
27 Mar 2024
The LMTraj framework recasts pedestrian trajectory prediction as a natural language question-answering task, leveraging large language models (LLMs) to forecast future pedestrian paths. It achieves competitive or superior performance compared to numerical regression methods on standard public benchmarks, including ETH/UCY, SDD, and GCS.

23 Sep 2025
Learning robust visuomotor policies that generalize across diverse objects and interaction dynamics remains a central challenge in robotic manipulation. Most existing approaches rely on direct observation-to-action mappings or compress perceptual inputs into global or object-centric features, which often overlook localized motion cues critical for precise and contact-rich manipulation. We present 3D Flow Diffusion Policy (3D FDP), a novel framework that leverages scene-level 3D flow as a structured intermediate representation to capture fine-grained local motion cues. Our approach predicts the temporal trajectories of sampled query points and conditions action generation on these interaction-aware flows, implemented jointly within a unified diffusion architecture. This design grounds manipulation in localized dynamics while enabling the policy to reason about broader scene-level consequences of actions. Extensive experiments on the MetaWorld benchmark show that 3D FDP achieves state-of-the-art performance across 50 tasks, particularly excelling on medium and hard settings. Beyond simulation, we validate our method on eight real-robot tasks, where it consistently outperforms prior baselines in contact-rich and non-prehensile scenarios. These results highlight 3D flow as a powerful structural prior for learning generalizable visuomotor policies, supporting the development of more robust and versatile robotic manipulation. Robot demonstrations, additional results, and code can be found at this https URL.

23 Sep 2025
Researchers at Gwangju Institute of Science and Technology (GIST) developed the ManipForce system and a Frequency-Aware Multimodal Transformer (FMT) to improve contact-rich robotic manipulation. This framework integrates high-frequency force-torque data with visual information using specialized embeddings and cross-attention, achieving an average success rate of 83% across various tasks, which significantly outperforms RGB-only methods.

31 May 2025

A new benchmark, CHED, exposes how contextual information degrades the recall of edited knowledge in language models, and a new method, CoRE, improves knowledge editing's resilience to such contextual interference. CoRE achieves higher average scores on efficacy, generalization, and specificity on the CHED benchmark, especially when preceding contexts are present, while preserving general model capabilities.
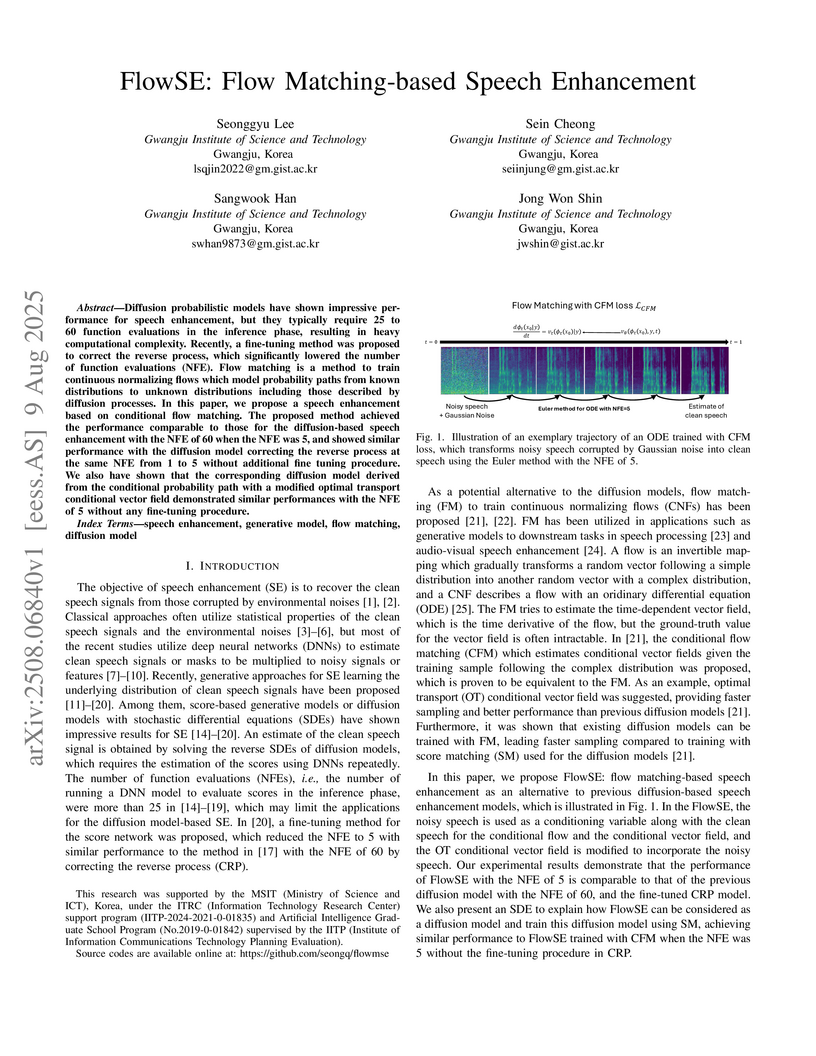
09 Aug 2025
Researchers at the Gwangju Institute of Science and Technology developed FlowSE, a speech enhancement model leveraging conditional flow matching to achieve high-quality results akin to state-of-the-art diffusion models. This model operates with a significantly reduced inference computational cost, requiring only 5 function evaluations compared to 60, without needing any additional fine-tuning steps.

