
14 Feb 2025



OMNI-EPIC introduces an open-ended framework that uses large foundation models to autonomously generate diverse, learnable, and interesting reinforcement learning environments programmed in code. The system demonstrates an ability to generate a continuous stream of challenging tasks, achieving higher task diversity and progress metrics than control methods.

30 Sep 2025




We introduce DRBench, a benchmark for evaluating AI agents on complex, open-ended deep research tasks in enterprise settings. Unlike prior benchmarks that focus on simple questions or web-only queries, DRBench evaluates agents on multi-step queries (for example, ``What changes should we make to our product roadmap to ensure compliance with this standard?") that require identifying supporting facts from both the public web and private company knowledge base. Each task is grounded in realistic user personas and enterprise context, spanning a heterogeneous search space that includes productivity software, cloud file systems, emails, chat conversations, and the open web. Tasks are generated through a carefully designed synthesis pipeline with human-in-the-loop verification, and agents are evaluated on their ability to recall relevant insights, maintain factual accuracy, and produce coherent, well-structured reports. We release 15 deep research tasks across 10 domains, such as Sales, Cybersecurity, and Compliance. We demonstrate the effectiveness of DRBench by evaluating diverse DR agents across open- and closed-source models (such as GPT, Llama, and Qwen) and DR strategies, highlighting their strengths, weaknesses, and the critical path for advancing enterprise deep research. Code is available at this https URL.

30 Oct 2025

This study traces the dynamic acquisition of human values in Large Language Models during supervised fine-tuning and preference optimization, revealing that supervised fine-tuning primarily establishes a model's foundational values, while subsequent preference optimization only effectively reshapes values when specific 'value-gaps' exist in the preference data.

10 Jul 2019

Domain randomization is a popular technique for improving domain transfer, often used in a zero-shot setting when the target domain is unknown or cannot easily be used for training. In this work, we empirically examine the effects of domain randomization on agent generalization. Our experiments show that domain randomization may lead to suboptimal, high-variance policies, which we attribute to the uniform sampling of environment parameters. We propose Active Domain Randomization, a novel algorithm that learns a parameter sampling strategy. Our method looks for the most informative environment variations within the given randomization ranges by leveraging the discrepancies of policy rollouts in randomized and reference environment instances. We find that training more frequently on these instances leads to better overall agent generalization. Our experiments across various physics-based simulated and real-robot tasks show that this enhancement leads to more robust, consistent policies.

30 Oct 2024

Recurrent Neural Networks (RNNs) are used to learn representations in partially observable environments. For agents that learn online and continually interact with the environment, it is desirable to train RNNs with real-time recurrent learning (RTRL); unfortunately, RTRL is prohibitively expensive for standard RNNs. A promising direction is to use linear recurrent architectures (LRUs), where dense recurrent weights are replaced with a complex-valued diagonal, making RTRL efficient. In this work, we build on these insights to provide a lightweight but effective approach for training RNNs in online RL. We introduce Recurrent Trace Units (RTUs), a small modification on LRUs that we nonetheless find to have significant performance benefits over LRUs when trained with RTRL. We find RTUs significantly outperform other recurrent architectures across several partially observable environments while using significantly less computation.

03 Apr 2024
The ability to learn good representations of states is essential for solving
large reinforcement learning problems, where exploration, generalization, and
transfer are particularly challenging. The Laplacian representation is a
promising approach to address these problems by inducing informative state
encoding and intrinsic rewards for temporally-extended action discovery and
reward shaping. To obtain the Laplacian representation one needs to compute the
eigensystem of the graph Laplacian, which is often approximated through
optimization objectives compatible with deep learning approaches. These
approximations, however, depend on hyperparameters that are impossible to tune
efficiently, converge to arbitrary rotations of the desired eigenvectors, and
are unable to accurately recover the corresponding eigenvalues. In this paper
we introduce a theoretically sound objective and corresponding optimization
algorithm for approximating the Laplacian representation. Our approach
naturally recovers both the true eigenvectors and eigenvalues while eliminating
the hyperparameter dependence of previous approximations. We provide
theoretical guarantees for our method and we show that those results translate
empirically into robust learning across multiple environments.

