
12 Mar 2024

A Python tool, CAFA-evaluator, was developed to benchmark ontological classification methods, generalizing and consolidating state-of-the-art evaluation methodologies. It provides an efficient, adaptable, and user-friendly platform for any hierarchical classification task and has been adopted as the official evaluation software for the CAFA5 challenge.

30 Jan 2024
Space missions that use low-thrust propulsion technology are becoming
increasingly popular since they utilize propellant more efficiently and thus
reduce mission costs. However, optimizing continuous-thrust trajectories is
complex, time-consuming, and extremely sensitive to initial guesses. Hence,
generating approximate trajectories that can be used as reliable initial
guesses in trajectory generators is essential. This paper presents a
semi-analytic approach for designing planar and three-dimensional trajectories
using Hills equations. The spacecraft is assumed to be acted upon by a constant
thrust acceleration magnitude. The proposed equations are employed in a
Nonlinear Programming Problem (NLP) solver to obtain the thrust directions.
Their applicability is tested for various design scenarios like orbit raising,
orbit insertion, and rendezvous. The trajectory solutions are then validated as
initial guesses in high-fidelity optimal control tools. The usefulness of this
method lies in the preliminary stages of low-thrust mission design, where speed
and reliability are key.
02 Oct 2025
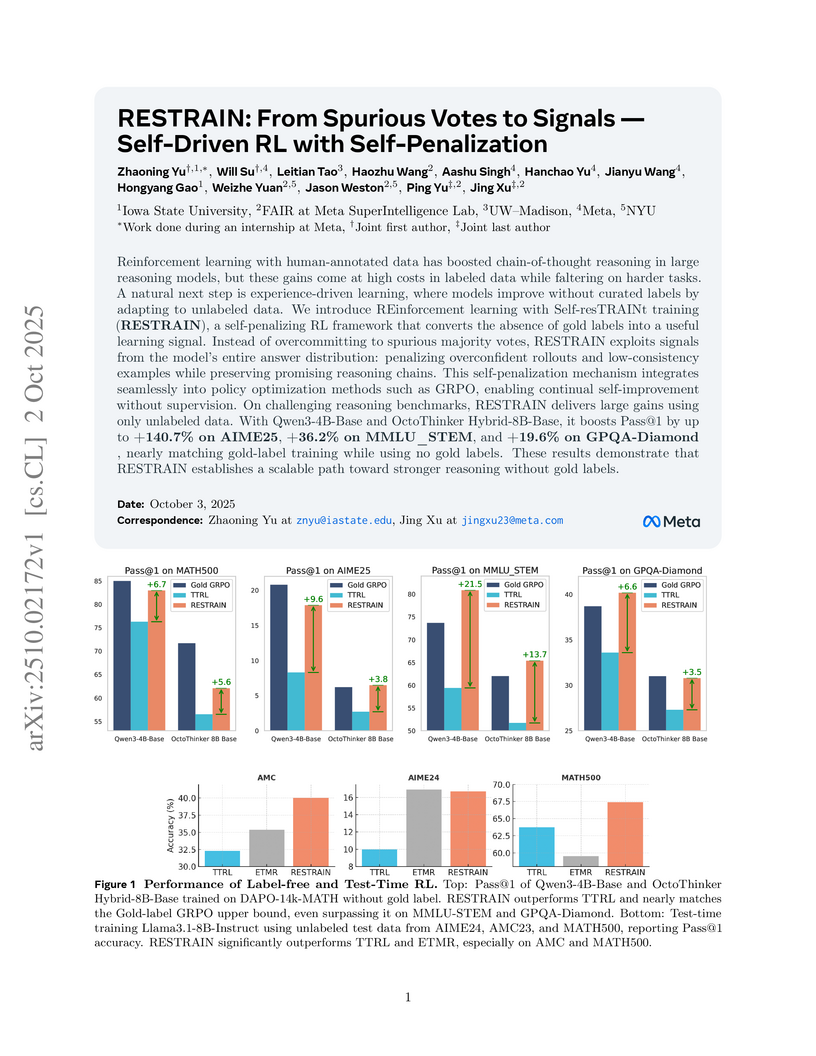
A self-driven reinforcement learning framework called RESTRAIN enables Large Language Models to improve reasoning capabilities without human-annotated labels by converting the absence of supervision and model uncertainty into robust learning signals. This approach surpasses existing unsupervised methods and nearly matches the performance of models trained with full gold-label supervision.