21 Sep 2025

Teacher Value-based Knowledge Distillation (TVKD) introduces a method for aligning small language models (SLMs) with human preferences by extracting soft reward labels from a DPO-trained teacher's value function. This approach, which applies potential-based reward shaping, consistently improves SLM performance on preference benchmarks while maintaining computational efficiency in an offline setting.

31 Jul 2024
Multi-agent trajectory prediction is crucial to autonomous driving and
understanding the surrounding environment. Learning-based approaches for
multi-agent trajectory prediction, such as primarily relying on graph neural
networks, graph transformers, and hypergraph neural networks, have demonstrated
outstanding performance on real-world datasets in recent years. However, the
hypergraph transformer-based method for trajectory prediction is yet to be
explored. Therefore, we present a MultiscAle Relational Transformer (MART)
network for multi-agent trajectory prediction. MART is a hypergraph transformer
architecture to consider individual and group behaviors in transformer
machinery. The core module of MART is the encoder, which comprises a Pair-wise
Relational Transformer (PRT) and a Hyper Relational Transformer (HRT). The
encoder extends the capabilities of a relational transformer by introducing
HRT, which integrates hyperedge features into the transformer mechanism,
promoting attention weights to focus on group-wise relations. In addition, we
propose an Adaptive Group Estimator (AGE) designed to infer complex group
relations in real-world environments. Extensive experiments on three real-world
datasets (NBA, SDD, and ETH-UCY) demonstrate that our method achieves
state-of-the-art performance, enhancing ADE/FDE by 3.9%/11.8% on the NBA
dataset. Code is available at https://github.com/gist-ailab/MART.

23 Sep 2025
Bimanual grasping is essential for robots to handle large and complex objects. However, existing methods either focus solely on single-arm grasping or employ separate grasp generation and bimanual evaluation stages, leading to coordination problems including collision risks and unbalanced force distribution. To address these limitations, we propose BiGraspFormer, a unified end-to-end transformer framework that directly generates coordinated bimanual grasps from object point clouds. Our key idea is the Single-Guided Bimanual (SGB) strategy, which first generates diverse single grasp candidates using a transformer decoder, then leverages their learned features through specialized attention mechanisms to jointly predict bimanual poses and quality scores. This conditioning strategy reduces the complexity of the 12-DoF search space while ensuring coordinated bimanual manipulation. Comprehensive simulation experiments and real-world validation demonstrate that BiGraspFormer consistently outperforms existing methods while maintaining efficient inference speed (<0.05s), confirming the effectiveness of our framework. Code and supplementary materials are available at this https URL

