
23 Sep 2025
This paper focuses on automatic music engraving, i.e., the creation of a humanly-readable musical score from musical content. This step is fundamental for all applications that include a human player, but it remains a mostly unexplored topic in symbolic music processing. In this work, we formalize the problem as a collection of interdependent subtasks, and propose a unified graph neural network (GNN) framework that targets the case of piano music and quantized symbolic input. Our method employs a multi-task GNN to jointly predict voice connections, staff assignments, pitch spelling, key signature, stem direction, octave shifts, and clef signs. A dedicated postprocessing pipeline generates print-ready MusicXML/MEI outputs. Comprehensive evaluation on two diverse piano corpora (J-Pop and DCML Romantic) demonstrates that our unified model achieves good accuracy across all subtasks, compared to existing systems that only specialize in specific subtasks. These results indicate that a shared GNN encoder with lightweight task-specific decoders in a multi-task setting offers a scalable and effective solution for automatic music engraving.

27 Oct 2023


Reinforcement Learning (RL) has been successful in various domains like
robotics, game playing, and simulation. While RL agents have shown impressive
capabilities in their specific tasks, they insufficiently adapt to new tasks.
In supervised learning, this adaptation problem is addressed by large-scale
pre-training followed by fine-tuning to new down-stream tasks. Recently,
pre-training on multiple tasks has been gaining traction in RL. However,
fine-tuning a pre-trained model often suffers from catastrophic forgetting.
That is, the performance on the pre-training tasks deteriorates when
fine-tuning on new tasks. To investigate the catastrophic forgetting
phenomenon, we first jointly pre-train a model on datasets from two benchmark
suites, namely Meta-World and DMControl. Then, we evaluate and compare a
variety of fine-tuning methods prevalent in natural language processing, both
in terms of performance on new tasks, and how well performance on pre-training
tasks is retained. Our study shows that with most fine-tuning approaches, the
performance on pre-training tasks deteriorates significantly. Therefore, we
propose a novel method, Learning-to-Modulate (L2M), that avoids the degradation
of learned skills by modulating the information flow of the frozen pre-trained
model via a learnable modulation pool. Our method achieves state-of-the-art
performance on the Continual-World benchmark, while retaining performance on
the pre-training tasks. Finally, to aid future research in this area, we
release a dataset encompassing 50 Meta-World and 16 DMControl tasks.

28 Sep 2025


The advancements of technology have led to the use of multimodal systems in various real-world applications. Among them, audio-visual systems are among the most widely used multimodal systems. In the recent years, associating face and voice of a person has gained attention due to the presence of unique correlation between them. The Face-voice Association in Multilingual Environments (FAME) 2026 Challenge focuses on exploring face-voice association under the unique condition of a multilingual scenario. This condition is inspired from the fact that half of the world's population is bilingual and most often people communicate under multilingual scenarios. The challenge uses a dataset named Multilingual Audio-Visual (MAV-Celeb) for exploring face-voice association in multilingual environments. This report provides the details of the challenge, dataset, baseline models, and task details for the FAME Challenge.

18 Sep 2025
Music is characterized by aspects related to different modalities, such as the audio signal, the lyrics, or the music video clips. This has motivated the development of multimodal datasets and methods for Music Information Retrieval (MIR) tasks such as genre classification or autotagging. Music can be described at different levels of granularity, for instance defining genres at the level of artists or music albums. However, most datasets for multimodal MIR neglect this aspect and provide data at the level of individual music tracks. We aim to fill this gap by providing Music4All Artist and Album (Music4All A+A), a dataset for multimodal MIR tasks based on music artists and albums. Music4All A+A is built on top of the Music4All-Onion dataset, an existing track-level dataset for MIR tasks. Music4All A+A provides metadata, genre labels, image representations, and textual descriptors for 6,741 artists and 19,511 albums. Furthermore, since Music4All A+A is built on top of Music4All-Onion, it allows access to other multimodal data at the track level, including user--item interaction data. This renders Music4All A+A suitable for a broad range of MIR tasks, including multimodal music recommendation, at several levels of granularity. To showcase the use of Music4All A+A, we carry out experiments on multimodal genre classification of artists and albums, including an analysis in missing-modality scenarios, and a quantitative comparison with genre classification in the movie domain. Our experiments show that images are more informative for classifying the genres of artists and albums, and that several multimodal models for genre classification struggle in generalizing across domains. We provide the code to reproduce our experiments at this https URL, the dataset is linked in the repository and provided open-source under a CC BY-NC-SA 4.0 license.

