
13 Mar 2025
Text summarization plays a crucial role in natural language processing by
condensing large volumes of text into concise and coherent summaries. As
digital content continues to grow rapidly and the demand for effective
information retrieval increases, text summarization has become a focal point of
research in recent years. This study offers a thorough evaluation of four
leading pre-trained and open-source large language models: BART, FLAN-T5,
LLaMA-3-8B, and Gemma-7B, across five diverse datasets CNN/DM, Gigaword, News
Summary, XSum, and BBC News. The evaluation employs widely recognized automatic
metrics, including ROUGE-1, ROUGE-2, ROUGE-L, BERTScore, and METEOR, to assess
the models' capabilities in generating coherent and informative summaries. The
results reveal the comparative strengths and limitations of these models in
processing various text types.

08 Oct 2025
The Indian Dark matter search Experiment (InDEx) has been initiated at Jaduguda Underground Science Laboratory (JUSL) to explore the low mass region of dark matter. The detectors used by InDEx are superheated droplet detectors with active liquid C2H2F4. The run1 of InDEx was with 2.47 kg-days of exposure at a threshold of 5.87 keV. In the present work, the run2 of InDEx, the detectors were set at 1.95 keV thresholds with an active liquid mass of 70.4 g. For a runtime of 102.48 days, the experimental results set constraint on spin-independent at 20.4 GeV/c2 and on spin-dependent at 21.0 GeV/c2 WIMP mass respectively. There is a shift of the most sensitive WIMP mass towards the lower region and an improvement of the sensitivity limit over the InDEx run1.

23 Jun 2025
Talking Head Generation (THG) has emerged as a transformative technology in computer vision, enabling the synthesis of realistic human faces synchronized with image, audio, text, or video inputs. This paper provides a comprehensive review of methodologies and frameworks for talking head generation, categorizing approaches into 2D--based, 3D--based, Neural Radiance Fields (NeRF)--based, diffusion--based, parameter-driven techniques and many other techniques. It evaluates algorithms, datasets, and evaluation metrics while highlighting advancements in perceptual realism and technical efficiency critical for applications such as digital avatars, video dubbing, ultra-low bitrate video conferencing, and online education. The study identifies challenges such as reliance on pre--trained models, extreme pose handling, multilingual synthesis, and temporal consistency. Future directions include modular architectures, multilingual datasets, hybrid models blending pre--trained and task-specific layers, and innovative loss functions. By synthesizing existing research and exploring emerging trends, this paper aims to provide actionable insights for researchers and practitioners in the field of talking head generation. For the complete survey, code, and curated resource list, visit our GitHub repository: this https URL.

20 Sep 2022
Optical Coherence Tomography (OCT) image denoising is a fundamental problem as OCT images suffer from multiplicative speckle noise, resulting in poor visibility of retinal layers. The traditional denoising methods consider specific statistical properties of the noise, which are not always known. Furthermore, recent deep learning-based denoising methods require paired noisy and clean images, which are often difficult to obtain, especially medical images. Noise2Noise family architectures are generally proposed to overcome this issue by learning without noisy-clean image pairs. However, for that, multiple noisy observations from a single image are typically needed. Also, sometimes the experiments are demonstrated by simulating noises on clean synthetic images, which is not a realistic scenario. This work shows how a single real-world noisy observation of each image can be used to train a denoising network. Along with a theoretical understanding, our algorithm is experimentally validated using a publicly available OCT image dataset. Our approach incorporates Anscombe transform to convert the multiplicative noise model to additive Gaussian noise to make it suitable for OCT images. The quantitative results show that this method can outperform several other methods where a single noisy observation of an image is needed for denoising. The code and implementation of this paper will be available publicly upon acceptance of this paper.

