
16 Mar 2024

HCF-Net effectively enhances infrared small object detection by integrating Parallelized Patch-Aware Attention, Dimension-Aware Selective Integration, and Multi-Dilated Channel Refiner modules into an upgraded U-Net architecture. This approach yielded an IoU of 80.09% and an nIoU of 78.31% on the SIRST dataset, surpassing existing deep learning methods.

13 Jul 2025

Sound event detection (SED) has made strong progress in controlled environments with clear event categories. However, real-world applications often take place in open environments. In such cases, current methods often produce predictions with too much confidence and lack proper ways to measure uncertainty. This limits their ability to adapt and perform well in new situations. To solve this problem, we are the first to use ensemble methods in SED to improve robustness against out-of-domain (OOD) inputs. We propose a confidence calibration method called Energy-based Open-World Softmax (EOW-Softmax), which helps the system better handle uncertainty in unknown scenes. We further apply EOW-Softmax to sound occurrence and overlap detection (SOD) by adjusting the prediction. In this way, the model becomes more adaptable while keeping its ability to detect overlapping events. Experiments show that our method improves performance in open environments. It reduces overconfidence and increases the ability to handle OOD situations.

30 Oct 2025
This paper systematically reviews the research progress and application prospects of machine learning technologies in the field of polymer materials. Currently, machine learning methods are developing rapidly in polymer material research; although they have significantly accelerated material prediction and design, their complexity has also caused difficulties in understanding and application for researchers in traditional fields. In response to the above issues, this paper first analyzes the inherent challenges in the research and development of polymer materials, including structural complexity and the limitations of traditional trial-and-error methods. To address these problems, it focuses on introducing key basic technologies such as molecular descriptors and feature representation, data standardization and cleaning, and records a number of high-quality polymer databases. Subsequently, it elaborates on the key role of machine learning in polymer property prediction and material design, covering the specific applications of algorithms such as traditional machine learning, deep learning, and transfer learning; further, it deeply expounds on data-driven design strategies, such as reverse design, high-throughput virtual screening, and multi-objective optimization. The paper also systematically introduces the complete process of constructing high-reliability machine learning models and summarizes effective experimental verification, model evaluation, and optimization methods. Finally, it summarizes the current technical challenges in research, such as data quality and model generalization ability, and looks forward to future development trends including multi-scale modeling, physics-informed machine learning, standardized data sharing, and interpretable machine learning.

20 Jul 2025
Visual and semantic concepts are often structured in a hierarchical manner. For instance, textual concept `cat' entails all images of cats. A recent study, MERU, successfully adapts multimodal learning techniques from Euclidean space to hyperbolic space, effectively capturing the visual-semantic hierarchy. However, a critical question remains: how can we more efficiently train a model to capture and leverage this hierarchy? In this paper, we propose the Hyperbolic Masked Image and Distillation Network (HMID-Net), a novel and efficient method that integrates Masked Image Modeling (MIM) and knowledge distillation techniques within hyperbolic space. To the best of our knowledge, this is the first approach to leverage MIM and knowledge distillation in hyperbolic space to train highly efficient models. In addition, we introduce a distillation loss function specifically designed to facilitate effective knowledge transfer in hyperbolic space. Our experiments demonstrate that MIM and knowledge distillation techniques in hyperbolic space can achieve the same remarkable success as in Euclidean space. Extensive evaluations show that our method excels across a wide range of downstream tasks, significantly outperforming existing models like MERU and CLIP in both image classification and retrieval.

22 Aug 2023
Mixed-precision neural networks (MPNNs) that enable the use of just enough
data width for a deep learning task promise significant advantages of both
inference accuracy and computing overhead. FPGAs with fine-grained
reconfiguration capability can adapt the processing with distinct data width
and models, and hence, can theoretically unleash the potential of MPNNs.
Nevertheless, commodity DPUs on FPGAs mostly emphasize generality and have
limited support for MPNNs especially the ones with lower data width. In
addition, primitive DSPs in FPGAs usually have much larger data width than that
is required by MPNNs and haven't been sufficiently co-explored with MPNNs yet.
To this end, we propose an open source MPNN accelerator design framework
specifically tailored for FPGAs. In this framework, we have a systematic
DSP-packing algorithm to pack multiple lower data width MACs in a single
primitive DSP and enable efficient implementation of MPNNs. Meanwhile, we take
DSP packing efficiency into consideration with MPNN quantization within a
unified neural network architecture search (NAS) framework such that it can be
aware of the DSP overhead during quantization and optimize the MPNN performance
and accuracy concurrently. Finally, we have the optimized MPNN fine-tuned to a
fully pipelined neural network accelerator template based on HLS and make best
use of available resources for higher performance. Our experiments reveal the
resulting accelerators produced by the proposed framework can achieve
overwhelming advantages in terms of performance, resource utilization, and
inference accuracy for MPNNs when compared with both handcrafted counterparts
and prior hardware-aware neural network accelerators on FPGAs.