21 Apr 2025
Modeling and reproducing crowd behaviors are important in various domains
including psychology, robotics, transport engineering and virtual environments.
Conventional methods have focused on synthesizing momentary scenes, which have
difficulty in replicating the continuous nature of real-world crowds. In this
paper, we introduce a novel method for automatically generating continuous,
realistic crowd trajectories with heterogeneous behaviors and interactions
among individuals. We first design a crowd emitter model. To do this, we obtain
spatial layouts from single input images, including a segmentation map,
appearance map, population density map and population probability, prior to
crowd generation. The emitter then continually places individuals on the
timeline by assigning independent behavior characteristics such as agents'
type, pace, and start/end positions using diffusion models. Next, our crowd
simulator produces their long-term locomotions. To simulate diverse actions, it
can augment their behaviors based on a Markov chain. As a result, our overall
framework populates the scenes with heterogeneous crowd behaviors by
alternating between the proposed emitter and simulator. Note that all the
components in the proposed framework are user-controllable. Lastly, we propose
a benchmark protocol to evaluate the realism and quality of the generated
crowds in terms of the scene-level population dynamics and the individual-level
trajectory accuracy. We demonstrate that our approach effectively models
diverse crowd behavior patterns and generalizes well across different
geographical environments. Code is publicly available at
this https URL .

26 Aug 2025
We present DESAMO, an on-device smart home system for elder-friendly use powered by Audio LLM, that supports natural and private interactions. While conventional voice assistants rely on ASR-based pipelines or ASR-LLM cascades, often struggling with the unclear speech common among elderly users and unable to handle non-speech audio, DESAMO leverages an Audio LLM to process raw audio input directly, enabling a robust understanding of user intent and critical events, such as falls or calls for help.

14 Jan 2024
Purpose: This study aimed to develop an open-source multimodal large language model (CXR-LLAVA) for interpreting chest X-ray images (CXRs), leveraging recent advances in large language models (LLMs) to potentially replicate the image interpretation skills of human radiologists Materials and Methods: For training, we collected 592,580 publicly available CXRs, of which 374,881 had labels for certain radiographic abnormalities (Dataset 1) and 217,699 provided free-text radiology reports (Dataset 2). After pre-training a vision transformer with Dataset 1, we integrated it with an LLM influenced by the LLAVA network. Then, the model was fine-tuned, primarily using Dataset 2. The model's diagnostic performance for major pathological findings was evaluated, along with the acceptability of radiologic reports by human radiologists, to gauge its potential for autonomous reporting. Results: The model demonstrated impressive performance in test sets, achieving an average F1 score of 0.81 for six major pathological findings in the MIMIC internal test set and 0.62 for seven major pathological findings in the external test set. The model's F1 scores surpassed those of GPT-4-vision and Gemini-Pro-Vision in both test sets. In human radiologist evaluations of the external test set, the model achieved a 72.7% success rate in autonomous reporting, slightly below the 84.0% rate of ground truth reports. Conclusion: This study highlights the significant potential of multimodal LLMs for CXR interpretation, while also acknowledging the performance limitations. Despite these challenges, we believe that making our model open-source will catalyze further research, expanding its effectiveness and applicability in various clinical contexts. CXR-LLAVA is available at this https URL.

24 Sep 2025
Speaker verification (SV) utilizing features obtained from models pre-trained via self-supervised learning has recently demonstrated impressive performances. However, these pre-trained models (PTMs) usually have a temporal resolution of 20 ms, which is lower than typical filterbank features. It may be problematic especially for short-segment SV with an input segment shorter than 2 s, in which we need to extract as much information as possible from the input with a limited length. Although there have been approaches to utilize multi-resolution features from the HuBERT models, the window shifts were 320, 640, and 1600 samples when the sampling rate was 16 kHz and thus only lower resolution features were considered. In this study, we propose an SV system which utilizes PTM features along with filterbank features and those from the multi-resolution time domain encoder with window shifts of 25, 50, 100, and 200 samples. Experimental results on the VoxCeleb dataset with various input lengths showed consistent improvements over systems with various combinations of input features.

