
23 Jun 2025

The 'PlanGenLLMs' survey provides a structured overview of Large Language Model planning capabilities, proposing six consistent evaluation criteria: completeness, executability, optimality, representation, generalization, and efficiency, and analyzing current research against these standards. It synthesizes existing findings to highlight the strengths and limitations of current LLM planners and identifies key directions for future research in the field.

30 Mar 2025
This research introduces a systematic framework and refined metrics for evaluating Large Language Models (LLMs) used as judges in alignment tasks, explicitly accounting for internal inconsistencies and demonstrating their high sensitivity to prompt templates. Experiments reveal that even advanced LLM judges achieve accuracies below 0.7 on human preferences and exhibit significant biases.

02 Oct 2025

Diffusion models can synthesize realistic co-speech video from audio for various applications, such as video creation and virtual agents. However, existing diffusion-based methods are slow due to numerous denoising steps and costly attention mechanisms, preventing real-time deployment. In this work, we distill a many-step diffusion video model into a few-step student model. Unfortunately, directly applying recent diffusion distillation methods degrades video quality and falls short of real-time performance. To address these issues, our new video distillation method leverages input human pose conditioning for both attention and loss functions. We first propose using accurate correspondence between input human pose keypoints to guide attention to relevant regions, such as the speaker's face, hands, and upper body. This input-aware sparse attention reduces redundant computations and strengthens temporal correspondences of body parts, improving inference efficiency and motion coherence. To further enhance visual quality, we introduce an input-aware distillation loss that improves lip synchronization and hand motion realism. By integrating our input-aware sparse attention and distillation loss, our method achieves real-time performance with improved visual quality compared to recent audio-driven and input-driven methods. We also conduct extensive experiments showing the effectiveness of our algorithmic design choices.
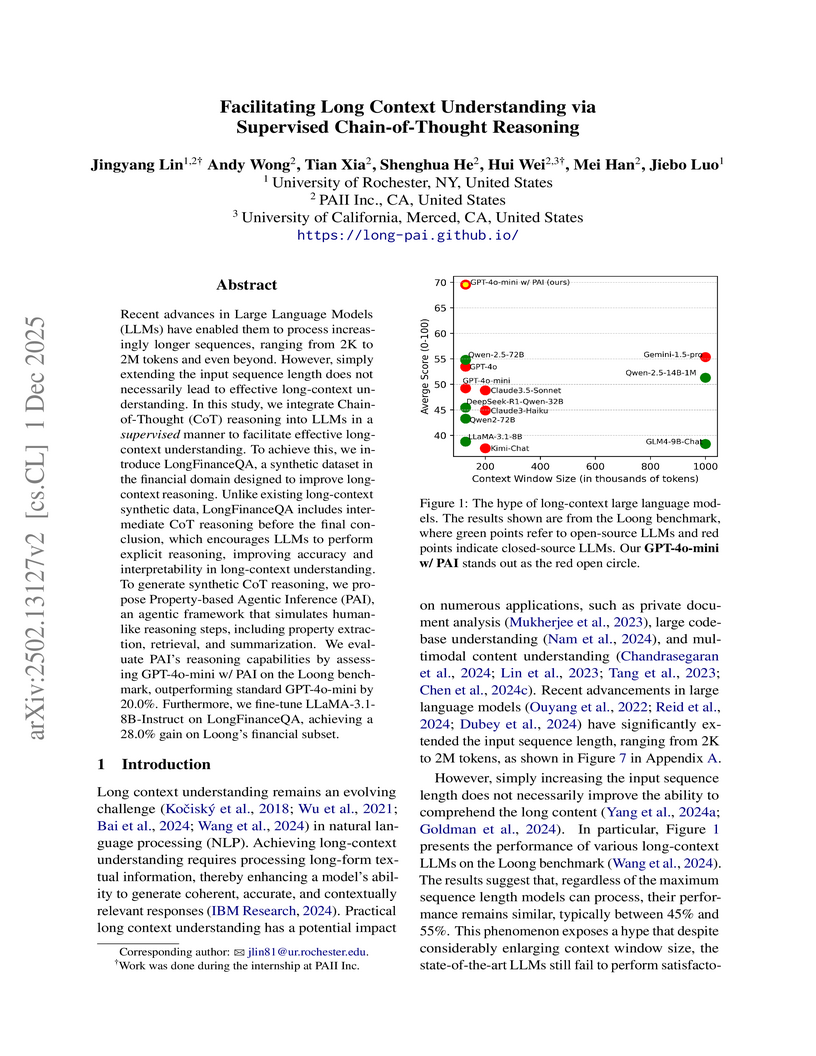
01 Dec 2025
Recent advances in Large Language Models (LLMs) have enabled them to process increasingly longer sequences, ranging from 2K to 2M tokens and even beyond. However, simply extending the input sequence length does not necessarily lead to effective long-context understanding. In this study, we integrate Chain-of-Thought (CoT) reasoning into LLMs in a supervised manner to facilitate effective long-context understanding. To achieve this, we introduce LongFinanceQA, a synthetic dataset in the financial domain designed to improve long-context reasoning. Unlike existing long-context synthetic data, LongFinanceQA includes intermediate CoT reasoning before the final conclusion, which encourages LLMs to perform explicit reasoning, improving accuracy and interpretability in long-context understanding. To generate synthetic CoT reasoning, we propose Property-based Agentic Inference (PAI), an agentic framework that simulates human-like reasoning steps, including property extraction, retrieval, and summarization. We evaluate PAI's reasoning capabilities by assessing GPT-4o-mini w/ PAI on the Loong benchmark, outperforming standard GPT-4o-mini by 20.0%. Furthermore, we fine-tune LLaMA-3.1-8B-Instruct on LongFinanceQA, achieving a 28.0% gain on Loong's financial subset.