15 Oct 2024
In this paper we investigate transformer architectures designed for partially observable online reinforcement learning. The self-attention mechanism in the transformer architecture is capable of capturing long-range dependencies and it is the main reason behind its effectiveness in processing sequential data. Nevertheless, despite their success, transformers have two significant drawbacks that still limit their applicability in online reinforcement learning: (1) in order to remember all past information, the self-attention mechanism requires access to the whole history to be provided as context. (2) The inference cost in transformers is expensive. In this paper, we introduce recurrent alternatives to the transformer self-attention mechanism that offer context-independent inference cost, leverage long-range dependencies effectively, and performs well in online reinforcement learning task. We quantify the impact of the different components of our architecture in a diagnostic environment and assess performance gains in 2D and 3D pixel-based partially-observable environments (e.g. T-Maze, Mystery Path, Craftax, and Memory Maze). Compared with a state-of-the-art architecture, GTrXL, inference in our approach is at least 40% cheaper while reducing memory use more than 50%. Our approach either performs similarly or better than GTrXL, improving more than 37% upon GTrXL performance in harder tasks.

06 Feb 2025
Knowledge distillation (KD) is a popular method of transferring knowledge
from a large "teacher" model to a small "student" model. KD can be divided into
two categories: prediction matching and intermediate-layer matching. We explore
an intriguing phenomenon: layer-selection strategy does not matter (much) in
intermediate-layer matching. In this paper, we show that seemingly nonsensical
matching strategies such as matching the teacher's layers in reverse still
result in surprisingly good student performance. We provide an interpretation
for this phenomenon by examining the angles between teacher layers viewed from
the student's perspective.

07 Jun 2024


Large language models (LLMs) have excelled in various natural language processing tasks, but challenges in interpretability and trustworthiness persist, limiting their use in high-stakes fields. Causal discovery offers a promising approach to improve transparency and reliability. However, current evaluations are often one-sided and lack assessments focused on interpretability performance. Additionally, these evaluations rely on synthetic data and lack comprehensive assessments of real-world datasets. These lead to promising methods potentially being overlooked. To address these issues, we propose a flexible evaluation framework with metrics for evaluating differences in causal structures and causal effects, which are crucial attributes that help improve the interpretability of LLMs. We introduce the Open Causal Discovery Benchmark (OCDB), based on real data, to promote fair comparisons and drive optimization of algorithms. Additionally, our new metrics account for undirected edges, enabling fair comparisons between Directed Acyclic Graphs (DAGs) and Completed Partially Directed Acyclic Graphs (CPDAGs). Experimental results show significant shortcomings in existing algorithms' generalization capabilities on real data, highlighting the potential for performance improvement and the importance of our framework in advancing causal discovery techniques.

11 Jul 2025
The development of signal unmixing algorithms is essential for leveraging multimodal datasets acquired through a wide array of scientific imaging technologies, including hyperspectral or time-resolved acquisitions. In experimental physics, enhancing the spatio-temporal resolution or expanding the number of detection channels often leads to diminished sampling rate and signal-to-noise ratio, significantly affecting the efficacy of signal unmixing algorithms. We propose Latent Unmixing, a new approach which applies bandpass filters to the latent space of a multidimensional convolutional neural network to disentangle overlapping signal components. It enables better isolation and quantification of individual signal contributions, especially in the context of undersampled distributions. Using multidimensional convolution kernels to process all dimensions simultaneously enhances the network's ability to extract information from adjacent pixels, and time or spectral bins. This approach enables more effective separation of components in cases where individual pixels do not provide clear, well-resolved information. We showcase the method's practical use in experimental physics through two test cases that highlight the versatility of our approach: fluorescence lifetime microscopy and mode decomposition in optical fibers. The latent unmixing method extracts valuable information from complex signals that cannot be resolved by standard methods. It opens up new possibilities in optics and photonics for multichannel separation at an increased sampling rate.

