18 Oct 2025

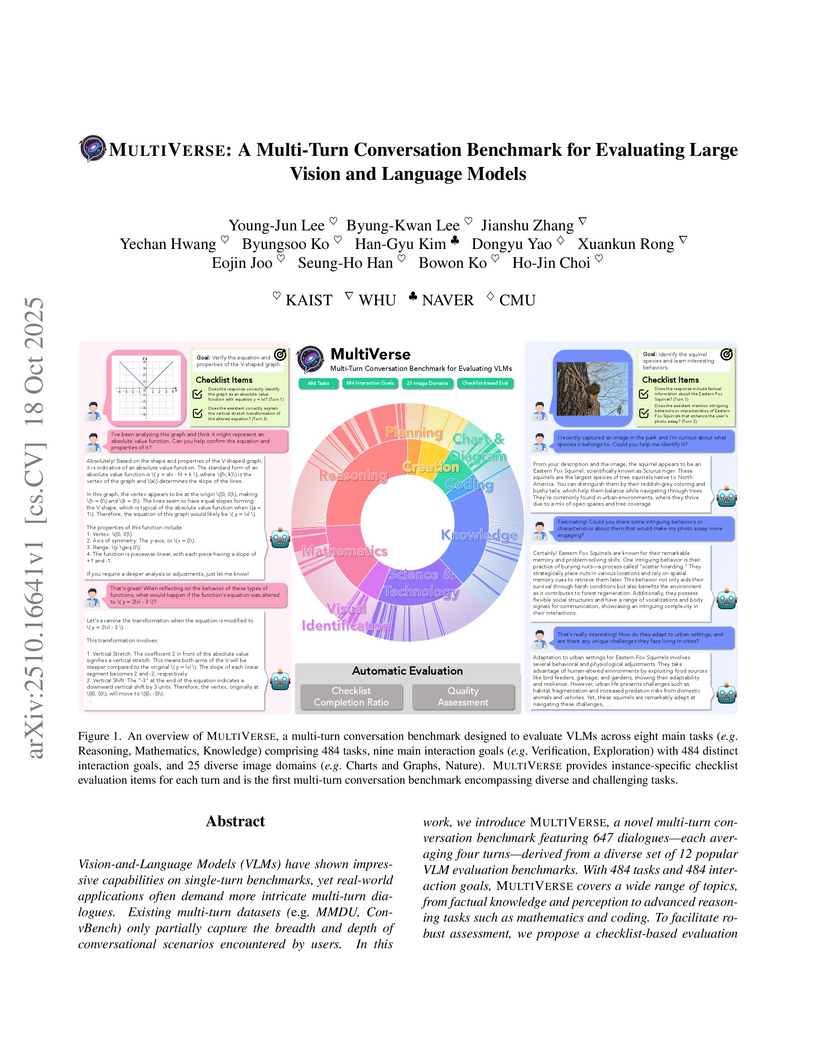
Researchers from KAIST, Wuhan University, NAVER, and Carnegie Mellon University developed MULTIVERSE, a multi-turn conversation benchmark that rigorously evaluates Large Vision and Language Models (VLMs) across diverse, complex tasks. The benchmark reveals that even state-of-the-art VLMs, including GPT-4o, achieve less than a 50% success rate in sustained dialogues, indicating a significant gap in their multi-turn interactive capabilities.

24 Jun 2024
EGTR introduces a lightweight and efficient one-stage Scene Graph Generation model that extracts relational information directly from the self-attention mechanisms of a Transformer object detector. The approach achieves a 4x faster inference speed and uses significantly fewer parameters while maintaining competitive triplet detection performance and achieving the highest object detection AP50 on the Visual Genome dataset.

30 May 2024

Kwon et al. from Naver developed an AI safety approach using small language models (SLMs) as "guardians" that detect harmful queries and generate explanatory safeguard responses for users. This method demonstrated superior performance over larger LLMs and commercial APIs for Korean language content while offering a cost-effective and modular solution.