01 Apr 2025

Researchers from USTC and PAII Inc. develop DiffDFKD, a data-free knowledge distillation framework that leverages pre-trained diffusion models to generate high-quality synthetic training data, achieving state-of-the-art performance across multiple datasets while enabling effective domain adaptation through teacher-guided synthesis and latent augmentation techniques.

23 Jul 2020

Image landmark detection aims to automatically identify the locations of
predefined fiducial points. Despite recent success in this field,
higher-ordered structural modeling to capture implicit or explicit
relationships among anatomical landmarks has not been adequately exploited. In
this work, we present a new topology-adapting deep graph learning approach for
accurate anatomical facial and medical (e.g., hand, pelvis) landmark detection.
The proposed method constructs graph signals leveraging both local image
features and global shape features. The adaptive graph topology naturally
explores and lands on task-specific structures which are learned end-to-end
with two Graph Convolutional Networks (GCNs). Extensive experiments are
conducted on three public facial image datasets (WFLW, 300W, and COFW-68) as
well as three real-world X-ray medical datasets (Cephalometric (public), Hand
and Pelvis). Quantitative results comparing with the previous state-of-the-art
approaches across all studied datasets indicating the superior performance in
both robustness and accuracy. Qualitative visualizations of the learned graph
topologies demonstrate a physically plausible connectivity laying behind the
landmarks.

03 Jun 2025
Mathematical analysis demonstrates that response-level rewards are sufficient for unbiased policy gradient estimation in large language models, challenging the perceived necessity of token-level rewards. This work provides a theoretical foundation for current practices like the 'Zero-Reward Assumption' and proposes a new algorithm, TRePO.

22 Jun 2024
Dance serves as a powerful medium for expressing human emotions, but the
lifelike generation of dance is still a considerable challenge. Recently,
diffusion models have showcased remarkable generative abilities across various
domains. They hold promise for human motion generation due to their adaptable
many-to-many nature. Nonetheless, current diffusion-based motion generation
models often create entire motion sequences directly and unidirectionally,
lacking focus on the motion with local and bidirectional enhancement. When
choreographing high-quality dance movements, people need to take into account
not only the musical context but also the nearby music-aligned dance motions.
To authentically capture human behavior, we propose a Bidirectional
Autoregressive Diffusion Model (BADM) for music-to-dance generation, where a
bidirectional encoder is built to enforce that the generated dance is
harmonious in both the forward and backward directions. To make the generated
dance motion smoother, a local information decoder is built for local motion
enhancement. The proposed framework is able to generate new motions based on
the input conditions and nearby motions, which foresees individual motion
slices iteratively and consolidates all predictions. To further refine the
synchronicity between the generated dance and the beat, the beat information is
incorporated as an input to generate better music-aligned dance movements.
Experimental results demonstrate that the proposed model achieves
state-of-the-art performance compared to existing unidirectional approaches on
the prominent benchmark for music-to-dance generation.

