
30 Dec 2024
This survey offers a comprehensive overview of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) in medicine, detailing their evolution, architectural principles, training methodologies, and diverse applications. It identifies key challenges and proposes future directions, providing a structured resource for researchers and practitioners in the field.

02 Jul 2025

CARE-RAG is a four-stage framework designed to enhance the trustworthiness of Retrieval-Augmented Generation (RAG) systems by explicitly identifying and resolving knowledge conflicts between a Large Language Model's internal knowledge and external retrieved evidence. This approach consistently achieved state-of-the-art performance across five QA benchmarks, improving Exact Match and F1 scores by up to 17.2 and 17.1 points respectively over standard RAG baselines.

07 Aug 2025
Video summarization aims to generate a compact, informative, and representative synopsis of raw videos, which is crucial for browsing, analyzing, and understanding video content. Dominant approaches in video summarization primarily rely on recurrent or convolutional neural networks, and more recently on encoder-only transformer architectures. However, these methods typically suffer from several limitations in parallelism, modeling long-range dependencies, and providing explicit generative capabilities. To address these issues, we propose a transformer-like architecture named FullTransNet with two-fold ideas. First, it uses a full transformer with an encoder-decoder structure as an alternative architecture for video summarization. As the full transformer is specifically designed for sequence transduction tasks, its direct application to video summarization is both intuitive and effective. Second, it replaces the standard full attention mechanism with a combination of local and global sparse attention, enabling the model to capture long-range dependencies while significantly reducing computational costs. This local-global sparse attention is applied exclusively at the encoder side, where the majority of computations occur, further enhancing efficiency. Extensive experiments on two widely used benchmark datasets, SumMe and TVSum, demonstrate that our model achieves F-scores of 54.4% and 63.9%, respectively, while maintaining relatively low computational and memory requirements. These results surpass the second-best performing methods by 0.1% and 0.3%, respectively, verifying the effectiveness and efficiency of FullTransNet.

19 Feb 2024

Empathetic response generation is increasingly significant in AI, necessitating nuanced emotional and cognitive understanding coupled with articulate response expression. Current large language models (LLMs) excel in response expression; however, they lack the ability to deeply understand emotional and cognitive nuances, particularly in pinpointing fine-grained emotions and their triggers. Conversely, small-scale empathetic models (SEMs) offer strength in fine-grained emotion detection and detailed emotion cause identification. To harness the complementary strengths of both LLMs and SEMs, we introduce a Hybrid Empathetic Framework (HEF). HEF regards SEMs as flexible plugins to improve LLM's nuanced emotional and cognitive understanding. Regarding emotional understanding, HEF implements a two-stage emotion prediction strategy, encouraging LLMs to prioritize primary emotions emphasized by SEMs, followed by other categories, substantially alleviates the difficulties for LLMs in fine-grained emotion detection. Regarding cognitive understanding, HEF employs an emotion cause perception strategy, prompting LLMs to focus on crucial emotion-eliciting words identified by SEMs, thus boosting LLMs' capabilities in identifying emotion causes. This collaborative approach enables LLMs to discern emotions more precisely and formulate empathetic responses. We validate HEF on the Empathetic-Dialogue dataset, and the findings indicate that our framework enhances the refined understanding of LLMs and their ability to convey empathetic responses.

24 May 2025
Both CNN-based and Transformer-based methods have achieved remarkable success
in medical image segmentation tasks. However, CNN-based methods struggle to
effectively capture global contextual information due to the inherent
limitations of convolution operations. Meanwhile, Transformer-based methods
suffer from insufficient local feature modeling and face challenges related to
the high computational complexity caused by the self-attention mechanism. To
address these limitations, we propose a novel hybrid CNN-Transformer
architecture, named MSLAU-Net, which integrates the strengths of both
paradigms. The proposed MSLAU-Net incorporates two key ideas. First, it
introduces Multi-Scale Linear Attention, designed to efficiently extract
multi-scale features from medical images while modeling long-range dependencies
with low computational complexity. Second, it adopts a top-down feature
aggregation mechanism, which performs multi-level feature aggregation and
restores spatial resolution using a lightweight structure. Extensive
experiments conducted on benchmark datasets covering three imaging modalities
demonstrate that the proposed MSLAU-Net outperforms other state-of-the-art
methods on nearly all evaluation metrics, validating the superiority,
effectiveness, and robustness of our approach. Our code is available at
this https URL

