 Emory University
Emory University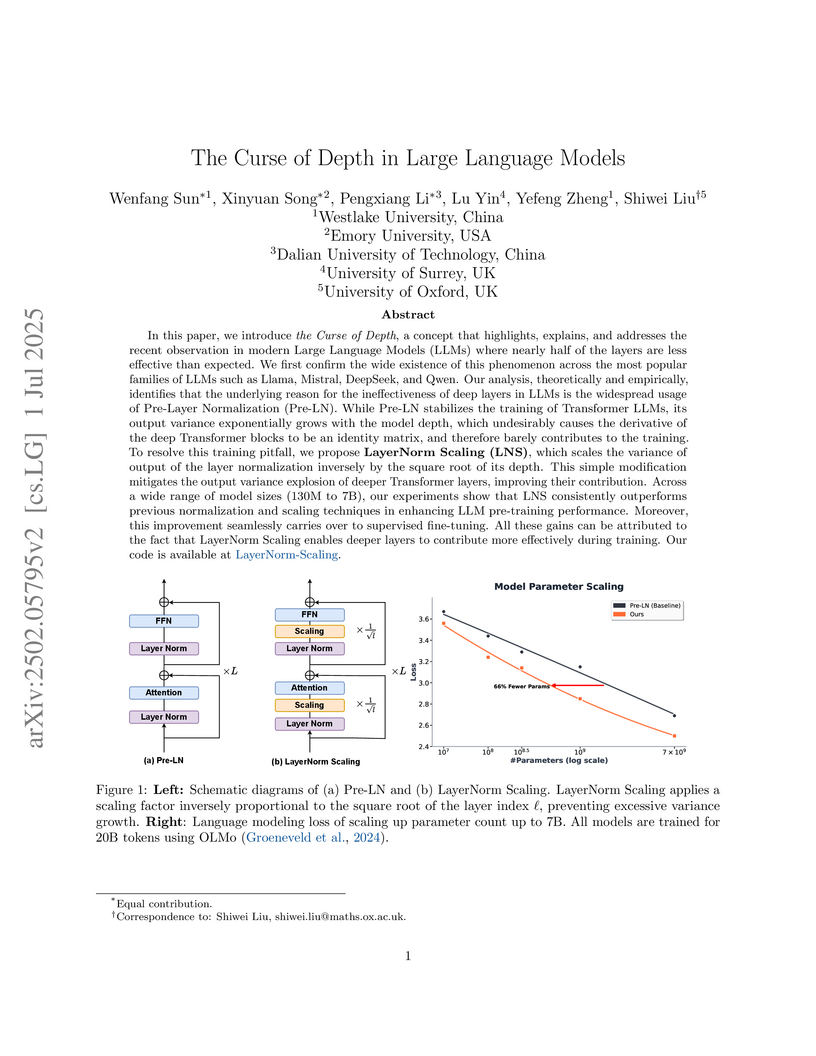
01 Jul 2025



Researchers at Westlake University, Emory University, Dalian University of Technology, University of Surrey, and University of Oxford investigated the 'Curse of Depth' in large language models, demonstrating that Pre-Layer Normalization leads to exponential output variance growth, rendering deep layers ineffective. They propose LayerNorm Scaling (LNS), a hyperparameter-free method that reduces variance growth to a polynomial rate, leading to improved pre-training perplexity and an average 1.8% gain on downstream tasks across various LLM scales.

17 Nov 2025





The paper scrutinizes the long-standing belief in unbounded Large Language Model (LLM) scaling, establishing a proof-informed framework that identifies intrinsic theoretical limits on their capabilities. It synthesizes empirical failures like hallucination and reasoning degradation with foundational concepts from computability theory, information theory, and statistical learning, showing that these issues are inherent rather than transient engineering challenges.

09 Oct 2025


A scalable framework was established for generating high-quality synthetic rubrics, enabling the development of a rubric-guided reward model (Rubric-RM) to improve large language model alignment. Rubric-RM consistently outperforms comparable 7B-scale reward models by an average of 6.8% and achieves state-of-the-art performance in instruction-following tasks.