22 Sep 2025
Researchers at QuEra Computing Inc. developed a transversal STAR architecture, co-designed with neutral-atom quantum hardware, to significantly reduce resource overhead for early fault-tolerant quantum simulation. This approach projects over 100x space-time savings and achieves logical error rates approaching 10^-6 for distance-7 surface codes, enabling megaquop-scale Hamiltonian simulation with fewer physical resources.

06 Nov 2025

Retrieval-augmented generation (RAG) aims to reduce hallucinations by grounding responses in external context, yet large language models (LLMs) still frequently introduce unsupported information or contradictions even when provided with relevant context. This paper presents two complementary efforts at Vectara to measure and benchmark LLM faithfulness in RAG. First, we describe our original hallucination leaderboard, which has tracked hallucination rates for LLMs since 2023 using our HHEM hallucination detection model. Motivated by limitations observed in current hallucination detection methods, we introduce FaithJudge, an LLM-as-a-judge framework that leverages a pool of diverse human-annotated hallucination examples to substantially improve the automated hallucination evaluation of LLMs. We introduce an enhanced hallucination leaderboard centered on FaithJudge that benchmarks LLMs on RAG faithfulness in summarization, question-answering, and data-to-text generation tasks. FaithJudge enables a more reliable benchmarking of LLM hallucinations in RAG and supports the development of more trustworthy generative AI systems: this https URL.

13 May 2024
 California Institute of Technology
California Institute of Technology Carnegie Mellon University
Carnegie Mellon University Google
Google New York University
New York University University of Chicago
University of Chicago National University of Singapore
National University of Singapore University of Oxford
University of Oxford Stanford University
Stanford University Meta
Meta CohereIllinois Institute of TechnologyGoogle Research
CohereIllinois Institute of TechnologyGoogle Research NVIDIASony AI
NVIDIASony AI MicrosoftUCSBIntel LabsDFKIUMass Amherst
MicrosoftUCSBIntel LabsDFKIUMass Amherst Virginia Tech
Virginia Tech MIT
MIT The Ohio State UniversityIowa State UniversityUniversity of TrentoUniversity of BathTU EindhovenBocconi UniversityUniversity of YorkIntel CorporationIIT Delhi
The Ohio State UniversityIowa State UniversityUniversity of TrentoUniversity of BathTU EindhovenBocconi UniversityUniversity of YorkIntel CorporationIIT Delhi AdobePolytechnique MontrealQualcomm Technologies, Inc.Hessian.AINIKENebius AIAI Risk and Vulnerability AllianceSaferAIHaize LabsJuniper NetworksCerebras SystemsMeedanRANDFAIRNutanixEthrivaDotphotonPatronus AINational University, PhilippinesMLCommonsGraphcoreCenter for Security and Emerging TechnologyCredo AIReins AIBestech SystemsContext FundActiveFenceDigital Safety Research InstituteLF AI & DataPublic Authority for Applied Education and Training of KuwaitCoactive.AI
AdobePolytechnique MontrealQualcomm Technologies, Inc.Hessian.AINIKENebius AIAI Risk and Vulnerability AllianceSaferAIHaize LabsJuniper NetworksCerebras SystemsMeedanRANDFAIRNutanixEthrivaDotphotonPatronus AINational University, PhilippinesMLCommonsGraphcoreCenter for Security and Emerging TechnologyCredo AIReins AIBestech SystemsContext FundActiveFenceDigital Safety Research InstituteLF AI & DataPublic Authority for Applied Education and Training of KuwaitCoactive.AIThis paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.

