical image segmentation benchmarks. Extensive experiments demonstrate
that Hi-End-MAE achieves superior transfer learning capabilities across various
downstream tasks, revealing the potential of ViT in medical imaging
applications. The code is available at:
this https URL

22 Jan 2025
Unsupervised anomaly detection (UAD) from images strives to model normal data distributions, creating discriminative representations to distinguish and precisely localize anomalies. Despite recent advancements in the efficient and unified one-for-all scheme, challenges persist in accurately segmenting anomalies for further monitoring. Moreover, this problem is obscured by the widely-used AUROC metric under imbalanced UAD settings. This motivates us to emphasize the significance of precise segmentation of anomaly pixels using pAP and DSC as metrics. To address the unsolved segmentation task, we introduce the Unified Anomaly Segmentation (UniAS). UniAS presents a multi-level hybrid pipeline that progressively enhances normal information from coarse to fine, incorporating a novel multi-granularity gated CNN (MGG-CNN) into Transformer layers to explicitly aggregate local details from different granularities. UniAS achieves state-of-the-art anomaly segmentation performance, attaining 65.12/59.33 and 40.06/32.50 in pAP/DSC on the MVTec-AD and VisA datasets, respectively, surpassing previous methods significantly. The codes are shared at this https URL.

26 Nov 2025

Large language models (LLM) have emerged as a promising avenue for time series forecasting, offering the potential to integrate multimodal data. However, existing LLM-based approaches face notable limitations-such as marginalized role in model architectures, reliance on coarse statistical text prompts, and lack of interpretability. In this work, we introduce Augur, a fully LLM driven time series forecasting framework that exploits LLM causal reasoning to discover and use directed causal associations among covariates. Augur uses a two stage teacher student architecture where a powerful teacher LLM infers a directed causal graph from time series using heuristic search together with pairwise causality testing. A lightweight student agent then refines the graph and fine tune on high confidence causal associations that are encoded as rich textual prompts to perform forecasting. This design improves predictive accuracy while yielding transparent, traceable reasoning about variable interactions. Extensive experiments on real-world datasets with 26 baselines demonstrate that Augur achieves competitive performance and robust zero-shot generalization.

15 Jul 2025
Achieving equity in healthcare accessibility requires lightweight yet high-performance solutions for medical image segmentation, particularly in resource-limited settings. Existing methods like U-Net and its variants often suffer from limited global Effective Receptive Fields (ERFs), hindering their ability to capture long-range dependencies. To address this, we propose U-RWKV, a novel framework leveraging the Recurrent Weighted Key-Value(RWKV) architecture, which achieves efficient long-range modeling at O(N) computational cost. The framework introduces two key innovations: the Direction-Adaptive RWKV Module(DARM) and the Stage-Adaptive Squeeze-and-Excitation Module(SASE). DARM employs Dual-RWKV and QuadScan mechanisms to aggregate contextual cues across images, mitigating directional bias while preserving global context and maintaining high computational efficiency. SASE dynamically adapts its architecture to different feature extraction stages, balancing high-resolution detail preservation and semantic relationship capture. Experiments demonstrate that U-RWKV achieves state-of-the-art segmentation performance with high computational efficiency, offering a practical solution for democratizing advanced medical imaging technologies in resource-constrained environments. The code is available at this https URL.

16 Oct 2024
SiFiSinger introduces an end-to-end singing voice synthesizer that integrates a neural source-filter model and differentiable acoustic feature reconstruction losses to improve synthesis fidelity. The system achieves a lower F0 RMSE of 42.93 Hz and a higher Mean Opinion Score of 3.77, outperforming the VISinger 2 baseline while operating with a smaller model size.

