
20 Apr 2025

A comprehensive survey examines the integration of Multi-Agent Reinforcement Learning (MARL) with Large Language Models to develop meta-thinking capabilities, synthesizing approaches across reward mechanisms, self-play architectures, and meta-learning strategies while highlighting key challenges in scalability and stability for building more introspective AI systems.

20 Oct 2025
This review surveys video-based learning methods for robot manipulation, classifying approaches across foundational perception, reinforcement learning, imitation learning, hybrid, and multi-modal strategies. It identifies key challenges like domain shift and the need for causal reasoning, and outlines future research directions, including enhanced evaluation benchmarks.

26 Aug 2025

For Large Language Models (LLMs), a disconnect persists between benchmark performance and real-world utility. Current evaluation frameworks remain fragmented, prioritizing technical metrics while neglecting holistic assessment for deployment. This survey introduces an anthropomorphic evaluation paradigm through the lens of human intelligence, proposing a novel three-dimensional taxonomy: Intelligence Quotient (IQ)-General Intelligence for foundational capacity, Emotional Quotient (EQ)-Alignment Ability for value-based interactions, and Professional Quotient (PQ)-Professional Expertise for specialized proficiency. For practical value, we pioneer a Value-oriented Evaluation (VQ) framework assessing economic viability, social impact, ethical alignment, and environmental sustainability. Our modular architecture integrates six components with an implementation roadmap. Through analysis of 200+ benchmarks, we identify key challenges including dynamic assessment needs and interpretability gaps. It provides actionable guidance for developing LLMs that are technically proficient, contextually relevant, and ethically sound. We maintain a curated repository of open-source evaluation resources at: this https URL.

08 Oct 2025
 CNRS
CNRS University of Pittsburgh
University of Pittsburgh University of Chicago
University of Chicago University of Oxford
University of Oxford INFN
INFN Yale University
Yale University Northwestern UniversityCONICET
Northwestern UniversityCONICET CERN
CERN Argonne National Laboratory
Argonne National Laboratory University of Wisconsin-Madison
University of Wisconsin-Madison Purdue University
Purdue University University of ArizonaUniversity of RochesterDeutsches Elektronen-Synchrotron DESY
University of ArizonaUniversity of RochesterDeutsches Elektronen-Synchrotron DESY CEAUniversity of GlasgowUniversidad Complutense de MadridUniversity of SussexUniversidad Nacional de La PlataUniversity of TartuUniversity Paris-SaclayJagiellonian UniversityUniversity of TriesteOklahoma State UniversityUniversity of GdańskGdańsk University of TechnologyUniversity of Hawai’iGeorg-August Universität GöttingenUniversity of DortmundIFT UAM/CSICUniversity of ŁódźKBFIUniversit
catholique de LouvainUniversit
Grenoble AlpesSapienza Universit
di RomaUniversit
degli Studi di Milano-BicoccaUniversit
Di Bologna
CEAUniversity of GlasgowUniversidad Complutense de MadridUniversity of SussexUniversidad Nacional de La PlataUniversity of TartuUniversity Paris-SaclayJagiellonian UniversityUniversity of TriesteOklahoma State UniversityUniversity of GdańskGdańsk University of TechnologyUniversity of Hawai’iGeorg-August Universität GöttingenUniversity of DortmundIFT UAM/CSICUniversity of ŁódźKBFIUniversit
catholique de LouvainUniversit
Grenoble AlpesSapienza Universit
di RomaUniversit
degli Studi di Milano-BicoccaUniversit
Di BolognaSome of the most astonishing and prominent properties of Quantum Mechanics, such as entanglement and Bell nonlocality, have only been studied extensively in dedicated low-energy laboratory setups. The feasibility of these studies in the high-energy regime explored by particle colliders was only recently shown and has gathered the attention of the scientific community. For the range of particles and fundamental interactions involved, particle colliders provide a novel environment where quantum information theory can be probed, with energies exceeding by about 12 orders of magnitude those employed in dedicated laboratory setups. Furthermore, collider detectors have inherent advantages in performing certain quantum information measurements, and allow for the reconstruction of the state of the system under consideration via quantum state tomography. Here, we elaborate on the potential, challenges, and goals of this innovative and rapidly evolving line of research and discuss its expected impact on both quantum information theory and high-energy physics.