06 Feb 2025


G-Designer introduces a framework using Graph Neural Networks to dynamically generate task-aware communication topologies for LLM-based multi-agent systems. This approach achieved superior performance on various benchmarks while significantly reducing token consumption by up to 95.33% and demonstrating high adversarial robustness.

23 Jan 2025

This Tsinghua University-led survey synthesizes advancements in reinforced reasoning with Large Language Models, identifying the emerging paradigm of "Large Reasoning Models (LRMs)." It outlines how these models integrate train-time improvements through reinforcement learning and automated data construction, particularly with Process Reward Models, alongside test-time computational scaling for enhanced reasoning.

27 Oct 2025





Med-R1, a Vision-Language Model leveraging reinforcement learning, achieves superior generalizability in medical reasoning across eight imaging modalities and five clinical tasks. It demonstrates a 29.94% accuracy improvement over its base model and outperforms larger general-purpose VLMs while an introduced 'Think-After' strategy provides clinically sound, post-hoc rationales.

25 Oct 2025
A study of thinking in rule-based visual reinforcement fine-tuning for multi-modal large language models reveals that explicit reasoning processes are not always necessary and can even be detrimental, especially for visual perception tasks. For 2B models, a "no-thinking" strategy achieved a 3.14% higher average accuracy in image classification and offered significant computational efficiency over thinking-based methods.

15 Oct 2025
MedDINOv3 adapts Vision Transformer foundation models for medical image segmentation by integrating architectural refinements and large-scale, domain-adaptive pretraining on nearly 4 million CT slices. This framework achieves superior performance over nnU-Net on several organ segmentation tasks and competitive results for tumor segmentation across diverse medical imaging benchmarks.

29 Sep 2025


Researchers from Arizona State University and collaborating institutions present a comprehensive survey of the "LLM-as-a-judge" paradigm, defining its operational framework, taxonomizing methodologies, and exploring its opportunities and challenges across the LLM lifecycle. The work identifies six key judging attributes and categorizes various tuning and prompting strategies employed to enhance LLM judging capabilities.

01 Sep 2025
Researchers developed TAAROFBENCH, the first open-ended benchmark for Persian *taarof*, revealing that current LLMs exhibit a strong bias towards directness and perform poorly on culturally nuanced interactions. Targeted fine-tuning, especially using Direct Preference Optimization, significantly improved LLM accuracy on *taarof*-expected scenarios, bringing performance close to native human levels.

29 May 2025



GuardAgent introduces a framework for safeguarding Large Language Model (LLM) agents against safety and privacy violations by leveraging knowledge-enabled reasoning and code generation for deterministic policy enforcement. The system significantly outperforms existing text-based guardrails and hardcoded approaches in accuracy while maintaining the target agent's original task performance, validated on newly created healthcare access control and web safety benchmarks.

26 Sep 2025




A memory management framework for multi-agent systems, SEDM, implements verifiable write admission, self-scheduling, and cross-domain knowledge diffusion to address noise accumulation and uncontrolled memory expansion. It enhances reasoning accuracy on benchmarks like LoCoMo, FEVER, and HotpotQA while reducing token consumption by up to 50% compared to previous memory systems.

17 Jun 2025


This practitioner's guide clarifies the complexities of Difference-in-Differences (DiD) designs, particularly in multi-period and staggered treatment adoption settings, by advocating for a 'forward-engineering' approach to explicitly define causal parameters and their identification assumptions. The authors demonstrate how commonly used Two-Way Fixed Effects (TWFE) estimators can produce biased results in these complex scenarios and provide robust, transparent alternatives for applied researchers.