18 Sep 2025

Multimodal acoustic event classification plays a key role in audio-visual systems. Although combining audio and visual signals improves recognition, it is still difficult to align them over time and to reduce the effect of noise across modalities. Existing methods often treat audio and visual streams separately, fusing features later with contrastive or mutual information objectives. Recent advances explore multimodal graph learning, but most fail to distinguish between intra- and inter-modal temporal dependencies. To address this, we propose Temporally Heterogeneous Graph-based Contrastive Learning (THGCL). Our framework constructs a temporal graph for each event, where audio and video segments form nodes and their temporal links form edges. We introduce Gaussian processes for intra-modal smoothness, Hawkes processes for inter-modal decay, and contrastive learning to capture fine-grained relationships. Experiments on AudioSet show that THGCL achieves state-of-the-art performance.

10 Aug 2025
Most sound event detection (SED) systems perform well on clean datasets but degrade significantly in noisy environments. Language-queried audio source separation (LASS) models show promise for robust SED by separating target events; existing methods require elaborate multi-stage training and lack explicit guidance for target events. To address these challenges, we introduce event appearance detection (EAD), a counting-based approach that counts event occurrences at both the clip and frame levels. Based on EAD, we propose a co-training-based multi-task learning framework for EAD and SED to enhance SED's performance in noisy environments. First, SED struggles to learn the same patterns as EAD. Then, a task-based constraint is designed to improve prediction consistency between SED and EAD. This framework provides more reliable clip-level predictions for LASS models and strengthens timestamp detection capability. Experiments on DESED and WildDESED datasets demonstrate better performance compared to existing methods, with advantages becoming more pronounced at higher noise levels.

03 Sep 2021
Complex vector light modes with a spatial variant polarization distribution have become topical of late, enabling the development of novel applications in numerous research fields. Key to this is the remarkable similarities they hold with quantum entangled states, which arises from the non-separability between the spatial and polarisation degrees of freedom (DoF). As such, the demand for diversification of generation methods and characterization techniques have increased dramatically. Here we put forward a comprehensive tutorial about the use of DMDs in the generation and characterization of vector modes, providing details on the implementation of techniques that fully exploits the unsurpassed advantage of Digital Micromirrors Devices (DMDs), such as their high refresh rates and polarisation independence. We start by briefly describing the operating principles of DMD and follow with a thorough explanation of some of the methods to shape arbitrary vector modes. Finally, we describe some techniques aiming at the real-time characterization of vector beams. This tutorial highlights the value of DMDs as an alternative tool for the generation and characterization of complex vector light fields, of great relevance in a wide variety of applications.

03 Apr 2025
Video Question Answering (VideoQA) is an important research direction in the
field of artificial intelligence, enabling machines to understand video content
and perform reasoning and answering based on natural language questions.
Although methods based on static relationship reasoning have made certain
progress, there are still deficiencies in the accuracy of static relationship
recognition and representation, and they have not fully utilized the static
relationship information in videos for in-depth reasoning and analysis.
Therefore, this paper proposes a reasoning method for intra-type and inter-type
message passing based on static relationships. This method constructs a dual
graph for intra-type message passing reasoning and builds a heterogeneous graph
based on static relationships for inter-type message passing reasoning. The
intra-type message passing reasoning model captures the neighborhood
information of targets and relationships related to the question in the dual
graph, updating the dual graph to obtain intra-type clues for answering the
question. The inter-type message passing reasoning model captures the
neighborhood information of targets and relationships from different categories
related to the question in the heterogeneous graph, updating the heterogeneous
graph to obtain inter-type clues for answering the question. Finally, the
answers are inferred by combining the intra-type and inter-type clues based on
static relationships. Experimental results on the ANetQA and Next-QA datasets
demonstrate the effectiveness of this method.