16 Apr 2024



Researchers from KAIST, University of Michigan, Carnegie Mellon University, and NAVER introduced HOMER, a training-free method that extends pre-trained Large Language Models (LLMs) to handle context lengths up to 64,000 tokens and beyond. This approach significantly reduces peak GPU memory usage by at least 73.4% and accelerates inference speed, while demonstrating high accuracy on long-context tasks like passkey retrieval and question answering.

21 Nov 2022

Contrastive learning is a form of distance learning that aims to learn
invariant features from two related representations. In this paper, we explore
the bold hypothesis that an image and its caption can be simply regarded as two
different views of the underlying mutual information, and train a model to
learn a unified vision-language representation space that encodes both
modalities at once in a modality-agnostic manner. We first identify
difficulties in learning a generic one-tower model for vision-language
pretraining (VLP), and propose OneR as a simple yet effective framework for our
goal. We discover intriguing properties that distinguish OneR from the previous
works that learn modality-specific representation spaces such as zero-shot
object localization, text-guided visual reasoning and multi-modal retrieval,
and present analyses to provide insights into this new form of multi-modal
representation learning. Thorough evaluations demonstrate the potential of a
unified modality-agnostic VLP framework.

27 Oct 2023
Preference-based reinforcement learning (PbRL) is an approach that enables RL agents to learn from preference, which is particularly useful when formulating a reward function is challenging. Existing PbRL methods generally involve a two-step procedure: they first learn a reward model based on given preference data and then employ off-the-shelf reinforcement learning algorithms using the learned reward model. However, obtaining an accurate reward model solely from preference information, especially when the preference is from human teachers, can be difficult. Instead, we propose a PbRL algorithm that directly learns from preference without requiring any reward modeling. To achieve this, we adopt a contrastive learning framework to design a novel policy scoring metric that assigns a high score to policies that align with the given preferences. We apply our algorithm to offline RL tasks with actual human preference labels and show that our algorithm outperforms or is on par with the existing PbRL methods. Notably, on high-dimensional control tasks, our algorithm surpasses offline RL methods that learn with ground-truth reward information. Finally, we show that our algorithm can be successfully applied to fine-tune large language models.

21 Jan 2024
This paper introduces a novel approach for topic modeling utilizing latent codebooks from Vector-Quantized Variational Auto-Encoder~(VQ-VAE), discretely encapsulating the rich information of the pre-trained embeddings such as the pre-trained language model. From the novel interpretation of the latent codebooks and embeddings as conceptual bag-of-words, we propose a new generative topic model called Topic-VQ-VAE~(TVQ-VAE) which inversely generates the original documents related to the respective latent codebook. The TVQ-VAE can visualize the topics with various generative distributions including the traditional BoW distribution and the autoregressive image generation. Our experimental results on document analysis and image generation demonstrate that TVQ-VAE effectively captures the topic context which reveals the underlying structures of the dataset and supports flexible forms of document generation. Official implementation of the proposed TVQ-VAE is available at this https URL.