27 May 2021


In the modern medical care, venipuncture is an indispensable procedure for both diagnosis and treatment. In this paper, unlike existing solutions that fully or partially rely on professional assistance, we propose VeniBot -- a compact robotic system solution integrating both novel hardware and software developments. For the hardware, we design a set of units to facilitate the supporting, positioning, puncturing and imaging functionalities. For the software, to move towards a full automation, we propose a novel deep learning framework -- semi-ResNeXt-Unet for semi-supervised vein segmentation from ultrasound images. From which, the depth information of vein is calculated and used to enable automated navigation for the puncturing unit. VeniBot is validated on 40 volunteers, where ultrasound images can be collected successfully. For the vein segmentation validation, the proposed semi-ResNeXt-Unet improves the dice similarity coefficient (DSC) by 5.36%, decreases the centroid error by 1.38 pixels and decreases the failure rate by 5.60%, compared to fully-supervised ResNeXt-Unet.
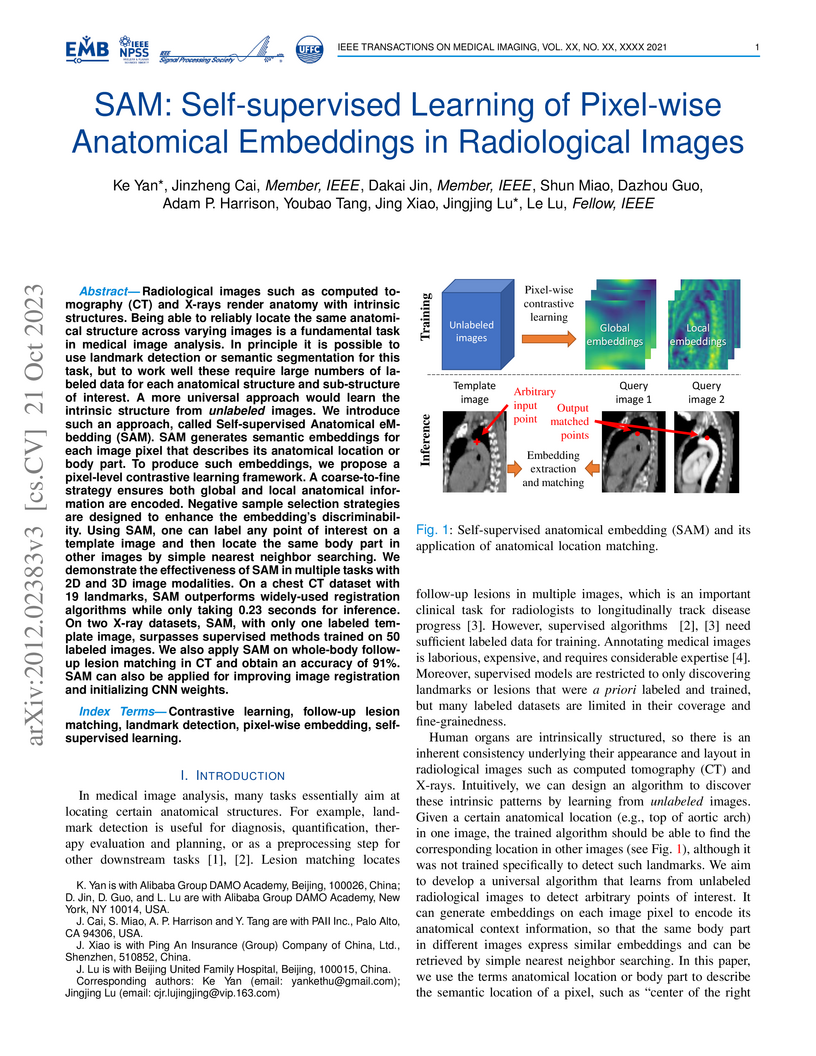
21 Oct 2023
Researchers from Alibaba Group DAMO Academy and PAII Inc. developed SAM, a self-supervised framework that learns robust pixel-wise anatomical embeddings directly from unlabeled radiological images. SAM enables universal anatomical point matching and lesion tracking with high accuracy and efficiency, outperforming existing methods and significantly reducing the need for extensive manual annotations.