08 Apr 2025
Recent advancements in large language models (LLMs) have significantly
advanced text-to-SQL systems. However, most LLM-based methods often narrowly
focus on SQL generation, neglecting the complexities of real-world
conversational queries. This oversight can lead to unreliable responses,
particularly for ambiguous questions that cannot be directly addressed with
SQL. To bridge this gap, we propose MMSQL, a comprehensive test suite designed
to evaluate the question classification and SQL generation capabilities of LLMs
by simulating real-world scenarios with diverse question types and multi-turn
Q&A interactions. Using MMSQL, we assessed the performance of popular LLMs,
including both open-source and closed-source models, and identified key factors
impacting their performance in such scenarios. Moreover, we introduce an
LLM-based multi-agent framework that employs specialized agents to identify
question types and determine appropriate answering strategies. Our experiments
demonstrate that this approach significantly enhances the model's ability to
navigate the complexities of conversational dynamics, effectively handling the
diverse and complex nature of user queries. Our dataset and code are publicly
available at this https URL

10 Nov 2024
Fine-tuning large language models (LLMs) for specific domain tasks has achieved great success in Text-to-SQL tasks. However, these fine-tuned models often face challenges with multi-turn Text-to-SQL tasks caused by ambiguous or unanswerable questions. It is desired to enhance LLMs to handle multiple types of questions in multi-turn Text-to-SQL tasks. To address this, we propose a novel data augmentation method, called QDA-SQL, which generates multiple types of multi-turn Q\&A pairs using LLMs. In QDA-SQL, we introduce a method incorporating validation and correction mechanisms to handle complex multi-turn Text-to-SQL tasks. Experimental results demonstrate that QDA-SQL enables fine-tuned models to exhibit higher performance on SQL statement accuracy and enhances their ability to handle complex, unanswerable questions in multi-turn Text-to-SQL tasks. The generation script and test set are released at this https URL

05 Apr 2024
Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.

20 Nov 2024
Although great progress has been made in the research of unbiased scene graph generation, issues still hinder improving the predictive performance of both head and tail classes. An unbiased scene graph generation (TA-HDG) is proposed to address these issues. For modeling interactive and non-interactive relations, the Interactive Graph Construction is proposed to model the dependence of relations on objects by combining heterogeneous and dual graph, when modeling relations between multiple objects. It also implements a subject-object pair selection strategy to reduce meaningless edges. Moreover, the Type-Aware Message Passing enhances the understanding of complex interactions by capturing intra- and inter-type context in the Intra-Type and Inter-Type stages. The Intra-Type stage captures the semantic context of inter-relaitons and inter-objects. On this basis, the Inter-Type stage captures the context between objects and relations for interactive and non-interactive relations, respectively. Experiments on two datasets show that TA-HDG achieves improvements in the metrics of R@K and mR@K, which proves that TA-HDG can accurately predict the tail class while maintaining the competitive performance of the head class.

25 Jun 2025
Federated learning aims to train a global model in a distributed environment that is close to the performance of centralized training. However, issues such as client label skew, data quantity skew, and other heterogeneity problems severely degrade the model's performance. Most existing methods overlook the scenario where only a small portion of clients participate in training within a large-scale client setting, whereas our experiments show that this scenario presents a more challenging federated learning task. Therefore, we propose a Knowledge Distillation with teacher-student Inequitable Aggregation (KDIA) strategy tailored to address the federated learning setting mentioned above, which can effectively leverage knowledge from all clients. In KDIA, the student model is the average aggregation of the participating clients, while the teacher model is formed by a weighted aggregation of all clients based on three frequencies: participation intervals, participation counts, and data volume proportions. During local training, self-knowledge distillation is performed. Additionally, we utilize a generator trained on the server to generate approximately independent and identically distributed (IID) data features locally for auxiliary training. We conduct extensive experiments on the CIFAR-10/100/CINIC-10 datasets and various heterogeneous settings to evaluate KDIA. The results show that KDIA can achieve better accuracy with fewer rounds of training, and the improvement is more significant under severe heterogeneity.