30 Sep 2025
We investigate regular rotating black holes predicted by asymptotically safe gravity, where the Newton constant varies with energy scale and modifies the near horizon geometry. These solutions remain asymptotically flat and avoid central singularities while differing from the classical Kerr spacetime in the strong field region. We compute the radiative efficiency of thin accretion disks and the jet power from the Blandford Znajek mechanism, both of which depend on the deformation parameter of the model. The predictions are compared with observational estimates for six stellar mass black holes. For systems with low or moderate spin the model reproduces the data within reported uncertainties, while rapidly spinning sources such as GRS 1915 105 present tensions and point to a restricted deformation range or the need for additional physics. The results show that quantum corrections confined to the strong gravity regime can still leave detectable imprints on high energy astrophysical processes. Radiative and jet based diagnostics therefore provide a promising method to test the geometry near the horizon and to explore possible signatures of quantum gravity in observations.

03 Oct 2025

Researchers from RIT, Columbia University, and Jadavpur University introduce a publicly available, UAV-based Visible and Near-Infrared (VNIR) hyperspectral benchmark dataset tailored for landmine and unexploded ordnance (UXO) detection. This dataset, featuring 143 diverse inert targets, demonstrates high radiometric accuracy (RMSE < 1.0, SAM 1°-6° for 400-900nm) and is designed to facilitate multi-sensor fusion research by complementing existing electromagnetic induction (EMI) data.

23 Feb 2024

Deep Operator Networks are an increasingly popular paradigm for solving
regression in infinite dimensions and hence solve families of PDEs in one shot.
In this work, we aim to establish a first-of-its-kind data-dependent lowerbound
on the size of DeepONets required for them to be able to reduce empirical error
on noisy data. In particular, we show that for low training errors to be
obtained on data points it is necessary that the common output dimension of
the branch and the trunk net be scaling as $\Omega \left (
\sqrt[\leftroot{-1}\uproot{-1}4]{n} \right )$.
This inspires our experiments with DeepONets solving the
advection-diffusion-reaction PDE, where we demonstrate the possibility that at
a fixed model size, to leverage increase in this common output dimension and
get monotonic lowering of training error, the size of the training data might
necessarily need to scale at least quadratically with it.

15 Sep 2024
In recent years, there has been a surge in the publication of clinical trial
reports, making it challenging to conduct systematic reviews. Automatically
extracting Population, Intervention, Comparator, and Outcome (PICO) from
clinical trial studies can alleviate the traditionally time-consuming process
of manually scrutinizing systematic reviews. Existing approaches of PICO frame
extraction involves supervised approach that relies on the existence of
manually annotated data points in the form of BIO label tagging. Recent
approaches, such as In-Context Learning (ICL), which has been shown to be
effective for a number of downstream NLP tasks, require the use of labeled
examples. In this work, we adopt ICL strategy by employing the pretrained
knowledge of Large Language Models (LLMs), gathered during the pretraining
phase of an LLM, to automatically extract the PICO-related terminologies from
clinical trial documents in unsupervised set up to bypass the availability of
large number of annotated data instances. Additionally, to showcase the highest
effectiveness of LLM in oracle scenario where large number of annotated samples
are available, we adopt the instruction tuning strategy by employing Low Rank
Adaptation (LORA) to conduct the training of gigantic model in low resource
environment for the PICO frame extraction task. Our empirical results show that
our proposed ICL-based framework produces comparable results on all the version
of EBM-NLP datasets and the proposed instruction tuned version of our framework
produces state-of-the-art results on all the different EBM-NLP datasets. Our
project is available at \url{this https URL}.