04 Aug 2025


Artificial intelligence (AI) has demonstrated significant potential in ECG analysis and cardiovascular disease assessment. Recently, foundation models have played a remarkable role in advancing medical AI. The development of an ECG foundation model holds the promise of elevating AI-ECG research to new heights. However, building such a model faces several challenges, including insufficient database sample sizes and inadequate generalization across multiple domains. Additionally, there is a notable performance gap between single-lead and multi-lead ECG analyses. We introduced an ECG Foundation Model (ECGFounder), a general-purpose model that leverages real-world ECG annotations from cardiology experts to broaden the diagnostic capabilities of ECG analysis. ECGFounder was trained on over 10 million ECGs with 150 label categories from the Harvard-Emory ECG Database, enabling comprehensive cardiovascular disease diagnosis through ECG analysis. The model is designed to be both an effective out-of-the-box solution, and a to be fine-tunable for downstream tasks, maximizing usability. Importantly, we extended its application to lower rank ECGs, and arbitrary single-lead ECGs in particular. ECGFounder is applicable to supporting various downstream tasks in mobile monitoring scenarios. Experimental results demonstrate that ECGFounder achieves expert-level performance on internal validation sets, with AUROC exceeding 0.95 for eighty diagnoses. It also shows strong classification performance and generalization across various diagnoses on external validation sets. When fine-tuned, ECGFounder outperforms baseline models in demographic analysis, clinical event detection, and cross-modality cardiac rhythm diagnosis. The trained model and data will be publicly released upon publication through the this http URL. Our code is available at this https URL

05 Nov 2025
Researchers at Shanghai AI Laboratory and collaborating institutions developed TIR-BENCH, a comprehensive benchmark designed to evaluate multimodal large language models' ability to 'think with images' by dynamically manipulating visual inputs with tools. The benchmark revealed that models with explicit agentic tool-use capabilities achieved up to 46% accuracy, significantly outperforming non-agentic models on tasks requiring active visual interaction.

23 Jun 2025
The 'PlanGenLLMs' survey provides a structured overview of Large Language Model planning capabilities, proposing six consistent evaluation criteria: completeness, executability, optimality, representation, generalization, and efficiency, and analyzing current research against these standards. It synthesizes existing findings to highlight the strengths and limitations of current LLM planners and identifies key directions for future research in the field.

12 Jul 2025
GRAG introduces a framework that enables Large Language Models to effectively utilize textual graphs for Retrieval-Augmented Generation by efficiently retrieving relevant subgraphs and integrating their structural and textual information. This method significantly enhances multi-hop reasoning and factual accuracy, while also reducing the computational costs typically associated with LLM fine-tuning.

28 Nov 2025


Deductive reasoning is the process of deriving conclusions strictly from the given premises, without relying on external knowledge. We define honesty in this setting as a model's ability to respond only when the conclusion is logically entailed by the premises, and to abstain otherwise. However, current language models often fail to reason honestly, producing unwarranted answers when the input is insufficient. To study this challenge, we formulate honest deductive reasoning as multi-step tasks where models must either derive the correct conclusion or abstain. We curate two datasets from graph structures, one for linear algebra and one for logical inference, and introduce unanswerable cases by randomly perturbing an edge in half of the instances. We find that prompting and existing training methods, including GRPO with or without supervised fine-tuning initialization, struggle on these tasks. In particular, GRPO optimize only for final task outcomes, leaving models vulnerable to collapse when negative rewards dominate early training. To address this, we propose ACNCHOR, a reinforcement learning method that injects ground truth trajectories into rollouts, preventing early training collapse. Our results demonstrate that this method stabilizes learning and significantly improves the overall reasoning performance, underscoring the importance of training dynamics for enabling honest deductive reasoning in language models.

07 Apr 2025

Researchers from Emory University and partner institutions develop Collab-RAG, a framework that enables efficient collaboration between small and large language models for complex question answering, achieving 1.8-14.2% performance improvements across five multi-hop QA datasets through automated query decomposition and iterative preference optimization.

03 Oct 2024

AgentPrune presents a framework that addresses the high inference costs of LLM-based multi-agent systems by identifying and eliminating redundant communication paths. The approach reduces token consumption by 28.1% to 72.8% while maintaining comparable or improved task performance and enhancing robustness against adversarial attacks.
There are no more papers matching your filters at the moment.