20 Jun 2025

Nonlinear optics is crucial for shaping the spatial structure of shortwave light and its interactions with matter, but achieving this through simple harmonic generation with a single pump is challenging. This study demonstrates nonlinear spin-orbit conversion using spin-dependent pump shaping via geometric phase, allowing the direct creation of desired structured harmonic waves from a Gaussian pump beam. By using the liquid-crystal flat optical elements fabricated with photoalignment, we experimentally produce higher-order cylindrically vectorial modes in second harmonic fields. We examine the vectorial spatial wavefunctions, their propagation invariance, and nonlinear spin-orbit conversion. Our results provide an efficient method for full structuring nonlinear light in broader harmonic systems, with significant applications in laser micromachining and high-energy physics.

27 Apr 2025
There has long been a belief that high-level semantics learning can benefit
various downstream computer vision tasks. However, in the low-light image
enhancement (LLIE) community, existing methods learn a brutal mapping between
low-light and normal-light domains without considering the semantic information
of different regions, especially in those extremely dark regions that suffer
from severe information loss. To address this issue, we propose a new deep
semantic prior-guided framework (DeepSPG) based on Retinex image decomposition
for LLIE to explore informative semantic knowledge via a pre-trained semantic
segmentation model and multimodal learning. Notably, we incorporate both
image-level semantic prior and text-level semantic prior and thus formulate a
multimodal learning framework with combinatorial deep semantic prior guidance
for LLIE. Specifically, we incorporate semantic knowledge to guide the
enhancement process via three designs: an image-level semantic prior guidance
by leveraging hierarchical semantic features from a pre-trained semantic
segmentation model; a text-level semantic prior guidance by integrating natural
language semantic constraints via a pre-trained vision-language model; a
multi-scale semantic-aware structure that facilitates effective semantic
feature incorporation. Eventually, our proposed DeepSPG demonstrates superior
performance compared to state-of-the-art methods across five benchmark
datasets. The implementation details and code are publicly available at
this https URL

04 Mar 2024
Multi-view clustering thrives in applications where views are collected in advance by extracting consistent and complementary information among views. However, it overlooks scenarios where data views are collected sequentially, i.e., real-time data. Due to privacy issues or memory burden, previous views are not available with time in these situations. Some methods are proposed to handle it but are trapped in a stability-plasticity dilemma. In specific, these methods undergo a catastrophic forgetting of prior knowledge when a new view is attained. Such a catastrophic forgetting problem (CFP) would cause the consistent and complementary information hard to get and affect the clustering performance. To tackle this, we propose a novel method termed Contrastive Continual Multi-view Clustering with Filtered Structural Fusion (CCMVC-FSF). Precisely, considering that data correlations play a vital role in clustering and prior knowledge ought to guide the clustering process of a new view, we develop a data buffer with fixed size to store filtered structural information and utilize it to guide the generation of a robust partition matrix via contrastive learning. Furthermore, we theoretically connect CCMVC-FSF with semi-supervised learning and knowledge distillation. Extensive experiments exhibit the excellence of the proposed method.
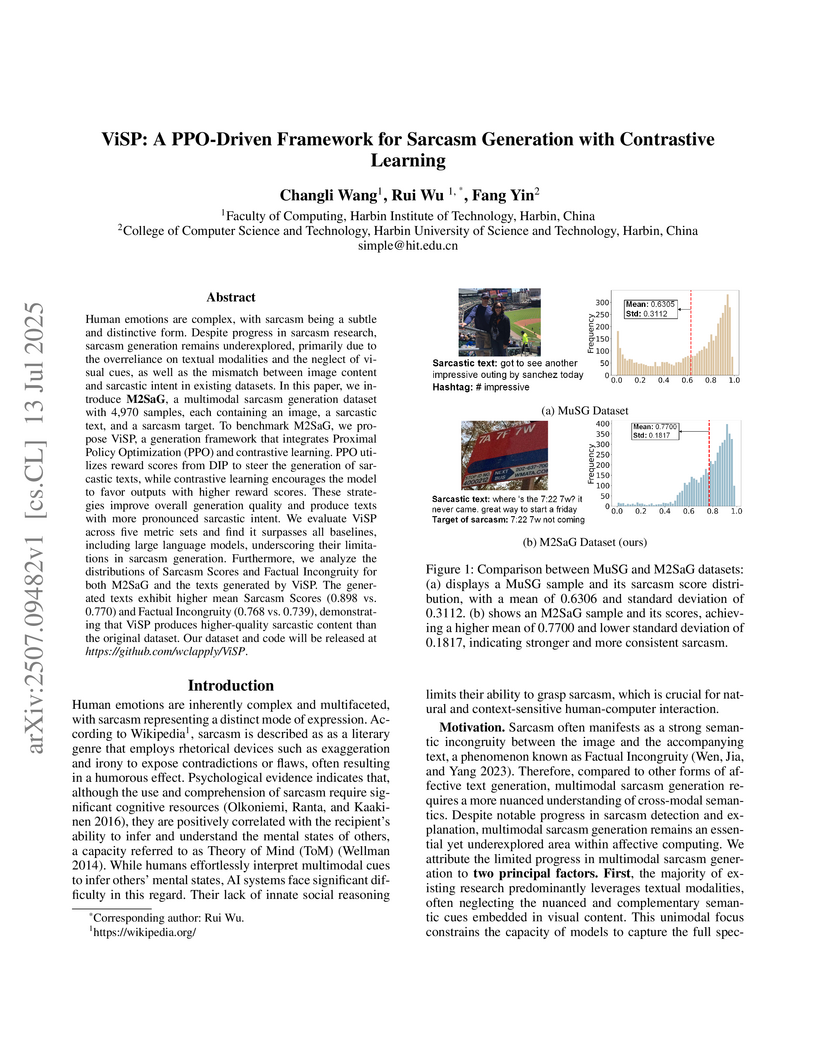
13 Jul 2025
Human emotions are complex, with sarcasm being a subtle and distinctive form. Despite progress in sarcasm research, sarcasm generation remains underexplored, primarily due to the overreliance on textual modalities and the neglect of visual cues, as well as the mismatch between image content and sarcastic intent in existing datasets. In this paper, we introduce M2SaG, a multimodal sarcasm generation dataset with 4,970 samples, each containing an image, a sarcastic text, and a sarcasm target. To benchmark M2SaG, we propose ViSP, a generation framework that integrates Proximal Policy Optimization (PPO) and contrastive learning. PPO utilizes reward scores from DIP to steer the generation of sarcastic texts, while contrastive learning encourages the model to favor outputs with higher reward scores. These strategies improve overall generation quality and produce texts with more pronounced sarcastic intent. We evaluate ViSP across five metric sets and find it surpasses all baselines, including large language models, underscoring their limitations in sarcasm generation. Furthermore, we analyze the distributions of Sarcasm Scores and Factual Incongruity for both M2SaG and the texts generated by ViSP. The generated texts exhibit higher mean Sarcasm Scores (0.898 vs. 0.770) and Factual Incongruity (0.768 vs. 0.739), demonstrating that ViSP produces higher-quality sarcastic content than the original dataset. % The dataset and code will be publicly available. Our dataset and code will be released at \textit{this https URL}.