05 Dec 2024


Traffic sign detection is crucial for improving road safety and advancing autonomous driving technologies. Due to the complexity of driving environments, traffic sign detection frequently encounters a range of challenges, including low resolution, limited feature information, and small object sizes. These challenges significantly hinder the effective extraction of features from traffic signs, resulting in false positives and false negatives in object detection. To address these challenges, it is essential to explore more efficient and accurate approaches for traffic sign detection. This paper proposes a context-based algorithm for traffic sign detection, which utilizes YOLOv7 as the baseline model. Firstly, we propose an adaptive local context feature enhancement (LCFE) module using multi-scale dilation convolution to capture potential relationships between the object and surrounding areas. This module supplements the network with additional local context information. Secondly, we propose a global context feature collection (GCFC) module to extract key location features from the entire image scene as global context information. Finally, we build a Transformer-based context collection augmentation (CCA) module to process the collected local context and global context, which achieves superior multi-level feature fusion results for YOLOv7 without bringing in additional complexity. Extensive experimental studies performed on the Tsinghua-Tencent 100K dataset show that the mAP of our method is 92.1\%. Compared with YOLOv7, our approach improves 3.9\% in mAP, while the amount of parameters is reduced by 2.7M. On the CCTSDB2021 dataset the mAP is improved by 0.9\%. These results show that our approach achieves higher detection accuracy with fewer parameters. The source code is available at \url{this https URL}.

19 Dec 2024
Multi-behavior recommendation (MBR) has garnered growing attention recently due to its ability to mitigate the sparsity issue by inferring user preferences from various auxiliary behaviors to improve predictions for the target behavior. Although existing research on MBR has yielded impressive results, they still face two major limitations. First, previous methods mainly focus on modeling fine-grained interaction information between users and items under each behavior, which may suffer from sparsity issue. Second, existing models usually concentrate on exploiting dependencies between two consecutive behaviors, leaving intra- and inter-behavior consistency largely unexplored. To the end, we propose a novel approach named Hypergraph Enhanced Cascading Graph Convolution Network for multi-behavior recommendation (HEC-GCN). To be specific, we first explore both fine- and coarse-grained correlations among users or items of each behavior by simultaneously modeling the behavior-specific interaction graph and its corresponding hypergraph in a cascaded manner. Then, we propose a behavior consistency-guided alignment strategy that ensures consistent representations between the interaction graph and its associated hypergraph for each behavior, while also maintaining representation consistency across different behaviors. Extensive experiments and analyses on three public benchmark datasets demonstrate that our proposed approach is consistently superior to previous state-of-the-art methods due to its capability to effectively attenuate the sparsity issue as well as preserve both intra- and inter-behavior consistencies. The code is available at this https URL.

19 Dec 2024
Image restoration and enhancement are pivotal for numerous computer vision applications, yet unifying these tasks efficiently remains a significant challenge. Inspired by the iterative refinement capabilities of diffusion models, we propose CycleRDM, a novel framework designed to unify restoration and enhancement tasks while achieving high-quality mapping. Specifically, CycleRDM first learns the mapping relationships among the degraded domain, the rough normal domain, and the normal domain through a two-stage diffusion inference process. Subsequently, we transfer the final calibration process to the wavelet low-frequency domain using discrete wavelet transform, performing fine-grained calibration from a frequency domain perspective by leveraging task-specific frequency spaces. To improve restoration quality, we design a feature gain module for the decomposed wavelet high-frequency domain to eliminate redundant features. Additionally, we employ multimodal textual prompts and Fourier transform to drive stable denoising and reduce randomness during the inference process. After extensive validation, CycleRDM can be effectively generalized to a wide range of image restoration and enhancement tasks while requiring only a small number of training samples to be significantly superior on various benchmarks of reconstruction quality and perceptual quality. The source code will be available at this https URL.

