
16 Sep 2025
Talk2DINO, developed by researchers at UNIMORE and ISTI-CNR, combines the fine-grained visual features of DINOv2 with the rich semantic understanding of CLIP for open-vocabulary segmentation. The approach uses a lightweight, learned projection to bridge their embedding spaces, reaching an average mIoU of 46.3 on eight unsupervised OVS benchmarks with significantly fewer trained parameters than existing methods.

05 Apr 2024
Researchers at CNR-ISTI developed Fine-Grained Open-Vocabulary Object Detection (FG-OVD), a new benchmark and evaluation protocol, to assess how well open-vocabulary object detectors understand fine-grained object attributes. They found that state-of-the-art models exhibit a drastic performance drop when distinguishing subtle attribute differences, particularly for properties like transparency and pattern, revealing a critical gap in current OVD capabilities.

02 Apr 2025

ISTI-CNR researchers develop a semi-supervised biomedical image segmentation framework that combines diffusion models with teacher-student co-training, achieving performance comparable to fully supervised approaches while using only 20% of labeled data across multiple medical imaging datasets including GlaS, PH2, HMEPS, and LA.

18 Mar 2021
In this paper, we describe in details VISIONE, a video search system that
allows users to search for videos using textual keywords, occurrence of objects
and their spatial relationships, occurrence of colors and their spatial
relationships, and image similarity. These modalities can be combined together
to express complex queries and satisfy user needs. The peculiarity of our
approach is that we encode all the information extracted from the keyframes,
such as visual deep features, tags, color and object locations, using a
convenient textual encoding indexed in a single text retrieval engine. This
offers great flexibility when results corresponding to various parts of the
query (visual, text and locations) have to be merged. In addition, we report an
extensive analysis of the system retrieval performance, using the query logs
generated during the Video Browser Showdown (VBS) 2019 competition. This
allowed us to fine-tune the system by choosing the optimal parameters and
strategies among the ones that we tested.

21 Jun 2018
A survey by researchers at the University of Pisa and ISTI-CNR systematically reviews and classifies existing methods for explaining black box AI models, providing a taxonomy of problem types, explanation forms, and model characteristics. This work offers a structured understanding of the Explainable AI field and identifies key open research questions.

02 Oct 2025


The structure of road networks impacts various urban dynamics, from traffic congestion to environmental sustainability and access to essential services. Recent studies reveal that most roads are underutilized, faster alternative routes are often overlooked, and traffic is typically concentrated on a few corridors. In this article, we examine how road network structure, and in particular the presence of mobility attractors (e.g., highways and ring roads), shapes the counterpart to traffic concentration: route diversification. To this end, we introduce DiverCity, a measure that quantifies the extent to which traffic can potentially be distributed across multiple, loosely overlapping near-shortest routes. Analyzing 56 diverse global cities, we find that DiverCity is influenced by network characteristics and is associated with traffic efficiency. Within cities, DiverCity increases with distance from the city center before stabilizing in the periphery, but declines in the proximity of mobility attractors. We demonstrate that strategic speed limit adjustments on mobility attractors can increase DiverCity while preserving travel efficiency. We isolate the complex interplay between mobility attractors and DiverCity through simulations in a controlled setting, confirming the patterns observed in real-world cities. DiverCity provides a practical tool for urban planners and policymakers to optimize road network design and balance route diversification, efficiency, and sustainability. We provide an interactive platform (this https URL) to visualize the spatial distribution of DiverCity across all considered cities.

24 May 2024

The range of real-world scene luminance is larger than the capture capability
of many digital camera sensors which leads to details being lost in captured
images, most typically in bright regions. Inverse tone mapping attempts to
boost these captured Standard Dynamic Range (SDR) images back to High Dynamic
Range (HDR) by creating a mapping that linearizes the well exposed values from
the SDR image, and provides a luminance boost to the clipped content. However,
in most cases, the details in the clipped regions cannot be recovered or
estimated. In this paper, we present a novel inverse tone mapping approach for
mapping SDR images to HDR that generates lost details in clipped regions
through a semantic-aware diffusion based inpainting approach. Our method
proposes two major contributions - first, we propose to use a semantic graph to
guide SDR diffusion based inpainting in masked regions in a saturated image.
Second, drawing inspiration from traditional HDR imaging and bracketing
methods, we propose a principled formulation to lift the SDR inpainted regions
to HDR that is compatible with generative inpainting methods. Results show that
our method demonstrates superior performance across different datasets on
objective metrics, and subjective experiments show that the proposed method
matches (and in most cases outperforms) state-of-art inverse tone mapping
operators in terms of objective metrics and outperforms them for visual
fidelity.

