
28 Apr 2025



Perception Encoder introduces a family of vision models that achieve state-of-the-art performance across diverse vision and vision-language tasks, demonstrating that general, high-quality visual features can be extracted from the intermediate layers of a single, contrastively-trained network. It provides specific alignment tuning methods to make these features accessible for tasks ranging from zero-shot classification to dense spatial prediction and multimodal language understanding.

18 Sep 2025

Researchers from Meta Reality Labs and Carnegie Mellon University developed MapAnything, a transformer-based model that unifies over 12 3D reconstruction tasks by directly predicting metric 3D scene geometry and camera parameters from diverse, heterogeneous inputs. This single feed-forward model achieves state-of-the-art or comparable performance across tasks such as multi-view dense reconstruction, monocular depth estimation, and camera localization.

30 Sep 2025


TruthRL introduces a reinforcement learning framework that optimizes LLM truthfulness through a ternary reward scheme, significantly reducing hallucination rates by distinguishing between incorrect answers and appropriate abstentions. This approach leads to models that are more capable of recognizing knowledge boundaries and expressing uncertainty across various model sizes.

23 Jul 2025
Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models. this https URL
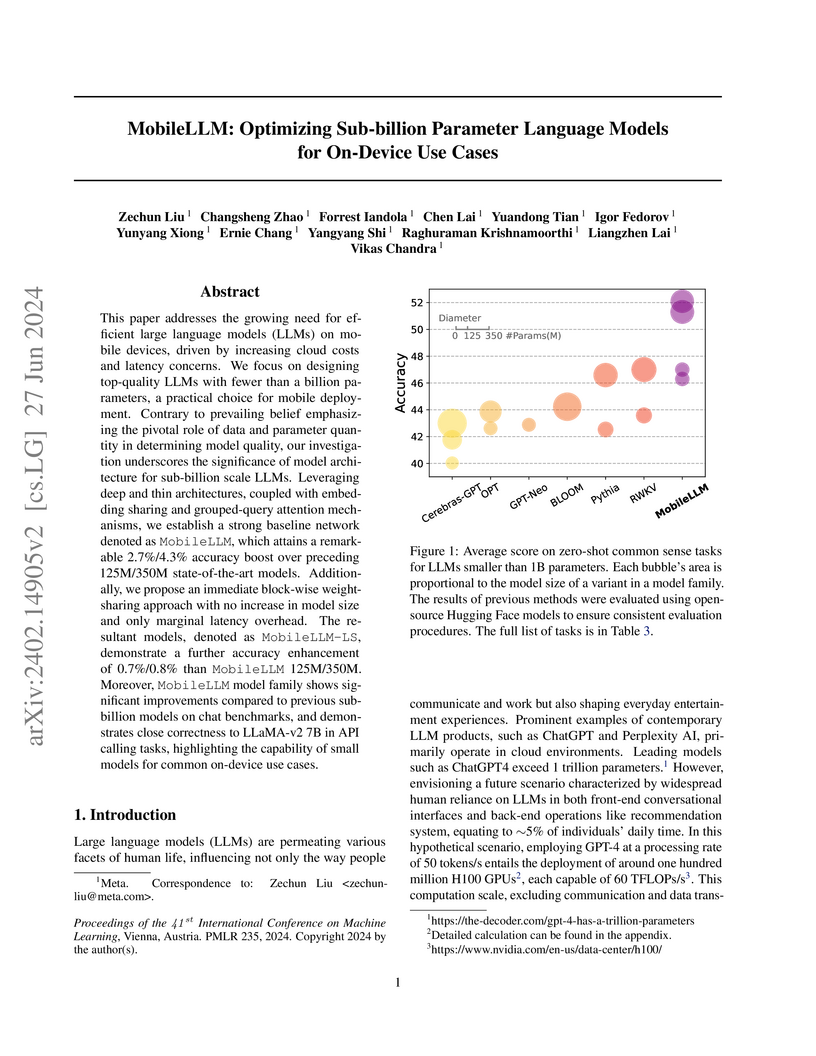
27 Jun 2024

MobileLLM develops a suite of sub-billion parameter language models optimized for efficient on-device deployment, achieving state-of-the-art performance in their class through architectural innovations and immediate block-wise layer sharing. The models demonstrate enhanced efficiency on mobile hardware, significantly outperforming previous small LLMs across various benchmarks while maintaining compatibility with 8-bit quantization.