25 Sep 2025

Numerical relativity has produced wide-ranging influences on modern astrophysics and gravitational-wave astronomy. In this work, we develop a Python interface for the numerical relativity program AMSS-NCKU, which enables the automation of initializing and starting the AMSS-NCKU simulations and the automatically generating visualizations of the output results. Numerical relativity simulations using this Python interface have been presented through two representative examples (binary back hole and triple black hole merger processes), and well-behaved stable numerical results and the expected physical behaviors for black hole systems have been acquired. The Python operational interface significantly lowers the operational complexity of the simulation workflow of AMSS-NCKU simulations, reducing the technical barriers for freshman users.
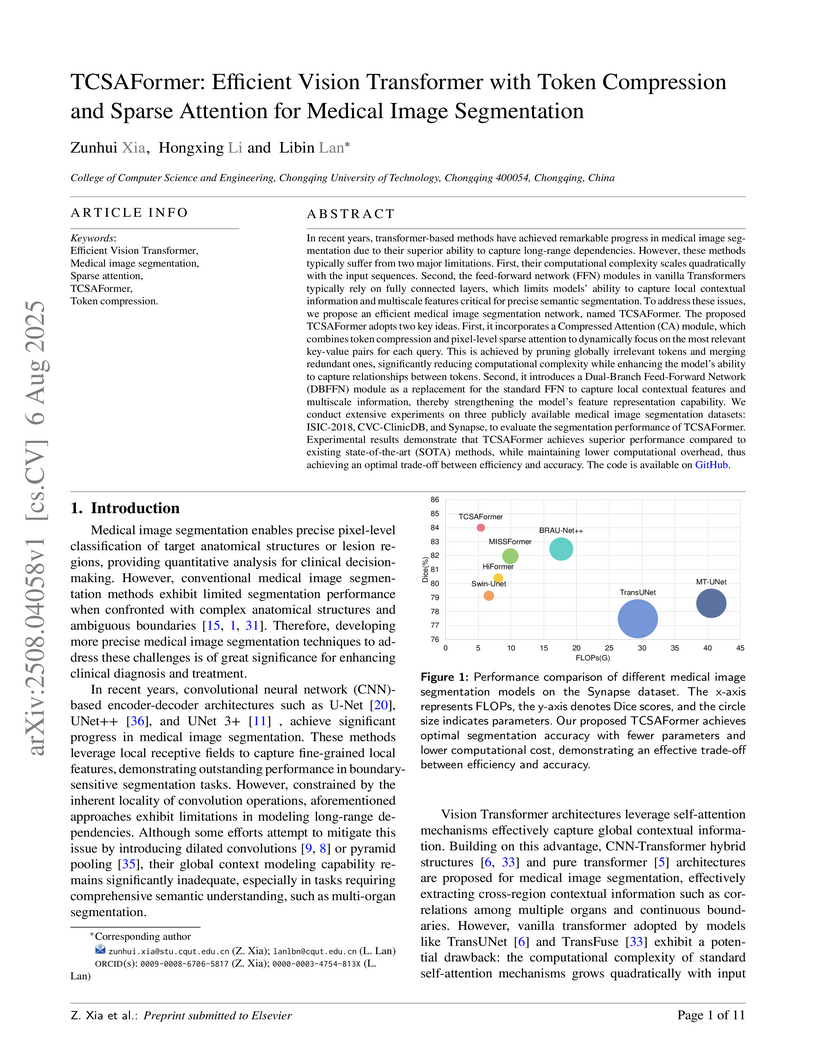
06 Aug 2025
In recent years, transformer-based methods have achieved remarkable progress in medical image segmentation due to their superior ability to capture long-range dependencies. However, these methods typically suffer from two major limitations. First, their computational complexity scales quadratically with the input sequences. Second, the feed-forward network (FFN) modules in vanilla Transformers typically rely on fully connected layers, which limits models' ability to capture local contextual information and multiscale features critical for precise semantic segmentation. To address these issues, we propose an efficient medical image segmentation network, named TCSAFormer. The proposed TCSAFormer adopts two key ideas. First, it incorporates a Compressed Attention (CA) module, which combines token compression and pixel-level sparse attention to dynamically focus on the most relevant key-value pairs for each query. This is achieved by pruning globally irrelevant tokens and merging redundant ones, significantly reducing computational complexity while enhancing the model's ability to capture relationships between tokens. Second, it introduces a Dual-Branch Feed-Forward Network (DBFFN) module as a replacement for the standard FFN to capture local contextual features and multiscale information, thereby strengthening the model's feature representation capability. We conduct extensive experiments on three publicly available medical image segmentation datasets: ISIC-2018, CVC-ClinicDB, and Synapse, to evaluate the segmentation performance of TCSAFormer. Experimental results demonstrate that TCSAFormer achieves superior performance compared to existing state-of-the-art (SOTA) methods, while maintaining lower computational overhead, thus achieving an optimal trade-off between efficiency and accuracy.

