
23 Jun 2024
RomanSetu: Efficiently unlocking multilingual capabilities of Large Language Models via Romanization
RomanSetu: Efficiently unlocking multilingual capabilities of Large Language Models via Romanization

This study addresses the challenge of extending Large Language Models (LLMs) to non-English languages that use non-Roman scripts. We propose an approach that utilizes the romanized form of text as an interface for LLMs, hypothesizing that its frequent informal use and shared tokens with English enhance cross-lingual alignment. Our approach involves the continual pretraining of an English LLM like Llama 2 on romanized text of non-English, non-Roman script languages, followed by instruction tuning on romanized data. The results indicate that romanized text not only reduces token fertility by 2x-4x but also matches or outperforms native script representation across various NLU, NLG, and MT tasks. Moreover, the embeddings computed on romanized text exhibit closer alignment with their English translations than those from the native script. Our approach presents a promising direction for leveraging the power of English LLMs in languages traditionally underrepresented in NLP. Our code is available on this https URL.

03 Feb 2025
Flipkart Data Science developed Agent-S, a framework utilizing orchestrated Large Language Models (LLMs) to automate complex, multi-step customer service Standard Operating Procedures (SOPs). The system achieved over 95% accuracy in state decisions and 90% in action execution on synthetic data, demonstrating robust fault tolerance and successful automation in live environments.

08 Apr 2024
In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.

16 Jun 2024
Opinion summarization in e-commerce encapsulates the collective views of
numerous users about a product based on their reviews. Typically, a product on
an e-commerce platform has thousands of reviews, each review comprising around
10-15 words. While Large Language Models (LLMs) have shown proficiency in
summarization tasks, they struggle to handle such a large volume of reviews due
to context limitations. To mitigate, we propose a scalable framework called
Xl-OpSumm that generates summaries incrementally. However, the existing test
set, AMASUM has only 560 reviews per product on average. Due to the lack of a
test set with thousands of reviews, we created a new test set called
Xl-Flipkart by gathering data from the Flipkart website and generating
summaries using GPT-4. Through various automatic evaluations and extensive
analysis, we evaluated the framework's efficiency on two datasets, AMASUM and
Xl-Flipkart. Experimental results show that our framework, Xl-OpSumm powered by
Llama-3-8B-8k, achieves an average ROUGE-1 F1 gain of 4.38% and a ROUGE-L F1
gain of 3.70% over the next best-performing model.
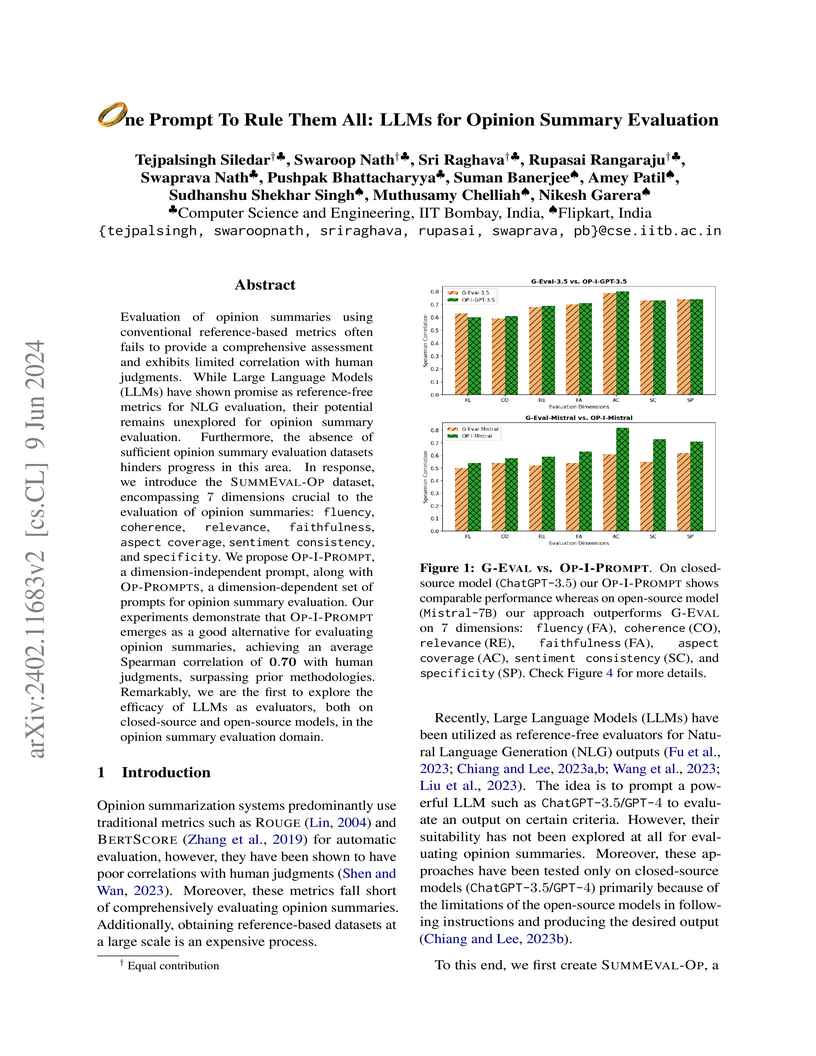
09 Jun 2024
Evaluation of opinion summaries using conventional reference-based metrics rarely provides a holistic evaluation and has been shown to have a relatively low correlation with human judgments. Recent studies suggest using Large Language Models (LLMs) as reference-free metrics for NLG evaluation, however, they remain unexplored for opinion summary evaluation. Moreover, limited opinion summary evaluation datasets inhibit progress. To address this, we release the SUMMEVAL-OP dataset covering 7 dimensions related to the evaluation of opinion summaries: fluency, coherence, relevance, faithfulness, aspect coverage, sentiment consistency, and specificity. We investigate Op-I-Prompt a dimension-independent prompt, and Op-Prompts, a dimension-dependent set of prompts for opinion summary evaluation. Experiments indicate that Op-I-Prompt emerges as a good alternative for evaluating opinion summaries achieving an average Spearman correlation of 0.70 with humans, outperforming all previous approaches. To the best of our knowledge, we are the first to investigate LLMs as evaluators on both closed-source and open-source models in the opinion summarization domain.