29 Aug 2025
The evolution of technology and education is driving the emergence of Intelligent & Autonomous Tutoring Systems (IATS), where objective and domain-agnostic methods for determining question difficulty are essential. Traditional human labeling is subjective, and existing NLP-based approaches fail in symbolic domains like algebra. This study introduces the Approach of Passive Measures among Educands (APME), a reinforcement learning-based Multi-Armed Bandit (MAB) framework that estimates difficulty solely from solver performance data -- marks obtained and time taken -- without requiring linguistic features or expert labels. By leveraging the inverse coefficient of variation as a risk-adjusted metric, the model provides an explainable and scalable mechanism for adaptive assessment. Empirical validation was conducted on three heterogeneous datasets. Across these diverse contexts, the model achieved an average R2 of 0.9213 and an average RMSE of 0.0584, confirming its robustness, accuracy, and adaptability to different educational levels and assessment formats. Compared with baseline approaches-such as regression-based, NLP-driven, and IRT models-the proposed framework consistently outperformed alternatives, particularly in purely symbolic domains. The findings highlight that (i) item heterogeneity strongly influences perceived difficulty, and (ii) variance in solver outcomes is as critical as mean performance for adaptive allocation. Pedagogically, the model aligns with Vygotskys Zone of Proximal Development by identifying tasks that balance challenge and attainability, supporting motivation while minimizing disengagement. This domain-agnostic, self-supervised approach advances difficulty tagging in IATS and can be extended beyond algebra wherever solver interaction data is available

08 Mar 2023

Glaucoma is a chronic visual disease that may cause permanent irreversible blindness. Measurement of the cup-to-disc ratio (CDR) plays a pivotal role in the detection of glaucoma in its early stage, preventing visual disparities. Therefore, accurate and automatic segmentation of optic disc (OD) and optic cup (OC) from retinal fundus images is a fundamental requirement. Existing CNN-based segmentation frameworks resort to building deep encoders with aggressive downsampling layers, which suffer from a general limitation on modeling explicit long-range dependency. To this end, in this paper, we propose a new segmentation pipeline, called UT-Net, availing the advantages of U-Net and transformer both in its encoding layer, followed by an attention-gated bilinear fusion scheme. In addition to this, we incorporate Multi-Head Contextual attention to enhance the regular self-attention used in traditional vision transformers. Thus low-level features along with global dependencies are captured in a shallow manner. Besides, we extract context information at multiple encoding layers for better exploration of receptive fields, and to aid the model to learn deep hierarchical representations. Finally, an enhanced mixing loss is proposed to tightly supervise the overall learning process. The proposed model has been implemented for joint OD and OC segmentation on three publicly available datasets: DRISHTI-GS, RIM-ONE R3, and REFUGE. Additionally, to validate our proposal, we have performed exhaustive experimentation on Glaucoma detection from all three datasets by measuring the Cup to Disc Ratio (CDR) value. Experimental results demonstrate the superiority of UT-Net as compared to the state-of-the-art methods.

30 Apr 2024

Unsupervised object discovery is becoming an essential line of research for
tackling recognition problems that require decomposing an image into entities,
such as semantic segmentation and object detection. Recently, object-centric
methods that leverage self-supervision have gained popularity, due to their
simplicity and adaptability to different settings and conditions. However,
those methods do not exploit effective techniques already employed in modern
self-supervised approaches. In this work, we consider an object-centric
approach in which DINO ViT features are reconstructed via a set of queried
representations called slots. Based on that, we propose a masking scheme on
input features that selectively disregards the background regions, inducing our
model to focus more on salient objects during the reconstruction phase.
Moreover, we extend the slot attention to a multi-query approach, allowing the
model to learn multiple sets of slots, producing more stable masks. During
training, these multiple sets of slots are learned independently while, at test
time, these sets are merged through Hungarian matching to obtain the final
slots. Our experimental results and ablations on the PASCAL-VOC 2012 dataset
show the importance of each component and highlight how their combination
consistently improves object localization. Our source code is available at:
this https URL

04 Dec 2025
This article investigates how a uniform high frequency (HF) drive applied to each site of a weakly-coupled discrete nonlinear resonator array can modulate the onsite natural stiffness and damping and thereby facilitate the active tunability of the nonlinear response and the phonon dispersion relation externally. Starting from a canonical model of parametrically excited \textit{van der Pol-Duffing} chain of oscillators with nearest neighbor coupling, a systematic two-widely separated time scale expansion (\textit{Direct Partition of Motion}) has been employed, in the backdrop of Blekhman's perturbation scheme. This procedure eliminates the fast scale and yields the effective collective dynamics of the array with renormalized stiffness and damping, modified by the high-frequency drive. The resulting dispersion shift controls which normal modes enter the parametric resonance window, allowing highly selective activation of specific bulk modes through external HF tuning. The collective resonant response to the parametric excitation and mode-selection by the HF drive has been analyzed and validated by detailed numerical simulations. The results offer a straightforward, experimentally tractable route to active control of response and channelize energy through selective mode activation in MEMS/NEMS arrays and related resonator platforms.