29 Jul 2022
ALADIN introduces a two-stage architecture that distills fine-grained alignment scores into an efficient common embedding space, enabling high-performance image-text matching and retrieval. The model achieves competitive recall while demonstrating up to a 90-fold increase in inference speed compared to entangled Vision-Language Transformers.

21 Sep 2025
This paper presents a comprehensive review of the AIM 2025 Challenge on Inverse Tone Mapping (ITM). The challenge aimed to push forward the development of effective ITM algorithms for HDR image reconstruction from single LDR inputs, focusing on perceptual fidelity and numerical consistency. A total of \textbf{67} participants submitted \textbf{319} valid results, from which the best five teams were selected for detailed analysis. This report consolidates their methodologies and performance, with the lowest PU21-PSNR among the top entries reaching 29.22 dB. The analysis highlights innovative strategies for enhancing HDR reconstruction quality and establishes strong benchmarks to guide future research in inverse tone mapping.

02 Dec 2024

FLANDERS (Federated Learning meets ANomaly DEtection for a Robust and Secure) introduces a pre-aggregation filter for Federated Learning that leverages multidimensional time series anomaly detection to combat extreme model poisoning attacks. The system achieves near-perfect detection accuracy and significantly boosts global model performance, even when 80% of clients are malicious, without requiring prior knowledge of attacker proportions.

25 Jan 2019
The problem of evaluating the performance of soccer players is attracting the
interest of many companies and the scientific community, thanks to the
availability of massive data capturing all the events generated during a match
(e.g., tackles, passes, shots, etc.). Unfortunately, there is no consolidated
and widely accepted metric for measuring performance quality in all of its
facets. In this paper, we design and implement PlayeRank, a data-driven
framework that offers a principled multi-dimensional and role-aware evaluation
of the performance of soccer players. We build our framework by deploying a
massive dataset of soccer-logs and consisting of millions of match events
pertaining to four seasons of 18 prominent soccer competitions. By comparing
PlayeRank to known algorithms for performance evaluation in soccer, and by
exploiting a dataset of players' evaluations made by professional soccer
scouts, we show that PlayeRank significantly outperforms the competitors. We
also explore the ratings produced by {\sf PlayeRank} and discover interesting
patterns about the nature of excellent performances and what distinguishes the
top players from the others. At the end, we explore some applications of
PlayeRank -- i.e. searching players and player versatility --- showing its
flexibility and efficiency, which makes it worth to be used in the design of a
scalable platform for soccer analytics.

29 Sep 2025

Sparse embeddings of data form an attractive class due to their inherent interpretability: Every dimension is tied to a term in some vocabulary, making it easy to visually decipher the latent space. Sparsity, however, poses unique challenges for Approximate Nearest Neighbor Search (ANNS) which finds, from a collection of vectors, the k vectors closest to a query. To encourage research on this underexplored topic, sparse ANNS featured prominently in a BigANN Challenge at NeurIPS 2023, where approximate algorithms were evaluated on large benchmark datasets by throughput and accuracy. In this work, we introduce a set of novel data structures and algorithmic methods, a combination of which leads to an elegant, effective, and highly efficient solution to sparse ANNS. Our contributions range from a theoretically-grounded sketching algorithm for sparse vectors to reduce their effective dimensionality while preserving inner product-induced ranks; a geometric organization of the inverted index; and the blending of local and global information to improve the efficiency and efficacy of ANNS. Empirically, our final algorithm, dubbed Seismic, reaches sub-millisecond per-query latency with high accuracy on a large-scale benchmark dataset using a single CPU.

29 Apr 2024
The research introduces Seismic, a new inverted index structure designed for efficient approximate retrieval over learned sparse representations (LSRs). It achieves sub-millisecond query latencies and high recall, outperforming state-of-the-art inverted index and graph-based ANN methods by significant margins for sparse vector search.