26 Feb 2024
We announce the initial release of "Airavata," an instruction-tuned LLM for Hindi. Airavata was created by fine-tuning OpenHathi with diverse, instruction-tuning Hindi datasets to make it better suited for assistive tasks. Along with the model, we also share the IndicInstruct dataset, which is a collection of diverse instruction-tuning datasets to enable further research for Indic LLMs. Additionally, we present evaluation benchmarks and a framework for assessing LLM performance across tasks in Hindi. Currently, Airavata supports Hindi, but we plan to expand this to all 22 scheduled Indic languages. You can access all artifacts at this https URL.

01 Aug 2018

In this paper, we address the problem of evaluating whether results served by an e-commerce search engine for a query are good or not. This is a critical question in evaluating any e-commerce search engine. While this question is traditionally answered using simple metrics like query click-through rate (CTR), we observe that in e-commerce search, such metrics can be misleading. Upon inspection, we find cases where CTR is high but the results are poor and vice versa. Similar cases exist for other metrics like time to click which are often also used for evaluating search engines. We aim to learn the quality of the results served by the search engine based on users' interactions with the results. Although this problem has been studied in the web search context, this is the first study for e-commerce search, to the best of our knowledge. Despite certain commonalities with evaluating web search engines, there are several major differences such as underlying reasons for search failure, and availability of rich user interaction data with products (e.g. adding a product to the cart). We study large-scale user interaction logs from Flipkart's search engine, analyze behavioral patterns and build models to classify queries based on user behavior signals. We demonstrate the feasibility and efficacy of such models in accurately predicting query performance. Our classifier is able to achieve an average AUC of 0.75 on a held-out test set.

