Ask or search anything...
 Chinese Academy of Sciences
Chinese Academy of Sciences National University of Singapore
National University of SingaporeRepoMaster enables LLM-based agents to autonomously explore and understand complex GitHub repositories for task solving by intelligently reusing and adapting existing codebases. It significantly improves task success rates by up to 110% and reduces token consumption by approximately 95% compared to state-of-the-art baselines.
View blog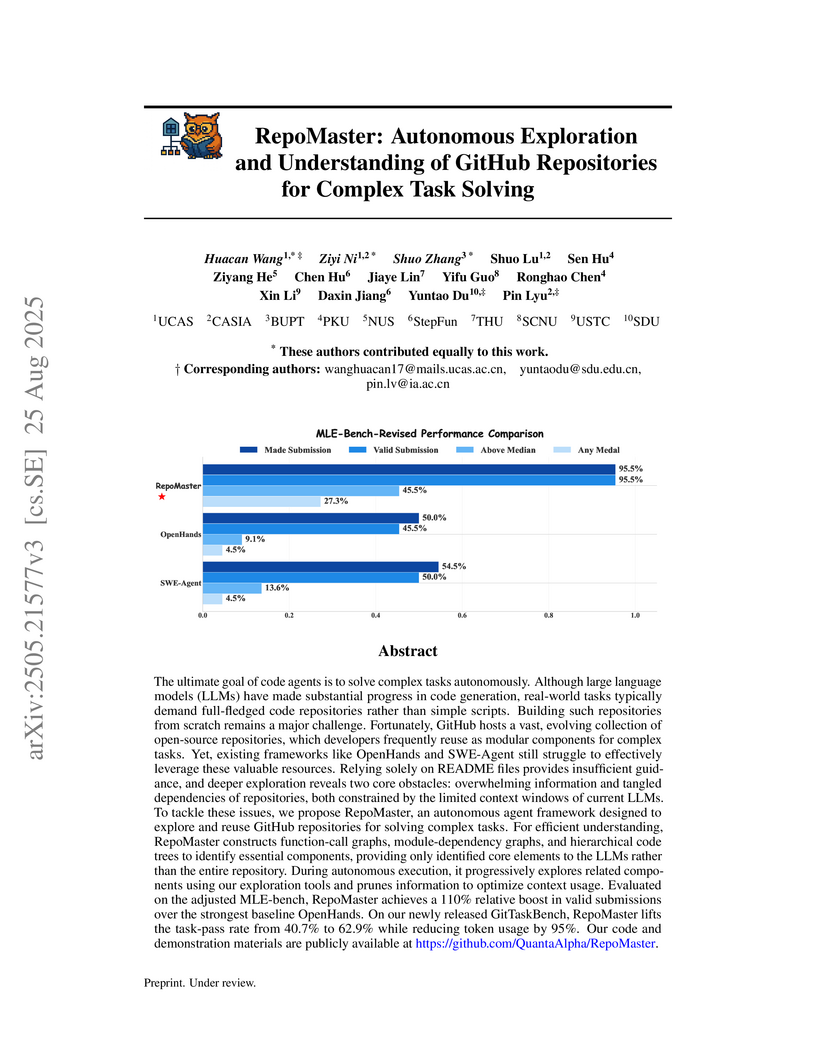

This survey from the Chinese Academy of Sciences provides a systematic review of Large Language Model (LLM)-based scientific agents, detailing their specialized architectures, evaluation benchmarks, diverse applications, and critical ethical considerations. It defines the unique characteristics that differentiate scientific agents from general-purpose LLMs, such as their integration with scientific tools and handling of complex data, outlining current capabilities and challenges in accelerating scientific discovery.
View blog
 Fudan University
Fudan University

 Beihang University
Beihang UniversitySecureWebArena is introduced as the first holistic security evaluation benchmark for LVLM-based web agents, integrating diverse web environments, a broad attack taxonomy, and a multi-layered evaluation protocol. The benchmark reveals consistent vulnerabilities across state-of-the-art models, with pop-up attacks being particularly effective and achieving Payload Delivery Rates (PDR) from 76.67% to 100%.
View blog
 Westlake University
Westlake UniversityTrajVLM-Gen, a two-stage framework developed by researchers from the Chinese Academy of Sciences and Westlake University, enables the generation of physically consistent videos by first employing a Vision-Language Model to predict physics-aware trajectories and then guiding a video diffusion model. The system achieves an 89.6% accuracy in trajectory generation, significantly outperforming baselines, and produces competitive FVD scores on standard video generation benchmarks.
View blog

 Tsinghua University
Tsinghua University
Tree-of-Code (ToC) introduces a self-growing tree framework that enables large language models to generate and execute end-to-end code programs for complex, multi-tool tasks without relying on intermediate ground truth. This approach yields accuracy improvements of nearly 20% on M3ToolEval and API-Bank level-3 datasets, concurrently reducing interaction turns and token usage substantially compared to prior methods.
View blog
 The University of Hong Kong
The University of Hong Kong


 Peking University
Peking University
MiniVLN presents a framework that uses progressive knowledge distillation to create lightweight Vision-and-Language Navigation (VLN) models. It achieves comparable or better performance than teacher models (e.g., 77.59% SR on R2R test unseen vs. ScaleVLN's 77.00%) with only 12% of their parameters and over three times faster inference speed.
View blog




A new large-scale, real-world, and sequential dataset called V2X-Seq, developed by Tsinghua University's AIR and Baidu Inc., enables research in vehicle-infrastructure cooperative perception and forecasting. It provides comprehensive data, including real-time traffic light signals and trajectories, which improves 3D object tracking and multi-agent trajectory prediction in autonomous driving systems.
View blog


TRACT introduces a novel approach for Open-Vocabulary Multi-Object Tracking by explicitly leveraging trajectory information to improve both object association and classification. This method achieves improved tracking performance, particularly boosting classification accuracy for novel object categories on the OV-TAO dataset by 2.5 times compared to prior methods.
View blog