18 Dec 2024


This paper introduces a method to enable Large Language Models to both understand and generate visual content through a simple instruction tuning approach

05 Nov 2025
A comprehensive survey systematically reviews text-driven 360-degree panorama generation, establishing a taxonomy of methods and analyzing representational challenges while benchmarking state-of-the-art models. The work also reveals the inadequacy of universal evaluation metrics for panoramic content and proposes future research directions.
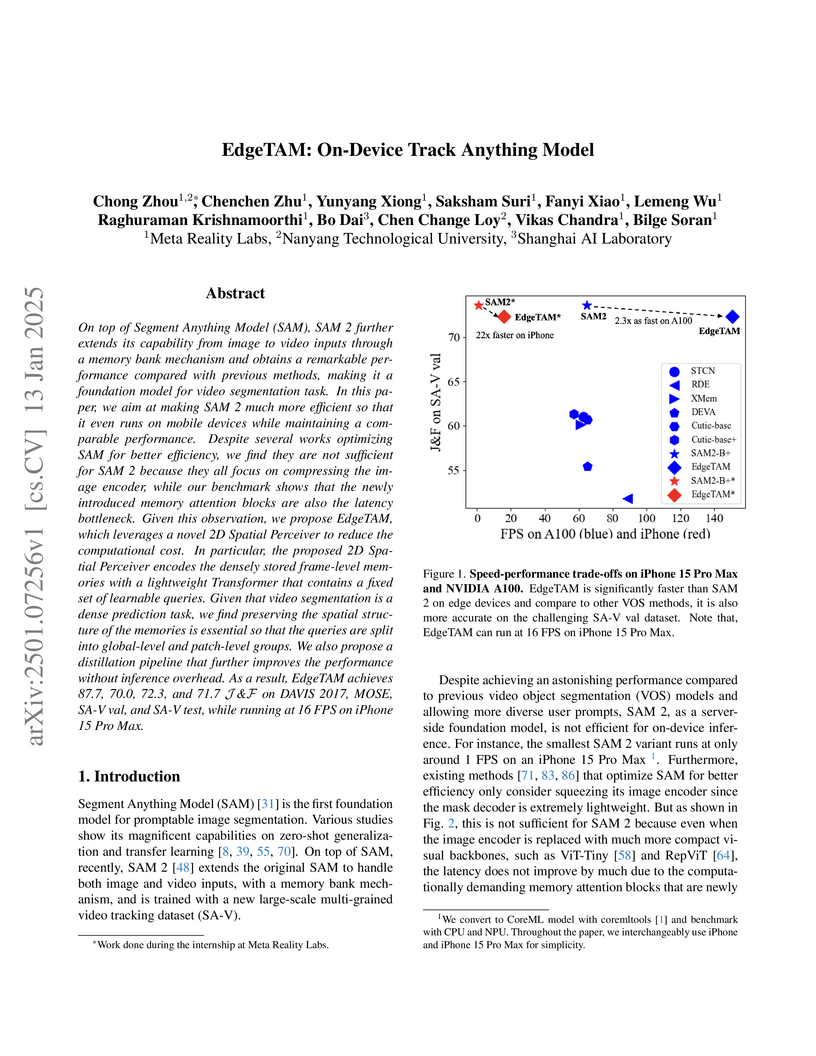
13 Jan 2025

EdgeTAM, developed by Meta Reality Labs, Nanyang Technological University, and Shanghai AI Laboratory, introduces an efficient version of SAM 2 capable of performing unified video and image segmentation and tracking on mobile devices. It achieves 16 FPS on an iPhone 15 Pro Max, a 22x speed-up over SAM 2, while maintaining competitive accuracy by addressing the memory attention bottleneck with a novel 2D Spatial Perceiver and knowledge distillation.