30 Aug 2023
Environmental sound scene and sound event recognition is important for the
recognition of suspicious events in indoor and outdoor environments (such as
nurseries, smart homes, nursing homes, etc.) and is a fundamental task involved
in many audio surveillance applications. In particular, there is no public
common data set for the research field of sound event recognition for the data
set of the indoor environmental sound scene. Therefore, this paper proposes a
data set (called as AGS) for the home environment sound. This data set
considers various types of overlapping audio in the scene, background noise.
Moreover, based on the proposed data set, this paper compares and analyzes the
advanced methods for sound event recognition, and then illustrates the
reliability of the data set proposed in this paper, and studies the challenges
raised by the new data set. Our proposed AGS and the source code of the
corresponding baselines at this https URL .

21 Feb 2021
Marching Cube algorithm is currently one of the most popular 3D
reconstruction surface rendering algorithms. It forms cube voxels through the
input image, and then uses 15 basic topological configurations to extract the
iso-surfaces in the voxels. It processes each cube voxel in a traversal manner,
but it does not consider the relationship between iso-surfaces in adjacent
cubes. Due to ambiguity, the final reconstructed model may have holes. We
propose a Marching Cube algorithm based on edge growth. The algorithm first
extracts seed triangles, then grows the seed triangles and reconstructs the
entire 3D model. According to the position of the growth edge, we propose 17
topological configurations with iso-surfaces. From the reconstruction results,
the algorithm can reconstruct the 3D model well. When only the main contour of
the 3D model needs to be organized, the algorithm performs well. In addition,
when there are multiple scattered parts in the data, the algorithm can extract
only the 3D contours of the parts connected to the seed by setting the region
selected by the seed.
There are no more papers matching your filters at the moment.