03 Nov 2025

We introduce MoSa, a novel hierarchical motion generation framework for text-driven 3D human motion generation that enhances the Vector Quantization-guided Generative Transformers (VQ-GT) paradigm through a coarse-to-fine scalable generation process. In MoSa, we propose a Multi-scale Token Preservation Strategy (MTPS) integrated into a hierarchical residual vector quantization variational autoencoder (RQ-VAE). MTPS employs interpolation at each hierarchical quantization to effectively retain coarse-to-fine multi-scale tokens. With this, the generative transformer supports Scalable Autoregressive (SAR) modeling, which predicts scale tokens, unlike traditional methods that predict only one token at each step. Consequently, MoSa requires only 10 inference steps, matching the number of RQ-VAE quantization layers. To address potential reconstruction degradation from frequent interpolation, we propose CAQ-VAE, a lightweight yet expressive convolution-attention hybrid VQ-VAE. CAQ-VAE enhances residual block design and incorporates attention mechanisms to better capture global dependencies. Extensive experiments show that MoSa achieves state-of-the-art generation quality and efficiency, outperforming prior methods in both fidelity and speed. On the Motion-X dataset, MoSa achieves an FID of 0.06 (versus MoMask's 0.20) while reducing inference time by 27 percent. Moreover, MoSa generalizes well to downstream tasks such as motion editing, requiring no additional fine-tuning. The code is available at this https URL

03 Jul 2025

3D semantic occupancy prediction plays a pivotal role in autonomous driving. However, inherent limitations of fewframe images and redundancy in 3D space compromise prediction accuracy for occluded and distant scenes. Existing methods enhance performance by fusing historical frame data, which need additional data and significant computational resources. To address these issues, this paper propose FMOcc, a Tri-perspective View (TPV) refinement occupancy network with flow matching selective state space model for few-frame 3D occupancy prediction. Firstly, to generate missing features, we designed a feature refinement module based on a flow matching model, which is called Flow Matching SSM module (FMSSM). Furthermore, by designing the TPV SSM layer and Plane Selective SSM (PS3M), we selectively filter TPV features to reduce the impact of air voxels on non-air voxels, thereby enhancing the overall efficiency of the model and prediction capability for distant scenes. Finally, we design the Mask Training (MT) method to enhance the robustness of FMOcc and address the issue of sensor data loss. Experimental results on the Occ3D-nuScenes and OpenOcc datasets show that our FMOcc outperforms existing state-of-theart methods. Our FMOcc with two frame input achieves notable scores of 43.1% RayIoU and 39.8% mIoU on Occ3D-nuScenes validation, 42.6% RayIoU on OpenOcc with 5.4 G inference memory and 330ms inference time.

30 Sep 2024
Accurate medical image segmentation is essential for clinical quantification,
disease diagnosis, treatment planning and many other applications. Both
convolution-based and transformer-based u-shaped architectures have made
significant success in various medical image segmentation tasks. The former can
efficiently learn local information of images while requiring much more
image-specific inductive biases inherent to convolution operation. The latter
can effectively capture long-range dependency at different feature scales using
self-attention, whereas it typically encounters the challenges of quadratic
compute and memory requirements with sequence length increasing. To address
this problem, through integrating the merits of these two paradigms in a
well-designed u-shaped architecture, we propose a hybrid yet effective
CNN-Transformer network, named BRAU-Net++, for an accurate medical image
segmentation task. Specifically, BRAU-Net++ uses bi-level routing attention as
the core building block to design our u-shaped encoder-decoder structure, in
which both encoder and decoder are hierarchically constructed, so as to learn
global semantic information while reducing computational complexity.
Furthermore, this network restructures skip connection by incorporating
channel-spatial attention which adopts convolution operations, aiming to
minimize local spatial information loss and amplify global
dimension-interaction of multi-scale features. Extensive experiments on three
public benchmark datasets demonstrate that our proposed approach surpasses
other state-of-the-art methods including its baseline: BRAU-Net under almost
all evaluation metrics. We achieve the average Dice-Similarity Coefficient
(DSC) of 82.47, 90.10, and 92.94 on Synapse multi-organ segmentation, ISIC-2018
Challenge, and CVC-ClinicDB, as well as the mIoU of 84.01 and 88.17 on
ISIC-2018 Challenge and CVC-ClinicDB, respectively.