01 Nov 2024



CRAG, a new benchmark from Meta Reality Labs, FAIR, and HKUST, evaluates Retrieval-Augmented Generation (RAG) systems against the complexities of real-world question answering. It features diverse, temporally dynamic questions and realistic noisy retrieval environments, revealing that current RAG solutions, even state-of-the-art ones, still exhibit significant hallucination rates ranging from 16% to 25%, particularly when dealing with dynamic information and complex reasoning.

10 Apr 2025

ProVideLLM introduces a memory-efficient framework for streaming procedural video understanding, which employs a multimodal interleaved cache and a DETR-QFormer to capture fine-grained hand-object interactions. The system achieves state-of-the-art performance across six procedural video tasks while maintaining real-time inference and constant memory usage for extended video lengths.

05 Dec 2025

Forecasting how human hands move in egocentric views is critical for applications like augmented reality and human-robot policy transfer. Recently, several hand trajectory prediction (HTP) methods have been developed to generate future possible hand waypoints, which still suffer from insufficient prediction targets, inherent modality gaps, entangled hand-head motion, and limited validation in downstream tasks. To address these limitations, we present a universal hand motion forecasting framework considering multi-modal input, multi-dimensional and multi-target prediction patterns, and multi-task affordances for downstream applications. We harmonize multiple modalities by vision-language fusion, global context incorporation, and task-aware text embedding injection, to forecast hand waypoints in both 2D and 3D spaces. A novel dual-branch diffusion is proposed to concurrently predict human head and hand movements, capturing their motion synergy in egocentric vision. By introducing target indicators, the prediction model can forecast the specific joint waypoints of the wrist or the fingers, besides the widely studied hand center points. In addition, we enable Uni-Hand to additionally predict hand-object interaction states (contact/separation) to facilitate downstream tasks better. As the first work to incorporate downstream task evaluation in the literature, we build novel benchmarks to assess the real-world applicability of hand motion forecasting algorithms. The experimental results on multiple publicly available datasets and our newly proposed benchmarks demonstrate that Uni-Hand achieves the state-of-the-art performance in multi-dimensional and multi-target hand motion forecasting. Extensive validation in multiple downstream tasks also presents its impressive human-robot policy transfer to enable robotic manipulation, and effective feature enhancement for action anticipation/recognition.