20 Jun 2021
Popular approaches for minimizing loss in data-driven learning often involve an abstraction or an explicit retention of the history of gradients for efficient parameter updates. The aggregated history of gradients nudges the parameter updates in the right direction even when the gradients at any given step are not informative. Although the history of gradients summarized in meta-parameters or explicitly stored in memory has been shown effective in theory and practice, the question of whether or only a subset of the gradients in the history are sufficient in deciding the parameter updates remains unanswered. In this paper, we propose a framework of memory-augmented gradient descent optimizers that retain a limited view of their gradient history in their internal memory. Such optimizers scale well to large real-life datasets, and our experiments show that the memory augmented extensions of standard optimizers enjoy accelerated convergence and improved performance on a majority of computer vision and language tasks that we considered. Additionally, we prove that the proposed class of optimizers with fixed-size memory converge under assumptions of strong convexity, regardless of which gradients are selected or how they are linearly combined to form the update step.

21 Mar 2023
Energy-efficient deep neural network (DNN) accelerators are prone to non-idealities that degrade DNN performance at inference time. To mitigate such degradation, existing methods typically add perturbations to the DNN weights during training to simulate inference on noisy hardware. However, this often requires knowledge about the target hardware and leads to a trade-off between DNN performance and robustness, decreasing the former to increase the latter. In this work, we show that applying sharpness-aware training, by optimizing for both the loss value and loss sharpness, significantly improves robustness to noisy hardware at inference time without relying on any assumptions about the target hardware. In particular, we propose a new adaptive sharpness-aware method that conditions the worst-case perturbation of a given weight not only on its magnitude but also on the range of the weight distribution. This is achieved by performing sharpness-aware minimization scaled by outlier minimization (SAMSON). Our approach outperforms existing sharpness-aware training methods both in terms of model generalization performance in noiseless regimes and robustness in noisy settings, as measured on several architectures and datasets.

19 Jun 2020
Reasoning about graphs evolving over time is a challenging concept in many domains, such as bioinformatics, physics, and social networks. We consider a common case in which edges can be short term interactions (e.g., messaging) or long term structural connections (e.g., friendship). In practice, long term edges are often specified by humans. Human-specified edges can be both expensive to produce and suboptimal for the downstream task. To alleviate these issues, we propose a model based on temporal point processes and variational autoencoders that learns to infer temporal attention between nodes by observing node communication. As temporal attention drives between-node feature propagation, using the dynamics of node interactions to learn this key component provides more flexibility while simultaneously avoiding issues associated with human-specified edges. We also propose a bilinear transformation layer for pairs of node features instead of concatenation, typically used in prior work, and demonstrate its superior performance in all cases. In experiments on two datasets in the dynamic link prediction task, our model often outperforms the baseline model that requires a human-specified graph. Moreover, our learned attention is semantically interpretable and infers connections similar to actual graphs.

26 Nov 2024
TrackPGD: Efficient Adversarial Attack using Object Binary Masks against Robust Transformer Trackers
TrackPGD: Efficient Adversarial Attack using Object Binary Masks against Robust Transformer Trackers
Adversarial perturbations can deceive neural networks by adding small, imperceptible noise to the input. Recent object trackers with transformer backbones have shown strong performance on tracking datasets, but their adversarial robustness has not been thoroughly evaluated. While transformer trackers are resilient to black-box attacks, existing white-box adversarial attacks are not universally applicable against these new transformer trackers due to differences in backbone architecture. In this work, we introduce TrackPGD, a novel white-box attack that utilizes predicted object binary masks to target robust transformer trackers. Built upon the powerful segmentation attack SegPGD, our proposed TrackPGD effectively influences the decisions of transformer-based trackers. Our method addresses two primary challenges in adapting a segmentation attack for trackers: limited class numbers and extreme pixel class imbalance. TrackPGD uses the same number of iterations as other attack methods for tracker networks and produces competitive adversarial examples that mislead transformer and non-transformer trackers such as MixFormerM, OSTrackSTS, TransT-SEG, and RTS on datasets including VOT2022STS, DAVIS2016, UAV123, and GOT-10k.