22 Oct 2024
Ex4DGS, a fully explicit keyframe interpolation-based 4D Gaussian Splatting approach, enables real-time novel view synthesis for dynamic scenes. It achieves state-of-the-art rendering quality with up to 120 FPS and 115 MB model size while demonstrating robustness to sparse point cloud initialization and reducing training time to 0.6 hours.

23 Sep 2024

GraspSAM, developed by the GIST AI Lab, integrates the Segment Anything Model into a unified, prompt-driven framework for end-to-end robotic grasp detection, achieving an 86% physical grasp success rate in real-world cluttered scenarios. This approach improves upon traditional multi-stage methods by directly predicting grasp parameters from various prompts, and demonstrates strong cross-dataset generalization.

18 Aug 2025
A classical dynamical system can be viewed as a probability space equipped with a measure-preserving time evolution map, admitting a purely algebraic formulation in terms of the algebra of bounded functions on the phase space. Similarly, a quantum dynamical system can be formulated using an algebra of bounded operators in a non-commutative probability space equipped with a time evolution map. Chaos, in either setting, can be characterized by statistical independence between observables at and , leading to the vanishing of cumulants involving these observables. In the quantum case, the notion of independence is replaced by free independence, which only emerges in the thermodynamic limit (asymptotic freeness). In this work, we propose a definition of quantum chaos based on asymptotic freeness and investigate its emergence in quantum many-body systems including the mixed-field Ising model with a random magnetic field, a higher spin version of the same model, and the SYK model. The hallmark of asymptotic freeness is the emergence of the free convolution prediction for the spectrum of operators of the form , implying the vanishing of all free cumulants between and in the thermodynamic limit for an infinite-temperature thermal state. We systematically investigate the spectral properties of in the above-mentioned models, show that fluctuations on top of the free convolution prediction follow universal Wigner-Dyson statistics, and discuss the connection with quantum chaos. Finally, we argue that free probability theory provides a rigorous framework for understanding quantum chaos, offering a unifying perspective that connects many different manifestations of it.

13 Nov 2025
Contact-rich manipulation has become increasingly important in robot learning. However, previous studies on robot learning datasets have focused on rigid objects and underrepresented the diversity of pressure conditions for real-world manipulation. To address this gap, we present a humanoid visual-tactile-action dataset designed for manipulating deformable soft objects. The dataset was collected via teleoperation using a humanoid robot equipped with dexterous hands, capturing multi-modal interactions under varying pressure conditions. This work also motivates future research on models with advanced optimization strategies capable of effectively leveraging the complexity and diversity of tactile signals.