02 Jul 2025

As large language models (LLMs) are increasingly used across various applications, there is a growing need to control text generation to satisfy specific constraints or requirements. This raises a crucial question: Is it possible to guarantee strict constraint satisfaction in generated outputs while preserving the distribution of the original model as much as possible? We first define the ideal distribution - the one closest to the original model, which also always satisfies the expressed constraint - as the ultimate goal of guaranteed generation. We then state a fundamental limitation, namely that it is impossible to reach that goal through autoregressive training alone. This motivates the necessity of combining training-time and inference-time methods to enforce such guarantees. Based on this insight, we propose GUARD, a simple yet effective approach that combines an autoregressive proposal distribution with rejection sampling. Through GUARD's theoretical properties, we show how controlling the KL divergence between a specific proposal and the target ideal distribution simultaneously optimizes inference speed and distributional closeness. To validate these theoretical concepts, we conduct extensive experiments on two text generation settings with hard-to-satisfy constraints: a lexical constraint scenario and a sentiment reversal scenario. These experiments show that GUARD achieves perfect constraint satisfaction while almost preserving the ideal distribution with highly improved inference efficiency. GUARD provides a principled approach to enforcing strict guarantees for LLMs without compromising their generative capabilities.
26 Apr 2022
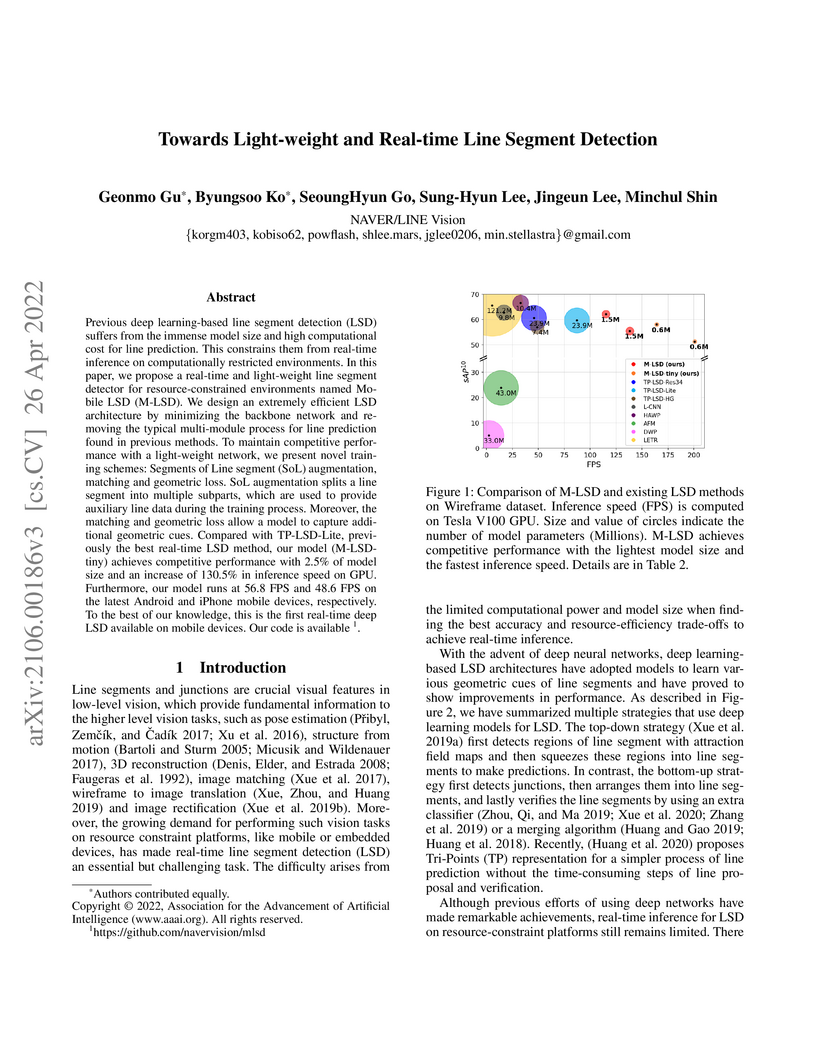
Previous deep learning-based line segment detection (LSD) suffers from the immense model size and high computational cost for line prediction. This constrains them from real-time inference on computationally restricted environments. In this paper, we propose a real-time and light-weight line segment detector for resource-constrained environments named Mobile LSD (M-LSD). We design an extremely efficient LSD architecture by minimizing the backbone network and removing the typical multi-module process for line prediction found in previous methods. To maintain competitive performance with a light-weight network, we present novel training schemes: Segments of Line segment (SoL) augmentation, matching and geometric loss. SoL augmentation splits a line segment into multiple subparts, which are used to provide auxiliary line data during the training process. Moreover, the matching and geometric loss allow a model to capture additional geometric cues. Compared with TP-LSD-Lite, previously the best real-time LSD method, our model (M-LSD-tiny) achieves competitive performance with 2.5% of model size and an increase of 130.5% in inference speed on GPU. Furthermore, our model runs at 56.8 FPS and 48.6 FPS on the latest Android and iPhone mobile devices, respectively. To the best of our knowledge, this is the first real-time deep LSD available on mobile devices. Our code is available.