12 Jul 2022


The ICML 2022 Expressive Vocalizations (EXVO) Workshop and Competition introduced the large-scale, diverse HUME-VB dataset to foster advancements in recognizing, generating, and personalizing non-linguistic vocal bursts. It established initial benchmarks across three distinct machine learning tracks, highlighting capabilities and areas for improvement in this under-researched area of human emotional expression.
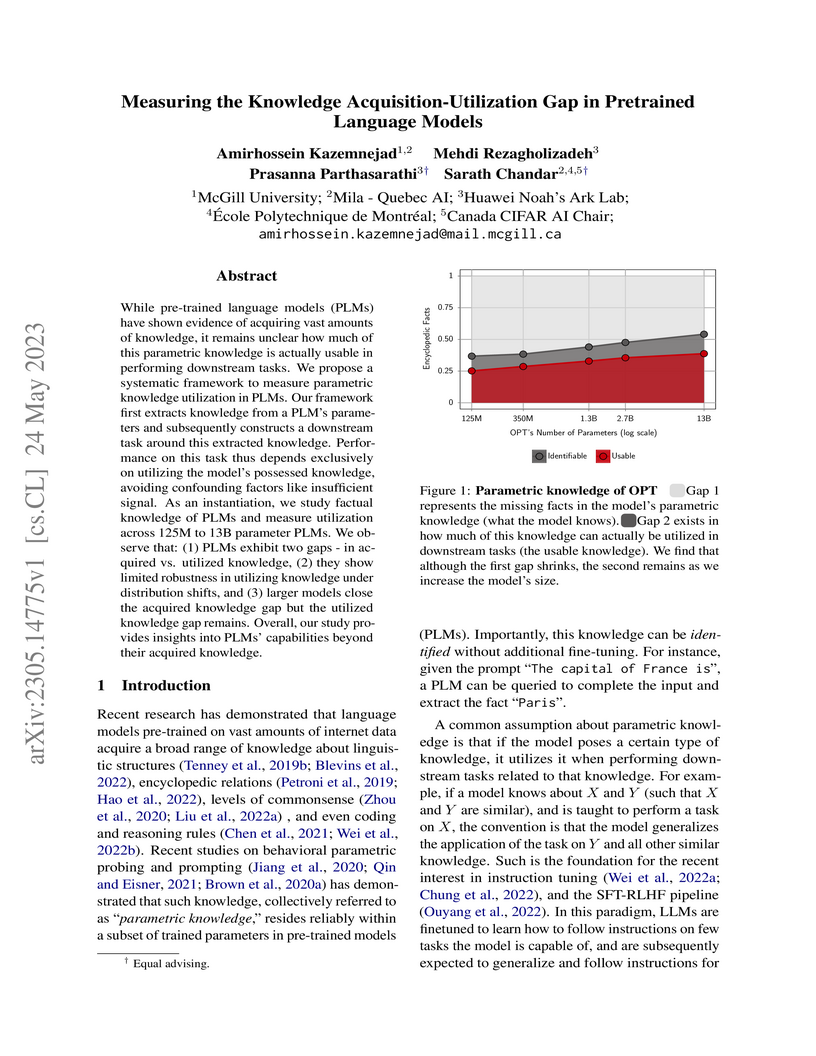
24 May 2023
While pre-trained language models (PLMs) have shown evidence of acquiring
vast amounts of knowledge, it remains unclear how much of this parametric
knowledge is actually usable in performing downstream tasks. We propose a
systematic framework to measure parametric knowledge utilization in PLMs. Our
framework first extracts knowledge from a PLM's parameters and subsequently
constructs a downstream task around this extracted knowledge. Performance on
this task thus depends exclusively on utilizing the model's possessed
knowledge, avoiding confounding factors like insufficient signal. As an
instantiation, we study factual knowledge of PLMs and measure utilization
across 125M to 13B parameter PLMs. We observe that: (1) PLMs exhibit two gaps -
in acquired vs. utilized knowledge, (2) they show limited robustness in
utilizing knowledge under distribution shifts, and (3) larger models close the
acquired knowledge gap but the utilized knowledge gap remains. Overall, our
study provides insights into PLMs' capabilities beyond their acquired
knowledge.