08 Jan 2025
Binaural speech enhancement (BSE) aims to jointly improve the speech quality
and intelligibility of noisy signals received by hearing devices and preserve
the spatial cues of the target for natural listening. Existing methods often
suffer from the compromise between noise reduction (NR) capacity and spatial
cues preservation (SCP) accuracy and a high computational demand in complex
acoustic scenes. In this work, we present a learning-based lightweight binaural
complex convolutional network (LBCCN), which excels in NR by filtering
low-frequency bands and keeping the rest. Additionally, our approach explicitly
incorporates the estimation of interchannel relative acoustic transfer function
to ensure the spatial cues fidelity and speech clarity. Results show that the
proposed LBCCN can achieve a comparable NR performance to state-of-the-art
methods under fixed-speaker conditions, but with a much lower computational
cost and a certain degree of SCP capability. The reproducible code and audio
examples are available at this https URL

08 Jun 2024
Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.

21 Oct 2025
3D landmark detection is a critical task in medical image analysis, and accurately detecting anatomical landmarks is essential for subsequent medical imaging tasks. However, mainstream deep learning methods in this field struggle to simultaneously capture fine-grained local features and model global spatial relationships, while maintaining a balance between accuracy and computational efficiency. Local feature extraction requires capturing fine-grained anatomical details, while global modeling requires understanding the spatial relationships within complex anatomical structures. The high-dimensional nature of 3D volume further exacerbates these challenges, as landmarks are sparsely distributed, leading to significant computational costs. Therefore, achieving efficient and precise 3D landmark detection remains a pressing challenge in medical image analysis.
In this work, We propose a \textbf{H}ybrid \textbf{3}D \textbf{DE}tection \textbf{Net}(H3DE-Net), a novel framework that combines CNNs for local feature extraction with a lightweight attention mechanism designed to efficiently capture global dependencies in 3D volumetric data. This mechanism employs a hierarchical routing strategy to reduce computational cost while maintaining global context modeling. To our knowledge, H3DE-Net is the first 3D landmark detection model that integrates such a lightweight attention mechanism with CNNs. Additionally, integrating multi-scale feature fusion further enhances detection accuracy and robustness. Experimental results on a public CT dataset demonstrate that H3DE-Net achieves state-of-the-art(SOTA) performance, significantly improving accuracy and robustness, particularly in scenarios with missing landmarks or complex anatomical variations. We aready open-source our project, including code, data and model weights.

24 Mar 2025
In multimodal sentiment analysis, collecting text data is often more
challenging than video or audio due to higher annotation costs and inconsistent
automatic speech recognition (ASR) quality. To address this challenge, our
study has developed a robust model that effectively integrates multimodal
sentiment information, even in the absence of text modality. Specifically, we
have developed a Double-Flow Self-Distillation Framework, including Unified
Modality Cross-Attention (UMCA) and Modality Imagination Autoencoder (MIA),
which excels at processing both scenarios with complete modalities and those
with missing text modality. In detail, when the text modality is missing, our
framework uses the LLM-based model to simulate the text representation from the
audio modality, while the MIA module supplements information from the other two
modalities to make the simulated text representation similar to the real text
representation. To further align the simulated and real representations, and to
enable the model to capture the continuous nature of sample orders in sentiment
valence regression tasks, we have also introduced the Rank-N Contrast (RNC)
loss function. When testing on the CMU-MOSEI, our model achieved outstanding
performance on MAE and significantly outperformed other models when text
modality is missing. The code is available at:
this https URL

24 Oct 2024


Research into the external behaviors and internal mechanisms of large language models (LLMs) has shown promise in addressing complex tasks in the physical world. Studies suggest that powerful LLMs, like GPT-4, are beginning to exhibit human-like cognitive abilities, including planning, reasoning, and reflection. In this paper, we introduce a research line and methodology called LLM Psychology, leveraging human psychology experiments to investigate the cognitive behaviors and mechanisms of LLMs. We migrate the Typoglycemia phenomenon from psychology to explore the "mind" of LLMs. Unlike human brains, which rely on context and word patterns to comprehend scrambled text, LLMs use distinct encoding and decoding processes. Through Typoglycemia experiments at the character, word, and sentence levels, we observe: (I) LLMs demonstrate human-like behaviors on a macro scale, such as lower task accuracy and higher token/time consumption; (II) LLMs exhibit varying robustness to scrambled input, making Typoglycemia a benchmark for model evaluation without new datasets; (III) Different task types have varying impacts, with complex logical tasks (e.g., math) being more challenging in scrambled form; (IV) Each LLM has a unique and consistent "cognitive pattern" across tasks, revealing general mechanisms in its psychology process. We provide an in-depth analysis of hidden layers to explain these phenomena, paving the way for future research in LLM Psychology and deeper interpretability.