27 May 2025
 University College LondonUniversity of Edinburgh
University College LondonUniversity of Edinburgh University of British ColumbiaUniversity of Bamberg
University of British ColumbiaUniversity of Bamberg KU LeuvenKansas State UniversityVector InstituteMeta Reality LabsFondazione Bruno KesslerTechnical University of DarmstadtLudwig-Maximilians-Universität MünchenTU Wien
KU LeuvenKansas State UniversityVector InstituteMeta Reality LabsFondazione Bruno KesslerTechnical University of DarmstadtLudwig-Maximilians-Universität MünchenTU Wien University of GroningenPaderborn UniversityUniversity of BielefeldVrije Universiteit AmsterdamUniversity of St. GallenNEC Laboratories EuropeMiniml.AIDuolingoTechnical University FreibergUniversity of Applied Sciences MittweidaSs. Cyril and Methodius University of SkopjeCarnegie Bosch InstituteUniversit
degli Studi di Milano-BicoccaUniversit
Di Bologna
University of GroningenPaderborn UniversityUniversity of BielefeldVrije Universiteit AmsterdamUniversity of St. GallenNEC Laboratories EuropeMiniml.AIDuolingoTechnical University FreibergUniversity of Applied Sciences MittweidaSs. Cyril and Methodius University of SkopjeCarnegie Bosch InstituteUniversit
degli Studi di Milano-BicoccaUniversit
Di BolognaRecent advances in AI -- including generative approaches -- have resulted in
technology that can support humans in scientific discovery and forming
decisions, but may also disrupt democracies and target individuals. The
responsible use of AI and its participation in human-AI teams increasingly
shows the need for AI alignment, that is, to make AI systems act according to
our preferences. A crucial yet often overlooked aspect of these interactions is
the different ways in which humans and machines generalise. In cognitive
science, human generalisation commonly involves abstraction and concept
learning. In contrast, AI generalisation encompasses out-of-domain
generalisation in machine learning, rule-based reasoning in symbolic AI, and
abstraction in neurosymbolic AI. In this perspective paper, we combine insights
from AI and cognitive science to identify key commonalities and differences
across three dimensions: notions of, methods for, and evaluation of
generalisation. We map the different conceptualisations of generalisation in AI
and cognitive science along these three dimensions and consider their role for
alignment in human-AI teaming. This results in interdisciplinary challenges
across AI and cognitive science that must be tackled to provide a foundation
for effective and cognitively supported alignment in human-AI teaming
scenarios.