11 May 2021



Researchers from Princeton University, The Chinese University of Hong Kong, Iowa State University, and Monash University developed FedBN, a federated learning framework that addresses feature shift non-IID data by keeping Batch Normalization layer parameters local to clients. The method consistently outperforms FedAvg and FedProx, achieving faster convergence and higher accuracy on various benchmark and real-world datasets, including medical imaging.

25 Sep 2025
The reasoning processes of large language models often lack faithfulness; a model may generate a correct answer while relying on a flawed or irrelevant reasoning trace. This behavior, a direct consequence of training objectives that solely reward final-answer correctness, severely undermines the trustworthiness of these models in high-stakes domains. This paper introduces \textbf{Counterfactual Sensitivity Regularization (CSR)}, a novel training objective designed to forge a strong, causal-like dependence between a model's output and its intermediate reasoning steps. During training, CSR performs automated, operator-level interventions on the generated reasoning trace (e.g., swapping ``+'' with ``-'') to create a minimally-perturbed counterfactual. A regularization term then penalizes the model if this logically flawed trace still yields the original answer. Our efficient implementation adds only 8.7\% training overhead through warm-start curriculum and token-subset optimization. We evaluate faithfulness using \textbf{Counterfactual Outcome Sensitivity (COS)}, a metric quantifying how sensitive the final answer is to such logical perturbations. Across diverse structured reasoning benchmarks -- arithmetic (GSM8K), logical deduction (ProofWriter), multi-hop QA (HotpotQA), and code generation (MBPP) -- models trained with CSR demonstrate a vastly superior trade-off between accuracy and faithfulness. CSR improves faithfulness over standard fine-tuning and process supervision by up to 70 percentage points, with this learned sensitivity generalizing to larger models and enhancing the performance of inference-time techniques like self-consistency.

10 Oct 2024


OPPO Research Institute, in collaboration with Shanghai Jiao Tong University and Iowa State University, developed "Hammer" models, which achieve state-of-the-art robust and generalizable function-calling for on-device language models. This is primarily enabled by a novel function masking technique and an irrelevance-augmented dataset, leading to more reliable LLM-powered agents suitable for resource-constrained devices.

01 Jan 2025
MBA-RAG, developed by researchers from The Hong Kong University of Science and Technology (Guangzhou) and Tencent Hunyuan, introduces a multi-armed bandit framework for adaptive Retrieval-Augmented Generation. The system dynamically selects optimal retrieval strategies by balancing generation accuracy and computational cost, achieving state-of-the-art accuracy while reducing average retrieval steps by 17% compared to prior adaptive RAG approaches.

15 Apr 2024


The eighth AI City Challenge highlighted the convergence of computer vision
and artificial intelligence in areas like retail, warehouse settings, and
Intelligent Traffic Systems (ITS), presenting significant research
opportunities. The 2024 edition featured five tracks, attracting unprecedented
interest from 726 teams in 47 countries and regions. Track 1 dealt with
multi-target multi-camera (MTMC) people tracking, highlighting significant
enhancements in camera count, character number, 3D annotation, and camera
matrices, alongside new rules for 3D tracking and online tracking algorithm
encouragement. Track 2 introduced dense video captioning for traffic safety,
focusing on pedestrian accidents using multi-camera feeds to improve insights
for insurance and prevention. Track 3 required teams to classify driver actions
in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics
using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule
violation detection. The challenge utilized two leaderboards to showcase
methods, with participants setting new benchmarks, some surpassing existing
state-of-the-art achievements.