26 Sep 2024
SiBraR (Single-Branch embedding network for Recommendation) uses a weight-sharing architecture to learn unified representations from diverse content modalities and collaborative interaction data. This approach enables robust recommendations in cold-start scenarios and effectively handles missing modalities, demonstrating superior performance across music, movie, and e-commerce datasets compared to existing methods.

24 Oct 2023
Quantifying uncertainty is important for actionable predictions in real-world
applications. A crucial part of predictive uncertainty quantification is the
estimation of epistemic uncertainty, which is defined as an integral of the
product between a divergence function and the posterior. Current methods such
as Deep Ensembles or MC dropout underperform at estimating the epistemic
uncertainty, since they primarily consider the posterior when sampling models.
We suggest Quantification of Uncertainty with Adversarial Models (QUAM) to
better estimate the epistemic uncertainty. QUAM identifies regions where the
whole product under the integral is large, not just the posterior.
Consequently, QUAM has lower approximation error of the epistemic uncertainty
compared to previous methods. Models for which the product is large correspond
to adversarial models (not adversarial examples!). Adversarial models have both
a high posterior as well as a high divergence between their predictions and
that of a reference model. Our experiments show that QUAM excels in capturing
epistemic uncertainty for deep learning models and outperforms previous methods
on challenging tasks in the vision domain.

17 Jan 2023
Predicting future direction of stock markets using the historical data has been a fundamental component in financial forecasting. This historical data contains the information of a stock in each specific time span, such as the opening, closing, lowest, and highest price. Leveraging this data, the future direction of the market is commonly predicted using various time-series models such as Long-Short Term Memory networks. This work proposes modeling and predicting market movements with a fundamentally new approach, namely by utilizing image and byte-based number representation of the stock data processed with the recently introduced Vision-Language models. We conduct a large set of experiments on the hourly stock data of the German share index and evaluate various architectures on stock price prediction using historical stock data. We conduct a comprehensive evaluation of the results with various metrics to accurately depict the actual performance of various approaches. Our evaluation results show that our novel approach based on representation of stock data as text (bytes) and image significantly outperforms strong deep learning-based baselines.

28 Jun 2025
DE-DETECT, a multimodal late-fusion pipeline, identifies AI-generated lyrics using only audio input by combining automatically transcribed text and speech features. This method demonstrated superior robustness against audio perturbations and better generalization to unseen AI music generators, achieving an average recall of 87.9% under attacks and 94.1% for an unseen generator.

07 Jul 2025
Generative models of music audio are typically used to generate output based solely on a text prompt or melody. Boomerang sampling, recently proposed for the image domain, allows generating output close to an existing example, using any pretrained diffusion model. In this work, we explore its application in the audio domain as a tool for data augmentation or content manipulation. Specifically, implementing Boomerang sampling for Stable Audio Open, we augment training data for a state-of-the-art beat tracker, and attempt to replace musical instruments in recordings. Our results show that the rhythmic structure of existing examples is mostly preserved, that it improves performance of the beat tracker, but only in scenarios of limited training data, and that it can accomplish text-based instrument replacement on monophonic inputs. We publish our implementation to invite experiments on data augmentation in other tasks and explore further applications.