08 May 2025
Super-resolution (SR) techniques aim to enhance data resolution, enabling the
retrieval of finer details, and improving the overall quality and fidelity of
the data representation. There is growing interest in applying SR methods to
complex spatiotemporal systems within the Scientific Machine Learning (SciML)
community, with the hope of accelerating numerical simulations and/or improving
forecasts in weather, climate, and related areas. However, the lack of
standardized benchmark datasets for comparing and validating SR methods hinders
progress and adoption in SciML. To address this, we introduce SuperBench, the
first benchmark dataset featuring high-resolution datasets, including data from
fluid flows, cosmology, and weather. Here, we focus on validating spatial SR
performance from data-centric and physics-preserved perspectives, as well as
assessing robustness to data degradation tasks. While deep learning-based SR
methods (developed in the computer vision community) excel on certain tasks,
despite relatively limited prior physics information, we identify limitations
of these methods in accurately capturing intricate fine-scale features and
preserving fundamental physical properties and constraints in scientific data.
These shortcomings highlight the importance and subtlety of incorporating
domain knowledge into ML models. We anticipate that SuperBench will help to
advance SR methods for science.

17 Oct 2025
Multimodal learning aims to leverage information from diverse data modalities to achieve more comprehensive performance. However, conventional multimodal models often suffer from modality imbalance, where one or a few modalities dominate model optimization, leading to suboptimal feature representation and underutilization of weak modalities. To address this challenge, we introduce Gradient-Guided Distillation (GD), a knowledge distillation framework that optimizes the multimodal model with a custom-built loss function that fuses both unimodal and multimodal objectives. GD further incorporates a dynamic sequential modality prioritization (SMP) technique in the learning process to ensure each modality leads the learning process, avoiding the pitfall of stronger modalities overshadowing weaker ones. We validate GD on multiple real-world datasets and show that GD amplifies the significance of weak modalities while training and outperforms state-of-the-art methods in classification and regression tasks. Our code is available at this https URL.