20 Jan 2022
Deepfakes are the result of digital manipulation to forge realistic yet fake imagery. With the astonishing advances in deep generative models, fake images or videos are nowadays obtained using variational autoencoders (VAEs) or Generative Adversarial Networks (GANs). These technologies are becoming more accessible and accurate, resulting in fake videos that are very difficult to be detected. Traditionally, Convolutional Neural Networks (CNNs) have been used to perform video deepfake detection, with the best results obtained using methods based on EfficientNet B7. In this study, we focus on video deep fake detection on faces, given that most methods are becoming extremely accurate in the generation of realistic human faces. Specifically, we combine various types of Vision Transformers with a convolutional EfficientNet B0 used as a feature extractor, obtaining comparable results with some very recent methods that use Vision Transformers. Differently from the state-of-the-art approaches, we use neither distillation nor ensemble methods. Furthermore, we present a straightforward inference procedure based on a simple voting scheme for handling multiple faces in the same video shot. The best model achieved an AUC of 0.951 and an F1 score of 88.0%, very close to the state-of-the-art on the DeepFake Detection Challenge (DFDC).

10 Mar 2025
Capturing images with enough details to solve imaging tasks is a
long-standing challenge in imaging, particularly due to the limitations of
standard dynamic range (SDR) images which often lose details in underexposed or
overexposed regions. Traditional high dynamic range (HDR) methods, like
multi-exposure fusion or inverse tone mapping, struggle with ghosting and
incomplete data reconstruction. Infrared (IR) imaging offers a unique advantage
by being less affected by lighting conditions, providing consistent detail
capture regardless of visible light intensity. In this paper, we introduce the
HDRT dataset, the first comprehensive dataset that consists of HDR and thermal
IR images. The HDRT dataset comprises 50,000 images captured across three
seasons over six months in eight cities, providing a diverse range of lighting
conditions and environmental contexts. Leveraging this dataset, we propose
HDRTNet, a novel deep neural method that fuses IR and SDR content to generate
HDR images. Extensive experiments validate HDRTNet against the
state-of-the-art, showing substantial quantitative and qualitative quality
improvements. The HDRT dataset not only advances IR-guided HDR imaging but also
offers significant potential for broader research in HDR imaging, multi-modal
fusion, domain transfer, and beyond. The dataset is available at
this https URL

30 Apr 2025
An efficient method named TopLoc is introduced to reduce retrieval latency in dense retrieval conversational search systems by leveraging topical locality within multi-turn conversations. The approach integrates with standard ANN algorithms like IVF and HNSW, achieving up to 10.4x speedup and reducing average query response time to as low as 0.7 msec, while largely preserving retrieval effectiveness.

21 Oct 2025
The birth of Foundation Models brought unprecedented results in a wide range of tasks, from language to vision, to robotic control. These models are able to process huge quantities of data, and can extract and develop rich representations, which can be employed across different domains and modalities. However, they still have issues in adapting to dynamic, real-world scenarios without retraining the entire model from scratch. In this work, we propose the application of Continual Learning and Compositionality principles to foster the development of more flexible, efficient and smart AI solutions.

01 Oct 2025
Understanding the inner workings of deep learning models is crucial for advancing artificial intelligence, particularly in high-stakes fields such as healthcare, where accurate explanations are as vital as precision. This paper introduces Batch-CAM, a novel training paradigm that fuses a batch implementation of the Grad-CAM algorithm with a prototypical reconstruction loss. This combination guides the model to focus on salient image features, thereby enhancing its performance across classification tasks. Our results demonstrate that Batch-CAM achieves a simultaneous improvement in accuracy and image reconstruction quality while reducing training and inference times. By ensuring models learn from evidence-relevant information,this approach makes a relevant contribution to building more transparent, explainable, and trustworthy AI systems.