06 Sep 2023
We present the Batik-plays-Mozart Corpus, a piano performance dataset combining professional Mozart piano sonata performances with expert-labelled scores at a note-precise level. The performances originate from a recording by Viennese pianist Roland Batik on a computer-monitored Bösendorfer grand piano, and are available both as MIDI files and audio recordings. They have been precisely aligned, note by note, with a current standard edition of the corresponding scores (the New Mozart Edition) in such a way that they can further be connected to the musicological annotations (harmony, cadences, phrases) on these scores that were recently published by Hentschel et al. (2021).
The result is a high-quality, high-precision corpus mapping scores and musical structure annotations to precise note-level professional performance information. As the first of its kind, it can serve as a valuable resource for studying various facets of expressive performance and their relationship with structural aspects. In the paper, we outline the curation process of the alignment and conduct two exploratory experiments to demonstrate its usefulness in analyzing expressive performance.
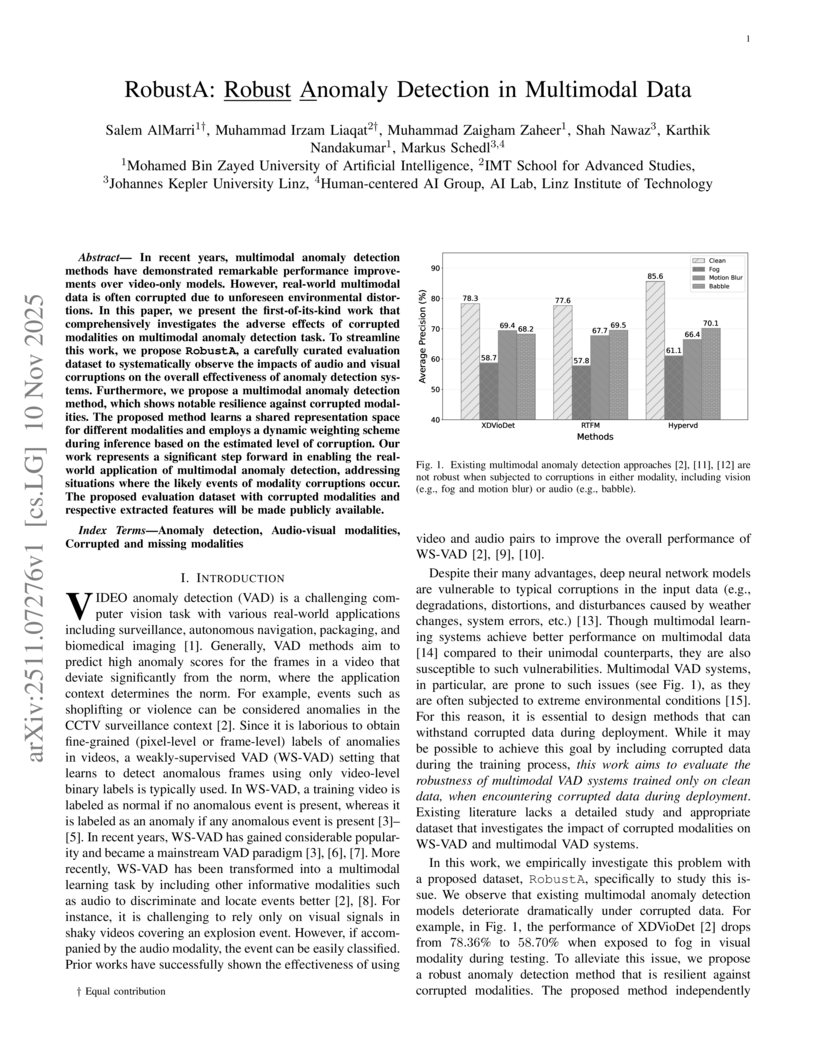
11 Nov 2025
In recent years, multimodal anomaly detection methods have demonstrated remarkable performance improvements over video-only models. However, real-world multimodal data is often corrupted due to unforeseen environmental distortions. In this paper, we present the first-of-its-kind work that comprehensively investigates the adverse effects of corrupted modalities on multimodal anomaly detection task. To streamline this work, we propose RobustA, a carefully curated evaluation dataset to systematically observe the impacts of audio and visual corruptions on the overall effectiveness of anomaly detection systems. Furthermore, we propose a multimodal anomaly detection method, which shows notable resilience against corrupted modalities. The proposed method learns a shared representation space for different modalities and employs a dynamic weighting scheme during inference based on the estimated level of corruption. Our work represents a significant step forward in enabling the real-world application of multimodal anomaly detection, addressing situations where the likely events of modality corruptions occur. The proposed evaluation dataset with corrupted modalities and respective extracted features will be made publicly available.