29 May 2023
Automatic Speech Recognition (ASR) plays a crucial role in voice-based applications. For applications requiring real-time feedback like Voice Search, streaming capability becomes vital. While LSTM/RNN and CTC based ASR systems are commonly employed for low-latency streaming applications, they often exhibit lower accuracy compared to state-of-the-art models due to a lack of future audio frames. In this work, we focus on developing accurate LSTM, attention, and CTC based streaming ASR models for large-scale Hinglish (a blend of Hindi and English) Voice Search. We investigate various modifications in vanilla LSTM training which enhance the system's accuracy while preserving its streaming capabilities. We also address the critical requirement of end-of-speech (EOS) detection in streaming applications. We present a simple training and inference strategy for end-to-end CTC models that enables joint ASR and EOS detection. The evaluation of our model on Flipkart's Voice Search, which handles substantial traffic of approximately 6 million queries per day, demonstrates significant performance gains over the vanilla LSTM-CTC model. Our model achieves a word error rate (WER) of 3.69% without EOS and 4.78% with EOS while also reducing the search latency by approximately ~1300 ms (equivalent to 46.64% reduction) when compared to an independent voice activity detection (VAD) model.

04 Aug 2020
Decentralized marketplace applications demand fast, cheap and easy-to-use
cryptocurrency payment mechanisms to facilitate high transaction volumes. The
standard solution for off-chain payments, state channels, are optimized for
frequent transactions between two entities and impose prohibitive liquidity and
capital requirements on payment senders for marketplace transactions. We
propose PayPlace, a scalable off-chain protocol for payments between consumers
and sellers. Using PayPlace, consumers establish a virtual unidirectional
payment channel with an intermediary operator to pay for their transactions.
Unlike state channels, however, the PayPlace operator can reference the
custodial funds accrued off-chain in these channels to in-turn make
tamper-proof off-chain payments to merchants, without locking up corresponding
capital in channels with merchants. Our design ensures that new payments made
to merchants are guaranteed to be safe once notarized and provably mitigates
well-known drawbacks in previous constructions like the data availability
attack and ensures that neither consumers nor merchants need to be online to
ensure continued safety of their notarized funds. We show that the on-chain
monetary and computational costs for PayPlace is O(1) in the number of payment
transactions processed, and is near-constant in other parameters in most
scenarios. PayPlace can hence scale the payment throughput for large-scale
marketplaces at no marginal cost and is orders of magnitude cheaper than the
state-of-art solution for non-pairwise off-chain payments, Zero Knowledge
Rollups.

15 Jul 2020
Systematically discovering semantic relationships in text is an important and
extensively studied area in Natural Language Processing, with various tasks
such as entailment, semantic similarity, etc. Decomposability of sentence-level
scores via subsequence alignments has been proposed as a way to make models
more interpretable. We study the problem of aligning components of sentences
leading to an interpretable model for semantic textual similarity. In this
paper, we introduce a novel pointer network based model with a sentinel gating
function to align constituent chunks, which are represented using BERT. We
improve this base model with a loss function to equally penalize misalignments
in both sentences, ensuring the alignments are bidirectional. Finally, to guide
the network with structured external knowledge, we introduce first-order logic
constraints based on ConceptNet and syntactic knowledge. The model achieves an
F1 score of 97.73 and 96.32 on the benchmark SemEval datasets for the chunk
alignment task, showing large improvements over the existing solutions. Source
code is available at
this https URL

25 Aug 2020

We address the problem of large scale real-time classification of content
posted on social networks, along with the need to rapidly identify novel spam
types. Obtaining manual labels for user-generated content using editorial
labeling and taxonomy development lags compared to the rate at which new
content type needs to be classified. We propose a class of hierarchical
clustering algorithms that can be used both for efficient and scalable
real-time multiclass classification as well as in detecting new anomalies in
user-generated content. Our methods have low query time, linear space usage,
and come with theoretical guarantees with respect to a specific hierarchical
clustering cost function (Dasgupta, 2016). We compare our solutions against a
range of classification techniques and demonstrate excellent empirical
performance.

07 Jul 2025
Customer reviews on e-commerce platforms capture critical affective signals that drive purchasing decisions. However, no existing research has explored the joint task of emotion detection and explanatory span identification in e-commerce reviews - a crucial gap in understanding what triggers customer emotional responses. To bridge this gap, we propose a novel joint task unifying Emotion detection and Opinion Trigger extraction (EOT), which explicitly models the relationship between causal text spans (opinion triggers) and affective dimensions (emotion categories) grounded in Plutchik's theory of 8 primary emotions. In the absence of labeled data, we introduce EOT-X, a human-annotated collection of 2,400 reviews with fine-grained emotions and opinion triggers. We evaluate 23 Large Language Models (LLMs) and present EOT-DETECT, a structured prompting framework with systematic reasoning and self-reflection. Our framework surpasses zero-shot and chain-of-thought techniques, across e-commerce domains.