08 Jul 2025
Reward hacking in Reinforcement Learning (RL) systems poses a critical threat to the deployment of autonomous agents, where agents exploit flaws in reward functions to achieve high scores without fulfilling intended objectives. Despite growing awareness of this problem, systematic detection and mitigation approaches remain limited. This paper presents a large-scale empirical study of reward hacking across diverse RL environments and algorithms. We analyze 15,247 training episodes across 15 RL environments (Atari, MuJoCo, custom domains) and 5 algorithms (PPO, SAC, DQN, A3C, Rainbow), implementing automated detection algorithms for six categories of reward hacking: specification gaming, reward tampering, proxy optimization, objective misalignment, exploitation patterns, and wireheading. Our detection framework achieves 78.4% precision and 81.7% recall across environments, with computational overhead under 5%. Through controlled experiments varying reward function properties, we demonstrate that reward density and alignment with true objectives significantly impact hacking frequency (p < 0.001, Cohen's ). We validate our approach through three simulated application studies representing recommendation systems, competitive gaming, and robotic control scenarios. Our mitigation techniques reduce hacking frequency by up to 54.6% in controlled scenarios, though we find these trade-offs are more challenging in practice due to concept drift, false positive costs, and adversarial adaptation. All detection algorithms, datasets, and experimental protocols are publicly available to support reproducible research in RL safety.

27 Jan 2025


We introduce BioTrove, the largest publicly accessible dataset designed to
advance AI applications in biodiversity. Curated from the iNaturalist platform
and vetted to include only research-grade data, BioTrove contains 161.9 million
images, offering unprecedented scale and diversity from three primary kingdoms:
Animalia ("animals"), Fungi ("fungi"), and Plantae ("plants"), spanning
approximately 366.6K species. Each image is annotated with scientific names,
taxonomic hierarchies, and common names, providing rich metadata to support
accurate AI model development across diverse species and ecosystems.
We demonstrate the value of BioTrove by releasing a suite of CLIP models
trained using a subset of 40 million captioned images, known as BioTrove-Train.
This subset focuses on seven categories within the dataset that are
underrepresented in standard image recognition models, selected for their
critical role in biodiversity and agriculture: Aves ("birds"), Arachnida
("spiders/ticks/mites"), Insecta ("insects"), Plantae ("plants"), Fungi
("fungi"), Mollusca ("snails"), and Reptilia ("snakes/lizards"). To support
rigorous assessment, we introduce several new benchmarks and report model
accuracy for zero-shot learning across life stages, rare species, confounding
species, and multiple taxonomic levels.
We anticipate that BioTrove will spur the development of AI models capable of
supporting digital tools for pest control, crop monitoring, biodiversity
assessment, and environmental conservation. These advancements are crucial for
ensuring food security, preserving ecosystems, and mitigating the impacts of
climate change. BioTrove is publicly available, easily accessible, and ready
for immediate use.

25 Sep 2025
Large language models frequently generate confident but incorrect outputs, requiring formal uncertainty quantification with abstention guarantees. We develop information-lift certificates that compare model probabilities to a skeleton baseline, accumulating evidence into sub-gamma PAC-Bayes bounds valid under heavy-tailed distributions. Across eight datasets, our method achieves 77.2\% coverage at 2\% risk, outperforming recent 2023-2024 baselines by 8.6-15.1 percentage points, while blocking 96\% of critical errors in high-stakes scenarios vs 18-31\% for entropy methods. Limitations include skeleton dependence and frequency-only (not severity-aware) risk control, though performance degrades gracefully under corruption.

02 Oct 2025

Understanding and reasoning about code semantics is essential for enhancing code LLMs' abilities to solve real-world software engineering (SE) tasks. Although several code reasoning benchmarks exist, most rely on synthetic datasets or educational coding problems and focus on coarse-grained reasoning tasks such as input/output prediction, limiting their effectiveness in evaluating LLMs in practical SE contexts. To bridge this gap, we propose CodeSense, the first benchmark that makes available a spectrum of fine-grained code reasoning tasks concerned with the software engineering of real-world code. We collected Python, C and Java software projects from real-world repositories. We executed tests from these repositories, collected their execution traces, and constructed a ground truth dataset for fine-grained semantic reasoning tasks. We then performed comprehensive evaluations on state-of-the-art LLMs. Our results show a clear performance gap for the models to handle fine-grained reasoning tasks. Although prompting techniques such as chain-of-thought and in-context learning helped, the lack of code semantics in LLMs fundamentally limit models' capabilities of code reasoning. Besides dataset, benchmark and evaluation, our work produced an execution tracing framework and tool set that make it easy to collect ground truth for fine-grained SE reasoning tasks, offering a strong basis for future benchmark construction and model post training. Our code and data are located at this https URL.