23 Aug 2025
Live cell culture is crucial in biomedical studies for analyzing cell properties and dynamics in vitro. This study focuses on segmenting unstained live cells imaged with bright-field microscopy. While many segmentation approaches exist for microscopic images, none consistently address the challenges of bright-field live-cell imaging with high throughput, where temporal phenotype changes, low contrast, noise, and motion-induced blur from cellular movement remain major obstacles. We developed a low-cost CNN-based pipeline incorporating comparative analysis of frozen encoders within a unified U-Net architecture enhanced with attention mechanisms, instance-aware systems, adaptive loss functions, hard instance retraining, dynamic learning rates, progressive mechanisms to mitigate overfitting, and an ensemble technique. The model was validated on a public dataset featuring diverse live cell variants, showing consistent competitiveness with state-of-the-art methods, achieving 93% test accuracy and an average F1-score of 89% (std. 0.07) on low-contrast, noisy, and blurry images. Notably, the model was trained primarily on bright-field images with limited exposure to phase- contrast microscopy (<20%), yet it generalized effectively to the phase-contrast LIVECell dataset, demonstrating modality, robustness and strong performance. This highlights its potential for real- world laboratory deployment across imaging conditions. The model requires minimal compute power and is adaptable using basic deep learning setups such as Google Colab, making it practical for training on other cell variants. Our pipeline outperforms existing methods in robustness and precision for bright-field microscopy segmentation. The code and dataset are available for reproducibility 1.

14 Mar 2025
How Green are Neural Language Models? Analyzing Energy Consumption in Text Summarization Fine-tuning
How Green are Neural Language Models? Analyzing Energy Consumption in Text Summarization Fine-tuning
Artificial intelligence systems significantly impact the environment,
particularly in natural language processing (NLP) tasks. These tasks often
require extensive computational resources to train deep neural networks,
including large-scale language models containing billions of parameters. This
study analyzes the trade-offs between energy consumption and performance across
three neural language models: two pre-trained models (T5-base and BART-base),
and one large language model (LLaMA-3-8B). These models were fine-tuned for the
text summarization task, focusing on generating research paper highlights that
encapsulate the core themes of each paper. The carbon footprint associated with
fine-tuning each model was measured, offering a comprehensive assessment of
their environmental impact. It is observed that LLaMA-3-8B produces the largest
carbon footprint among the three models. A wide range of evaluation metrics,
including ROUGE, METEOR, MoverScore, BERTScore, and SciBERTScore, were employed
to assess the performance of the models on the given task. This research
underscores the importance of incorporating environmental considerations into
the design and implementation of neural language models and calls for the
advancement of energy-efficient AI methodologies.