22 Nov 2022
SinDiffusion, developed by Microsoft Research Asia and University of Science and Technology of China, proposes a novel framework that uses diffusion models to learn from a single natural image. This approach generates higher quality and more diverse image variations compared to prior GAN-based methods, effectively avoiding common artifacts while enabling applications like text-guided generation and image outpainting.
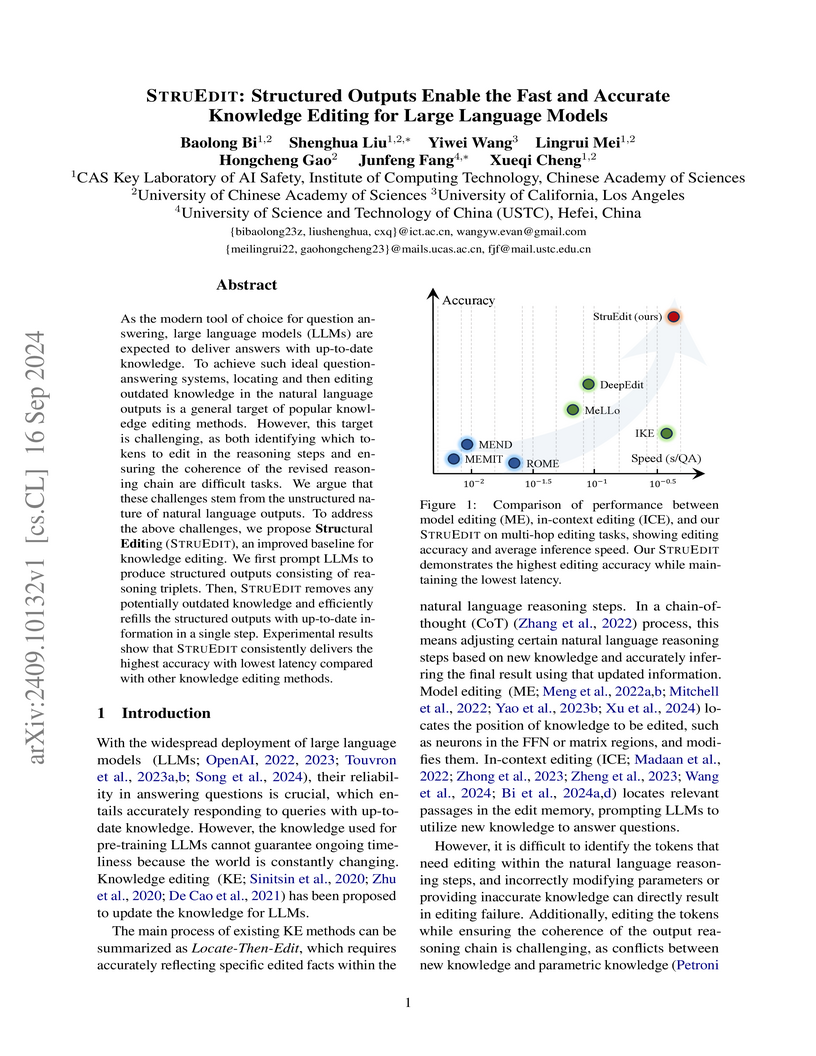
16 Sep 2024

STRUEDIT, developed by researchers from the CAS Key Laboratory of AI Safety, introduces a knowledge editing approach for Large Language Models that leverages structured outputs and a "remove-then-refill" strategy. This method enables faster and more accurate knowledge updates, particularly for multi-hop reasoning, outperforming existing techniques in accuracy, speed, and robustness across varying reasoning complexities and numbers of edits.