25 Jul 2025
Image-based product attribute prediction in e-commerce is a crucial task with numerous applications. The supervised fine-tuning of Vision Language Models (VLMs) faces significant scale challenges due to the cost of manual or API based annotation. In this paper, we investigate label-efficient semi-supervised fine-tuning strategies for compact VLMs (2B-3B parameters) that leverage unlabeled product listings through Direct Preference Optimization (DPO). Beginning with a small, API-based, annotated, and labeled set, we first employ PEFT to train low-rank adapter modules. To update the adapter weights with unlabeled data, we generate multiple reasoning-and-answer chains per unlabeled sample and segregate these chains into preferred and dispreferred based on self-consistency. We then fine-tune the model with DPO loss and use the updated model for the next iteration. By using PEFT fine-tuning with DPO, our method achieves efficient convergence with minimal compute overhead. On a dataset spanning twelve e-commerce verticals, DPO-based fine-tuning, which utilizes only unlabeled data, demonstrates a significant improvement over the supervised model. Moreover, experiments demonstrate that accuracy with DPO training improves with more unlabeled data, indicating that a large pool of unlabeled samples can be effectively leveraged to improve performance.

27 May 2023

Usage data of a group of users distributed across a number of categories,
such as songs, movies, webpages, links, regular household products, mobile
apps, games, etc. can be ultra-high dimensional and massive in size. More often
this kind of data is categorical and sparse in nature making it even more
difficult to interpret any underlying hidden patterns such as clusters of
users. However, if this information can be estimated accurately, it will have
huge impacts in different business areas such as user recommendations for apps,
songs, movies, and other similar products, health analytics using electronic
health record (EHR) data, and driver profiling for insurance premium estimation
or fleet management.
In this work, we propose a clustering strategy of such categorical big data,
utilizing the hidden sparsity of the dataset. Most traditional clustering
methods fail to give proper clusters for such data and end up giving one big
cluster with small clusters around it irrespective of the true structure of the
data clusters. We propose a feature transformation, which maps the
binary-valued usage vector to a lower dimensional continuous feature space in
terms of groups of usage categories, termed as covariate classes. The lower
dimensional feature representations in terms of covariate classes can be used
for clustering. We implemented the proposed strategy and applied it to a large
sized very high-dimensional song playlist dataset for the performance
validation. The results are impressive as we achieved similar-sized user
clusters with minimal between-cluster overlap in the feature space (8%) on
average). As the proposed strategy has a very generic framework, it can be
utilized as the analytic engine of many of the above-mentioned business use
cases allowing an intelligent and dynamic personal recommendation system or a
support system for smart business decision-making.

27 Nov 2021
Automatic question answering is an important yet challenging task in E-commerce given the millions of questions posted by users about the product that they are interested in purchasing. Hence, there is a great demand for automatic answer generation systems that provide quick responses using related information about the product. There are three sources of knowledge available for answering a user posted query, they are reviews, duplicate or similar questions, and specifications. Effectively utilizing these information sources will greatly aid us in answering complex questions. However, there are two main challenges present in exploiting these sources: (i) The presence of irrelevant information and (ii) the presence of ambiguity of sentiment present in reviews and similar questions. Through this work we propose a novel pipeline (MSQAP) that utilizes the rich information present in the aforementioned sources by separately performing relevancy and ambiguity prediction before generating a response.
Experimental results show that our relevancy prediction model (BERT-QA) outperforms all other variants and has an improvement of 12.36% in F1 score compared to the BERT-base baseline. Our generation model (T5-QA) outperforms the baselines in all content preservation metrics such as BLEU, ROUGE and has an average improvement of 35.02% in ROUGE and 198.75% in BLEU compared to the highest performing baseline (HSSC-q). Human evaluation of our pipeline shows us that our method has an overall improvement in accuracy of 30.7% over the generation model (T5-QA), resulting in our full pipeline-based approach (MSQAP) providing more accurate answers. To the best of our knowledge, this is the first work in the e-commerce domain that automatically generates natural language answers combining the information present in diverse sources such as specifications, similar questions, and reviews data.