28 May 2025
Researchers introduced a framework to categorize and detect misalignments in human problem-solving trajectories for abstract reasoning tasks. Training AI models with these inferred human intentions, alongside object-level features, improved task-solving accuracy on ARC.
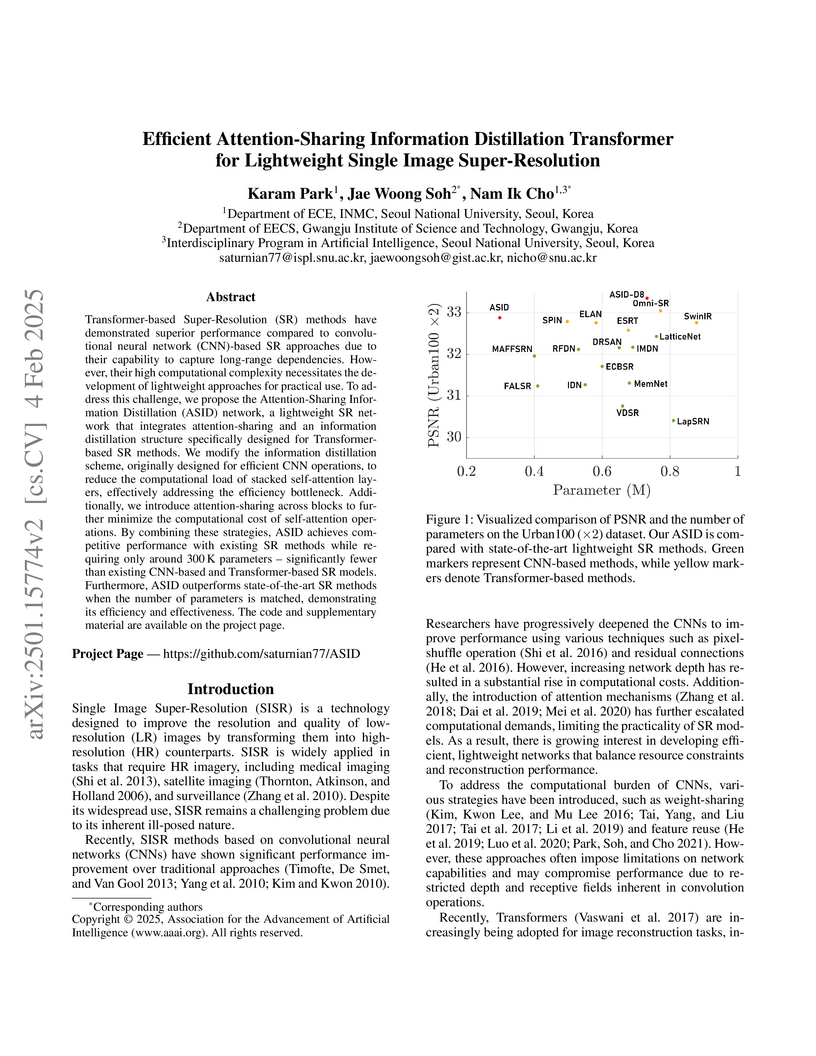
04 Feb 2025
The Attention-Sharing Information Distillation (ASID) Transformer provides a lightweight solution for single image super-resolution, achieving competitive performance against state-of-the-art models while significantly reducing parameters and computational costs through an innovative attention-sharing mechanism and channel-split information distillation.

02 Jun 2024
Compressed prompts aid instruction-tuned language models (LMs) in overcoming context window limitations and reducing computational costs. Existing methods, which primarily based on training embeddings, face various challenges associated with interpretability, the fixed number of embedding tokens, reusability across different LMs, and inapplicability when interacting with black-box APIs. This study proposes prompt compression with reinforcement learning (PCRL), which is a discrete prompt compression method that addresses these issues. The proposed PCRL method utilizes a computationally efficient policy network that edits prompts directly. The training approach employed in the proposed PCRLs can be applied flexibly to various types of LMs, including both decoder-only and encoder-decoder architecture and it can be trained without gradient access to the LMs or labeled data. The proposed PCRL achieves an average reduction of 24.6% in terms of the token count across various instruction prompts while maintaining sufficient performance. In addition, we demonstrate that the learned policy can be transferred to larger LMs, and through a comprehensive analysis, we explore the token importance within the prompts. Our code is accessible at this https URL.

03 Oct 2025
Motivated by bulk reconstruction of smeared boundary operators, we study the Krylov complexity of local and non-local primary CFT operators from the local bulk-to-bulk propagator of a minimally-coupled massive scalar field in Rindler-AdS space. We derive analytic and numerical evidence on how the degree of non-locality in the dual CFT observable affects the evolution of Krylov complexity and the Lanczos coefficients. Curiously, the near-horizon limit matches with the same observable for conformally-coupled probe scalar fields inserted at the asymptotic boundary of AdS space. Our results also show that the evolution of the growth rate of Krylov operator complexity in the CFT takes the same form as to the proper radial momentum of a probe particle inside the bulk to a good approximation. The exact equality only occurs when the probe particle is inserted in the asymptotic boundary or in the horizon limit. Our results capture a prosperous interplay between Krylov complexity in the CFT, thermal ensembles at finite bulk locations and their role in the holographic dictionary.
There are no more papers matching your filters at the moment.