07 Jun 2025
The advancements in large language models (LLMs) have brought significant progress in NLP tasks. However, if a task cannot be fully described in prompts, the models could fail to carry out the task. In this paper, we propose a simple yet effective method to contextualize a task toward a LLM. The method utilizes (1) open-ended zero-shot inference from the entire dataset, (2) aggregate the inference results, and (3) finally incorporate the aggregated meta-information for the actual task. We show the effectiveness in text clustering tasks, empowering LLMs to perform text-to-text-based clustering and leading to improvements on several datasets. Furthermore, we explore the generated class labels for clustering, showing how the LLM understands the task through data.

23 May 2023
Recent advances in diffusion models have showcased promising results in the text-to-video (T2V) synthesis task. However, as these T2V models solely employ text as the guidance, they tend to struggle in modeling detailed temporal dynamics. In this paper, we introduce a novel T2V framework that additionally employ audio signals to control the temporal dynamics, empowering an off-the-shelf T2I diffusion to generate audio-aligned videos. We propose audio-based regional editing and signal smoothing to strike a good balance between the two contradicting desiderata of video synthesis, i.e., temporal flexibility and coherence. We empirically demonstrate the effectiveness of our method through experiments, and further present practical applications for contents creation.

12 Aug 2024
This paper presents Adaptive Score Estimation (ASE), a framework that accelerates diffusion model sampling by adaptively skipping parts of the neural network during inference. ASE reduces computational cost per step by leveraging a time-varying block-dropping schedule, achieving over 30% acceleration with minimal quality degradation on various image synthesis tasks.

02 Jul 2025





As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.

17 Jun 2025
Quantization has been widely studied as an effective technique for reducing the memory requirement of large language models (LLMs), potentially improving the latency time as well. Utilizing the characteristic of rotational invariance of transformer, we propose the rotation-based saliency-aware weight quantization (ROSAQ), which identifies salient channels in the projection feature space, not in the original feature space, where the projected "principal" dimensions are naturally considered as "salient" features. The proposed ROSAQ consists of 1) PCA-based projection, which first performs principal component analysis (PCA) on a calibration set and transforms via the PCA projection, 2) Salient channel dentification, which selects dimensions corresponding to the K-largest eigenvalues as salient channels, and 3) Saliency-aware quantization with mixed-precision, which uses FP16 for salient dimensions and INT3/4 for other dimensions. Experiment results show that ROSAQ shows improvements over the baseline saliency-aware quantization on the original feature space and other existing quantization methods. With kernel fusion, ROSAQ presents about 2.3x speed up over FP16 implementation in generating 256 tokens with a batch size of 64.

20 Sep 2025
Researchers at Naver systematically investigated the role of vocabulary in Learned Sparse Retrieval (LSR) models, demonstrating that larger, effectively pre-trained vocabularies, combined with static term pruning, enable high retrieval effectiveness at significantly reduced computational costs, sometimes even below traditional lexical methods.

13 Jul 2020
This paper is dedicated to team VAA's approach submitted to the Fashion-IQ
challenge in CVPR 2020. Given a pair of the image and the text, we present a
novel multimodal composition method, RTIC, that can effectively combine the
text and the image modalities into a semantic space. We extract the image and
the text features that are encoded by the CNNs and the sequential models (e.g.,
LSTM or GRU), respectively. To emphasize the meaning of the residual of the
feature between the target and candidate, the RTIC is composed of N-blocks with
channel-wise attention modules. Then, we add the encoded residual to the
feature of the candidate image to obtain a synthesized feature. We also
explored an ensemble strategy with variants of models and achieved a
significant boost in performance comparing to the best single model. Finally,
our approach achieved 2nd place in the Fashion-IQ 2020 Challenge with a test
score of 48.02 on the leaderboard.