04 Jun 2024

Currently, the field of structure-based drug design is dominated by three main types of algorithms: search-based algorithms, deep generative models, and reinforcement learning. While existing works have typically focused on comparing models within a single algorithmic category, cross-algorithm comparisons remain scarce. In this paper, to fill the gap, we establish a benchmark to evaluate the performance of sixteen models across these different algorithmic foundations by assessing the pharmaceutical properties of the generated molecules and their docking affinities with specified target proteins. We highlight the unique advantages of each algorithmic approach and offer recommendations for the design of future SBDD models. We emphasize that 1D/2D ligand-centric drug design methods can be used in SBDD by treating the docking function as a black-box oracle, which is typically neglected. The empirical results show that 1D/2D methods achieve competitive performance compared with 3D-based methods that use the 3D structure of the target protein explicitly. Also, AutoGrow4, a 2D molecular graph-based genetic algorithm, dominates SBDD in terms of optimization ability. The relevant code is available in this https URL.

30 Aug 2025
The recent advance in multi-camera 3D object detection is featured by bird's-eye view (BEV) representation or object queries. However, the ill-posed transformation from image-plane view to 3D space inevitably causes feature clutter and distortion, making the objects blur into the background. To this end, we explore how to incorporate supplementary cues for differentiating objects in the transformed feature representation. Formally, we introduce OA-DET3D, a general plug-in module that improves 3D object detection by bringing object awareness into a variety of existing 3D object detection pipelines. Specifically, OA-DET3D boosts the representation of objects by leveraging object-centric depth information and foreground pseudo points. First, we use object-level supervision from the properties of each 3D bounding box to guide the network in learning the depth distribution. Next, we select foreground pixels using a 2D object detector and project them into 3D space for pseudo-voxel feature encoding. Finally, the object-aware depth features and pseudo-voxel features are incorporated into the BEV representation or query feature from the baseline model with a deformable attention mechanism. We conduct extensive experiments on the nuScenes dataset and Argoverse 2 dataset to validate the merits of OA-DET3D. Our method achieves consistent improvements over the BEV-based baselines in terms of both average precision and comprehensive detection score.

09 Mar 2025

Magnetic Resonance Imaging (MRI), including diffusion MRI (dMRI), serves as a
``microscope'' for anatomical structures and routinely mitigates the influence
of low signal-to-noise ratio scans by compromising temporal or spatial
resolution. However, these compromises fail to meet clinical demands for both
efficiency and precision. Consequently, denoising is a vital preprocessing
step, particularly for dMRI, where clean data is unavailable. In this paper, we
introduce Di-Fusion, a fully self-supervised denoising method that leverages
the latter diffusion steps and an adaptive sampling process. Unlike previous
approaches, our single-stage framework achieves efficient and stable training
without extra noise model training and offers adaptive and controllable results
in the sampling process. Our thorough experiments on real and simulated data
demonstrate that Di-Fusion achieves state-of-the-art performance in
microstructure modeling, tractography tracking, and other downstream tasks.
Code is available at this https URL

26 May 2025

Due to the profound impact of air pollution on human health, livelihoods, and
economic development, air quality forecasting is of paramount significance.
Initially, we employ the causal graph method to scrutinize the constraints of
existing research in comprehensively modeling the causal relationships between
the air quality index (AQI) and meteorological features. In order to enhance
prediction accuracy, we introduce a novel air quality forecasting model,
AirCade, which incorporates a causal decoupling approach. AirCade leverages a
spatiotemporal module in conjunction with knowledge embedding techniques to
capture the internal dynamics of AQI. Subsequently, a causal decoupling module
is proposed to disentangle synchronous causality from past AQI and
meteorological features, followed by the dissemination of acquired knowledge to
future time steps to enhance performance. Additionally, we introduce a causal
intervention mechanism to explicitly represent the uncertainty of future
meteorological features, thereby bolstering the model's robustness. Our
evaluation of AirCade on an open-source air quality dataset demonstrates over
20\% relative improvement over state-of-the-art models.
There are no more papers matching your filters at the moment.