07 Aug 2025
Recently, the information content (IC) of predictions from a Generative Infinite-Vocabulary Transformer (GIVT) has been used to model musical expectancy and surprisal in audio. We investigate the effectiveness of such modelling using IC calculated with autoregressive diffusion models (ADMs). We empirically show that IC estimates of models based on two different diffusion ordinary differential equations (ODEs) describe diverse data better, in terms of negative log-likelihood, than a GIVT. We evaluate diffusion model IC's effectiveness in capturing surprisal aspects by examining two tasks: (1) capturing monophonic pitch surprisal, and (2) detecting segment boundaries in multi-track audio. In both tasks, the diffusion models match or exceed the performance of a GIVT. We hypothesize that the surprisal estimated at different diffusion process noise levels corresponds to the surprisal of music and audio features present at different audio granularities. Testing our hypothesis, we find that, for appropriate noise levels, the studied musical surprisal tasks' results improve. Code is provided on this http URL.

13 Oct 2022
In response to a recent Nature article which announced an algorithm for multiplying -matrices over with only 96 multiplications, two fewer than the previous record, we present an algorithm that does the job with only 95 multiplications.

11 Mar 2025
In session-based recommender systems, predictions are based on the user's
preceding behavior in the session. State-of-the-art sequential recommendation
algorithms either use graph neural networks to model sessions in a graph or
leverage the similarity of sessions by exploiting item features. In this paper,
we combine these two approaches and propose a novel method, Graph Convolutional
Network Extension (GCNext), which incorporates item features directly into the
graph representation via graph convolutional networks. GCNext creates a
feature-rich item co-occurrence graph and learns the corresponding item
embeddings in an unsupervised manner. We show on three datasets that
integrating GCNext into sequential recommendation algorithms significantly
boosts the performance of nearest-neighbor methods as well as neural network
models. Our flexible extension is easy to incorporate in state-of-the-art
methods and increases the MRR@20 by up to 12.79%.

30 Aug 2023

Graph neural networks (GNNs) have evolved into one of the most popular deep learning architectures. However, GNNs suffer from over-smoothing node information and, therefore, struggle to solve tasks where global graph properties are relevant. We introduce G-Signatures, a novel graph learning method that enables global graph propagation via randomized signatures. G-Signatures use a new graph conversion concept to embed graph structured information which can be interpreted as paths in latent space. We further introduce the idea of latent space path mapping. This allows us to iteratively traverse latent space paths, and, thus globally process information. G-Signatures excel at extracting and processing global graph properties, and effectively scale to large graph problems. Empirically, we confirm the advantages of G-Signatures at several classification and regression tasks.

16 Jun 2021
Music emotion recognition is an important task in MIR (Music Information
Retrieval) research. Owing to factors like the subjective nature of the task
and the variation of emotional cues between musical genres, there are still
significant challenges in developing reliable and generalizable models. One
important step towards better models would be to understand what a model is
actually learning from the data and how the prediction for a particular input
is made. In previous work, we have shown how to derive explanations of model
predictions in terms of spectrogram image segments that connect to the
high-level emotion prediction via a layer of easily interpretable perceptual
features. However, that scheme lacks intuitive musical comprehensibility at the
spectrogram level. In the present work, we bridge this gap by merging audioLIME
-- a source-separation based explainer -- with mid-level perceptual features,
thus forming an intuitive connection chain between the input audio and the
output emotion predictions. We demonstrate the usefulness of this method by
applying it to debug a biased emotion prediction model.

