Ask or search anything...


 Peking University
Peking University Microsoft
MicrosoftThis survey systematically reviews Knowledge Distillation (KD) techniques for Large Language Models (LLMs), outlining methods for transferring capabilities from large proprietary models to smaller, more accessible open-source ones. It categorizes KD approaches by algorithms, skill distillation, and verticalization, highlighting the central role of data augmentation and iterative self-improvement for democratizing advanced LLM capabilities.
View blog
 Zhejiang University
Zhejiang UniversityResearchers from Zhejiang University's CCAI provide a comprehensive survey on world models for autonomous driving, establishing a three-tiered taxonomy to organize architectural innovations, training paradigms, and evaluation metrics. The survey synthesizes advancements in future physical world generation, intelligent agent behavior planning, and the interaction between prediction and planning, while identifying key trends and future research directions.
View blog
This paper presents MemVR, a novel decoding paradigm that effectively mitigates hallucinations in Multimodal Large Language Models by strategically re-injecting visual information into the model's memory space. It improves factual consistency and general capabilities across various benchmarks while incurring minimal computational overhead compared to existing methods.
View blog
 University of Maryland
University of MarylandResearchers from Australian AI Institute and collaborating institutions introduce WALL-E 2.0, a neurosymbolic framework that enables LLM agents to build accurate world models through integration of symbolic knowledge (action rules, knowledge graphs, scene graphs), achieving 98% success rate in ALFWorld and outperforming baselines by 16.1-51.6% in Mars environments without requiring model fine-tuning.
View blog
 University of Toronto
University of TorontoA memory management framework for multi-agent systems, SEDM, implements verifiable write admission, self-scheduling, and cross-domain knowledge diffusion to address noise accumulation and uncontrolled memory expansion. It enhances reasoning accuracy on benchmarks like LoCoMo, FEVER, and HotpotQA while reducing token consumption by up to 50% compared to previous memory systems.
View blog
 The Chinese University of Hong Kong
The Chinese University of Hong KongThis paper synthesizes the extensive and rapidly evolving literature on Large Language Models (LLMs), offering a structured resource on their architectures, training strategies, and applications. It provides a comprehensive overview of existing works, highlighting key design aspects, model capabilities, augmentation strategies, and efficiency techniques, while also discussing challenges and future research directions.
View blog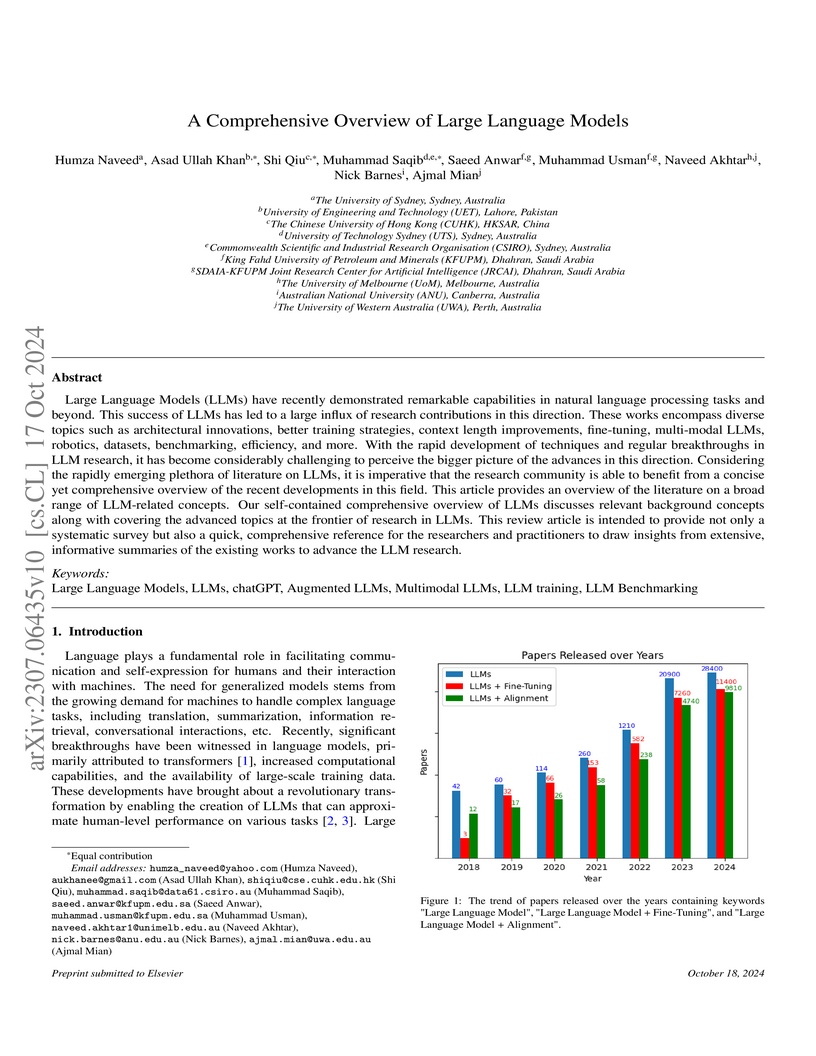
 Johns Hopkins University
Johns Hopkins UniversityR^2-Gaussian introduces a rectified 3D Gaussian Splatting framework for sparse-view X-ray tomographic reconstruction, correcting a previously unknown integration bias within 3DGS. This method achieves superior reconstruction quality, with up to 0.95 dB PSNR improvement, and significantly faster processing times, converging in approximately 15 minutes.