20 Mar 2025
Meta Reality Labs researchers present a two-stage framework for generating navigable 3D worlds from single images through panorama synthesis and point cloud-conditioned inpainting, enabling high-fidelity scene exploration within a 2-meter range while achieving superior image quality metrics compared to existing methods like WonderJourney and DimensionX.
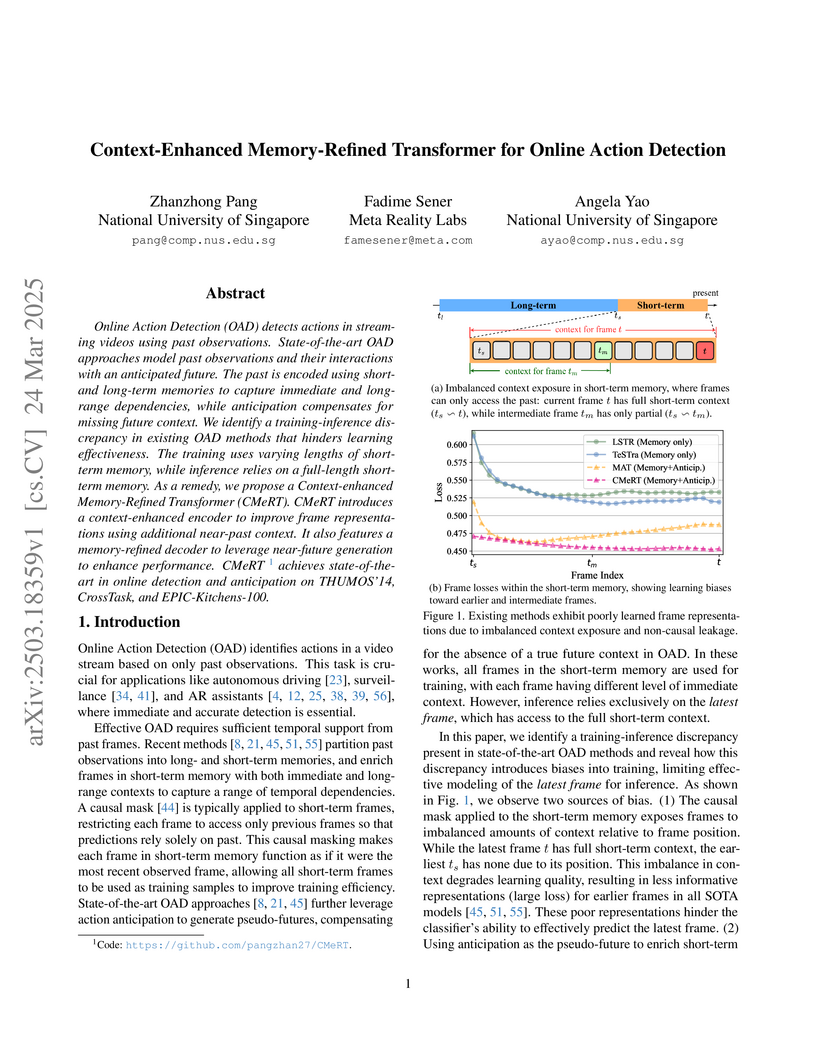
24 Mar 2025
The Context-Enhanced Memory-Refined Transformer (CMeRT), a collaboration between NUS and Meta Reality Labs, improves Transformer-based online action detection (OAD) by addressing issues like training-inference discrepancies and non-causal leakage. This framework achieves state-of-the-art performance, including a 0.6% mAP improvement on THUMOS'14 and a 2% mAP gain on CrossTask, while also enhancing action anticipation and introducing updated OAD evaluation protocols.
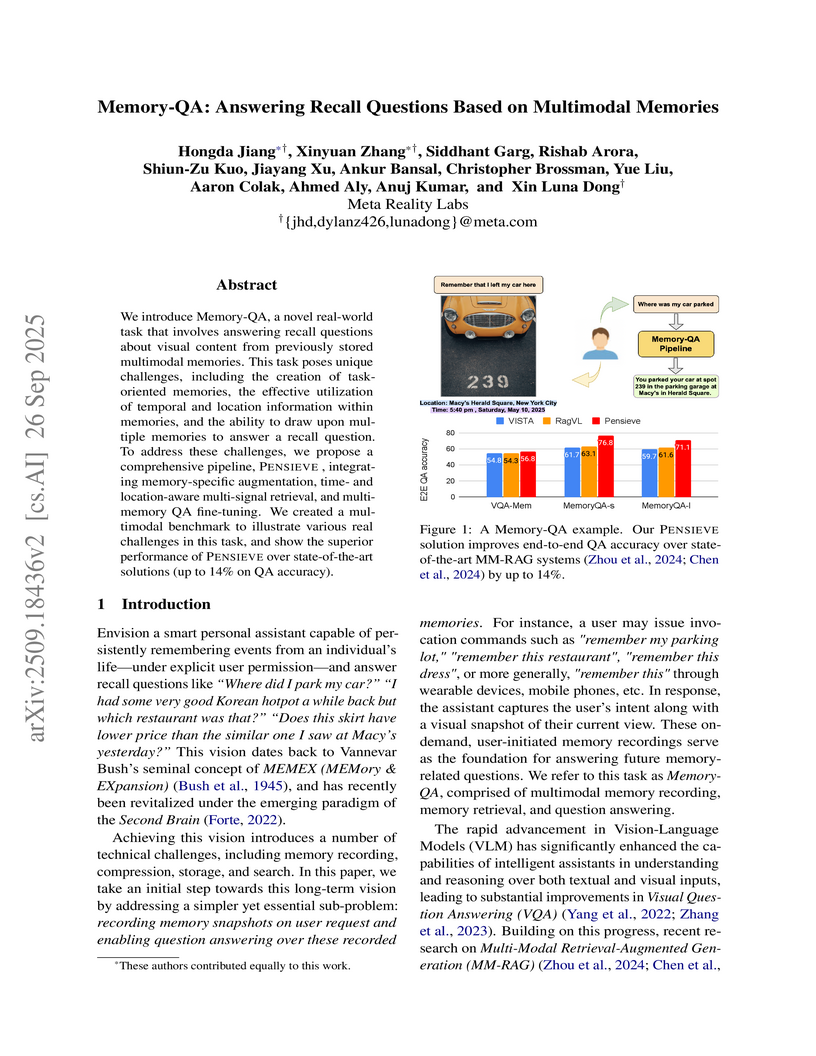
26 Sep 2025
We introduce Memory-QA, a novel real-world task that involves answering recall questions about visual content from previously stored multimodal memories. This task poses unique challenges, including the creation of task-oriented memories, the effective utilization of temporal and location information within memories, and the ability to draw upon multiple memories to answer a recall question. To address these challenges, we propose a comprehensive pipeline, Pensieve, integrating memory-specific augmentation, time- and location-aware multi-signal retrieval, and multi-memory QA fine-tuning. We created a multimodal benchmark to illustrate various real challenges in this task, and show the superior performance of Pensieve over state-of-the-art solutions (up to 14% on QA accuracy).