28 Aug 2025
The observation of collectivity and strangeness enhancement in small collision systems, such as proton-proton (pp) and proton-lead (p-Pb) collisions, challenges traditional assumptions regarding thermalization and particle production mechanisms. In this study, we investigate particle yields and transverse momentum distributions in pp and p-Pb collisions at \sqrt{s_\rm{NN}} = 5.02 TeV using the EPOS4 event generator, which employs a core-corona framework to model particle production across a variety of system sizes. EPOS4 successfully reproduces many qualitative trends observed in experimental data, including the hardening of -spectra with multiplicity, the hierarchical strangeness enhancement in strange-to-pion ratios, and characteristic modifications of particle yield ratios as a function of and multiplicity. The microcanonical approach to core hadronization used in EPOS4 seems to provide a more realistic description of small systems compared to grand-canonical treatments. Nonetheless, quantitative discrepancies still persist in describing several physical observables. Future model refinements, including improved core-corona balancing, differential freeze-out conditions for multi-strange hadrons, and incorporation of finite strangeness correlation volumes, may be taken into account for enhancing EPOS4's predictive power and deepening our understanding of the complex dynamics governing the particle production in high-energy collisions.
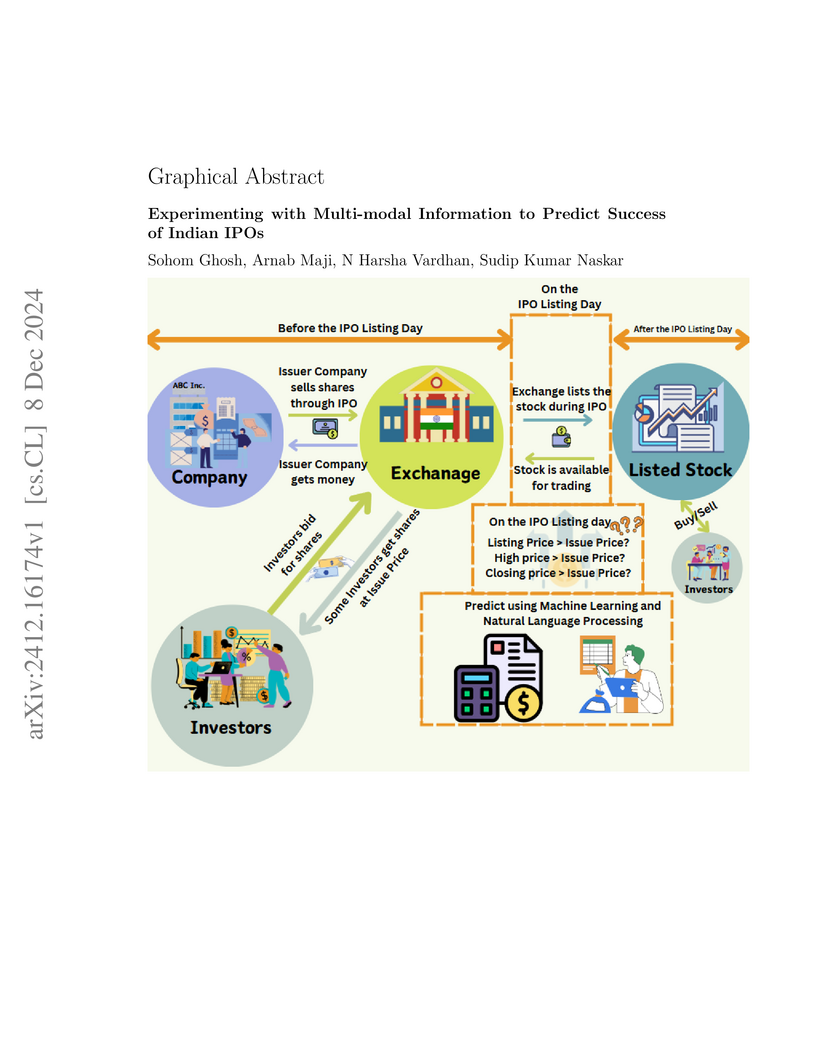
08 Dec 2024
A multi-modal machine learning framework predicts the short-term success of Indian Initial Public Offerings (IPOs), distinguishing between Main Board and Small and Medium Enterprises (SME) segments. The framework integrates numerical, categorical, and textual data to forecast listing day opening, high, and closing prices, while also assessing the reliability of Grey Market Premium as a predictor across different IPO types.