25 Jan 2024

Conventional cameras capture image irradiance on a sensor and convert it to
RGB images using an image signal processor (ISP). The images can then be used
for photography or visual computing tasks in a variety of applications, such as
public safety surveillance and autonomous driving. One can argue that since RAW
images contain all the captured information, the conversion of RAW to RGB using
an ISP is not necessary for visual computing. In this paper, we propose a novel
-Vision framework to perform high-level semantic understanding and
low-level compression using RAW images without the ISP subsystem used for
decades. Considering the scarcity of available RAW image datasets, we first
develop an unpaired CycleR2R network based on unsupervised CycleGAN to train
modular unrolled ISP and inverse ISP (invISP) models using unpaired RAW and RGB
images. We can then flexibly generate simulated RAW images (simRAW) using any
existing RGB image dataset and finetune different models originally trained for
the RGB domain to process real-world camera RAW images. We demonstrate object
detection and image compression capabilities in RAW-domain using RAW-domain
YOLOv3 and RAW image compressor (RIC) on snapshots from various cameras.
Quantitative results reveal that RAW-domain task inference provides better
detection accuracy and compression compared to RGB-domain processing.
Furthermore, the proposed \r{ho}-Vision generalizes across various camera
sensors and different task-specific models. Additional advantages of the
proposed -Vision that eliminates the ISP are the potential reductions in
computations and processing times.

12 Jan 2025
Image dehazing techniques aim to enhance contrast and restore details, which are essential for preserving visual information and improving image processing accuracy. Existing methods rely on a single manual prior, which cannot effectively reveal image details. To overcome this limitation, we propose an unpaired image dehazing network, called the Simple Image Dehaze Enhancer via Unpaired Rich Physical Prior (UR2P-Dehaze). First, to accurately estimate the illumination, reflectance, and color information of the hazy image, we design a shared prior estimator (SPE) that is iteratively trained to ensure the consistency of illumination and reflectance, generating clear, high-quality images. Additionally, a self-monitoring mechanism is introduced to eliminate undesirable features, providing reliable priors for image reconstruction. Next, we propose Dynamic Wavelet Separable Convolution (DWSC), which effectively integrates key features across both low and high frequencies, significantly enhancing the preservation of image details and ensuring global consistency. Finally, to effectively restore the color information of the image, we propose an Adaptive Color Corrector that addresses the problem of unclear colors. The PSNR, SSIM, LPIPS, FID and CIEDE2000 metrics on the benchmark dataset show that our method achieves state-of-the-art performance. It also contributes to the performance improvement of downstream tasks. The project code will be available at this https URL. \end{abstract}

16 Feb 2025
Diffusion model-based low-light image enhancement methods rely heavily on
paired training data, leading to limited extensive application. Meanwhile,
existing unsupervised methods lack effective bridging capabilities for unknown
degradation. To address these limitations, we propose a novel zero-reference
lighting estimation diffusion model for low-light image enhancement called
Zero-LED. It utilizes the stable convergence ability of diffusion models to
bridge the gap between low-light domains and real normal-light domains and
successfully alleviates the dependence on pairwise training data via
zero-reference learning. Specifically, we first design the initial optimization
network to preprocess the input image and implement bidirectional constraints
between the diffusion model and the initial optimization network through
multiple objective functions. Subsequently, the degradation factors of the
real-world scene are optimized iteratively to achieve effective light
enhancement. In addition, we explore a frequency-domain based and semantically
guided appearance reconstruction module that encourages feature alignment of
the recovered image at a fine-grained level and satisfies subjective
expectations. Finally, extensive experiments demonstrate the superiority of our
approach to other state-of-the-art methods and more significant generalization
capabilities. We will open the source code upon acceptance of the paper.