03 May 2024

This research introduces Denoised Diffusion Smoothing (DDS) to achieve provably faithful interpretations for Vision Transformers (ViTs), ensuring both the stability of attention maps and the robustness of predictions under input perturbations. The method consistently outperformed baseline interpretation approaches across various ViT architectures and tasks, yielding clearer, more stable, and class-aware explanations while maintaining or improving prediction accuracy.

17 Oct 2024

Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is this https URL

24 Sep 2025

QBlue is a formally verified compiler framework for Hamiltonian simulation that allows users to express quantum systems using second quantization, providing end-to-end correctness guarantees from high-level physical models to diverse quantum hardware backends. The system, mechanized in the Rocq proof assistant, delivers certified error bounds for approximations and ensures physical validity through its type system.

12 Jun 2025

The National Environment Policy Act (NEPA) stands as a foundational piece of environmental legislation in the United States, requiring federal agencies to consider the environmental impacts of their proposed actions. The primary mechanism for achieving this is through the preparation of Environmental Assessments (EAs) and, for significant impacts, comprehensive Environmental Impact Statements (EIS). Large Language Model (LLM)s' effectiveness in specialized domains like NEPA remains untested for adoption in federal decision-making processes. To address this gap, we present NEPA Question and Answering Dataset (NEPAQuAD), the first comprehensive benchmark derived from EIS documents, along with a modular and transparent evaluation pipeline, MAPLE, to assess LLM performance on NEPA-focused regulatory reasoning tasks. Our benchmark leverages actual EIS documents to create diverse question types, ranging from factual to complex problem-solving ones. We built a modular and transparent evaluation pipeline to test both closed- and open-source models in zero-shot or context-driven QA benchmarks. We evaluate five state-of-the-art LLMs using our framework to assess both their prior knowledge and their ability to process NEPA-specific information. The experimental results reveal that all the models consistently achieve their highest performance when provided with the gold passage as context. While comparing the other context-driven approaches for each model, Retrieval Augmented Generation (RAG)-based approaches substantially outperform PDF document contexts, indicating that neither model is well suited for long-context question-answering tasks. Our analysis suggests that NEPA-focused regulatory reasoning tasks pose a significant challenge for LLMs, particularly in terms of understanding the complex semantics and effectively processing the lengthy regulatory documents.

23 Jul 2025
Generative models such as diffusion and flow-matching offer expressive policies for offline reinforcement learning (RL) by capturing rich, multimodal action distributions, but their iterative sampling introduces high inference costs and training instability due to gradient propagation across sampling steps. We propose the \textit{Single-Step Completion Policy} (SSCP), a generative policy trained with an augmented flow-matching objective to predict direct completion vectors from intermediate flow samples, enabling accurate, one-shot action generation. In an off-policy actor-critic framework, SSCP combines the expressiveness of generative models with the training and inference efficiency of unimodal policies, without requiring long backpropagation chains. Our method scales effectively to offline, offline-to-online, and online RL settings, offering substantial gains in speed and adaptability over diffusion-based baselines. We further extend SSCP to goal-conditioned RL, enabling flat policies to exploit subgoal structures without explicit hierarchical inference. SSCP achieves strong results across standard offline RL and behavior cloning benchmarks, positioning it as a versatile, expressive, and efficient framework for deep RL and sequential decision-making.
There are no more papers matching your filters at the moment.
