Ask or search anything...

 Northeastern University
Northeastern UniversityMixtureVitae introduces an open, web-scale pretraining dataset that minimizes legal and ethical risks by using permissive-first text sources, augmented with high-quality instruction and reasoning data. Models trained on this corpus achieve performance competitive with those trained on non-permissive data, and demonstrate an order-of-magnitude improvement in math and coding abilities over other permissive datasets.
View blog
 Inria
InriaLatent Discrete Diffusion Models (LDDMs) address the factorization bottleneck in masked discrete diffusion by coupling a discrete token diffusion with a co-evolving continuous latent channel. This approach improves unconditional generation quality, particularly at low sampling budgets, on tasks like text generation by enabling more coherent and consistent outputs.
View blog
 CNRS
CNRSResearchers from the University of Trento and LIGM introduce Dense Motion Captioning (DMC), a new task for 3D human motion understanding that requires localizing and describing multiple atomic actions within complex, untrimmed motion sequences. They present CompMo, a large-scale dataset with precise temporal and textual annotations, and DEMO, a novel LLM-based model that significantly outperforms baselines in dense captioning quality and temporal localization.
View blog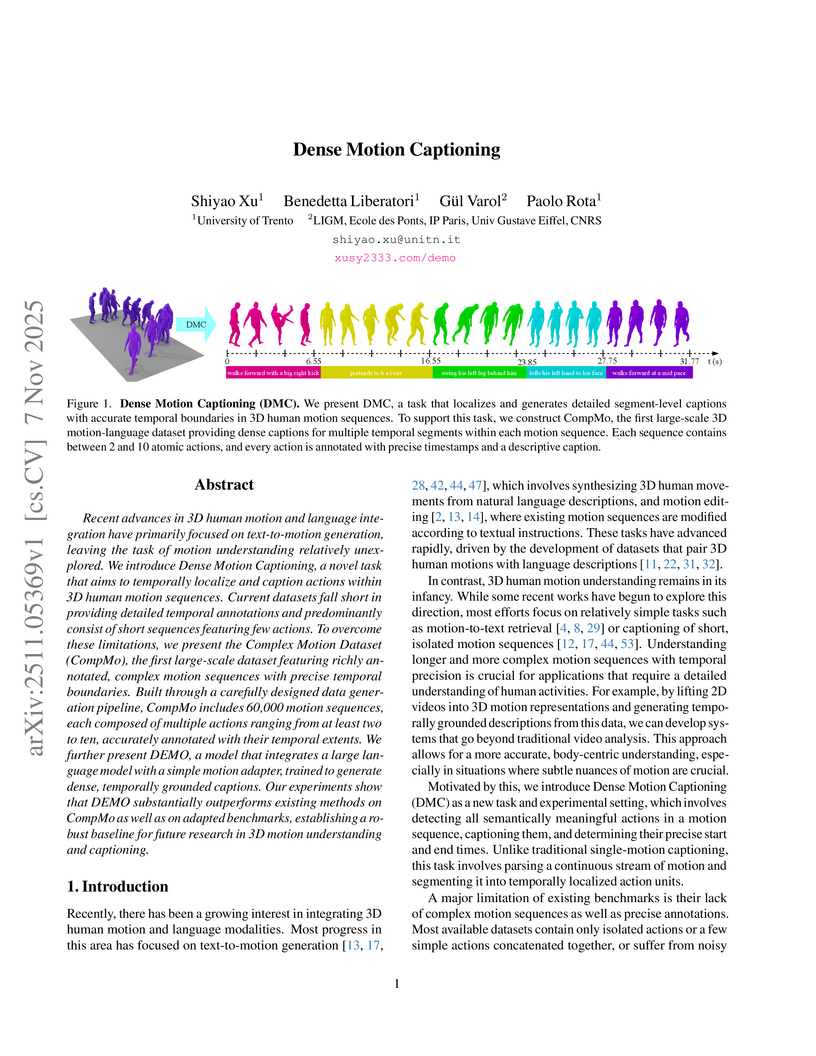
The NextBestPath (NBP) method introduces a deep learning approach for active 3D mapping that predicts long-term exploration goals, optimizing for surface coverage gain while simultaneously generating obstacle maps for path planning. This approach achieves a 6.23 absolute gain in completion ratio over the state-of-the-art ANM model on the MP3D dataset and outperforms baselines on the new AiMDoom dataset.
View blog
 Université Paris-Saclay
Université Paris-SaclayResearchers from ENSAE, CREST, and IP Paris introduce a theoretically grounded framework for optimizing functionals on data represented as probability distributions over probability distributions, utilizing Wasserstein over Wasserstein (WoW) gradient flows. This method establishes a rigorous differential structure for these higher-order spaces and provides a tractable, particle-based approach for tasks like domain adaptation, dataset distillation, and transfer learning, showing improved accuracy and efficiency.
View blog


 UC Berkeley
UC Berkeley








 NVIDIA
NVIDIA
 California Institute of Technology
California Institute of Technology

 INFN
INFN
 ETH Zurich
ETH Zurich