15 Oct 2021
The semantic matching capabilities of neural information retrieval can
ameliorate synonymy and polysemy problems of symbolic approaches. However,
neural models' dense representations are more suitable for re-ranking, due to
their inefficiency. Sparse representations, either in symbolic or latent form,
are more efficient with an inverted index. Taking the merits of the sparse and
dense representations, we propose an ultra-high dimensional (UHD)
representation scheme equipped with directly controllable sparsity. UHD's large
capacity and minimal noise and interference among the dimensions allow for
binarized representations, which are highly efficient for storage and search.
Also proposed is a bucketing method, where the embeddings from multiple layers
of BERT are selected/merged to represent diverse linguistic aspects. We test
our models with MS MARCO and TREC CAR, showing that our models outperforms
other sparse models

15 Apr 2022
This paper is a technical report to share our experience and findings
building a Korean and English bilingual multimodal model. While many of the
multimodal datasets focus on English and multilingual multimodal research uses
machine-translated texts, employing such machine-translated texts is limited to
describing unique expressions, cultural information, and proper noun in
languages other than English. In this work, we collect 1.1 billion image-text
pairs (708 million Korean and 476 million English) and train a bilingual
multimodal model named KELIP. We introduce simple yet effective training
schemes, including MAE pre-training and multi-crop augmentation. Extensive
experiments demonstrate that a model trained with such training schemes shows
competitive performance in both languages. Moreover, we discuss
multimodal-related research questions: 1) strong augmentation-based methods can
distract the model from learning proper multimodal relations; 2) training
multimodal model without cross-lingual relation can learn the relation via
visual semantics; 3) our bilingual KELIP can capture cultural differences of
visual semantics for the same meaning of words; 4) a large-scale multimodal
model can be used for multimodal feature analogy. We hope that this work will
provide helpful experience and findings for future research. We provide an
open-source pre-trained KELIP.

08 May 2024
With the advancement of Large-Language Models (LLMs) and Large Vision-Language Models (LVMs), agents have shown significant capabilities in various tasks, such as data analysis, gaming, or code generation. Recently, there has been a surge in research on web agents, capable of performing tasks within the web environment. However, the web poses unforeseeable scenarios, challenging the generalizability of these agents. This study investigates the disparities between human and web agents' performance in web tasks (e.g., information search) by concentrating on planning, action, and reflection aspects during task execution. We conducted a web task study with a think-aloud protocol, revealing distinct cognitive actions and operations on websites employed by humans. Comparative examination of existing agent structures and human behavior with thought processes highlighted differences in knowledge updating and ambiguity handling when performing the task. Humans demonstrated a propensity for exploring and modifying plans based on additional information and investigating reasons for failure. These findings offer insights into designing planning, reflection, and information discovery modules for web agents and designing the capturing method for implicit human knowledge in a web task.

12 May 2021
To tackle ever-increasing city traffic congestion problems, researchers have proposed deep learning models to aid decision-makers in the traffic control domain. Although the proposed models have been remarkably improved in recent years, there are still questions that need to be answered before deploying models. For example, it is difficult to figure out which models provide state-of-the-art performance, as recently proposed models have often been evaluated with different datasets and experiment environments. It is also difficult to determine which models would work when traffic conditions change abruptly (e.g., rush hour). In this work, we conduct two experiments to answer the two questions. In the first experiment, we conduct an experiment with the state-of-the-art models and the identical public datasets to compare model performance under a consistent experiment environment. We then extract a set of temporal regions in the datasets, whose speeds change abruptly and use these regions to explore model performance with difficult intervals. The experiment results indicate that Graph-WaveNet and GMAN show better performance in general. We also find that prediction models tend to have varying performances with data and intervals, which calls for in-depth analysis of models on difficult intervals for real-world deployment.
There are no more papers matching your filters at the moment.