04 Jan 2022
3D delineation of anatomical structures is a cardinal goal in medical imaging analysis. Prior to deep learning, statistical shape models that imposed anatomical constraints and produced high quality surfaces were a core technology. Prior to deep learning, statistical shape models that imposed anatomical constraints and produced high quality surfaces were a core technology. Today fully-convolutional networks (FCNs), while dominant, do not offer these capabilities. We present deep implicit statistical shape models (DISSMs), a new approach to delineation that marries the representation power of convolutional neural networks (CNNs) with the robustness of SSMs. DISSMs use a deep implicit surface representation to produce a compact and descriptive shape latent space that permits statistical models of anatomical variance. To reliably fit anatomically plausible shapes to an image, we introduce a novel rigid and non-rigid pose estimation pipeline that is modelled as a Markov decision process(MDP). We outline a training regime that includes inverted episodic training and a deep realization of marginal space learning (MSL). Intra-dataset experiments on the task of pathological liver segmentation demonstrate that DISSMs can perform more robustly than three leading FCN models, including nnU-Net: reducing the mean Hausdorff distance (HD) by 7.7-14.3mm and improving the worst case Dice-Sorensen coefficient (DSC) by 1.2-2.3%. More critically, cross-dataset experiments on a dataset directly reflecting clinical deployment scenarios demonstrate that DISSMs improve the mean DSC and HD by 3.5-5.9% and 12.3-24.5mm, respectively, and the worst-case DSC by 5.4-7.3%. These improvements are over and above any benefits from representing delineations with high-quality surface.

17 Mar 2025

Talking head synthesis, also known as speech-to-lip synthesis, reconstructs
the facial motions that align with the given audio tracks. The synthesized
videos are evaluated on mainly two aspects, lip-speech synchronization and
image fidelity. Recent studies demonstrate that GAN-based and diffusion-based
models achieve state-of-the-art (SOTA) performance on this task, with
diffusion-based models achieving superior image fidelity but experiencing lower
synchronization compared to their GAN-based counterparts. To this end, we
propose SyncDiff, a simple yet effective approach to improve diffusion-based
models using a temporal pose frame with information bottleneck and
facial-informative audio features extracted from AVHuBERT, as conditioning
input into the diffusion process. We evaluate SyncDiff on two canonical talking
head datasets, LRS2 and LRS3 for direct comparison with other SOTA models.
Experiments on LRS2/LRS3 datasets show that SyncDiff achieves a synchronization
score 27.7%/62.3% relatively higher than previous diffusion-based methods,
while preserving their high-fidelity characteristics.
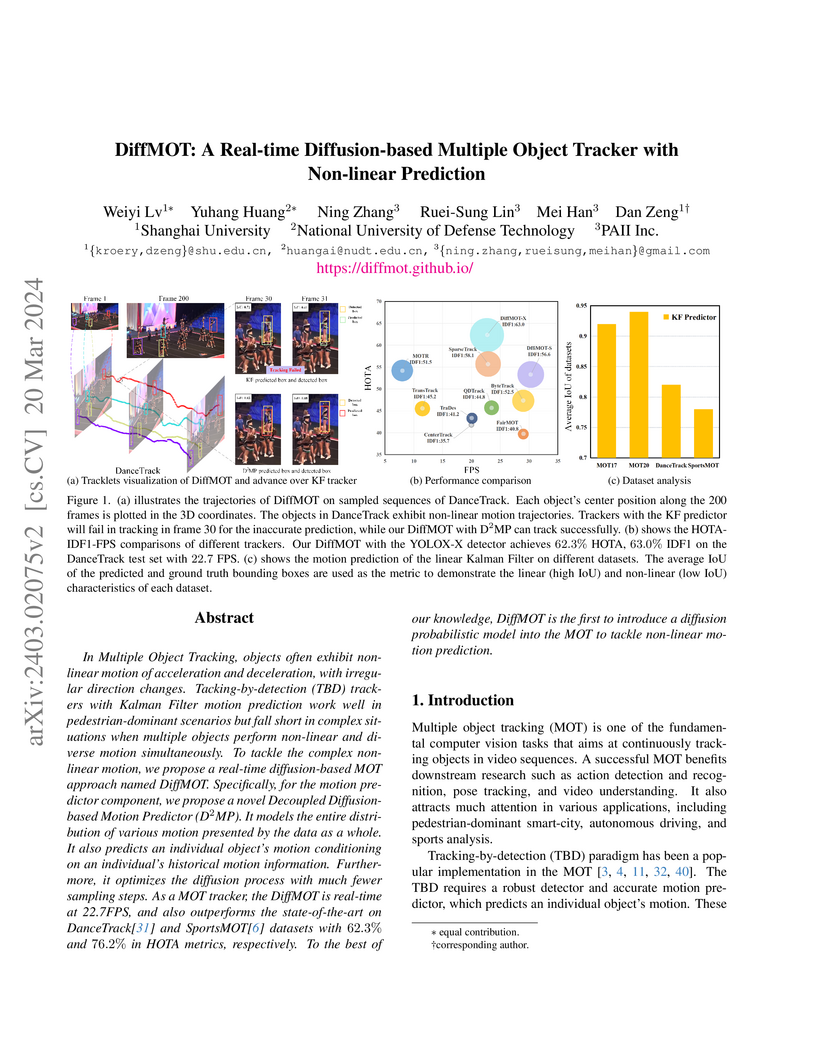
20 Mar 2024
DiffMOT introduces a real-time decoupled diffusion-based motion predictor (D²MP) for Multiple Object Tracking, achieving state-of-the-art performance on challenging non-linear motion datasets like DanceTrack and SportsMOT, while operating at real-time speeds.