23 Apr 2025
Accurate interpretation of lab results is crucial in clinical medicine, yet most patient portals use universal normal ranges, ignoring conditional factors like age and gender. This study introduces Lab-AI, an interactive system that offers personalized normal ranges using retrieval-augmented generation (RAG) from credible health sources. Lab-AI has two modules: factor retrieval and normal range retrieval. We tested these on 122 lab tests: 40 with conditional factors and 82 without. For tests with factors, normal ranges depend on patient-specific information. Our results show GPT-4-turbo with RAG achieved a 0.948 F1 score for factor retrieval and 0.995 accuracy for normal range retrieval. GPT-4-turbo with RAG outperformed the best non-RAG system by 33.5% in factor retrieval and showed 132% and 100% improvements in question-level and lab-level performance, respectively, for normal range retrieval. These findings highlight Lab-AI's potential to enhance patient understanding of lab results.
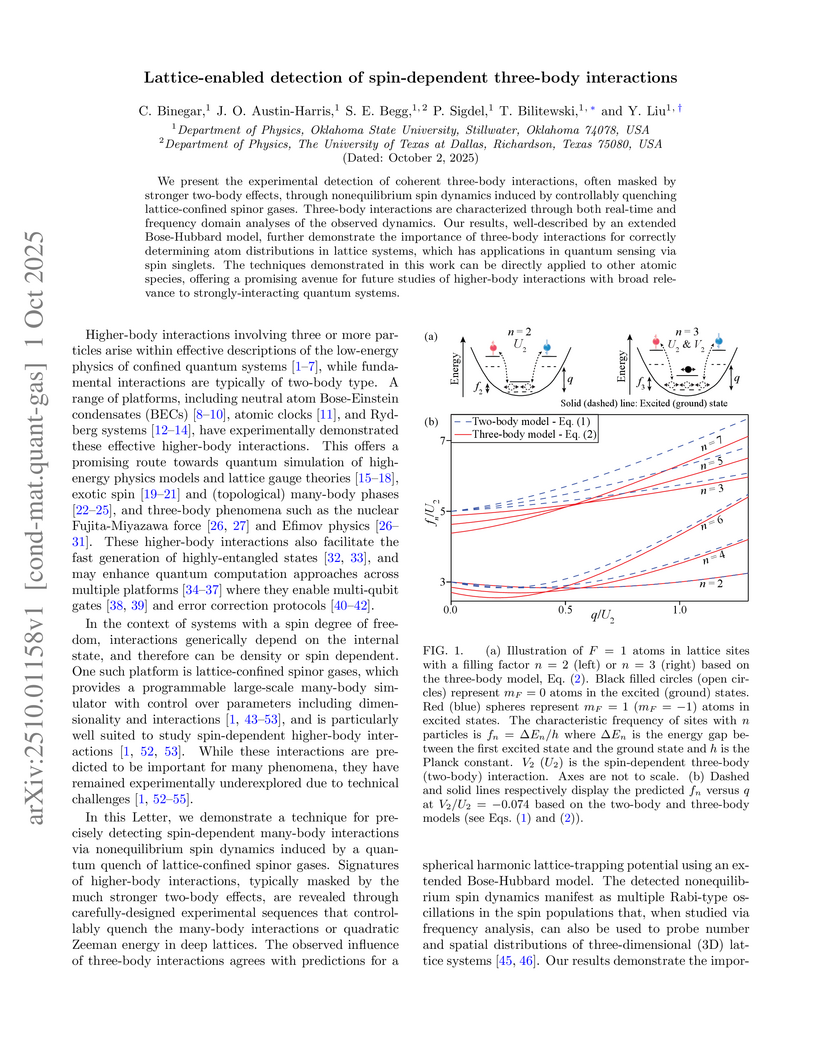
01 Oct 2025
We present the experimental detection of coherent three-body interactions, often masked by stronger two-body effects, through nonequilibrium spin dynamics induced by controllably quenching lattice-confined spinor gases. Three-body interactions are characterized through both real-time and frequency domain analyses of the observed dynamics. Our results, well-described by an extended Bose-Hubbard model, further demonstrate the importance of three-body interactions for correctly determining atom distributions in lattice systems, which has applications in quantum sensing via spin singlets. The techniques demonstrated in this work can be directly applied to other atomic species, offering a promising avenue for future studies of higher-body interactions with broad relevance to strongly-interacting quantum systems.

11 Oct 2025
Online sensing plays an important role in advancing modern manufacturing. The real-time sensor signals, which can be stored as high-resolution time series data, contain rich information about the operation status. One of its popular usages is online process monitoring, which can be achieved by effective anomaly detection from the sensor signals. However, most existing approaches either heavily rely on labeled data for training supervised models, or are designed to detect only extreme outliers, thus are ineffective at identifying subtle semantic off-track anomalies to capture where new regimes or unexpected routines start. To address this challenge, we propose an matrix profile-based unsupervised anomaly detection algorithm that captures fabrication cycle similarity and performs semantic segmentation to precisely identify the onset of defect anomalies in additive manufacturing. The effectiveness of the proposed method is demonstrated by the experiments on real-world sensor data.

18 Apr 2023

Drug-Drug Interactions (DDIs) may hamper the functionalities of drugs, and in the worst scenario, they may lead to adverse drug reactions (ADRs). Predicting all DDIs is a challenging and critical problem. Most existing computational models integrate drug-centric information from different sources and leverage them as features in machine learning classifiers to predict DDIs. However, these models have a high chance of failure, especially for the new drugs when all the information is not available. This paper proposes a novel Hypergraph Neural Network (HyGNN) model based on only the SMILES string of drugs, available for any drug, for the DDI prediction problem. To capture the drug similarities, we create a hypergraph from drugs' chemical substructures extracted from the SMILES strings. Then, we develop HyGNN consisting of a novel attention-based hypergraph edge encoder to get the representation of drugs as hyperedges and a decoder to predict the interactions between drug pairs. Furthermore, we conduct extensive experiments to evaluate our model and compare it with several state-of-the-art methods. Experimental results demonstrate that our proposed HyGNN model effectively predicts DDIs and impressively outperforms the baselines with a maximum ROC-AUC and PR-AUC of 97.9% and 98.1%, respectively.