31 Oct 2021
Homophily describes the phenomenon that similarity breeds connection, i.e.,
individuals tend to form ties with other people who are similar to themselves
in some aspect(s). The similarity in music taste can undoubtedly influence who
we make friends with and shape our social circles. In this paper, we study
homophily in an online music platform Last.fm regarding user preferences
towards listening to mainstream (M), novel (N), or diverse (D) content.
Furthermore, we draw comparisons with homophily based on listening profiles
derived from artists users have listened to in the past, i.e., artist profiles.
Finally, we explore the utility of users' artist profiles as well as features
describing M, N, and D for the task of link prediction. Our study reveals that:
(i) users with a friendship connection share similar music taste based on their
artist profiles; (ii) on average, a measure of how diverse is the music two
users listen to is a stronger predictor of friendship than measures of their
preferences towards mainstream or novel content, i.e., homophily is stronger
for D than for M and N; (iii) some user groups such as high-novelty-seekers
(explorers) exhibit strong homophily, but lower than average artist profile
similarity; (iv) using M, N and D achieves comparable results on link
prediction accuracy compared with using artist profiles, but the combination of
features yields the best accuracy results, and (v) using combined features does
not add value if graph-based features such as common neighbors are available,
making M, N, and D features primarily useful in a cold-start user
recommendation setting for users with few friendship connections. The insights
from this study will inform future work on social context-aware music
recommendation, user modeling, and link prediction.

15 Jan 2024
Collaborative filtering-based recommender systems leverage vast amounts of
behavioral user data, which poses severe privacy risks. Thus, often, random
noise is added to the data to ensure Differential Privacy (DP). However, to
date, it is not well understood, in which ways this impacts personalized
recommendations. In this work, we study how DP impacts recommendation accuracy
and popularity bias, when applied to the training data of state-of-the-art
recommendation models. Our findings are three-fold: First, we find that nearly
all users' recommendations change when DP is applied. Second, recommendation
accuracy drops substantially while recommended item popularity experiences a
sharp increase, suggesting that popularity bias worsens. Third, we find that DP
exacerbates popularity bias more severely for users who prefer unpopular items
than for users that prefer popular items.

01 Apr 2019
The RISC Algorithm Language (RISCAL) is a language for the formal modeling of
theories and algorithms. A RISCAL specification describes an infinite class of
models each of which has finite size; this allows to fully automatically check
in such a model the validity of all theorems and the correctness of all
algorithms. RISCAL thus enables us to quickly verify/falsify the specific truth
of propositions in sample instances of a model class before attempting to prove
their general truth in the whole class: the first can be achieved in a fully
automatic way while the second typically requires our assistance. RISCAL has
been mainly developed for educational purposes. To this end this paper reports
on some new enhancements of the tool: the automatic generation of checkable
verification conditions from algorithms, the visualization of the execution of
procedures and the evaluation of formulas illustrating the computation of their
results, and the generation of Web-based student exercises and assignments from
RISCAL specifications. Furthermore, we report on our first experience with
RISCAL in the teaching of courses on logic and formal methods and on further
plans to use this tool to enhance formal education.

13 Jan 2025

In modeling musical surprisal expectancy with computational methods, it has been proposed to use the information content (IC) of one-step predictions from an autoregressive model as a proxy for surprisal in symbolic music. With an appropriately chosen model, the IC of musical events has been shown to correlate with human perception of surprise and complexity aspects, including tonal and rhythmic complexity. This work investigates whether an analogous methodology can be applied to music audio. We train an autoregressive Transformer model to predict compressed latent audio representations of a pretrained autoencoder network. We verify learning effects by estimating the decrease in IC with repetitions. We investigate the mean IC of musical segment types (e.g., A or B) and find that segment types appearing later in a piece have a higher IC than earlier ones on average. We investigate the IC's relation to audio and musical features and find it correlated with timbral variations and loudness and, to a lesser extent, dissonance, rhythmic complexity, and onset density related to audio and musical features. Finally, we investigate if the IC can predict EEG responses to songs and thus model humans' surprisal in music. We provide code for our method on this http URL.
There are no more papers matching your filters at the moment.