14 Dec 2020

Accurate vertebra localization and identification are required in many
clinical applications of spine disorder diagnosis and surgery planning.
However, significant challenges are posed in this task by highly varying
pathologies (such as vertebral compression fracture, scoliosis, and vertebral
fixation) and imaging conditions (such as limited field of view and metal
streak artifacts). This paper proposes a robust and accurate method that
effectively exploits the anatomical knowledge of the spine to facilitate
vertebra localization and identification. A key point localization model is
trained to produce activation maps of vertebra centers. They are then
re-sampled along the spine centerline to produce spine-rectified activation
maps, which are further aggregated into 1-D activation signals. Following this,
an anatomically-constrained optimization module is introduced to jointly search
for the optimal vertebra centers under a soft constraint that regulates the
distance between vertebrae and a hard constraint on the consecutive vertebra
indices. When being evaluated on a major public benchmark of 302 highly
pathological CT images, the proposed method reports the state of the art
identification (id.) rate of 97.4%, and outperforms the best competing method
of 94.7% id. rate by reducing the relative id. error rate by half.

08 Nov 2020


In Robot-Assisted Minimally Invasive Surgery (RAMIS), a camera assistant is normally required to control the position and zooming ratio of the laparoscope, following the surgeon's instructions. However, moving the laparoscope frequently may lead to unstable and suboptimal views, while the adjustment of zooming ratio may interrupt the workflow of the surgical operation. To this end, we propose a multi-scale Generative Adversarial Network (GAN)-based video super-resolution method to construct a framework for automatic zooming ratio adjustment. It can provide automatic real-time zooming for high-quality visualization of the Region Of Interest (ROI) during the surgical operation. In the pipeline of the framework, the Kernel Correlation Filter (KCF) tracker is used for tracking the tips of the surgical tools, while the Semi-Global Block Matching (SGBM) based depth estimation and Recurrent Neural Network (RNN)-based context-awareness are developed to determine the upscaling ratio for zooming. The framework is validated with the JIGSAW dataset and Hamlyn Centre Laparoscopic/Endoscopic Video Datasets, with results demonstrating its practicability.