07 Jul 2025
Product recommendations inherently involve comparisons, yet traditional opinion summarization often fails to provide holistic comparative insights. We propose the novel task of generating Query-Focused Comparative Explainable Summaries (QF-CES) using Multi-Source Opinion Summarization (M-OS). To address the lack of query-focused recommendation datasets, we introduce MS-Q2P, comprising 7,500 queries mapped to 22,500 recommended products with metadata. We leverage Large Language Models (LLMs) to generate tabular comparative summaries with query-specific explanations. Our approach is personalized, privacy-preserving, recommendation engine-agnostic, and category-agnostic. M-OS as an intermediate step reduces inference latency approximately by 40% compared to the direct input approach (DIA), which processes raw data directly. We evaluate open-source and proprietary LLMs for generating and assessing QF-CES. Extensive evaluations using QF-CES-PROMPT across 5 dimensions (clarity, faithfulness, informativeness, format adherence, and query relevance) showed an average Spearman correlation of 0.74 with human judgments, indicating its potential for QF-CES evaluation.

07 Jul 2025
Multi-source Opinion Summarization (M-OS) extends beyond traditional opinion summarization by incorporating additional sources of product metadata such as descriptions, key features, specifications, and ratings, alongside reviews. This integration results in comprehensive summaries that capture both subjective opinions and objective product attributes essential for informed decision-making. While Large Language Models (LLMs) have shown significant success in various Natural Language Processing (NLP) tasks, their potential in M-OS remains largely unexplored. Additionally, the lack of evaluation datasets for this task has impeded further advancements. To bridge this gap, we introduce M-OS-EVAL, a benchmark dataset for evaluating multi-source opinion summaries across 7 key dimensions: fluency, coherence, relevance, faithfulness, aspect coverage, sentiment consistency, specificity. Our results demonstrate that M-OS significantly enhances user engagement, as evidenced by a user study in which, on average, 87% of participants preferred M-OS over opinion summaries. Our experiments demonstrate that factually enriched summaries enhance user engagement. Notably, M-OS-PROMPTS exhibit stronger alignment with human judgment, achieving an average Spearman correlation of \r{ho} = 0.74, which surpasses the performance of previous methodologies.

02 Dec 2023
Text-to-speech (TTS) systems are an important component in voice-based e-commerce applications. These applications include end-to-end voice assistant and customer experience (CX) voice bot. Code-mixed TTS is also relevant in these applications since the product names are commonly described in English while the surrounding text is in a regional language. In this work, we describe our approaches for production quality code-mixed Hindi-English TTS systems built for e-commerce applications. We propose a data-oriented approach by utilizing monolingual data sets in individual languages. We leverage a transliteration model to convert the Roman text into a common Devanagari script and then combine both datasets for training. We show that such single script bi-lingual training without any code-mixing works well for pure code-mixed test sets. We further present an exhaustive evaluation of single-speaker adaptation and multi-speaker training with Tacotron2 + Waveglow setup to show that the former approach works better. These approaches are also coupled with transfer learning and decoder-only fine-tuning to improve performance. We compare these approaches with the Google TTS and report a positive CMOS score of 0.02 with the proposed transfer learning approach. We also perform low-resource voice adaptation experiments to show that a new voice can be onboarded with just 3 hrs of data. This highlights the importance of our pre-trained models in resource-constrained settings. This subjective evaluation is performed on a large number of out-of-domain pure code-mixed sentences to demonstrate the high quality of the systems.