24 Dec 2016
In this work, we describe a system that detects paraphrases in Indian Languages as part of our participation in the shared Task on detecting paraphrases in Indian Languages (DPIL) organized by Forum for Information Retrieval Evaluation (FIRE) in 2016. Our paraphrase detection method uses a multinomial logistic regression model trained with a variety of features which are basically lexical and semantic level similarities between two sentences in a pair. The performance of the system has been evaluated against the test set released for the FIRE 2016 shared task on DPIL. Our system achieves the highest f-measure of 0.95 on task1 in Punjabi this http URL performance of our system on task1 in Hindi language is f-measure of 0.90. Out of 11 teams participated in the shared task, only four teams participated in all four languages, Hindi, Punjabi, Malayalam and Tamil, but the remaining 7 teams participated in one of the four languages. We also participated in task1 and task2 both for all four Indian Languages. The overall average performance of our system including task1 and task2 overall four languages is F1-score of 0.81 which is the second highest score among the four systems that participated in all four languages.

02 Apr 2025
Government fiscal policies, particularly annual union budgets, exert
significant influence on financial markets. However, real-time analysis of
budgetary impacts on sector-specific equity performance remains
methodologically challenging and largely unexplored. This study proposes a
framework to systematically identify and rank sectors poised to benefit from
India's Union Budget announcements. The framework addresses two core tasks: (1)
multi-label classification of excerpts from budget transcripts into 81
predefined economic sectors, and (2) performance ranking of these sectors.
Leveraging a comprehensive corpus of Indian Union Budget transcripts from 1947
to 2025, we introduce BASIR (Budget-Assisted Sectoral Impact Ranking), an
annotated dataset mapping excerpts from budgetary transcripts to sectoral
impacts. Our architecture incorporates fine-tuned embeddings for sector
identification, coupled with language models that rank sectors based on their
predicted performances. Our results demonstrate 0.605 F1-score in sector
classification, and 0.997 NDCG score in predicting ranks of sectors based on
post-budget performances. The methodology enables investors and policymakers to
quantify fiscal policy impacts through structured, data-driven insights,
addressing critical gaps in manual analysis. The annotated dataset has been
released under CC-BY-NC-SA-4.0 license to advance computational economics
research.

29 Jun 2023

The success of self-supervised learning (SSL) has mostly been attributed to
the availability of unlabeled yet large-scale datasets. However, in a
specialized domain such as medical imaging which is a lot different from
natural images, the assumption of data availability is unrealistic and
impractical, as the data itself is scanty and found in small databases,
collected for specific prognosis tasks. To this end, we seek to investigate the
applicability of self-supervised learning algorithms on small-scale medical
imaging datasets. In particular, we evaluate state-of-the-art SSL methods
on three publicly accessible \emph{small} medical imaging datasets. Our
investigation reveals that in-domain low-resource SSL pre-training can yield
competitive performance to transfer learning from large-scale datasets (such as
ImageNet). Furthermore, we extensively analyse our empirical findings to
provide valuable insights that can motivate for further research towards
circumventing the need for pre-training on a large image corpus. To the best of
our knowledge, this is the first attempt to holistically explore
self-supervision on low-resource medical datasets.

08 Oct 2025
During the Cosmic Dawn (CD), the HI 21-cm optical depth ( ) in the intergalactic medium can become significantly large. Consequently, the second and higher-order terms of appearing in the Taylor expansion of the HI 21-cm differential brightness temperature ( ) become important. This introduces additional non-Gaussianity into the signal. We study the impact of large on statistical quantities of HI 21-cm signal using a suite of standard numerical simulations that vary X-ray heating efficiency and the minimum halo mass required to host radiation sources. We find that the higher order terms suppress statistical quantities such as skewness, power-spectrum and bispectrum. However, the effect is found to be particularly strong on the non-Gaussian signal. We find that the change in skewness can reach several hundred percent in low X-ray heating scenarios, whereas for moderate and high X-ray heating models changes are around and , respectively, for . This change is around , and for low, moderate and high X-ray heating models, respectively, for . The change in bispectrum in both the halo cutoff mass scenarios ranges from to for low X-ray heating model. However, for moderate and high X-ray heating models the change remains between to for both equilateral and squeezed limit triangle configuration. Finally, we find that up to third orders of need to be retained to accurately model , especially for capturing the non-Gaussian features in the HI 21-cm signal.
There are no more papers matching your filters at the moment.