08 Feb 2024
Researchers at Mila investigated whether in-context learning (ICL) can compel large language models to re-learn tasks they were fine-tuned to refuse or to bypass safety alignments. The study found that ICL can restore forbidden behaviors and increase the generation of harmful content, achieving up to 51% success for re-learning sentiment classification and 72% for harmful content generation in some models, while LLAMA2-7B demonstrated strong resilience against these specific ICL attacks.

26 Nov 2022
Minimal changes to neural architectures (e.g. changing a single
hyperparameter in a key layer), can lead to significant gains in predictive
performance in Convolutional Neural Networks (CNNs). In this work, we present a
new approach to receptive field analysis that can yield these types of
theoretical and empirical performance gains across twenty well-known CNN
architectures examined in our experiments. By further developing and
formalizing the analysis of receptive field expansion in convolutional neural
networks, we can predict unproductive layers in an automated manner before ever
training a model. This allows us to optimize the parameter-efficiency of a
given architecture at low cost. Our method is computationally simple and can be
done in an automated manner or even manually with minimal effort for most
common architectures. We demonstrate the effectiveness of this approach by
increasing parameter efficiency across past and current top-performing
CNN-architectures. Specifically, our approach is able to improve ImageNet1K
performance across a wide range of well-known, state-of-the-art (SOTA) model
classes, including: VGG Nets, MobileNetV1, MobileNetV3, NASNet A (mobile),
MnasNet, EfficientNet, and ConvNeXt - leading to a new SOTA result for each
model class.

07 Jan 2023

Large capacity deep learning models are often prone to a high generalization gap when trained with a limited amount of labeled training data. A recent class of methods to address this problem uses various ways to construct a new training sample by mixing a pair (or more) of training samples. We propose PatchUp, a hidden state block-level regularization technique for Convolutional Neural Networks (CNNs), that is applied on selected contiguous blocks of feature maps from a random pair of samples. Our approach improves the robustness of CNN models against the manifold intrusion problem that may occur in other state-of-the-art mixing approaches. Moreover, since we are mixing the contiguous block of features in the hidden space, which has more dimensions than the input space, we obtain more diverse samples for training towards different dimensions. Our experiments on CIFAR10/100, SVHN, Tiny-ImageNet, and ImageNet using ResNet architectures including PreActResnet18/34, WRN-28-10, ResNet101/152 models show that PatchUp improves upon, or equals, the performance of current state-of-the-art regularizers for CNNs. We also show that PatchUp can provide a better generalization to deformed samples and is more robust against adversarial attacks.

20 Jun 2021
Neural models trained for next utterance generation in dialogue task learn to mimic the n-gram sequences in the training set with training objectives like negative log-likelihood (NLL) or cross-entropy. Such commonly used training objectives do not foster generating alternate responses to a context. But, the effects of minimizing an alternate training objective that fosters a model to generate alternate response and score it on semantic similarity has not been well studied. We hypothesize that a language generation model can improve on its diversity by learning to generate alternate text during training and minimizing a semantic loss as an auxiliary objective. We explore this idea on two different sized data sets on the task of next utterance generation in goal oriented dialogues. We make two observations (1) minimizing a semantic objective improved diversity in responses in the smaller data set (Frames) but only as-good-as minimizing the NLL in the larger data set (MultiWoZ) (2) large language model embeddings can be more useful as a semantic loss objective than as initialization for token embeddings.
There are no more papers matching your filters at the moment.