04 Jun 2025
In the childbirth process, traditional methods involve invasive vaginal
examinations, but research has shown that these methods are both subjective and
inaccurate. Ultrasound-assisted diagnosis offers an objective yet effective way
to assess fetal head position via two key parameters: Angle of Progression
(AoP) and Head-Symphysis Distance (HSD), calculated by segmenting the fetal
head (FH) and pubic symphysis (PS), which aids clinicians in ensuring a smooth
delivery process. Therefore, accurate segmentation of FH and PS is crucial. In
this work, we propose a sparse self-attention network architecture with good
performance and high computational efficiency, named DSSAU-Net, for the
segmentation of FH and PS. Specifically, we stack varying numbers of Dual
Sparse Selection Attention (DSSA) blocks at each stage to form a symmetric
U-shaped encoder-decoder network architecture. For a given query, DSSA is
designed to explicitly perform one sparse token selection at both the region
and pixel levels, respectively, which is beneficial for further reducing
computational complexity while extracting the most relevant features. To
compensate for the information loss during the upsampling process, skip
connections with convolutions are designed. Additionally, multiscale feature
fusion is employed to enrich the model's global and local information. The
performance of DSSAU-Net has been validated using the Intrapartum Ultrasound
Grand Challenge (IUGC) 2024 \textit{test set} provided by the organizer in the
MICCAI IUGC 2024
competition\footnote{\href{https://codalab.lisn.upsaclay.fr/competitions/18413\#learn\_the\_details}{this https URL}},
where we win the fourth place on the tasks of classification and segmentation,
demonstrating its effectiveness. The codes will be available at
this https URL

17 Apr 2024

Low-light image enhancement techniques have significantly progressed, but unstable image quality recovery and unsatisfactory visual perception are still significant challenges. To solve these problems, we propose a novel and robust low-light image enhancement method via CLIP-Fourier Guided Wavelet Diffusion, abbreviated as CFWD. Specifically, CFWD leverages multimodal visual-language information in the frequency domain space created by multiple wavelet transforms to guide the enhancement process. Multi-scale supervision across different modalities facilitates the alignment of image features with semantic features during the wavelet diffusion process, effectively bridging the gap between degraded and normal domains. Moreover, to further promote the effective recovery of the image details, we combine the Fourier transform based on the wavelet transform and construct a Hybrid High Frequency Perception Module (HFPM) with a significant perception of the detailed features. This module avoids the diversity confusion of the wavelet diffusion process by guiding the fine-grained structure recovery of the enhancement results to achieve favourable metric and perceptually oriented enhancement. Extensive quantitative and qualitative experiments on publicly available real-world benchmarks show that our approach outperforms existing state-of-the-art methods, achieving significant progress in image quality and noise suppression. The project code is available at this https URL.

26 Aug 2025
Single-domain generalization for object detection (S-DGOD) seeks to transfer learned representations from a single source domain to unseen target domains. While recent approaches have primarily focused on achieving feature invariance, they ignore that domain diversity also presents significant challenges for the task. First, such invariance-driven strategies often lead to the loss of domain-specific information, resulting in incomplete feature representations. Second, cross-domain feature alignment forces the model to overlook domain-specific discrepancies, thereby increasing the complexity of the training process. To address these limitations, this paper proposes the Diversity Invariant Detection Model (DIDM), which achieves a harmonious integration of domain-specific diversity and domain invariance. Our key idea is to learn the invariant representations by keeping the inherent domain-specific features. Specifically, we introduce the Diversity Learning Module (DLM). This module limits the invariant semantics while explicitly enhancing domain-specific feature representation through a proposed feature diversity loss. Furthermore, to ensure cross-domain invariance without sacrificing diversity, we incorporate the Weighted Aligning Module (WAM) to enable feature alignment while maintaining the discriminative domain-specific information. Extensive experiments on multiple diverse datasets demonstrate the effectiveness of the proposed model, achieving superior performance compared to existing methods.

08 Dec 2025
Diffusion models have achieved remarkable performance in generative modeling, yet their theoretical foundations are often intricate, and the gap between mathematical formulations in papers and practical open-source implementations can be difficult to bridge. Existing tutorials primarily focus on deriving equations, offering limited guidance on how diffusion models actually operate in code. To address this, we present a concise implementation of approximately 300 lines that explains diffusion models from a code-execution perspective. Our minimal example preserves the essential components -- including forward diffusion, reverse sampling, the noise-prediction network, and the training loop -- while removing unnecessary engineering details. This technical report aims to provide researchers with a clear, implementation-first understanding of how diffusion models work in practice and how code and theory correspond. Our code and pre-trained models are available at: this https URL.
There are no more papers matching your filters at the moment.