29 Aug 2025

Recent advances reveal that light propagation in free space supports many exotic topological textures, such as skyrmions. Their unique space-time topologies make them promising candidates as next-generation robust information carriers. Hence, the ability of switching different texture modes is highly demanded to serve as a manner of data transfer. However, previous studies focus on generation of one specific mode, lacking integrated devices with externally variable and stable mode generation capability. Here, we experimentally demonstrate the first realization of switchable skyrmions between electric and magnetic modes in toroidal light pulses using a nonlinear metasurface platform in terms of broadband terahertz generation driven by vectorial pulse. The spatial and temporal evolutions of them are also clearly observed. Our work establishes a new paradigm for manipulating and switching topologically structured light.

23 Aug 2025

Recent advances in synthetic quantum matter allow researchers to design quantum models inaccessible in traditional materials. Here, we propose protocols to engineer a new class of quantum spin models, which we call spin Kitaev models. The building blocks are basic spin-exchange interactions combined with locally selective Floquet pulses, a capability recently demonstrated in a range of experimental platforms. The resulting flip-flip and flop-flop terms lead to intriguing quantum transport dynamics beyond conventional spin models. For instance, in the absence of a magnetic field, spin excitations polarized along the and axes propagate chirally in opposite directions, producing polarization-dependent spin transport. In the large-spin limit, the spin Kitaev model maps to a nonlinear Hatano-Nelson model, where the interplay of nonlinearity and the underlying curvature yields polarization-dependent chiral solitons. A magnetic field binds two oppositely polarized chiral solitons into a chiral solitonic molecule, whose travel direction depends on its orientation. Our results, directly accessible in current experiments, open new opportunities for simulating transport in curved spaces and for applications in spintronics, information processing, and quantum sensing.

18 Apr 2009

We study the electron transport through a graphene nanoribbon-superconductor junction. Both zigzag and armchair edge graphene nanoribbons are considered, and the effects of the magnetic field and disorder on the transport property are investigated. By using the tight-binding model and the non-equilibrium Green's function method, the expressions of the current, conductance, normal tunneling coefficient, and Andreev reflection coefficient are obtained. For a clean system and at zero magnetic field, the linear conductance increases approximatively in a linear fashion with the on-site energy. In the presence of a magnetic field and a moderate disorder, the linear conductance exhibits plateau structures for both armchair and zigzag edges. The plateau values increase with the width of the graphene ribbon. With a wide sample width, a saturated plateau value of emerges at the filling factor . For a small filling factor, the conductance can reach the saturated value at a small width, but for a high filling factor, it requires to have a quite wide sample width to reach the saturated value. In particular, the Andreev reflection coefficient is always at 0.5 after reaching the saturated value, independent of any system parameters. In addition, we also consider the finite bias case, in which the Andreev reflection coefficient and normal tunneling coefficient are studied.

02 Jan 2025
Researchers at Oklahoma State University present a comprehensive review of quantum circuit optimization, categorizing techniques into hardware-independent simplification and hardware-dependent layout optimization. The work synthesizes approaches from pattern matching and unitary synthesis to AI-based methods, highlighting their necessity for mitigating noise and improving fidelity on current noisy quantum hardware.

25 Sep 2025
The exponential growth of computational workloads is surpassing the capabilities of conventional architectures, which are constrained by fundamental limits. In-memory computing (IMC) with RRAM provides a promising alternative by providing analog computations with significant gains in latency and energy use. However, existing algorithms developed for conventional architectures do not translate to IMC, particularly for constrained optimization problems where frequent matrix reprogramming remains cost-prohibitive for IMC applications. Here we present a distributed in-memory primal-dual hybrid gradient (PDHG) method, specifically co-designed for arrays of RRAM devices. Our approach minimizes costly write cycles, incorporates robustness against device non-idealities, and leverages a symmetric block-matrix formulation to unify operations across distributed crossbars. We integrate a physics-based simulation framework called MELISO+ to evaluate performance under realistic device conditions. Benchmarking against GPU-accelerated solvers on large-scale linear programs demonstrates that our RRAM-based solver achieves comparable accuracy with up to three orders of magnitude reductions in energy consumption and latency. These results demonstrate the first PDHG-based LP solver implemented on RRAMs, showcasing the transformative potential of algorithm-hardware co-design for solving large-scale optimization through distributed in-memory computing.