18 Jul 2025
Academic Search is a search task aimed to manage and retrieve scientific documents like journal articles and conference papers. Personalization in this context meets individual researchers' needs by leveraging, through user profiles, the user related information (e.g. documents authored by a researcher), to improve search effectiveness and to reduce the information overload. While citation graphs are a valuable means to support the outcome of recommender systems, their use in personalized academic search (with, e.g. nodes as papers and edges as citations) is still under-explored.
Existing personalized models for academic search often struggle to fully capture users' academic interests. To address this, we propose a two-step approach: first, training a neural language model for retrieval, then converting the academic graph into a knowledge graph and embedding it into a shared semantic space with the language model using translational embedding techniques. This allows user models to capture both explicit relationships and hidden structures in citation graphs and paper content. We evaluate our approach in four academic search domains, outperforming traditional graph-based and personalized models in three out of four, with up to a 10\% improvement in MAP@100 over the second-best model. This highlights the potential of knowledge graph-based user models to enhance retrieval effectiveness.
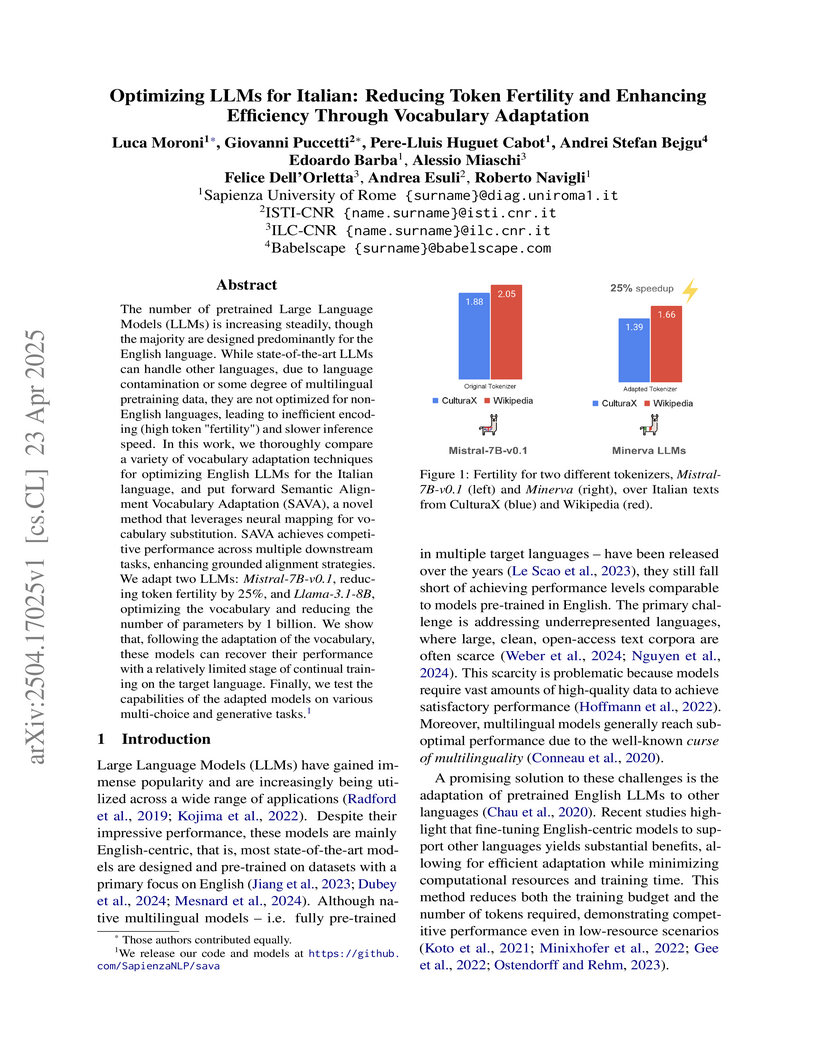
23 Apr 2025
The number of pretrained Large Language Models (LLMs) is increasing steadily,
though the majority are designed predominantly for the English language. While
state-of-the-art LLMs can handle other languages, due to language contamination
or some degree of multilingual pretraining data, they are not optimized for
non-English languages, leading to inefficient encoding (high token "fertility")
and slower inference speed. In this work, we thoroughly compare a variety of
vocabulary adaptation techniques for optimizing English LLMs for the Italian
language, and put forward Semantic Alignment Vocabulary Adaptation (SAVA), a
novel method that leverages neural mapping for vocabulary substitution. SAVA
achieves competitive performance across multiple downstream tasks, enhancing
grounded alignment strategies. We adapt two LLMs: Mistral-7b-v0.1, reducing
token fertility by 25\%, and Llama-3.1-8B, optimizing the vocabulary and
reducing the number of parameters by 1 billion. We show that, following the
adaptation of the vocabulary, these models can recover their performance with a
relatively limited stage of continual training on the target language. Finally,
we test the capabilities of the adapted models on various multi-choice and
generative tasks.
There are no more papers matching your filters at the moment.