View blog
 Chinese Academy of Sciences
Chinese Academy of Sciences
 University of Waterloo
University of WaterlooResearch establishes that genuinely entangled qubit states cannot be unique ground states of two-body frustration-free Hamiltonians, indicating such conditions preclude their use as natural, robust resource states for one-way quantum computing. The work also generally demonstrates that any two-body frustration-free Hamiltonian for a qubit system always has a ground state that is a product of single- or two-qubit states.
View blog
 Imperial College London
Imperial College LondonRICE (Region-based Cluster Discrimination) establishes a framework for learning fine-grained, region-level visual representations, unifying object and OCR understanding from billions of image regions. This approach enhances performance in dense prediction tasks, multimodal large language models, and video object tracking, achieving new benchmarks across various evaluations.
View blog
 Monash University
Monash UniversityResearchers from the University of Technology Sydney, Monash University, and the University of Illinois at Chicago systematically organize the rapidly expanding field of Graph Neural Networks (GNNs), proposing a novel four-category taxonomy. The survey comprehensively reviews diverse GNN models, details theoretical foundations, identifies practical challenges, and compiles extensive resources for the research community.
View blog

 Beihang University
Beihang University
 Google DeepMind
Google DeepMindGoogle DeepMind and University of Technology Sydney researchers establish scaling laws for deepfake detection using ScaleDF, the largest and most diverse dataset to date. The work reveals predictable power-law scaling for data diversity (real domains and deepfake methods), with no saturation, and a double-saturating power-law for training image quantity, providing a framework for data-centric development.
View blog
 Meta
Meta The Hong Kong Polytechnic University
The Hong Kong Polytechnic UniversityThis survey paper presents a three-tier taxonomy for LLM-based recommender systems, categorizing developments from foundational understanding to industrial deployment. It outlines how Large Language Models improve user/item representation and recommendation understanding, details various integration strategies, and addresses the challenges and solutions for deploying these systems in real-world scenarios.
View blog
 Rutgers University
Rutgers UniversityPersonaX is a user modeling framework that efficiently processes long user behavior sequences for recommendation agents by decoupling offline multi-persona generation from online inference. It consistently outperforms baselines, improving recommendation accuracy and reducing online inference latency by up to 95%.
View blog
 Nanjing University
Nanjing UniversityThe T2MIR framework, from researchers at Nanjing University and the University of Technology Sydney, enhances in-context reinforcement learning by incorporating Mixture-of-Experts (MoE) to explicitly address the multi-modal nature of RL data and the challenges of diverse task distributions. This approach yields consistent performance improvements and stronger generalization across multiple multi-task environments.
View blog
Researchers from the University of Technology Sydney and Zhejiang University developed VideoCoF, a unified video editing framework that introduces a "Chain of Frames" approach for explicit visual reasoning. This method achieves mask-free, fine-grained edits, demonstrating a 15.14% improvement in instruction following and an 18.6% higher success ratio on their VideoCoF-Bench, while also providing robust length extrapolation.
View blog
 University of Maryland, College Park
University of Maryland, College ParkThe WALL-E system enables Large Language Models to serve as more reliable world models for agents by learning environment-specific rules through a neurosymbolic approach. This method achieved 69% success in Minecraft TechTree tasks and 95% in ALFWorld while significantly reducing token costs and replanning rounds compared to prior baselines.
View blog
FreKoo, a framework from the Australian Artificial Intelligence Institute, addresses temporal domain generalization by decomposing model parameter trajectories into frequency components. It models low-frequency dynamics with a Koopman operator to capture long-term periodicity and regularizes high-frequency components to mitigate local uncertainties, achieving state-of-the-art performance across diverse benchmarks with a 1.7% error rate on a key benchmark, outperforming previous methods like Koodos at 2.1%.
View blog