13 Sep 2023

Demographics, Social determinants of health, and family history documented in
the unstructured text within the electronic health records are increasingly
being studied to understand how this information can be utilized with the
structured data to improve healthcare outcomes. After the GPT models were
released, many studies have applied GPT models to extract this information from
the narrative clinical notes. Different from the existing work, our research
focuses on investigating the zero-shot learning on extracting this information
together by providing minimum information to the GPT model. We utilize
de-identified real-world clinical notes annotated for demographics, various
social determinants, and family history information. Given that the GPT model
might provide text different from the text in the original data, we explore two
sets of evaluation metrics, including the traditional NER evaluation metrics
and semantic similarity evaluation metrics, to completely understand the
performance. Our results show that the GPT-3.5 method achieved an average of
0.975 F1 on demographics extraction, 0.615 F1 on social determinants
extraction, and 0.722 F1 on family history extraction. We believe these results
can be further improved through model fine-tuning or few-shots learning.
Through the case studies, we also identified the limitations of the GPT models,
which need to be addressed in future research.

28 Aug 2025

We propose heavy decaying dark matter (DM) as a new probe of the cosmic neutrino background (CB). Heavy DM, with mass GeV, decaying into neutrinos can be a new source of ultra-high-energy (UHE) neutrinos. Including this contribution along with the measured astrophysical and predicted cosmogenic neutrino fluxes, we study the scattering of UHE neutrinos with the CB via standard weak interactions mediated by the -boson. We solve the complete neutrino transport equation, taking into account both absorption and reinjection effects, to calculate the expected spectrum of UHE neutrino flux at future neutrino telescopes, such as IceCube-Gen2 Radio. We argue that such observations can be used to probe the CB properties, and in particular, local CB clustering. We find that, depending on the absolute neutrino mass and the DM mass and lifetime, a local CB overdensity can be probed at IceCube-Gen2 Radio within 10 years of data taking.

05 Mar 2025
The era of big data has made vast amounts of clinical data readily available,
particularly in the form of electronic health records (EHRs), which provides
unprecedented opportunities for developing data-driven diagnostic tools to
enhance clinical decision making. However, the application of EHRs in
data-driven modeling faces challenges such as irregularly spaced multi-variate
time series, issues of incompleteness, and data imbalance. Realizing the full
data potential of EHRs hinges on the development of advanced analytical models.
In this paper, we propose a novel Missingness-aware mUlti-branching
Self-Attention Encoder (MUSE-Net) to cope with the challenges in modeling
longitudinal EHRs for data-driven disease prediction. The proposed MUSE-Net is
composed by four novel modules including: (1) a multi-task Gaussian process
(MGP) with missing value masks for data imputation; (2) a multi-branching
architecture to address the data imbalance problem; (3) a time-aware
self-attention encoder to account for the irregularly spaced time interval in
longitudinal EHRs; (4) interpretable multi-head attention mechanism that
provides insights into the importance of different time points in disease
prediction, allowing clinicians to trace model decisions. We evaluate the
proposed MUSE-Net using both synthetic and real-world datasets. Experimental
results show that our MUSE-Net outperforms existing methods that are widely
used to investigate longitudinal signals.

23 Dec 2024


A comprehensive review systematizes current research on deep learning applications in additive manufacturing, identifying trends in design optimization, process modeling, and real-time monitoring and control. The analysis consolidates fragmented knowledge and highlights opportunities for improving part quality and manufacturing efficiency.

14 Aug 2012
We show that by adding a vector-like 5+5bar pair of matter fields to the spectrum of the minimal renormalizable SUSY SU(5) theory the wrong relations for fermion masses can be corrected, while being predictive and consistent with proton lifetime limits. Threshold correction from the vector-like fields improves unification of gauge couplings compared to the minimal model. It is found that for supersymmetric spectra lighter than 3 TeV, which would be testable at the LHC, at least some of the nucleon decay modes should have partial lifetimes shorter than about 2.10^34 yrs., which is within reach of ongoing and proposed experiments.
There are no more papers matching your filters at the moment.