29 Oct 2024
The rocketing prosperity of large language models (LLMs) in recent years has boosted the prevalence of vision-language models (VLMs) in the medical sector. In our online medical consultation scenario, a doctor responds to the texts and images provided by a patient in multiple rounds to diagnose her/his health condition, forming a multi-turn multimodal medical dialogue format. Unlike high-quality images captured by professional equipment in traditional medical visual question answering (Med-VQA), the images in our case are taken by patients' mobile phones. These images have poor quality control, with issues such as excessive background elements and the lesion area being significantly off-center, leading to degradation of vision-language alignment in the model training phase. In this paper, we propose ZALM3, a Zero-shot strategy to improve vision-language ALignment in Multi-turn Multimodal Medical dialogue. Since we observe that the preceding text conversations before an image can infer the regions of interest (RoIs) in the image, ZALM3 employs an LLM to summarize the keywords from the preceding context and a visual grounding model to extract the RoIs. The updated images eliminate unnecessary background noise and provide more effective vision-language alignment. To better evaluate our proposed method, we design a new subjective assessment metric for multi-turn unimodal/multimodal medical dialogue to provide a fine-grained performance comparison. Our experiments across three different clinical departments remarkably demonstrate the efficacy of ZALM3 with statistical significance.

22 Oct 2021
Box representation has been extensively used for object detection in computer vision. Such representation is efficacious but not necessarily optimized for biomedical objects (e.g., glomeruli), which play an essential role in renal pathology. In this paper, we propose a simple circle representation for medical object detection and introduce CircleNet, an anchor-free detection framework. Compared with the conventional bounding box representation, the proposed bounding circle representation innovates in three-fold: (1) it is optimized for ball-shaped biomedical objects; (2) The circle representation reduced the degree of freedom compared with box representation; (3) It is naturally more rotation invariant. When detecting glomeruli and nuclei on pathological images, the proposed circle representation achieved superior detection performance and be more rotation-invariant, compared with the bounding box. The code has been made publicly available: this https URL

11 Apr 2025
EasyGenNet presents a diffusion model-based framework for audio-driven gesture video generation, creating photorealistic videos with natural body movements and facial expressions synchronized with speech audio. The system, developed at an undisclosed institution, utilizes a two-stage pipeline that first converts audio to 3D human poses (SMPLX) and then transforms these poses into video frames, demonstrating superior visual quality and temporal consistency while requiring less training data compared to prior methods.

23 Jul 2020

Visual cues of enforcing bilaterally symmetric anatomies as normal findings are widely used in clinical practice to disambiguate subtle abnormalities from medical images. So far, inadequate research attention has been received on effectively emulating this practice in CAD methods. In this work, we exploit semantic anatomical symmetry or asymmetry analysis in a complex CAD scenario, i.e., anterior pelvic fracture detection in trauma PXRs, where semantically pathological (refer to as fracture) and non-pathological (e.g., pose) asymmetries both occur. Visually subtle yet pathologically critical fracture sites can be missed even by experienced clinicians, when limited diagnosis time is permitted in emergency care. We propose a novel fracture detection framework that builds upon a Siamese network enhanced with a spatial transformer layer to holistically analyze symmetric image features. Image features are spatially formatted to encode bilaterally symmetric anatomies. A new contrastive feature learning component in our Siamese network is designed to optimize the deep image features being more salient corresponding to the underlying semantic asymmetries (caused by pelvic fracture occurrences). Our proposed method have been extensively evaluated on 2,359 PXRs from unique patients (the largest study to-date), and report an area under ROC curve score of 0.9771. This is the highest among state-of-the-art fracture detection methods, with improved clinical indications.

09 May 2022
Deep learning methods can struggle to handle domain shifts not seen in
training data, which can cause them to not generalize well to unseen domains.
This has led to research attention on domain generalization (DG), which aims to
the model's generalization ability to out-of-distribution. Adversarial domain
generalization is a popular approach to DG, but conventional approaches (1)
struggle to sufficiently align features so that local neighborhoods are mixed
across domains; and (2) can suffer from feature space over collapse which can
threaten generalization performance. To address these limitations, we propose
localized adversarial domain generalization with space compactness
maintenance~(LADG) which constitutes two major contributions. First, we propose
an adversarial localized classifier as the domain discriminator, along with a
principled primary branch. This constructs a min-max game whereby the aim of
the featurizer is to produce locally mixed domains. Second, we propose to use a
coding-rate loss to alleviate feature space over collapse. We conduct
comprehensive experiments on the Wilds DG benchmark to validate our approach,
where LADG outperforms leading competitors on most datasets.
There are no more papers matching your filters at the moment.