23 Oct 2023
Community Question-Answering (CQA) portals serve as a valuable tool for
helping users within an organization. However, making them accessible to
non-English-speaking users continues to be a challenge. Translating questions
can broaden the community's reach, benefiting individuals with similar
inquiries in various languages. Translating questions using Neural Machine
Translation (NMT) poses more challenges, especially in noisy environments,
where the grammatical correctness of the questions is not monitored. These
questions may be phrased as statements by non-native speakers, with incorrect
subject-verb order and sometimes even missing question marks. Creating a
synthetic parallel corpus from such data is also difficult due to its noisy
nature. To address this issue, we propose a training methodology that
fine-tunes the NMT system only using source-side data. Our approach balances
adequacy and fluency by utilizing a loss function that combines BERTScore and
Masked Language Model (MLM) Score. Our method surpasses the conventional
Maximum Likelihood Estimation (MLE) based fine-tuning approach, which relies on
synthetic target data, by achieving a 1.9 BLEU score improvement. Our model
exhibits robustness while we add noise to our baseline, and still achieve 1.1
BLEU improvement and large improvements on TER and BLEURT metrics. Our proposed
methodology is model-agnostic and is only necessary during the training phase.
We make the codes and datasets publicly available at
\url{this https URL} for
facilitating further research.
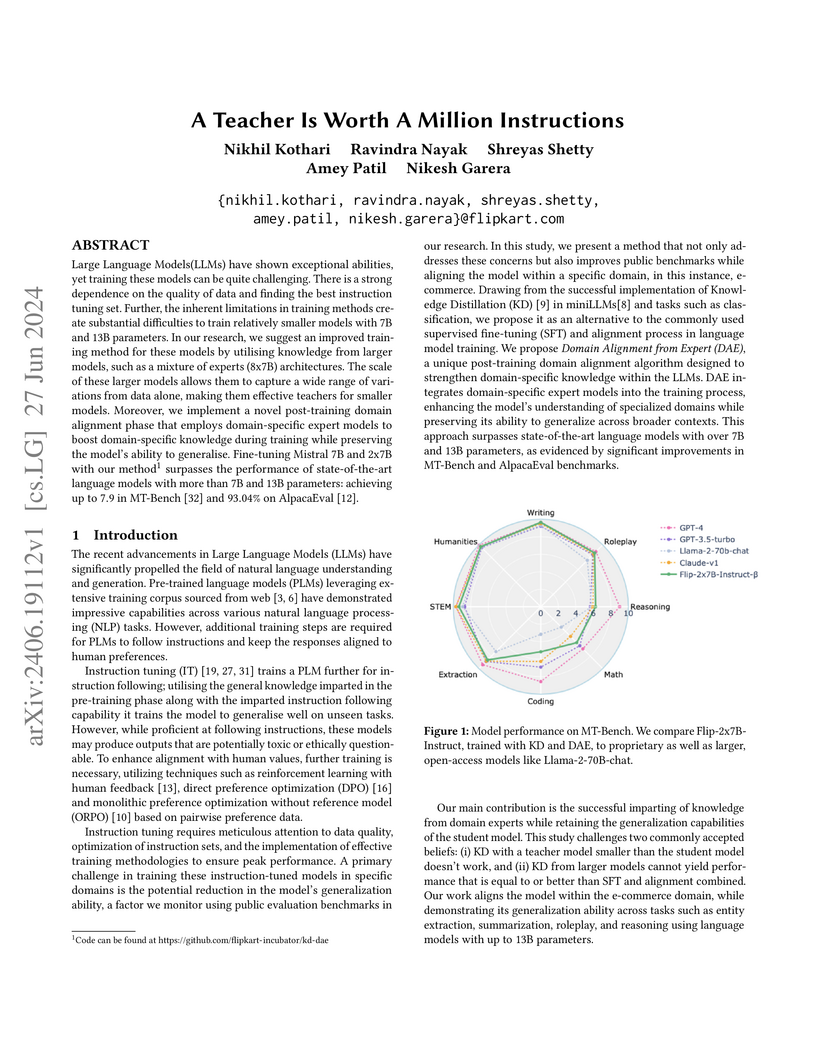
27 Jun 2024
Large Language Models(LLMs) have shown exceptional abilities, yet training
these models can be quite challenging. There is a strong dependence on the
quality of data and finding the best instruction tuning set. Further, the
inherent limitations in training methods create substantial difficulties to
train relatively smaller models with 7B and 13B parameters. In our research, we
suggest an improved training method for these models by utilising knowledge
from larger models, such as a mixture of experts (8x7B) architectures. The
scale of these larger models allows them to capture a wide range of variations
from data alone, making them effective teachers for smaller models. Moreover,
we implement a novel post-training domain alignment phase that employs
domain-specific expert models to boost domain-specific knowledge during
training while preserving the model's ability to generalise. Fine-tuning
Mistral 7B and 2x7B with our method surpasses the performance of
state-of-the-art language models with more than 7B and 13B parameters:
achieving up to in MT-Bench and on AlpacaEval.
There are no more papers matching your filters at the moment.