07 Oct 2025
METAVLA introduces a post-training framework for Vision-Language-Action (VLA) models, utilizing context-aware meta co-training to efficiently adapt models to diverse embodied tasks. It achieves substantial reductions in training resources and improves generalization across various robot manipulation tasks.

11 Nov 2025

AI agents capable of controlling user interfaces have the potential to transform human interaction with digital devices. To accelerate this transformation, two fundamental building blocks are essential: high-quality datasets that enable agents to achieve complex and human-relevant goals, and robust evaluation methods that allow researchers and practitioners to rapidly enhance agent performance. In this paper, we introduce DigiData, a large-scale, high-quality, diverse, multi-modal dataset designed for training mobile control agents. Unlike existing datasets, which derive goals from unstructured interactions, DigiData is meticulously constructed through comprehensive exploration of app features, resulting in greater diversity and higher goal complexity. Additionally, we present DigiData-Bench, a benchmark for evaluating mobile control agents on real-world complex tasks. We demonstrate that the commonly used step-accuracy metric falls short in reliably assessing mobile control agents and, to address this, we propose dynamic evaluation protocols and AI-powered evaluations as rigorous alternatives for agent assessment. Our contributions aim to significantly advance the development of mobile control agents, paving the way for more intuitive and effective human-device interactions.

30 Apr 2025
A new dataset, HOT3D, provides over 833 minutes of egocentric, multi-view, hardware-synchronized videos of hands and objects with high-fidelity 3D ground truth. Experiments show multi-view approaches significantly improve accuracy for 3D hand pose tracking and 6DoF object pose estimation compared to single-view methods.

17 Sep 2025

This paper introduces a multi-stage self-directed framework designed to address the spatial semantic segmentation of sound scene (S5) task in the DCASE 2025 Task 4 challenge. This framework integrates models focused on three distinct tasks: Universal Sound Separation (USS), Single-label Classification (SC), and Target Sound Extraction (TSE). Initially, USS breaks down a complex audio mixture into separate source waveforms. Each of these separated waveforms is then processed by a SC block, generating two critical pieces of information: the waveform itself and its corresponding class label. These serve as inputs for the TSE stage, which isolates the source that matches this information. Since these inputs are produced within the system, the extraction target is identified autonomously, removing the necessity for external guidance. The extracted waveform can be looped back into the classification task, creating a cycle of iterative refinement that progressively enhances both separability and labeling accuracy. We thus call our framework a multi-stage self-guided system due to these self-contained characteristics. On the official evaluation dataset, the proposed system achieves an 11.00 dB increase in class-aware signal-to-distortion ratio improvement (CA-SDRi) and a 55.8\% accuracy in label prediction, outperforming the ResUNetK baseline by 4.4 dB and 4.3\%, respectively, and achieving first place among all submissions.

25 Oct 2025
The paper introduces WAGIBench, a benchmark and dataset for evaluating implicit goal inference in assistive wearable agents from egocentric multimodal observations. It enables assessment of vision-language models across vision, audio, digital context, and longitudinal history, revealing a substantial performance gap between state-of-the-art models and human capabilities.
There are no more papers matching your filters at the moment.
